Trasformare i dati con i flussi di dati per mapping
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Se non si ha familiarità con Azure Data Factory, vedere Introduzione ad Azure Data Factory.
In questa esercitazione si userà l'interfaccia utente di Azure Data Factory per creare una pipeline che copia e trasforma i dati da un'origine Azure Data Lake Storage (ADLS) Gen2 a un sink ADLS Gen2 usando il flusso di dati di mapping. Il modello di configurazione in questa esercitazione può essere espanso quando si trasformano i dati usando il flusso di dati di mapping
Nota
Questa esercitazione è destinata ai flussi di dati di mapping in generale. I flussi di dati sono disponibili sia in Azure Data Factory che nelle pipeline di Synapse. Se non si ha una novità dei flussi di dati in Azure Synapse Pipelines, seguire Flusso di dati usando Azure Synapse Pipelines
In questa esercitazione vengono completati i passaggi seguenti:
- Creare una data factory.
- Creare una pipeline con un'attività di Flusso di dati.
- Creare un flusso di dati di mapping con quattro trasformazioni.
- Eseguire test della pipeline.
- Monitorare un’attività di flusso di dati
Prerequisiti
- Sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account Azure gratuito prima di iniziare.
- Account di archiviazione di Azure. Usare l'archivio ADSL come archivi dati di origine e sink. Se non si ha un account di archiviazione, vedere Creare un account di archiviazione di Azure per informazioni su come crearne uno.
Il file che si sta trasformando in questa esercitazione è MoviesDB.csv, disponibile qui. Per recuperare il file da GitHub, copiare il contenuto in un editor di testo di propria scelta per salvare localmente come file .csv. Per caricare il file nell'account di archiviazione, vedere Caricare BLOB con il portale di Azure. Gli esempi faranno riferimento a un contenitore denominato "sample-data".
Creare una data factory
In questo passaggio si crea una data factory e si apre l'esperienza utente di Data Factory per creare una pipeline nella data factory.
Aprire Microsoft Edge o Google Chrome. L'interfaccia utente di Data Factory è attualmente supportata solo nei Web browser Microsoft Edge e Google Chrome.
Nel menu sinistro selezionare Crea una risorsa>Integrazione>Data factory:
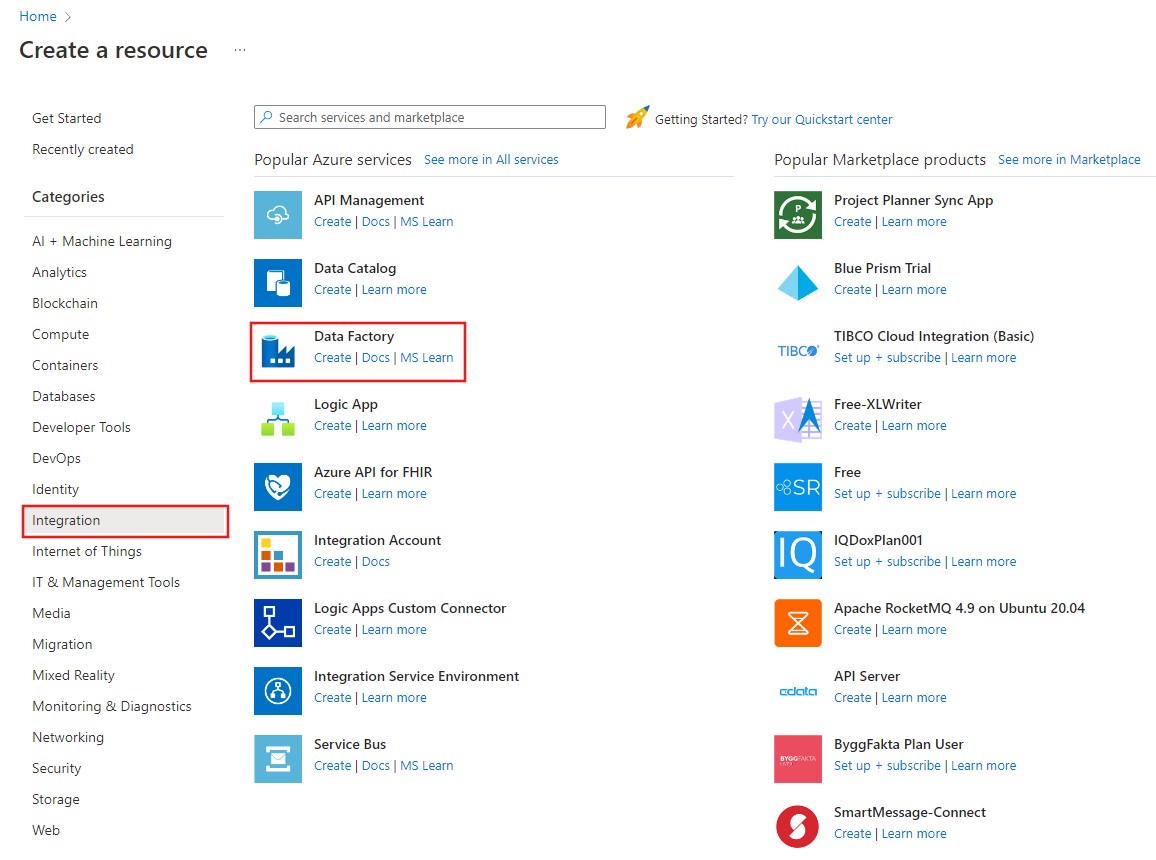
Nella pagina Nuova data factory immettere ADFTutorialDataFactory in Nome.
Il nome della data factory di Azure deve essere univoco a livello globale. Se viene visualizzato un messaggio di errore relativo al valore del nome, immettere un nome diverso per la data factory. Ad esempio, nomeutenteADFTutorialDataFactory. Per informazioni sulle regole di denominazione per gli elementi di Data factory, vedere Azure Data factory - Regole di denominazione.
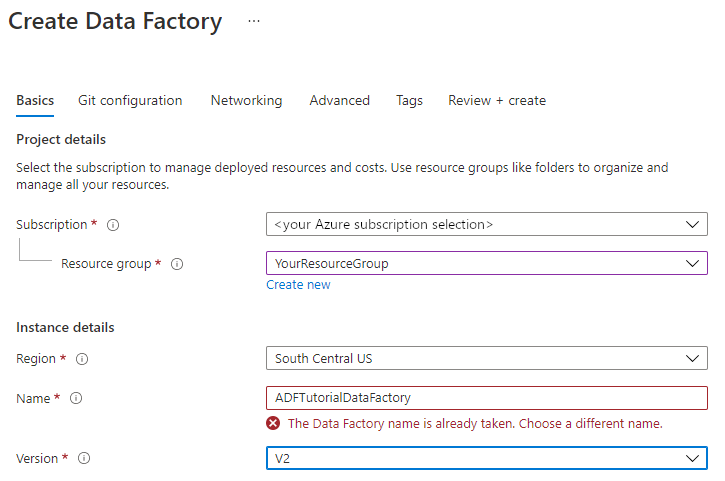
Selezionare la sottoscrizione di Azure in cui creare la data factory.
In Gruppo di risorse eseguire una di queste operazioni:
a. Selezionare Usa esistentee scegliere un gruppo di risorse esistente dall'elenco a discesa.
b. Selezionare Crea nuovoe immettere un nome per il gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere l'articolo su come usare gruppi di risorse per gestire le risorse di Azure.
In Versione selezionare V2.
In Località selezionare una località per la data factory. Nell'elenco a discesa vengono mostrate solo le località supportate. Archivi dati (ad esempio, Archiviazione di Azure e il database SQL) e risorse di calcolo (ad esempio, Azure HDInsight) usati dalla data factory possono trovarsi in altre aree.
Seleziona Crea.
Al termine della creazione, la relativa notifica verrà visualizzata nel centro notifiche. Selezionare Vai alla risorsa per passare alla pagina della data factory.
Selezionare Crea e monitora per avviare l'interfaccia utente di Data Factory in una scheda separata.
Creare una pipeline con un'attività Flusso di dati
In questo passaggio si creerà una pipeline contenente un'attività Flusso di dati.
Nella home page di Azure Data Factory selezionare Orchestrate .On the home page of Azure Data Factory, select Orchestrate.
