Trasformazione Assert nel flusso di dati di mapping
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
I flussi di dati sono disponibili nelle pipeline sia di Azure Data Factory che di Azure Synapse. Questo articolo si applica ai flussi di dati per mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati con un flusso di dati per mapping.
La trasformazione Assert consente di creare regole personalizzate all'interno dei flussi di dati di mapping per la qualità dei dati e la convalida dei dati. È possibile compilare regole che determinano se i valori soddisfano un dominio di valori previsti. Inoltre, è possibile compilare regole che controllano l'univocità delle righe. La trasformazione Assert consente di determinare se ogni riga nei dati soddisfa un set di criteri. La trasformazione Assert consente anche di impostare messaggi di errore personalizzati quando le regole di convalida dei dati non vengono soddisfatte.
Impostazione
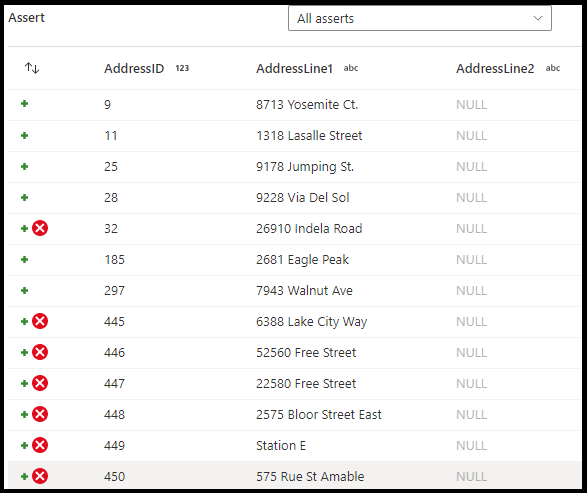
Nel pannello di configurazione della trasformazione asserzione si sceglie il tipo di asserzione, si specifica un nome univoco per l'asserzione, la descrizione facoltativa e si definiscono l'espressione e il filtro facoltativo. Il riquadro anteprima dati indica quali righe hanno avuto esito negativo nelle asserzioni. Inoltre, è possibile testare ogni tag di riga downstream usando isError() e hasError() per le righe che hanno avuto esito negativo.
Tipo asserzione
- Previsto true: il risultato dell'espressione deve restituire un risultato booleano true. Usare questa impostazione per convalidare gli intervalli di valori di dominio nei dati.
- Previsto univoco: impostare una colonna o un'espressione come regola di univocità nei dati. Usare questa impostazione per contrassegnare le righe duplicate.
- Previsto esistente: questa opzione è disponibile solo quando è stato selezionato un secondo flusso in ingresso. Exists esamina entrambi i flussi e determina se le righe esistono in entrambi i flussi in base alle colonne o alle espressioni specificate. Per aggiungere il secondo flusso per exists, selezionare
Additional streams.
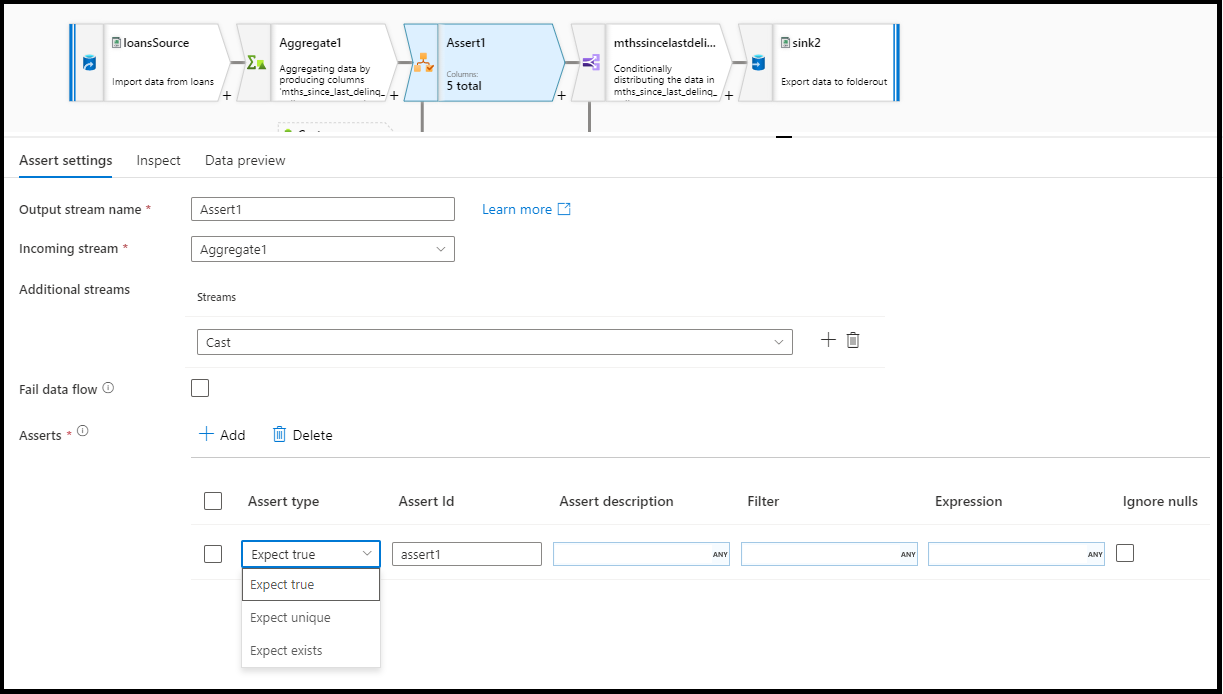
Flusso di dati non riuscita
Selezionare fail data flow se si vuole che l'attività del flusso di dati abbia esito negativo immediatamente non appena la regola di asserzione ha esito negativo.
ID asserzione
Assert ID è una proprietà in cui immettere un nome (stringa) per l'asserzione. È possibile usare l'identificatore in un secondo momento downstream nel flusso di dati usando hasError() o per restituire il codice di errore dell'asserzione. Gli ID assert devono essere univoci all'interno di ogni flusso di dati.
Descrizione asserzione
Immettere una descrizione stringa per l'asserzione qui. Qui è anche possibile usare espressioni e valori di colonna del contesto di riga.
Filtro
Filter è una proprietà facoltativa in cui è possibile filtrare l'asserzione in modo che solo un subset di righe in base al valore dell'espressione.
Espressione
Immettere un'espressione per la valutazione per ognuna delle asserzioni. È possibile avere più asserzioni per ogni trasformazione asserzione. Ogni tipo di asserzione richiede un'espressione che ADF deve valutare per verificare se l'asserzione è stata superata.
Ignora valori NULL
Per impostazione predefinita, la trasformazione assert include valori NULL nella valutazione dell'asserzione di riga. È possibile scegliere di ignorare i valori NULL con questa proprietà.
Errori di riga di asserzione diretta
Quando un'asserzione non riesce, è possibile indirizzare facoltativamente tali righe di errore a un file in Azure usando la scheda "Errori" nella trasformazione sink. È anche possibile scegliere nella trasformazione sink di non restituire righe con errori di asserzione ignorando le righe di errore.
Esempi
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Script del flusso di dati
Esempi
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1
Contenuto correlato
- Usare la trasformazione Seleziona per selezionare e convalidare le colonne.
- Utilizzare la trasformazione Colonna derivata per trasformare i valori delle colonne.