Selezionare la trasformazione nel flusso di dati di mapping
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
I flussi di dati sono disponibili nelle pipeline sia di Azure Data Factory che di Azure Synapse. Questo articolo si applica ai flussi di dati per mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati con un flusso di dati per mapping.
Usare la trasformazione select per rinominare, eliminare o riordinare le colonne. Questa trasformazione non modifica i dati delle righe, ma sceglie le colonne propagate a valle.
In una trasformazione selezionata gli utenti possono specificare mapping fissi, usare i modelli per eseguire il mapping basato su regole o abilitare il mapping automatico. I mapping fissi e basati su regole possono essere usati entrambi all'interno della stessa trasformazione di selezione. Se una colonna non corrisponde a uno dei mapping definiti, verrà eliminata.
Mapping fisso
Se nella proiezione sono definite meno di 50 colonne, per impostazione predefinita tutte le colonne definite avranno un mapping fisso. Un mapping fisso accetta una colonna definita, in ingresso e ne esegue il mapping con un nome esatto.
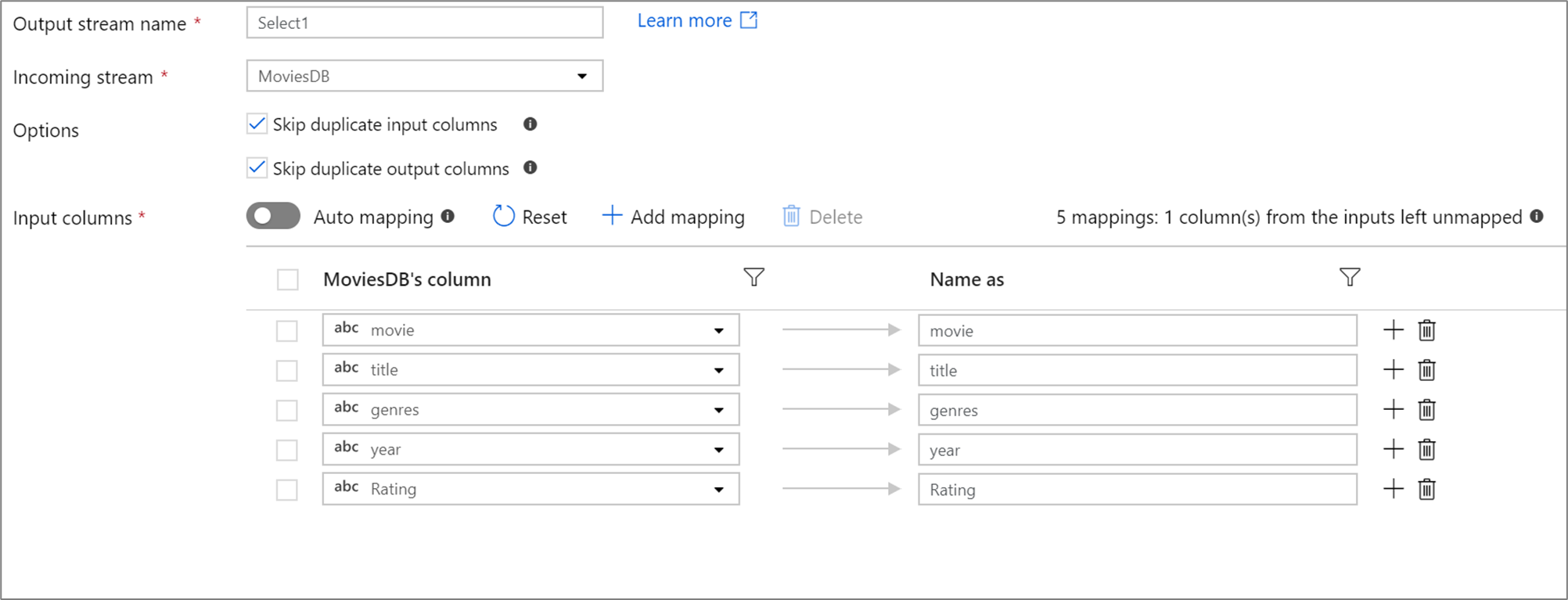
Nota
Non è possibile eseguire il mapping o rinominare una colonna derivata usando un mapping fisso
Mapping di colonne gerarchica
I mapping fissi possono essere usati per eseguire il mapping di una sottocolonna di una colonna gerarchica a una colonna di primo livello. Se si dispone di una gerarchia definita, usare l'elenco a discesa della colonna per selezionare una sottocolumina. La trasformazione select creerà una nuova colonna con il valore e il tipo di dati del sottocolume.