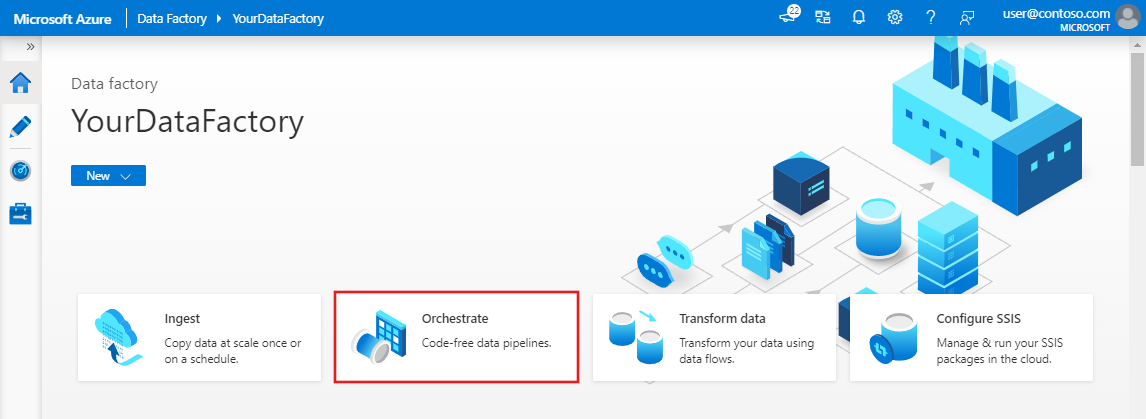
Nella scheda Generale della pipeline immettere TransformMovies per Nome della pipeline.
Nel riquadro Attività espandere l’accordion Sposta e trasforma. Trascinare e rilasciare l'attività Flusso di dati dal riquadro all'area di disegno della pipeline.
Nella finestra popup Aggiunta Flusso di dati selezionare Crea nuovo Flusso di dati e assegnare al flusso di dati il nome TransformMovies. Fare clic su Fine al termine.
Nella barra superiore dell'area di disegno della pipeline scorrere il dispositivo di scorrimento Debug del flusso di dati. La modalità di debug consente il test interattivo della logica di trasformazione rispetto a un cluster Spark live. L’avvio dei cluster Flusso di dati impiega 5-7 minuti e si consiglia di attivare prima il debug se si pianifica lo sviluppo del flusso di dati. Per altre informazioni, vedere Modalità di debug.

Compilare la logica di trasformazione nel canvas del flusso di dati
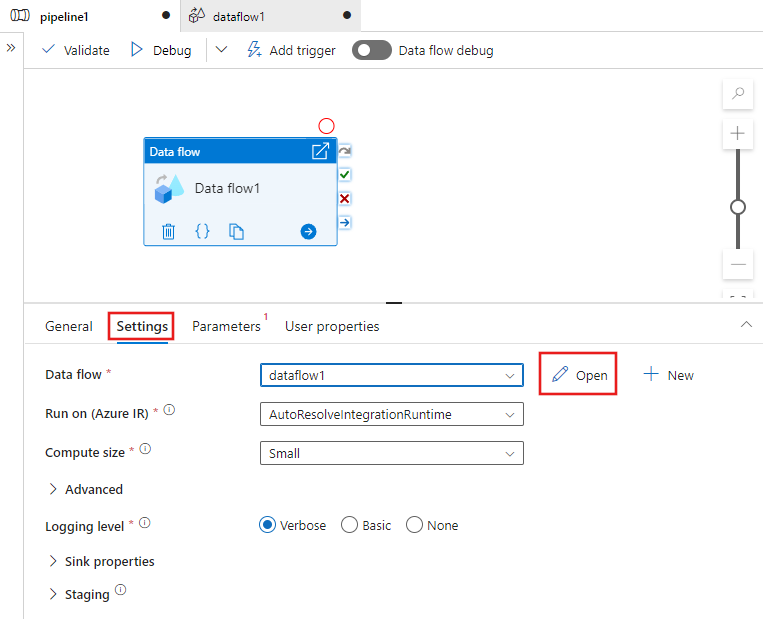
Dopo aver creato il flusso di dati, si verrà inviati automaticamente al canvas del flusso di dati. Se non si viene reindirizzati all'area di disegno del flusso di dati, nel pannello sotto l'area di disegno passare a Impostazioni e selezionare Apri, che si trova accanto al campo flusso di dati. Verrà aperta l'area di disegno del flusso di dati.
In questo passaggio si creerà un flusso di dati che accetta il moviesDB.csv nell'archiviazione ADLS e aggrega la classificazione media delle comedies dal 1910 al 2000. Si scriverà quindi di nuovo questo file nell'archiviazione ADLS.
Nel canvas del flusso di dati aggiungere un'origine facendo clic sulla casella Aggiungi origine.
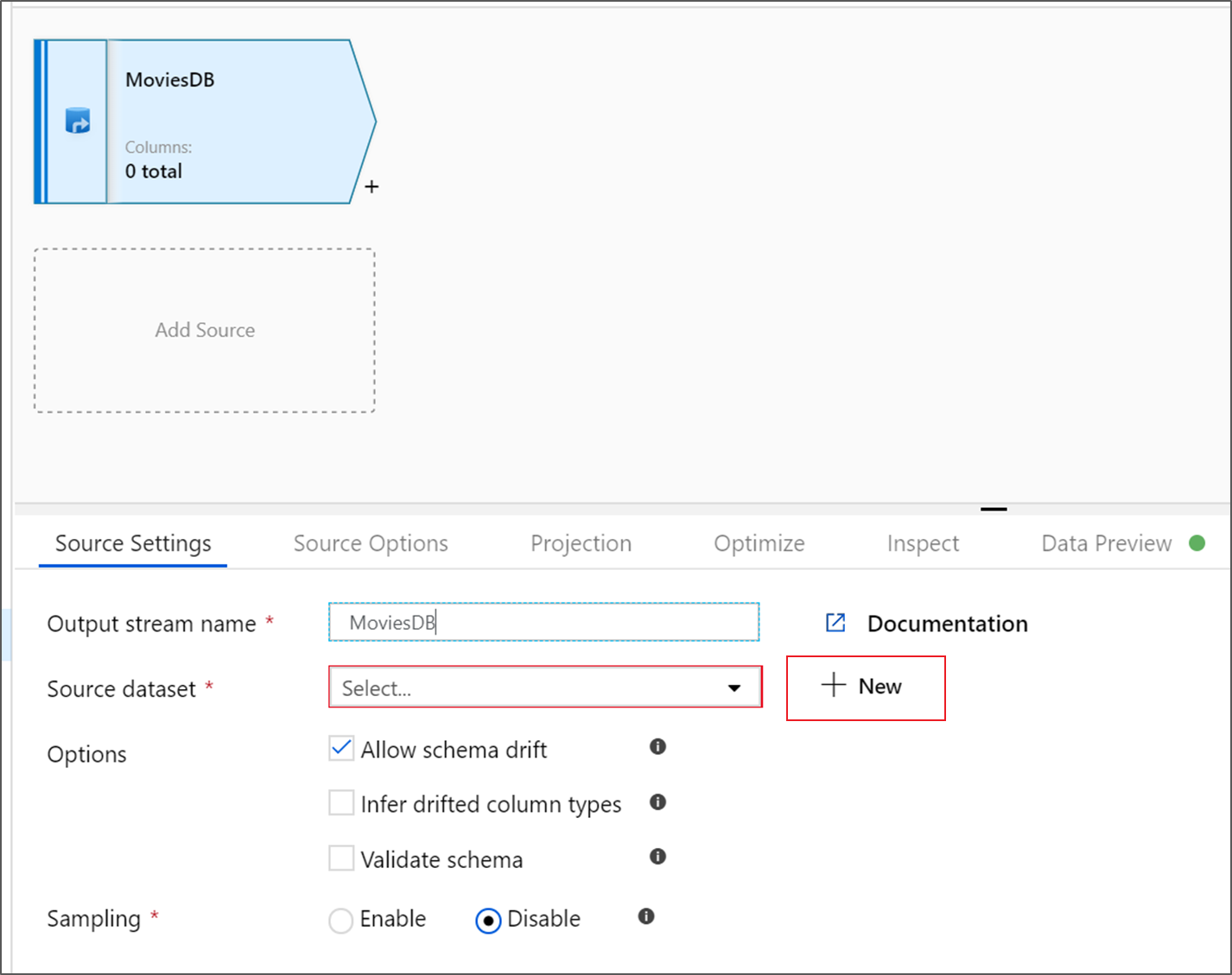
Assegnare all'origine il nome MoviesDB. Fare clic su Nuovo per creare un nuovo set di dati di origine.
Selezionare Azure Data Lake Storage Gen2. Fare clic su Continua.
