Trasformazione Suddivisione condizionale nel flusso di dati per mapping
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
I flussi di dati sono disponibili nelle pipeline sia di Azure Data Factory che di Azure Synapse. Questo articolo si applica ai flussi di dati per mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati con un flusso di dati per mapping.
La trasformazione Suddivisione condizionale instrada le righe di dati a flussi diversi in base alle condizioni di corrispondenza. La trasformazione Suddivisione condizionale è simile a una struttura decisionale CASE in un linguaggio di programmazione. La trasformazione valuta le espressioni e, in base ai risultati, indirizza la riga di dati al flusso specificato.
Impostazione
L'impostazione SplitOn determina se la riga di dati fluisce sul primo flusso corrispondente o su ogni flusso a cui corrisponde.
Utilizzare il generatore di espressioni del flusso di dati per immettere un'espressione per la condizione di divisione. Per aggiungere una nuova condizione, fare clic sull'icona con il segno più in una riga esistente. È possibile aggiungere un flusso predefinito anche per le righe che non soddisfano alcuna condizione.
Script del flusso di dati
Sintassi
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
Esempio
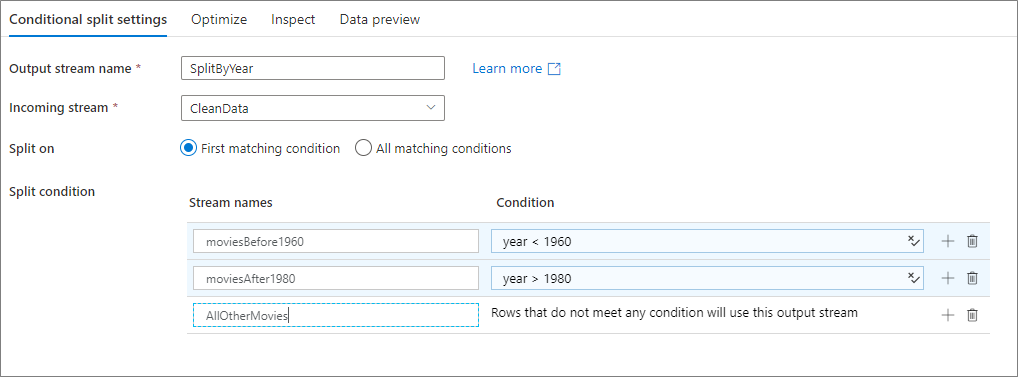
Nell'esempio seguente viene illustrata una trasformazione Suddivisione condizionale denominata SplitByYear che accetta il flusso in ingresso CleanData. Questa trasformazione presenta due condizioni di divisione year < 1960 e year > 1980. disjoint è false perché i dati passano alla prima condizione di corrispondenza anziché a tutte le condizioni corrispondenti. Ogni riga che corrisponde alla prima condizione passa al flusso di output moviesBefore1960. Tutte le righe rimanenti corrispondenti alla seconda condizione passano al flusso di output moviesAFter1980. Tutte le altre righe passano attraverso il flusso predefinito AllOtherMovies.
Nell'interfaccia utente del servizio questa trasformazione è simile all'immagine seguente:
Lo script del flusso di dati per questa trasformazione si trova nel frammento di codice seguente:
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)
Contenuto correlato
Le trasformazioni comuni del flusso di dati utilizzate con Suddivisione condizionale sono la trasformazione Join, la trasformazione Ricerca e la trasformazione Selezione