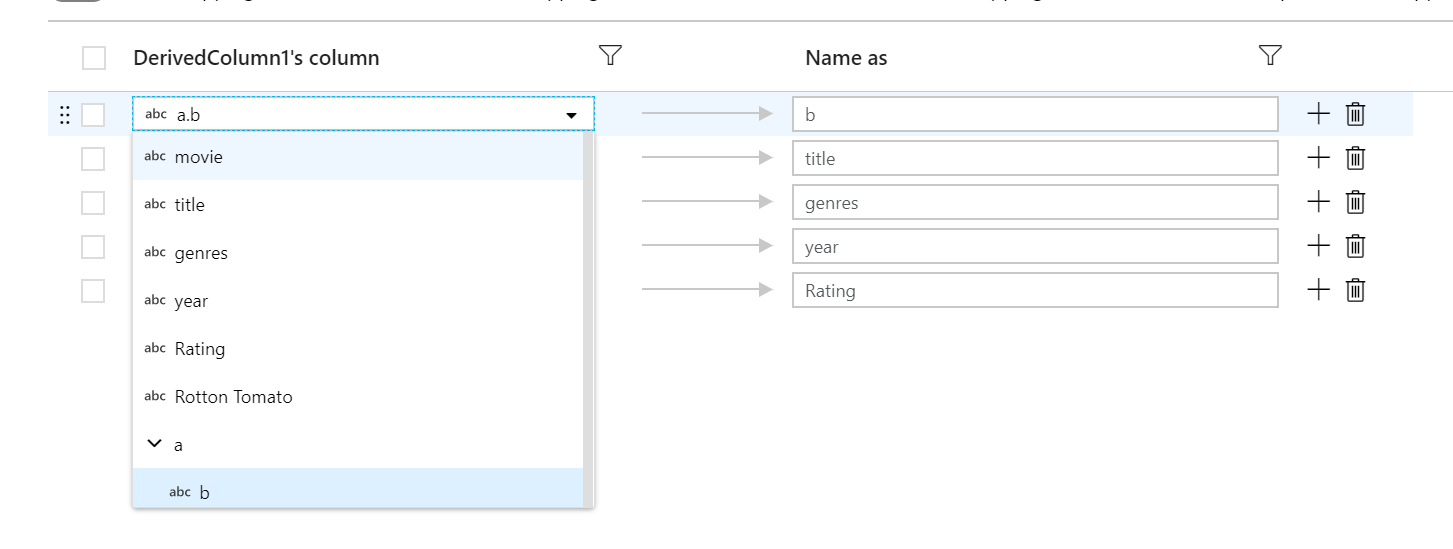
mapping basato su regole
Se si desidera eseguire il mapping di più colonne contemporaneamente o passare colonne a valle, usare il mapping basato su regole per definire i mapping usando i modelli di colonna. Trovare la corrispondenza in base alle namecolonne , typestream, e position . È possibile avere qualsiasi combinazione di mapping fissi e basati su regole. Per impostazione predefinita, tutte le proiezioni con più di 50 colonne avranno come impostazione predefinita un mapping basato su regole che corrisponde a ogni colonna e restituisce il nome immesso.
Per aggiungere un mapping basato su regole, fare clic su Aggiungi mapping e selezionare Mapping basato su regole.

Ogni mapping basato su regole richiede due input: la condizione in base alla quale trovare la corrispondenza e il nome di ogni colonna mappata. Entrambi i valori vengono inseriti tramite il generatore di espressioni. Nella casella dell'espressione a sinistra immettere la condizione di corrispondenza booleana. Nella casella dell'espressione destra specificare a quale colonna corrispondente verrà eseguito il mapping.

Usare $$ la sintassi per fare riferimento al nome di input di una colonna corrispondente. Usando l'immagine precedente come esempio, si supponga che un utente voglia trovare una corrispondenza in tutte le colonne stringa i cui nomi sono più brevi di sei caratteri. Se una colonna in ingresso è denominata test, l'espressione $$ + '_short' rinomina la colonna test_short. Se si tratta dell'unico mapping esistente, tutte le colonne che non soddisfano la condizione verranno eliminate dai dati restituiti.
I criteri corrispondono sia alle colonne deviate che alle colonne definite. Per visualizzare le colonne definite mappate da una regola, fare clic sull'icona degli occhiali accanto alla regola. Verificare l'output usando l'anteprima dei dati.