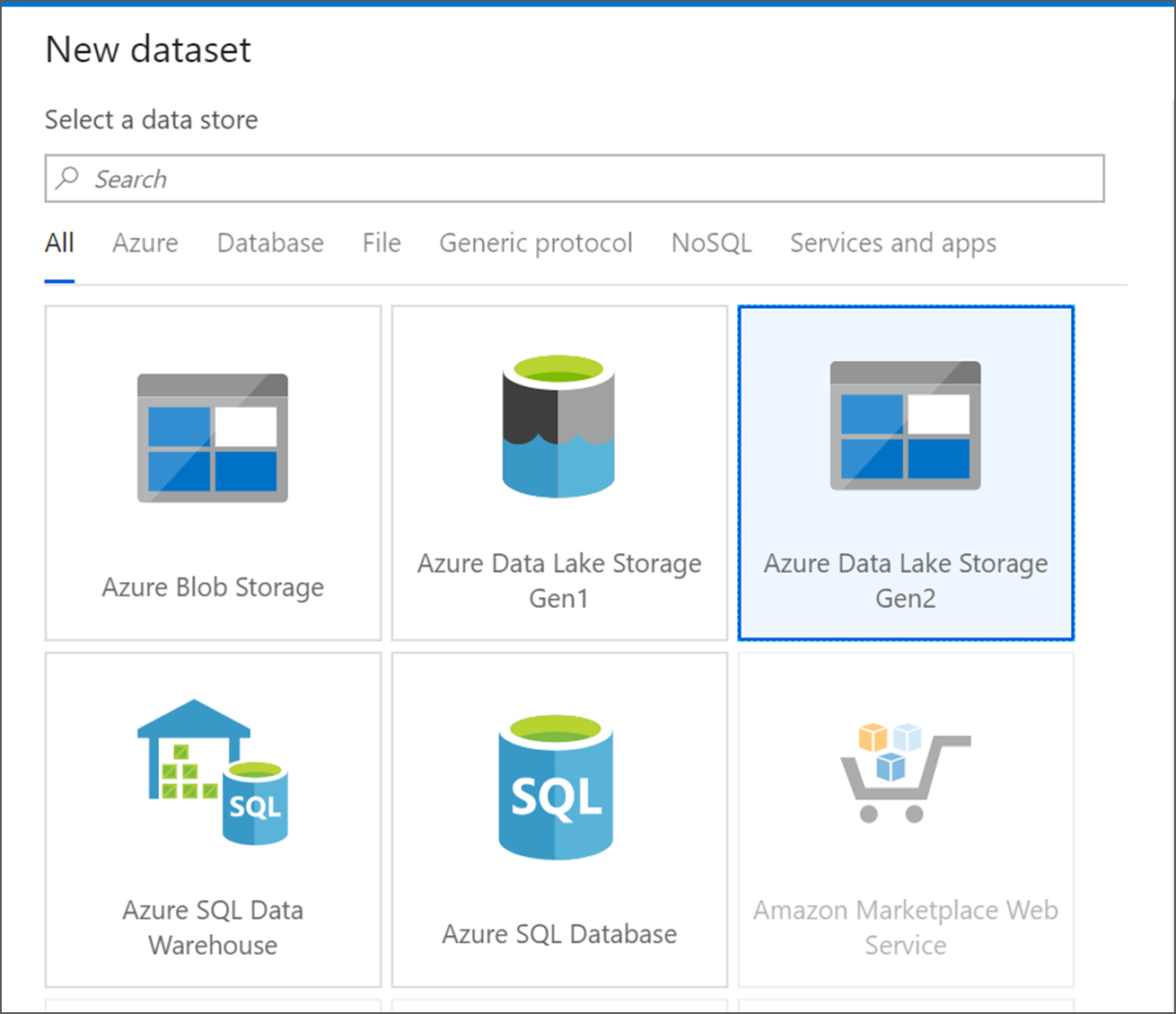
Scegliere DelimitedText. Fare clic su Continua.
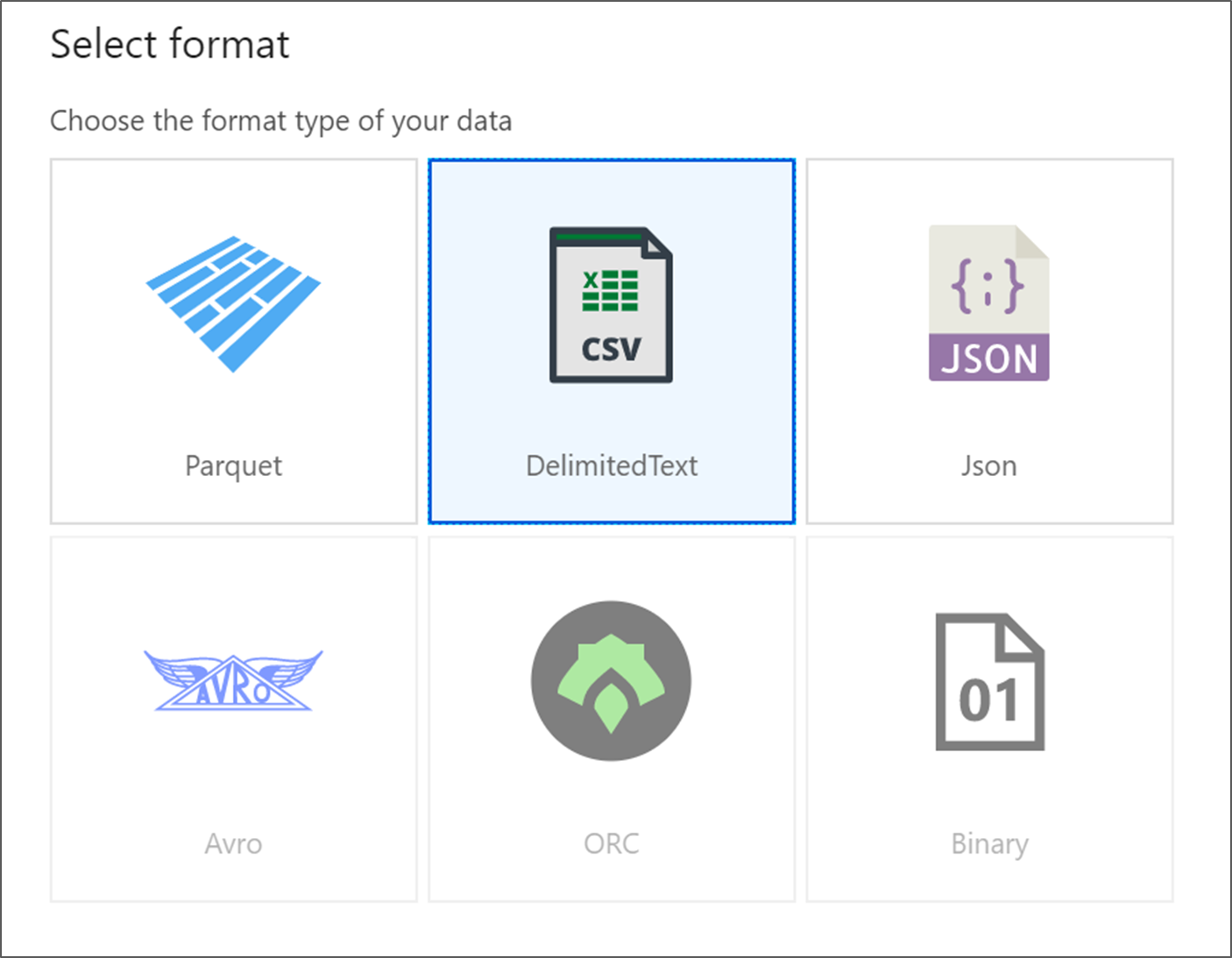
Assegnare al set di dati il nome MoviesDB. Nell'elenco a discesa dei servizi collegati scegliere Nuovo.
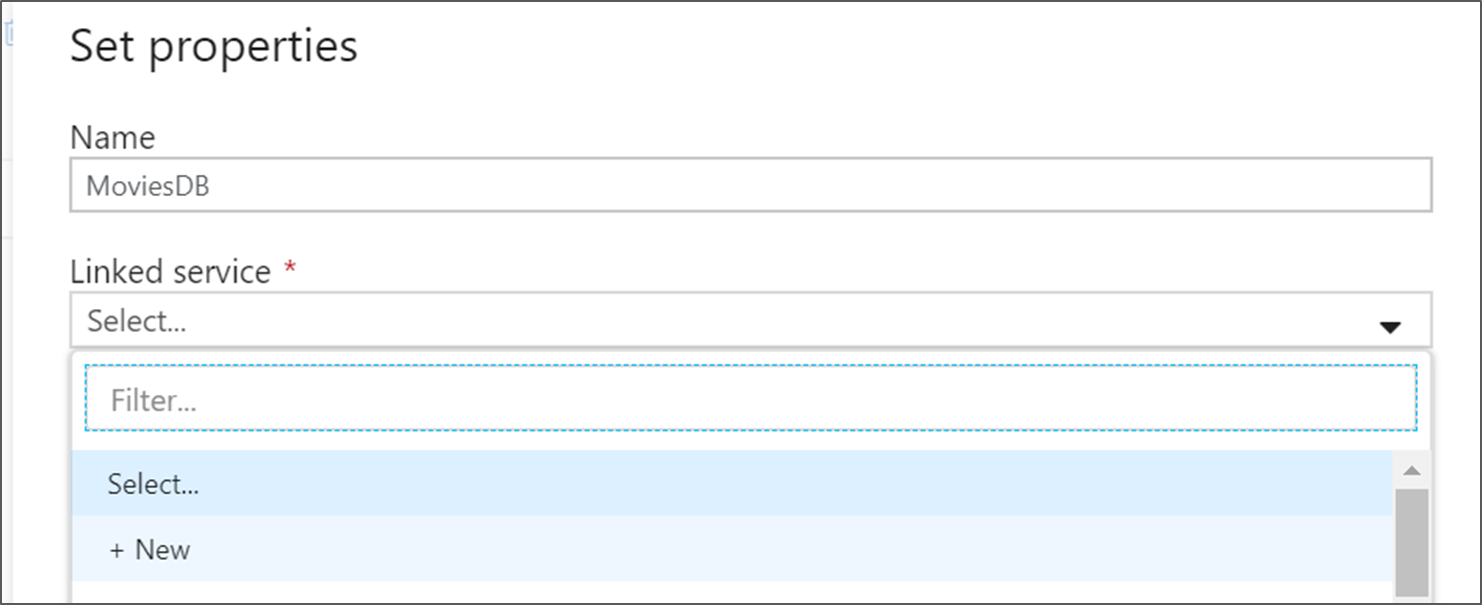
Nella schermata di creazione del servizio collegato assegnare un nome ad ADLS Gen2 al servizio collegato ADLSGen2 e specificare il metodo di autenticazione. Immettere quindi le credenziali di connessione. In questa esercitazione si usa la chiave dell'account per connettersi all'account di archiviazione. È possibile fare clic su Connessione di test per verificare che le credenziali siano state immesse correttamente. Al termine, fare clic su Crea.
