Suggerimenti sulle prestazioni per Azure Cosmos DB Java SDK v4
SI APPLICA A: ![]() NoSQL
NoSQL
Importante
I suggerimenti sulle prestazioni riportati in questo articolo riguardano esclusivamente Azure Cosmos DB Java SDK v4. Per altre informazioni, vedere le note sulla versione di Azure Cosmos DB Java SDK v4, il repository Maven e la guida alla risoluzione dei problemi di Azure Cosmos DB Java SDK v4. Se attualmente si usa una versione precedente a v4, vedere l'articolo Eseguire la migrazione a Java SDK v4 per Azure Cosmos DB per informazioni sull'aggiornamento a v4.
Azure Cosmos DB è un database distribuito veloce e flessibile, facilmente scalabile e con latenza e velocità effettiva garantite. Non è necessario apportare modifiche significative all'architettura o scrivere codice complesso per ridimensionare il database con Azure Cosmos DB. Aumentare o ridurre le prestazioni è semplice come eseguire una singola chiamata API o una chiamata al metodo SDK. Tuttavia, dato che si accede ad Azure Cosmos DB tramite chiamate di rete, è possibile introdurre ottimizzazioni sul lato client per ottenere massime prestazioni durante l'uso di Azure Cosmos DB Java SDK v4.
Se si vogliono migliorare le prestazioni del database, valutare le opzioni seguenti:
Rete
Collocare i client nella stessa area di Azure per ottenere prestazioni migliori
Quando possibile, posizionare eventuali applicazioni che chiamano Azure Cosmos DB nella stessa area del database Azure Cosmos DB. Per un confronto approssimativo, le chiamate ad Azure Cosmos DB eseguite nella stessa area vengono completate entro 1-2 millisecondi, mentre la latenza tra la costa occidentale e quella orientale degli Stati Uniti è >50 millisecondi. Questa latenza può variare da richiesta a richiesta, in base alla route seguita dalla richiesta durante il passaggio dal client al limite del data center di Azure. È possibile ottenere la latenza più bassa possibile assicurandosi che l'applicazione chiamante si trovi nella stessa area di Azure in cui si trova l'endpoint di Azure Cosmos DB con provisioning. Per un elenco delle aree disponibili, vedere Aree di Azure.
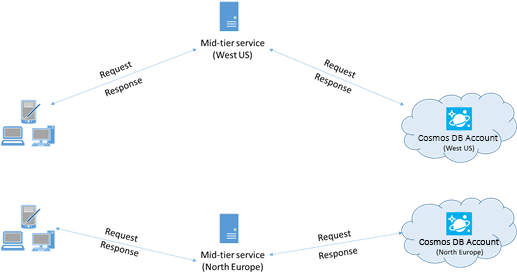
Un'app che interagisce con un account Azure Cosmos DB per più aree deve configurare località preferite per garantire che le richieste vengano inviate a un'area collocata.
Abilitare la rete accelerata per ridurre la latenza e l'instabilità della CPU
Per ottimizzare le prestazioni, riducendo la latenza e instabilità della CPU, è consigliabile seguire le istruzioni per abilitare la rete accelerata nella macchina virtuale di Azure con Windows (selezionare per istruzioni) o Linux (selezionare per istruzioni).
Senza rete accelerata, le operazioni di IO che transitano tra la macchina virtuale di Azure e le altre risorse di Azure potrebbero essere instradate attraverso un host e un commutatore virtuale posizionato tra la macchina virtuale e la relativa scheda di rete. La presenza dell'host e del commutatore virtuale inline nel percorso dei dati non solo aumenta la latenza e l'instabilità nel canale di comunicazione, ma sottrae anche cicli della CPU alla macchina virtuale. Con la rete accelerata, la macchina virtuale si interfaccia direttamente con la scheda di interfaccia di rete senza intermediari. Tutti i dettagli dei criteri di rete vengono gestiti nell'hardware nella scheda di interfaccia di rete, ignorando l'host e il commutatore virtuale. Quando si abilita la rete accelerata, è in genere possibile prevedere una latenza più bassa e una velocità effettiva più elevata, oltre a una maggiore latenza coerente e a un minore utilizzo della CPU.
Limitazioni: la rete accelerata deve essere supportata nel sistema operativo della macchina virtuale e può essere abilitata solo quando la macchina virtuale viene arrestata e deallocata. La macchina virtuale non può essere distribuita con Azure Resource Manager. Servizio app non ha alcuna rete accelerata abilitata.
Per altre informazioni, vedere le istruzioni di Windows e Linux.