Mapping regex
Se si fa clic sull'icona della freccia verso il basso, è possibile specificare una condizione di mapping regex. Una condizione di mapping regex corrisponde a tutti i nomi di colonna che corrispondono alla condizione regex specificata. Può essere usato in combinazione con i mapping standard basati su regole.

L'esempio precedente corrisponde al modello (r) regex o a qualsiasi nome di colonna contenente un valore r minuscolo. Analogamente al mapping standard basato su regole, tutte le colonne corrispondenti vengono modificate dalla condizione a destra usando $$ la sintassi.
Se sono presenti più corrispondenze regex nel nome della colonna, è possibile fare riferimento a corrispondenze specifiche usando $n dove 'n' fa riferimento a quale corrispondenza. Ad esempio, '$2' fa riferimento alla seconda corrispondenza all'interno di un nome di colonna.
Gerarchie basate su regole
Se la proiezione definita ha una gerarchia, è possibile usare il mapping basato su regole per eseguire il mapping delle sottocolume delle gerarchie. Specificare una condizione di corrispondenza e la colonna complessa di cui si desidera eseguire il mapping. Ogni sottocolume corrispondente verrà restituito usando la regola 'Name as' specificata a destra.
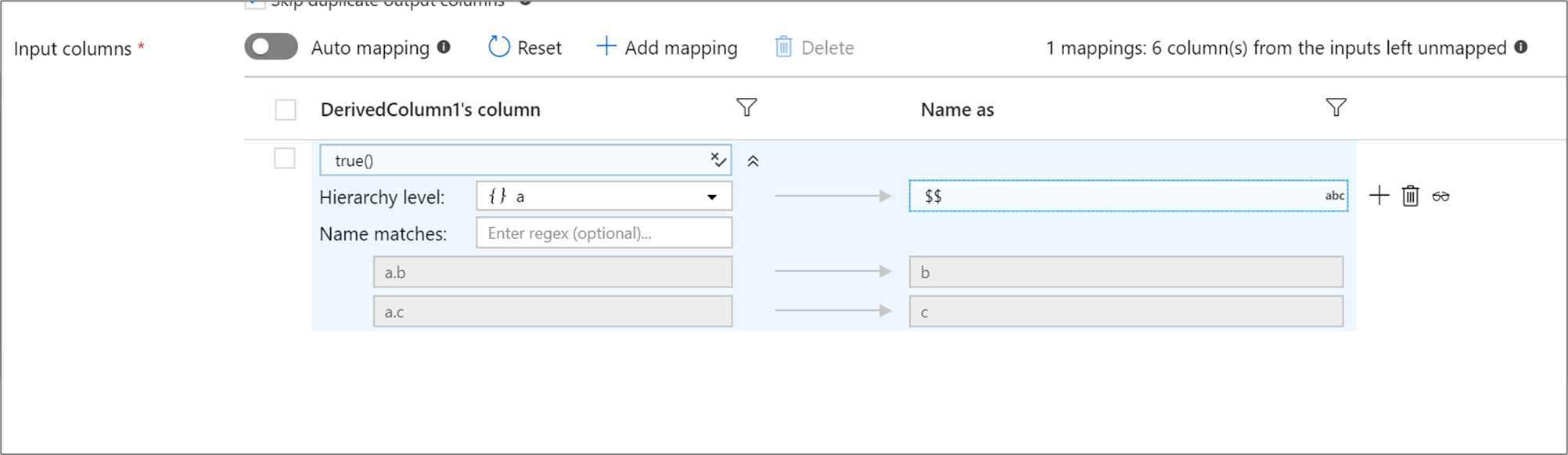
L'esempio precedente corrisponde a tutte le sottocolonne della colonna acomplessa . a contiene due sottocolumni b e c. Lo schema di output includerà due colonne b e c come condizione 'Name as' è $$.
Parametrizzazione
È possibile parametrizzare i nomi delle colonne usando il mapping basato su regole. Usare la parola chiave name per trovare la corrispondenza con i nomi delle colonne in ingresso rispetto a un parametro. Ad esempio, se si dispone di un parametro mycolumnflusso di dati , è possibile creare una regola che corrisponda a qualsiasi nome di colonna uguale a mycolumn. È possibile rinominare la colonna corrispondente in una stringa hardcoded, ad esempio "chiave business" e farvi riferimento in modo esplicito. In questo esempio la condizione di corrispondenza è name == $mycolumn e la condizione del nome è "chiave business".