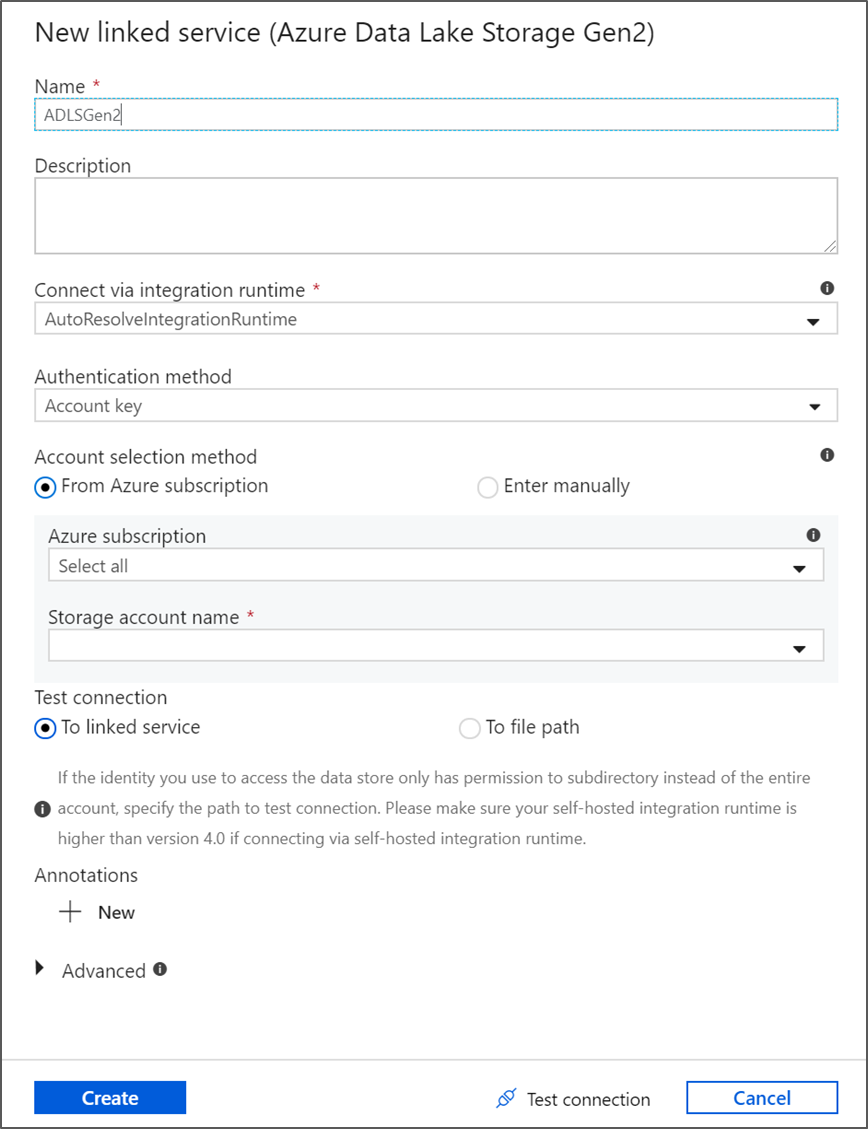
Quando si torna alla schermata di creazione del set di dati, immettere dove si trova il file nel campo Percorso file. In questa esercitazione il file moviesDB.csv si trova nel contenitore sample-data. Quando il file contiene intestazioni, selezionare Prima riga come intestazione. Selezionare Da connessione/archivio per importare lo schema di intestazione direttamente dal file nell'archiviazione. Fare clic su OK al termine dell'operazione.
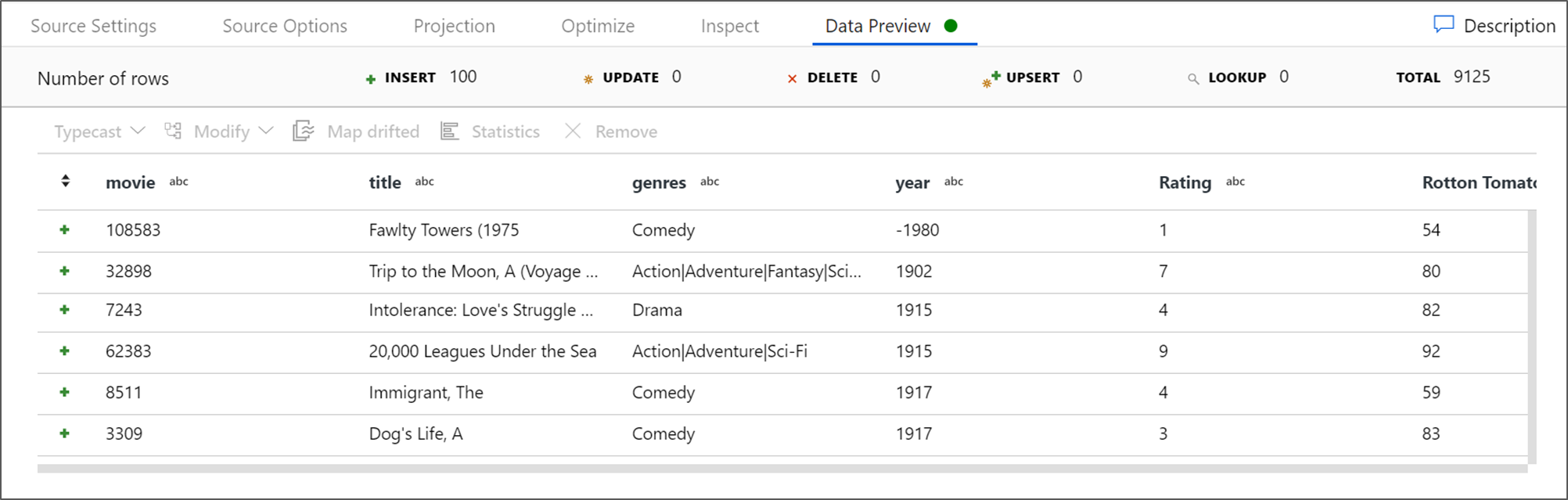
Se il cluster di debug è stato avviato, passare alla scheda Anteprima dati della trasformazione origine e fare clic su Aggiorna per ottenere uno snapshot dei dati. È possibile usare l'anteprima dei dati per verificare che la trasformazione sia configurata correttamente.
Accanto al nodo di origine nel canvas del flusso di dati, fare clic sull'icona con il segno più per aggiungere una nuova trasformazione. La prima trasformazione che si sta aggiungendo è un filtro.
Denominare la trasformazione filtro FilterYears. Fare clic sulla casella espressione accanto a Filtra in per aprire il generatore di espressioni. Qui si specificherà la condizione di filtro.
Il generatore di espressioni del flusso di dati consente di compilare in modo interattivo espressioni da usare in varie trasformazioni. Le espressioni possono includere funzioni predefinite, colonne dello schema di input e parametri definiti dall'utente. Per altre informazioni su come compilare espressioni, vedere Generatore di espressioni del flusso di dati.
In questa esercitazione si vogliono filtrare i film di genere commedia che sono usciti tra gli anni 1910 e 2000. Poiché l’anno è attualmente una stringa, è necessario convertirlo in un numero intero usando la funzione
toInteger(). Usare gli operatori maggiori o uguali a (>=) e minori o uguali a (<=) per confrontare i valori letterali anno 1910 e 2000. Unire queste espressioni con l'operatore e (&&). L'espressione viene restituita come segue:toInteger(year) >= 1910 && toInteger(year) <= 2000Per trovare quali film sono commedie, è possibile usare la funzione
rlike()per trovare il modello "Commedia" nella colonna Generi. Unire l'espressionerlikecon il confronto dell'anno per ottenere:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Se è attivo un cluster di debug, è possibile verificare la logica facendo clic su Aggiorna per visualizzare l'output dell'espressione rispetto agli input usati. Esiste più di una risposta corretta su come eseguire questa logica usando il linguaggio delle espressioni del flusso di dati.