Disponibilità elevata
Per indicazioni generali sulla configurazione della disponibilità elevata in Azure Cosmos DB, vedere Disponibilità elevata in Azure Cosmos DB.
Oltre a una buona configurazione di base della piattaforma di database, esistono tecniche specifiche che possono essere implementate nell'SDK Java stesso, che possono essere utili in scenari di interruzione. Due strategie rilevanti sono la strategia di disponibilità basata su soglia e l'interruttore a livello di partizione.
Queste tecniche forniscono meccanismi avanzati per risolvere problemi di latenza e disponibilità specifici, andando oltre le funzionalità di ripetizione tra aree integrate nell'SDK per impostazione predefinita. Gestendo in modo proattivo potenziali problemi a livello di richiesta e partizione, queste strategie possono migliorare significativamente la resilienza e le prestazioni dell'applicazione, in particolare in condizioni di carico elevato o danneggiato.
Strategia di disponibilità basata su soglia
La strategia di disponibilità basata su soglia può migliorare la latenza e la disponibilità della coda inviando richieste di lettura parallele alle aree secondarie e accettando la risposta più rapida. Questo approccio può ridurre drasticamente l'impatto di interruzioni a livello di area o condizioni di latenza elevata sulle prestazioni dell'applicazione. Inoltre, è possibile usare la gestione proattiva delle connessioni per migliorare ulteriormente le prestazioni riscaldando le connessioni e le cache nelle aree di lettura correnti e nelle aree remote preferite.
Configurazione di esempio:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
Funzionamento:
Prima richiesta: al momento T1, viene effettuata una richiesta di lettura all'area primaria, ad esempio Stati Uniti orientali. L'SDK attende una risposta fino a 500 millisecondi (valore
threshold).Seconda richiesta: se non è presente alcuna risposta dall'area primaria entro 500 millisecondi, viene inviata una richiesta parallela all'area preferita successiva, ad esempio Stati Uniti orientali 2.
Terza richiesta: se né l'area primaria né quella secondaria rispondono entro 600 millisecondi (500 ms + 100 ms, il valore
thresholdStep), l'SDK invia un'altra richiesta parallela alla terza area preferita, ad esempio Stati Uniti occidentali.La risposta più veloce prevale: l’area che risponde per prima viene accettata e le altre richieste parallele vengono ignorate.
La gestione proattiva delle connessioni consente di riscaldamento delle connessioni e delle cache per i contenitori tra le aree preferite, riducendo la latenza di avvio a freddo per scenari di failover o scritture in configurazioni in più aree.
Questa strategia può migliorare significativamente la latenza negli scenari in cui una determinata area è lenta o temporaneamente non disponibile, ma può comportare un costo maggiore in termini di unità richiesta quando sono necessarie richieste parallele tra aree.
Nota
Se la prima area preferita restituisce un codice di stato di errore non temporaneo, ad esempio, documento non trovato, errore di autorizzazione, conflitto e così via, l'operazione stessa avrà esito negativo rapidamente, perché la strategia di disponibilità non avrebbe alcun vantaggio in questo scenario.
Interruttore a livello di partizione
L'interruttore a livello di partizione migliora la latenza della coda e la disponibilità di scrittura monitorando e cortocircuitando le richieste alle partizioni fisiche non integre. Migliora le prestazioni evitando partizioni problematiche note e reindirizzando le richieste alle aree più integre.
Configurazione di esempio:
Per abilitare l'interruttore a livello di partizione:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
Per impostare la frequenza del processo in background per controllare le aree non disponibili:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
Per impostare la durata per cui una partizione può rimanere non disponibile:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
Funzionamento:
Errori di rilevamento: l'SDK tiene traccia degli errori del terminale, ad esempio, 503s, 500s, timeout, per singole partizioni in aree specifiche.
Contrassegno come non disponibile: se una partizione in un'area supera una soglia configurata di errori, viene contrassegnata come "Non disponibile". Le richieste successive a questa partizione sono in corto circuito e reindirizzate ad altre aree più integre.
Ripristino automatico: un thread in background controlla periodicamente le partizioni non disponibili. Dopo una determinata durata, queste partizioni vengono contrassegnate provvisoriamente come "Tentativo integro" e sottoposte a richieste di test per convalidare il ripristino.
Innalzamento/abbassamento di livello dell'integrità: in base all'esito positivo o negativo di queste richieste di test, lo stato della partizione viene promosso di nuovo a "Integro" o abbassato nuovamente su "Non disponibile".
Questo meccanismo consente di monitorare continuamente l'integrità delle partizioni e di garantire che le richieste vengano gestite con latenza minima e la massima disponibilità, senza essere limitati da partizioni problematiche.