Mapping automatico
Quando si aggiunge una trasformazione di selezione, è possibile abilitare il mapping automatico cambiando il dispositivo di scorrimento Mapping automatico. Con il mapping automatico, la trasformazione select esegue il mapping di tutte le colonne in ingresso, escluse le colonne duplicate, con lo stesso nome dell'input. Verranno incluse le colonne deviate, ovvero i dati di output potrebbero contenere colonne non definite nello schema. Per altre informazioni sulle colonne deviate, vedere Deviazione dello schema.
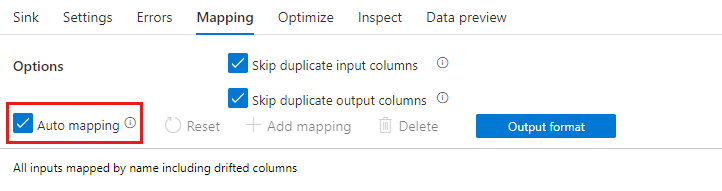
Con il mapping automatico attivato, la trasformazione select rispetta le impostazioni duplicate e fornisce un nuovo alias per le colonne esistenti. L'aliasing è utile quando si eseguono più join o ricerche nello stesso flusso e in scenari di self-join.
Colonne duplicate
Per impostazione predefinita, la trasformazione select elimina le colonne duplicate sia nella proiezione di input che in quella di output. Le colonne di input duplicate provengono spesso da trasformazioni join e ricerca in cui i nomi delle colonne vengono duplicati in ogni lato del join. Le colonne di output duplicate possono verificarsi se si esegue il mapping di due colonne di input diverse allo stesso nome. Scegliere se eliminare o passare colonne duplicate attivando o disattivando la casella di controllo.
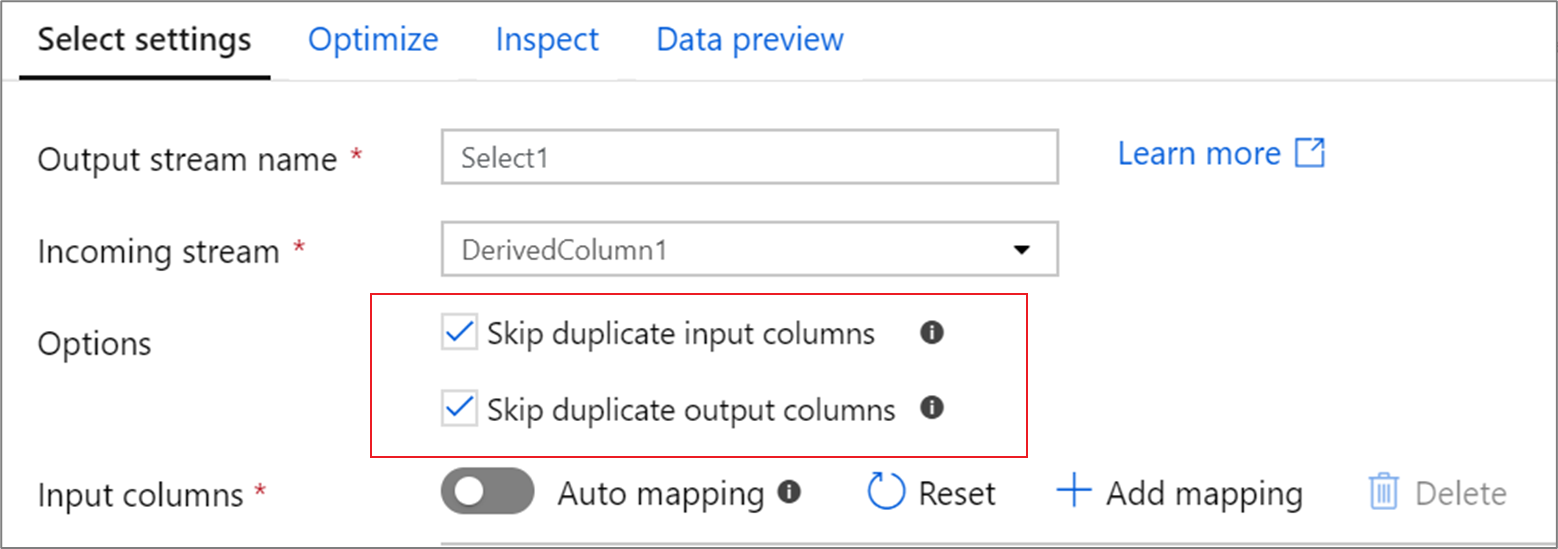
Ordinamento delle colonne
L'ordine dei mapping determina l'ordine delle colonne di output. Se viene eseguito più volte il mapping di una colonna di input, verrà rispettato solo il primo mapping. Per l'eliminazione di qualsiasi colonna duplicata, verrà mantenuta la prima corrispondenza.