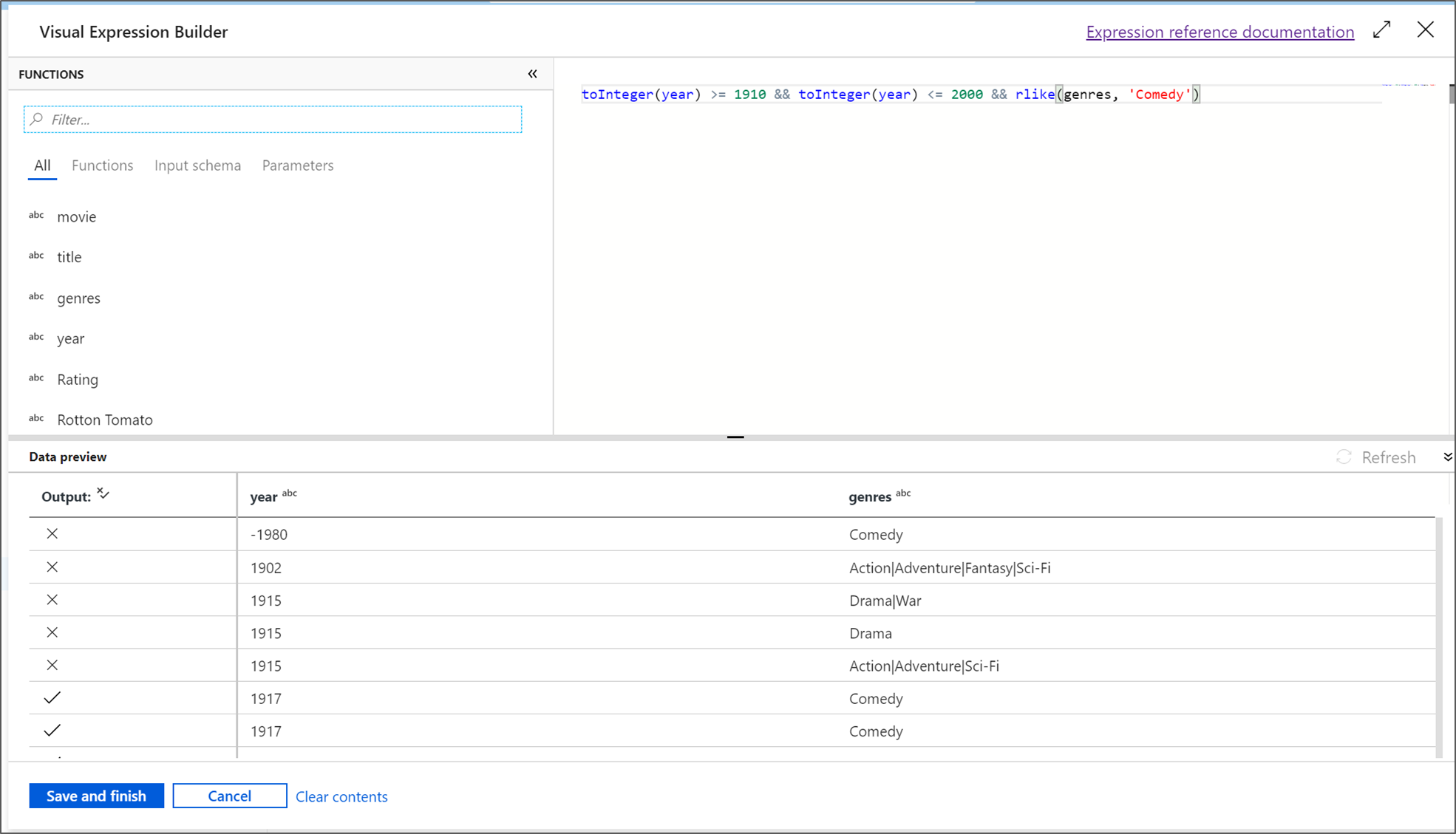
Dopo aver completato l'espressione, fare clic su Salva e fine.
Recuperare un'anteprima dei dati per verificare che il filtro funzioni correttamente.
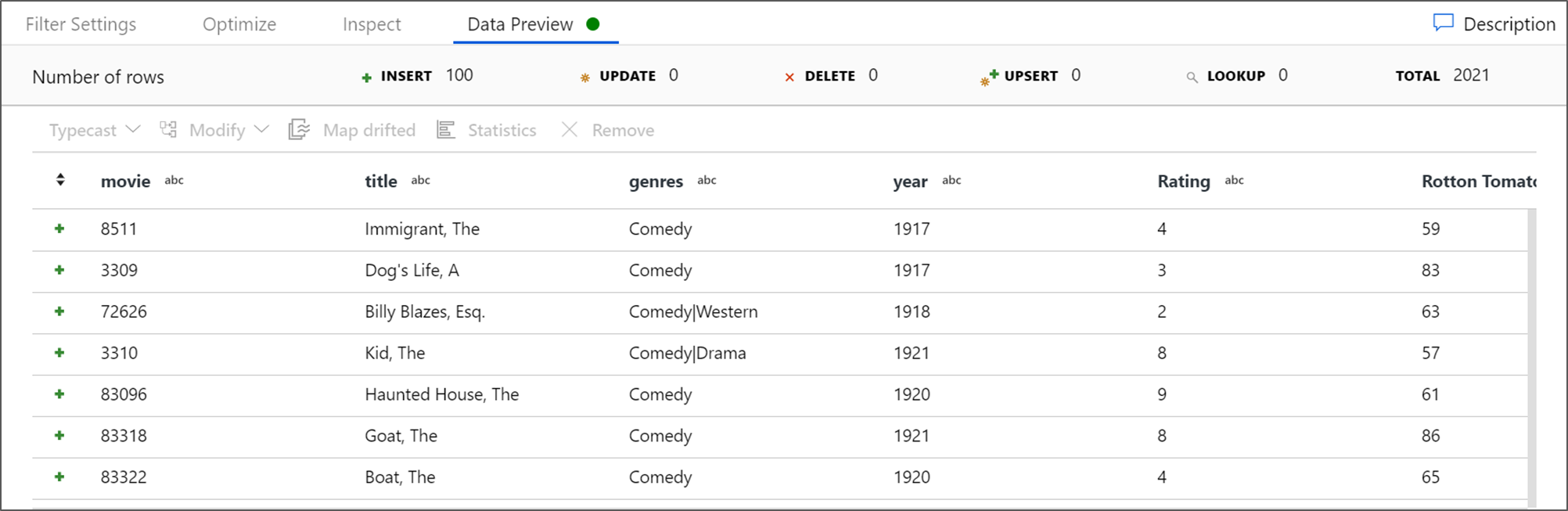
La trasformazione successiva che si aggiungerà è una di tipo Aggregazione in Modificatore dello schema.
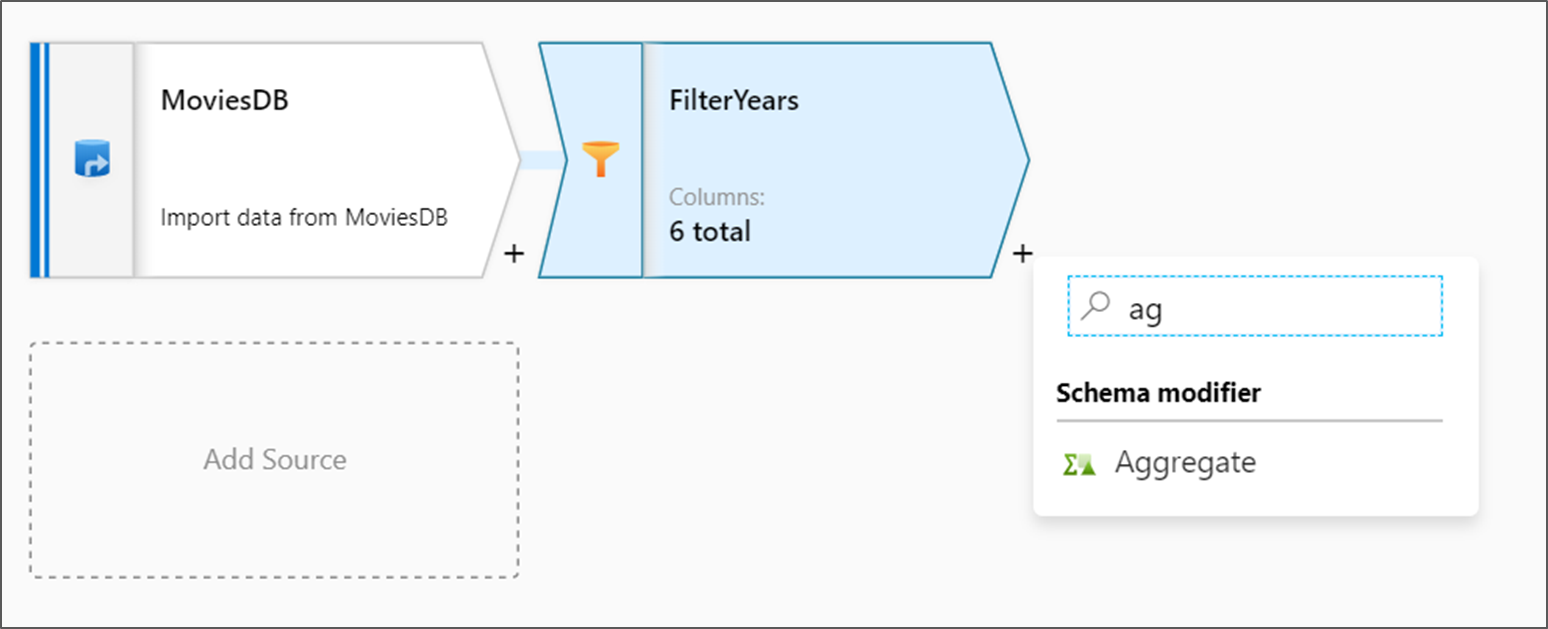
Assegnare un nome alla trasformazione di aggregazione AggregateComedyRatings. Nella scheda Raggruppa per selezionare anno nell'elenco a discesa per raggruppare le aggregazioni in base all'anno in cui è uscito il film.