Nota
L'interruttore si applica solo agli account di scrittura in più aree, come quando una partizione viene contrassegnata come Unavailable, sia le operazioni di lettura sia di scrittura vengono spostate nell'area preferita successiva. Ciò consente di impedire letture e scritture da aree diverse gestite dalla stessa istanza client, in quanto si tratta di un anti-pattern.
Importante
Per attivare l'interruttore a livello di partizione, è necessario usare la versione 4.63.0 di Java SDK o versione successiva.
Confronto delle ottimizzazioni della disponibilità
Strategia di disponibilità basata su soglia:
- Vantaggio: riduce la latenza della coda inviando richieste di lettura parallele alle aree secondarie e migliorando la disponibilità tramite richieste di pre-svuotamento che comportano timeout di rete.
- Compromesso: comporta costi aggiuntivi di UR (unità richiesta) rispetto all'interruttore, a causa di richieste parallele aggiuntive tra aree (anche se solo durante i periodi in cui le soglie vengono superate).
- Casi d'uso: ottimale per i carichi di lavoro con utilizzo elevato di lettura in cui la riduzione della latenza è critica e un costo aggiuntivo, sia in termini di carico UR sia di utilizzo della CPU client, è accettabile. Le operazioni di scrittura possono anche trarre vantaggio, se si è scelto di usare criteri di ripetizione dei tentativi di scrittura non idempotent e l'account dispone di scritture in più aree.
Interruttore a livello di partizione:
- Vantaggi: migliora la disponibilità e la latenza evitando partizioni non integre, assicurando che le richieste vengano instradate alle aree più integre.
- Compromesso: non comporta costi aggiuntivi per le UR, ma può comunque consentire una perdita di disponibilità iniziale per le richieste che genereranno timeout di rete.
- Casi d'uso: ideale per carichi di lavoro con operazioni di scrittura o miste in cui le prestazioni coerenti sono essenziali, soprattutto quando vengono gestite partizioni che possono diventare non integre a intermittenza.
Entrambe le strategie possono essere usate insieme per migliorare la disponibilità di lettura e scrittura e ridurre la latenza della coda. L'interruttore a livello di partizione può gestire un'ampia gamma di scenari di errore temporanei, tra cui quelli che possono comportare repliche a prestazioni lente, senza la necessità di eseguire richieste parallele. Inoltre, l'aggiunta della strategia di disponibilità basata su soglia ridurrà ulteriormente la latenza della coda ed eliminerà la perdita di disponibilità, se è accettabile un costo aggiuntivo per le UR.
Implementando queste strategie, gli sviluppatori possono garantire che le applicazioni rimangano resilienti, mantengano prestazioni elevate e forniscano un'esperienza utente migliore anche durante interruzioni a livello di area o condizioni di latenza elevata.
Coerenza della sessione con ambito area
Panoramica
Per altre informazioni sulle impostazioni di coerenza in generale, vedere Livelli di coerenza in Azure Cosmos DB. Java SDK offre un'ottimizzazione per la coerenza delle sessioni per gli account di scrittura in più aree, consentendo di definire l'ambito dell'area. Ciò migliora le prestazioni attenuando la latenza di replica tra aree riducendo al minimo i tentativi lato client. Questa operazione viene ottenuta gestendo i token di sessione a livello di area anziché a livello globale. Se l'ambito della coerenza nell'applicazione può essere limitato a un numero inferiore di aree, implementando la coerenza della sessione con ambito di area, è possibile ottenere prestazioni e affidabilità migliori per le operazioni di lettura e scrittura in account con più scritture riducendo al minimo i ritardi e i tentativi di replica tra aree.
Vantaggi
- Riduzione della latenza: localizzando la convalida del token di sessione a livello di area, le probabilità di tentativi tra aree più costose vengono ridotte.
- Prestazioni migliorate: riduce al minimo l'impatto del failover e del ritardo di replica a livello di area, offrendo maggiore coerenza di lettura/scrittura e un utilizzo inferiore della CPU.
- Utilizzo ottimizzato delle risorse: riduce il sovraccarico della CPU e della rete nelle applicazioni client limitando la necessità di tentativi e chiamate tra aree, ottimizzando così l'utilizzo delle risorse.
- Disponibilità elevata: mantenendo i token di sessione con ambito di area, le applicazioni possono continuare a funzionare senza problemi anche se determinate aree riscontrano una latenza o errori temporanei più elevati.
- Garanzie di coerenza: garantisce che la coerenza della sessione, ovvero lettura della scrittura e lettura monotonica, venga soddisfatta in modo più affidabile senza tentativi non necessari.