Script del flusso di dati
Sintassi
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
Esempio
Di seguito è riportato un esempio di mapping di selezione e del relativo script del flusso di dati:
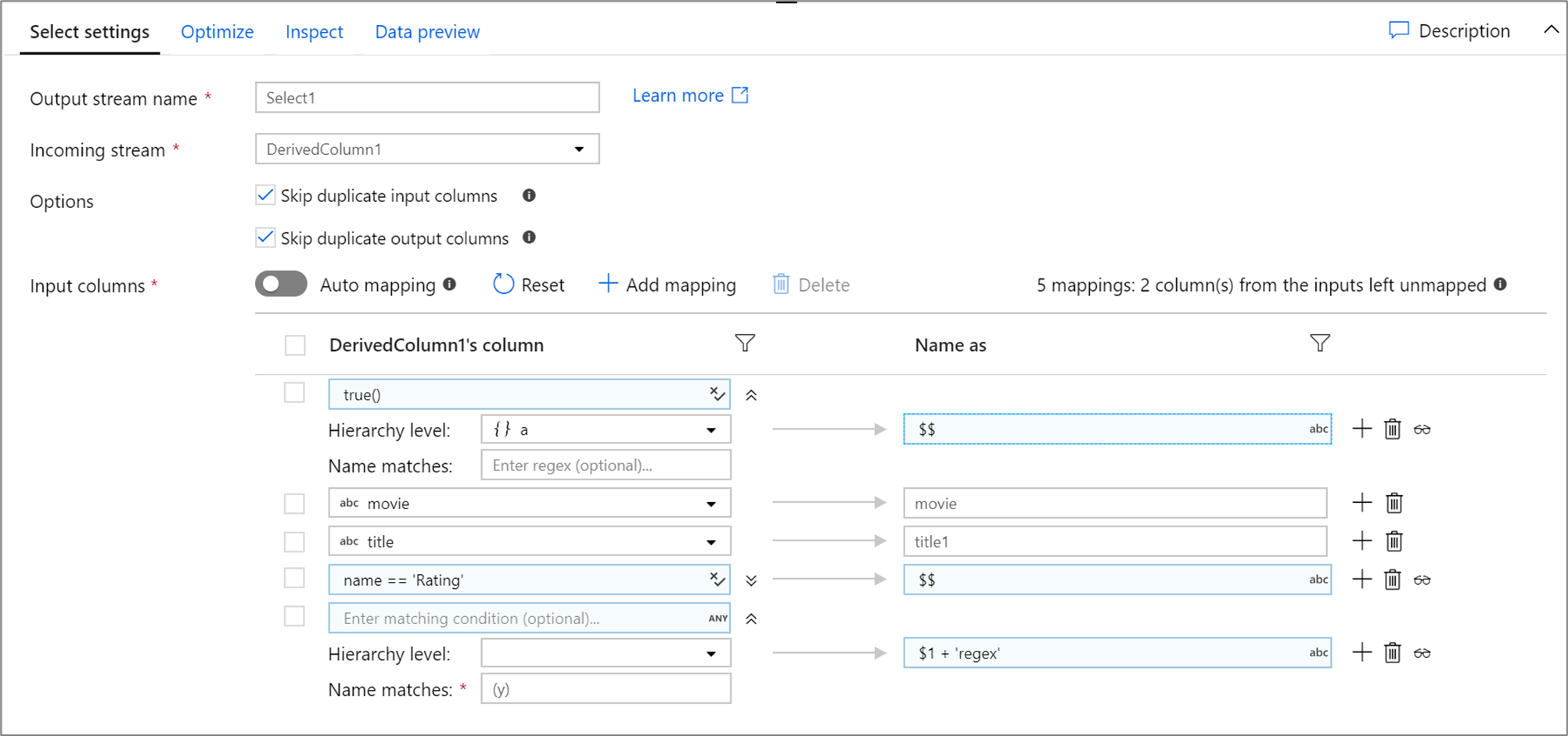
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
Contenuto correlato
- Dopo aver usato Select per rinominare, riordinare e alias le colonne, usare la trasformazione Sink per trasferire i dati in un archivio dati.