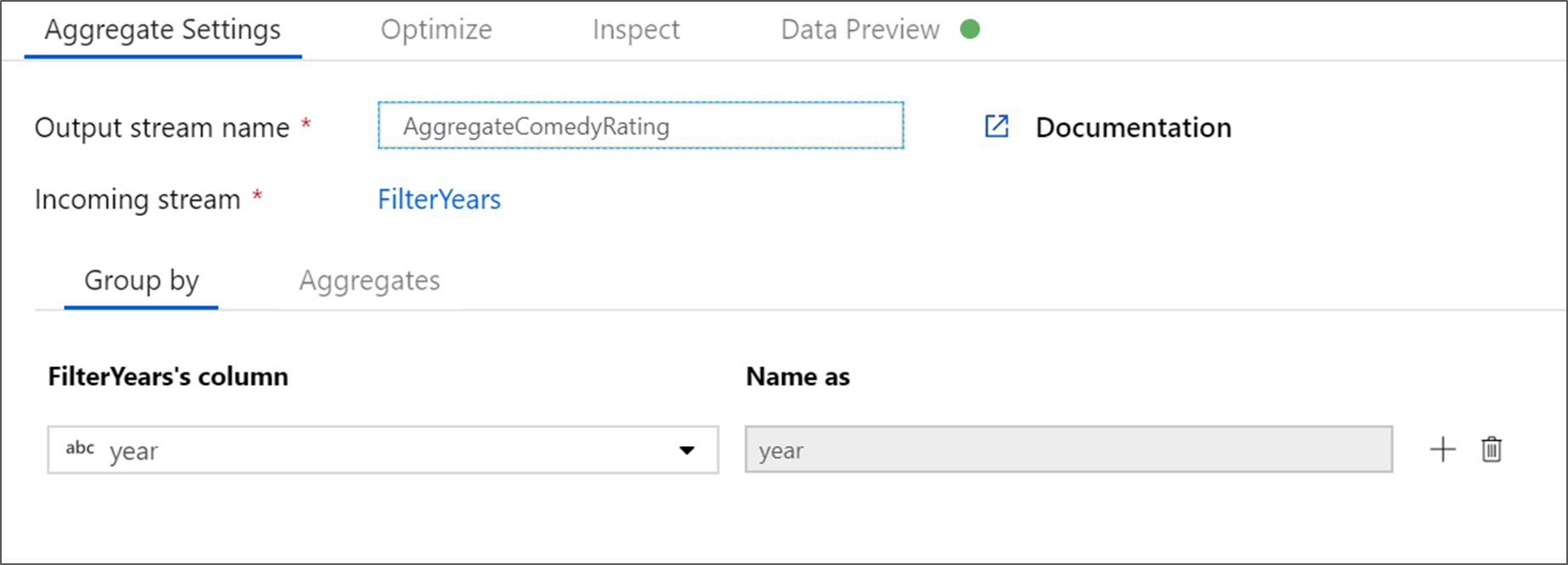
Passare alla scheda Aggregates (Aggregazioni). Nella casella di testo a sinistra denominare la colonna di aggregazione AverageComedyRating. Fare clic sulla casella dell'espressione a destra per immettere l'espressione di aggregazione tramite il generatore di espressioni.
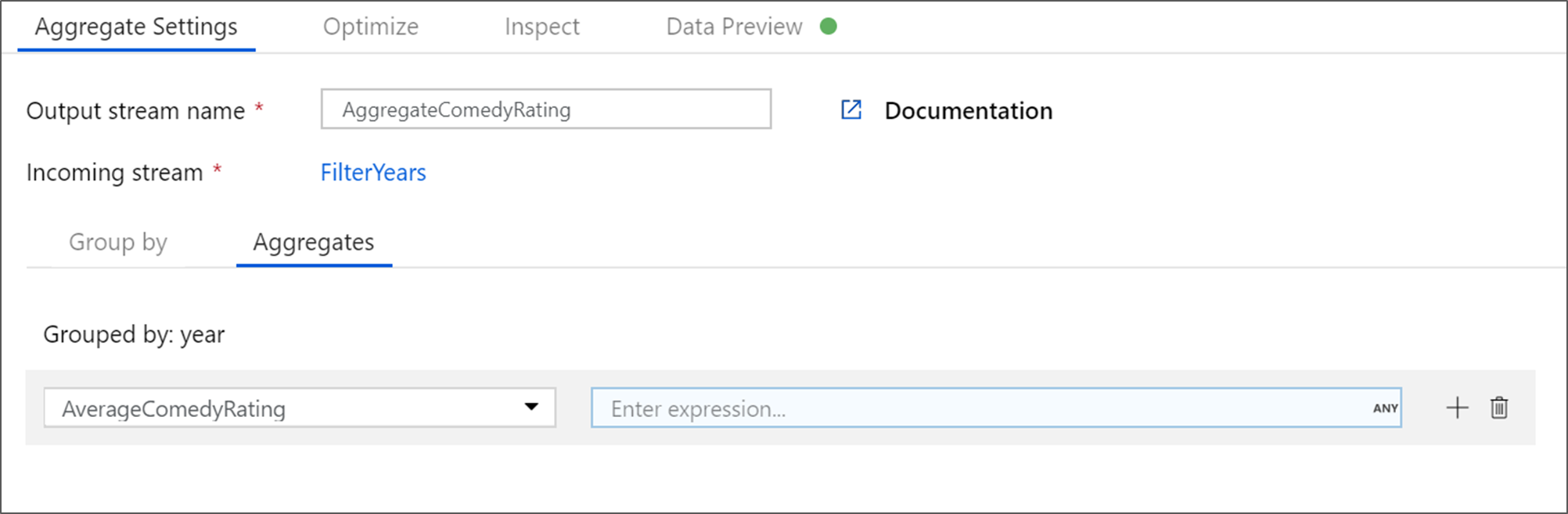
Per ottenere la media della colonna Valutazione, usare la funzione di aggregazione
avg(). Poiché Valutazione è una stringa eavg()accetta un input numerico, è necessario convertire il valore in un numero tramite la funzionetoInteger(). L'espressione è simile alla seguente:avg(toInteger(Rating))Al termine, fare clic su Salva e fine.

Andare alla scheda Anteprima dati per visualizzare l'output della trasformazione. Si noti che sono presenti solo due colonne, anno e AverageComedyRating.
Successivamente, si desidera aggiungere una trasformazione Sink in Destinazione.
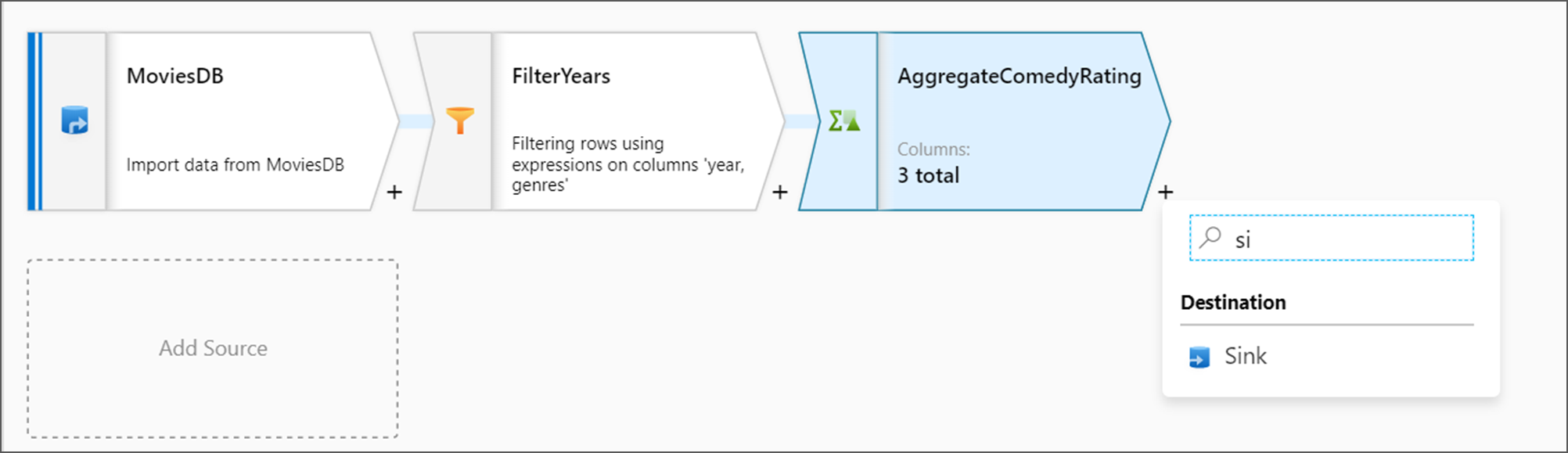
Denominare il sink Sink. Fare clic su Nuovo per creare il set di dati del sink.
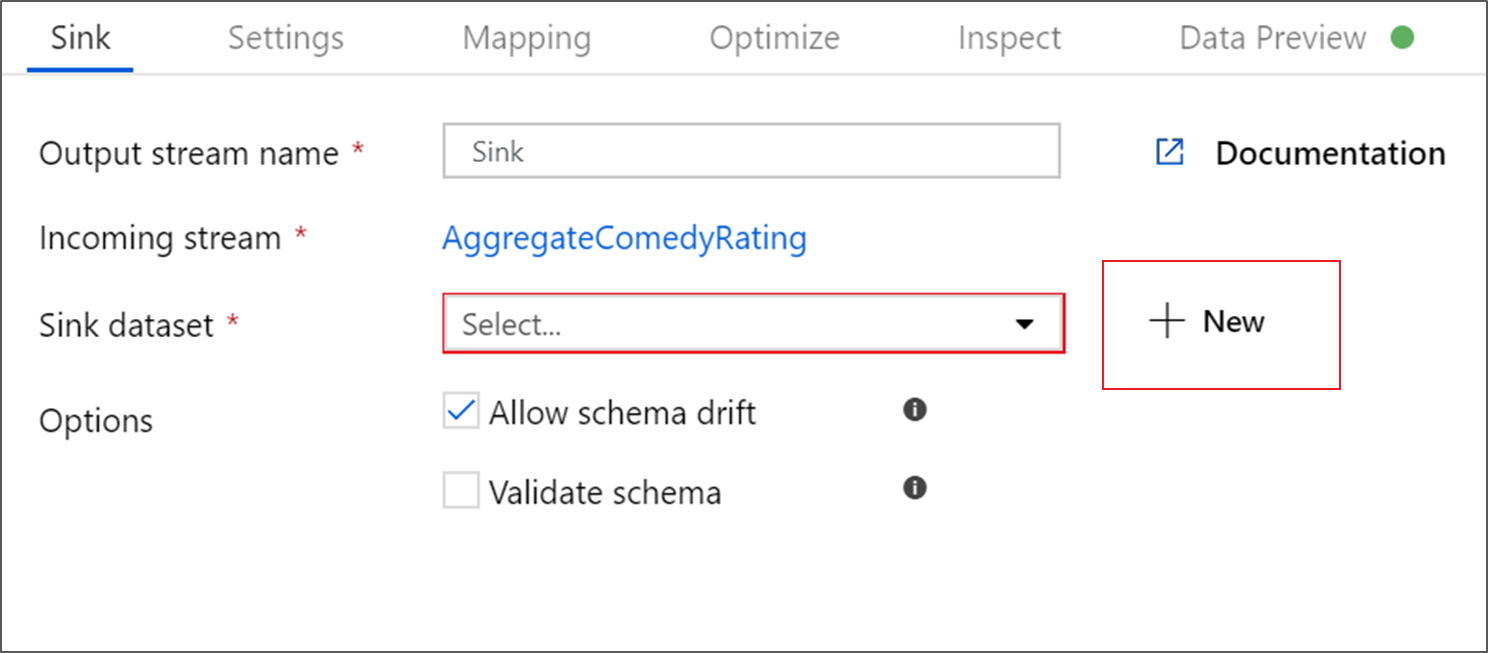
Selezionare Azure Data Lake Storage Gen2. Fare clic su Continua.
Scegliere DelimitedText. Fare clic su Continua.
Denominare il set di dati del sink MoviesSink. Per il servizio collegato, scegliere il servizio collegato ADLS Gen2 creato nel passaggio 6. Immettere una cartella di output in cui scrivere i dati. In questa esercitazione si sta scrivendo nella cartella 'output' nel contenitore 'sample-data'. Non occorre che la cartella esista in anticipo ed è possibile crearla dinamicamente. Impostare Prima riga come intestazione su true e selezionare Nessuno per Importa schema. Fare clic su Fine.
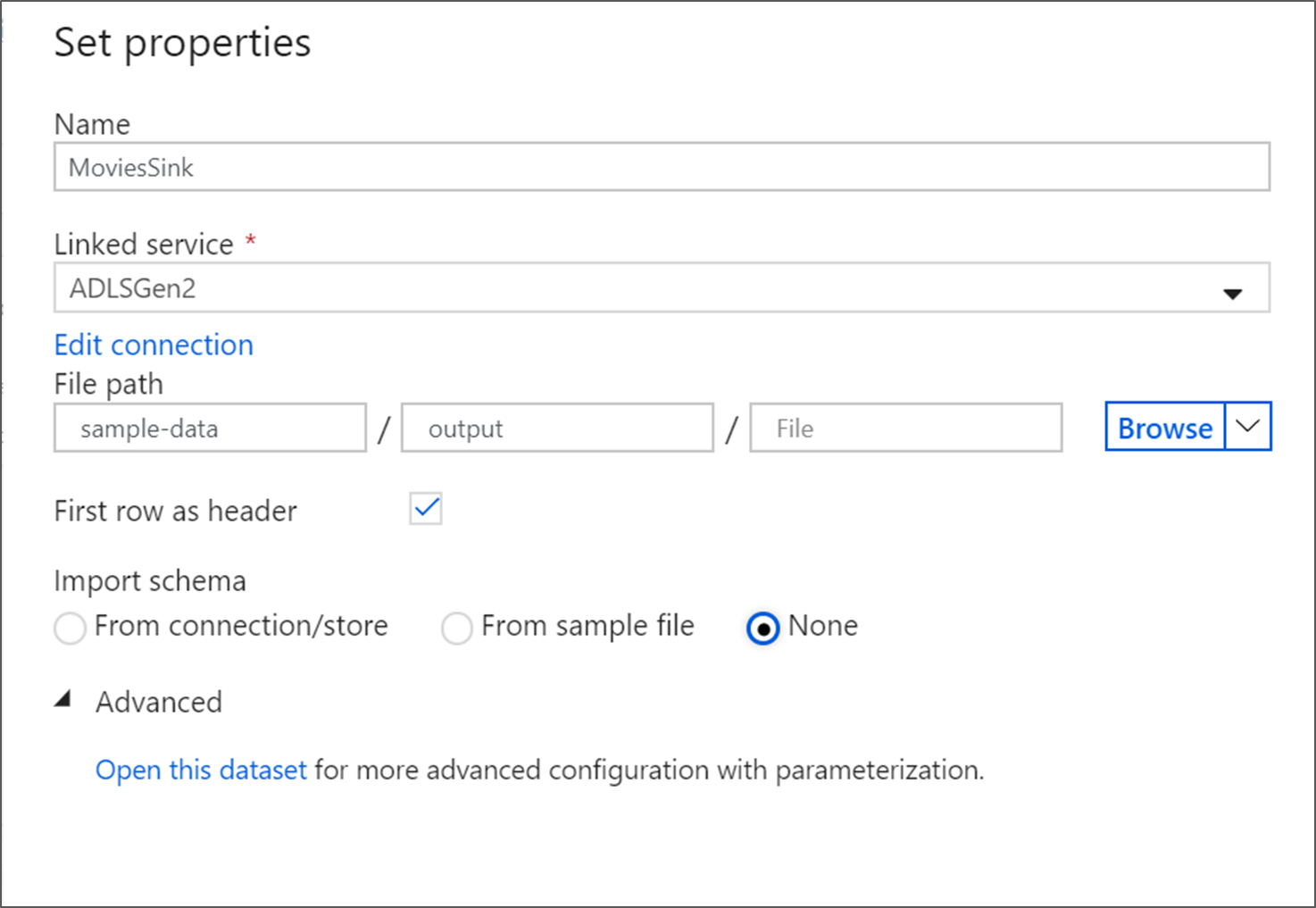
A questo punto la compilazione del flusso di dati è giunta al termine. È possibile eseguirlo nella pipeline.
Esecuzione e monitoraggio del flusso di dati
È possibile eseguire il debug di una pipeline prima di pubblicarla. In questo passaggio si attiverà un'esecuzione di debug della pipeline del flusso di dati. Mentre l'anteprima dei dati non scrive dati, un'esecuzione di debug scriverà i dati nella destinazione del sink.
Andare al canvas della pipeline. Fare clic su Debug per attivare un'esecuzione di debug.
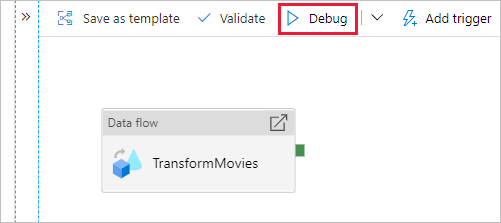
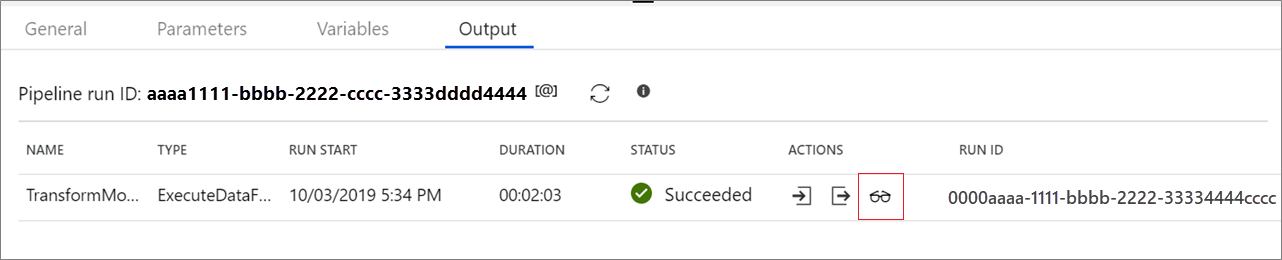
Il debug della pipeline delle attività Flusso di dati usa il cluster di debug attivo; tuttavia, la sua inizializzazione impiega almeno un minuto. È possibile tenere traccia dello stato di avanzamento tramite la scheda Output. Al termine dell'esecuzione, fare clic sull'icona a forma di occhiali per aprire il riquadro di monitoraggio.
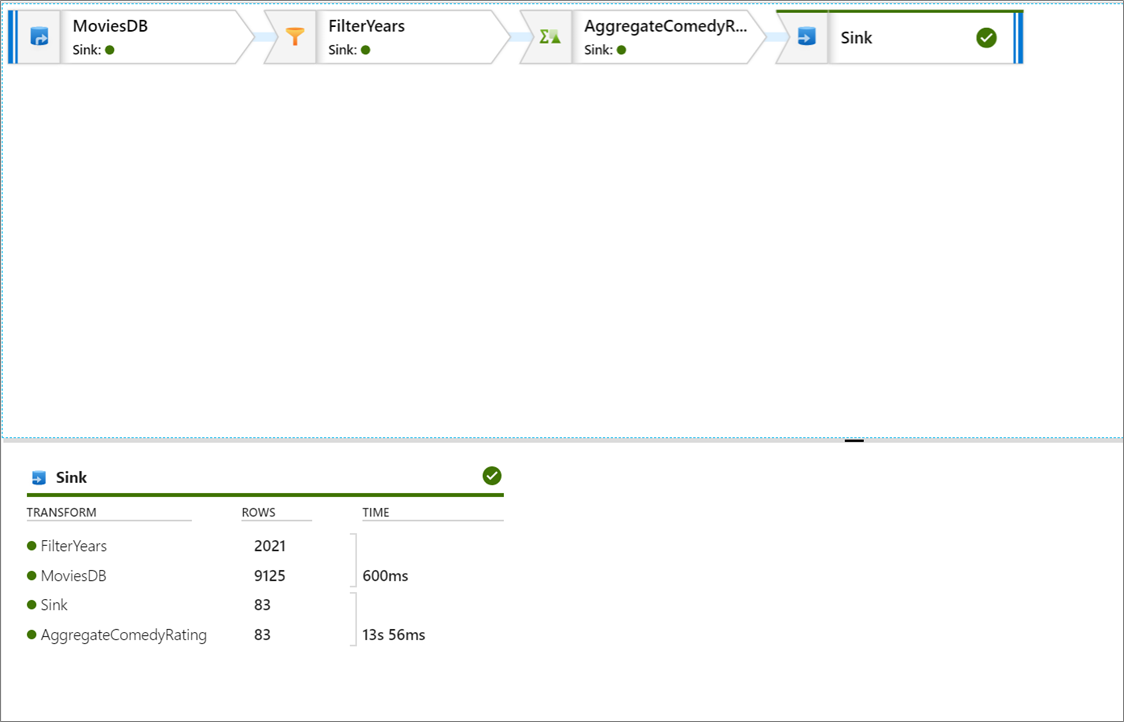
Nel riquadro di monitoraggio è possibile visualizzare il numero di righe e il tempo impiegato in ogni passaggio di trasformazione.
Fare clic su una trasformazione per ottenere informazioni dettagliate sulle colonne e sul partizionamento dei dati.
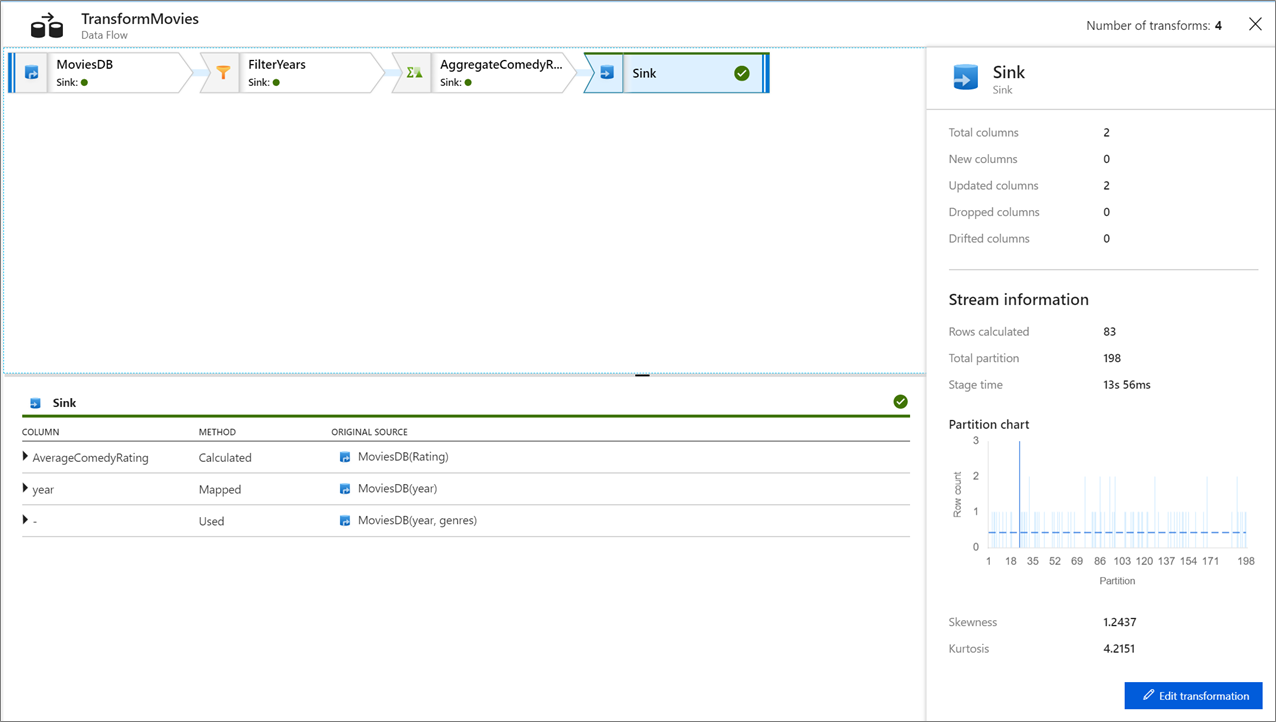
Se questa esercitazione è stata seguita correttamente, è necessario scrivere 83 righe e 2 colonne nella cartella sink. È possibile verificare che i dati siano corretti controllando l'archiviazione BLOB.
Contenuto correlato
La pipeline in questa esercitazione esegue un flusso di dati che aggrega la classificazione media delle comedies dal 1910 al 2000 e scrive i dati in ADLS. Contenuto del modulo:
- Creare una data factory.
- Creare una pipeline con un'attività di Flusso di dati.
- Creare un flusso di dati di mapping con quattro trasformazioni.
- Eseguire test della pipeline.
- Monitorare un’attività di flusso di dati
Altre informazioni sul Linguaggio delle espressioni del flusso di dati.