- Efficienza dei costi: riduce il numero di chiamate tra aree, riducendo in tal modo i costi associati ai trasferimenti di dati tra aree.
- Scalabilità: consente alle applicazioni di ridimensionare in modo più efficiente riducendo i conflitti e il sovraccarico associati alla gestione di un token di sessione globale, in particolare nelle configurazioni in più aree.
Compromessi
- Maggiore utilizzo della memoria: il filtro bloom e l'archiviazione del token di sessione specifica dell'area richiedono una memoria aggiuntiva, che può essere una considerazione per le applicazioni con risorse limitate.
- Complessità della configurazione: ottimizzare il numero di inserimenti previsto e la frequenza di falsi positivi per il filtro bloom aggiunge un livello di complessità al processo di configurazione.
- Potenziale per i falsi positivi: mentre il filtro Bloom riduce al minimo i tentativi tra aree, esiste ancora una leggera probabilità di falsi positivi che influiscano sulla convalida del token di sessione, anche se la frequenza può essere controllata. Un falso positivo indica che il token di sessione globale viene risolto, aumentando così la probabilità di nuovi tentativi tra aree se l'area locale non è stata rilevata in questa sessione globale. Le garanzie di sessione vengono soddisfatte anche in presenza di falsi positivi.
- Applicabilità: questa funzionalità è più utile per le applicazioni con una cardinalità elevata di partizioni logiche e riavvii regolari. Le applicazioni con meno partizioni logiche o riavvii non frequenti potrebbero non visualizzare vantaggi significativi.
Funzionamento
Impostare il token di sessione
- Completamento richiesta: al termine di una richiesta, l'SDK acquisisce il token di sessione e lo associa all'area e alla chiave di partizione.
- Archiviazione a livello di area: i token di sessione vengono archiviati in un
ConcurrentHashMapannidato che gestisce i mapping tra intervalli di chiavi di partizione e avanzamento a livello di area. - Filtro Bloom: un filtro Bloom tiene traccia delle aree a cui è stato eseguito l'accesso da ogni partizione logica, consentendo di localizzare la convalida del token di sessione.
Risolvere il token di sessione
- Inizializzazione richiesta: prima dell'invio di una richiesta, l'SDK tenta di risolvere il token di sessione per l'area appropriata.
- Controllo dei token: il token viene controllato rispetto ai dati specifici dell'area per assicurarsi che la richiesta venga instradata alla replica più aggiornata.
- Logica di ripetizione dei tentativi: se il token di sessione non viene convalidato all'interno dell'area corrente, l'SDK esegue nuovi tentativi con altre aree, ma data l'archiviazione localizzata, questa operazione è meno frequente.
Usare l'SDK
Ecco come inizializzare CosmosClient con coerenza della sessione con ambito di area:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
Abilitare la coerenza della sessione con ambito di area
Per abilitare l'acquisizione di sessioni con ambito di area nell'applicazione, impostare la proprietà di sistema seguente:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
Configurare il filtro Bloom
Ottimizzare le prestazioni configurando gli inserimenti previsti e il tasso di falsi positivi per il filtro Bloom:
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
Implicazioni relative alla memoria
Di seguito sono riportate le dimensioni mantenute (dimensioni dell'oggetto e qualsiasi cosa dipende) del contenitore di sessione interno (gestito dall'SDK) con inserimenti previsti variabili nel filtro Bloom.
| Inserimenti previsti | Tasso di falsi positivi | Dimensioni conservate |
|---|---|---|
| 10.000 | 0,001 | 21 KB |
| 100.000 | 0,001 | 183 KB |
| 1 milione | 0,001 | 1,8 MB |
| 10 milioni | 0,001 | 17,9 MB |
| 100 milioni | 0,001 | 179 MB |
| 1 miliardo | 0,001 | 1,8 GB |
Importante
Per attivare la coerenza della sessione con ambito di area, è necessario usare la versione 4.60.0 di Java SDK o versione successiva.
Ottimizzazione della configurazione della connessione diretta e gateway
Per ottimizzare le configurazioni di connessione in modalità diretta e gateway, vedere come ottimizzare le configurazioni di connessione per Java SDK v4.
Uso dell'SDK
- Installare l'SDK più recente
Agli SDK di Azure Cosmos DB vengono apportati continui miglioramenti per offrire prestazioni ottimali. Per determinare i miglioramenti più recenti di SDK, visitare Azure Cosmos DB SDK.
Ogni istanza del client Azure Cosmos DB è thread-safe ed esegue la gestione efficiente delle connessioni e la memorizzazione nella cache degli indirizzi. Per consentire una gestione efficiente delle connessioni e prestazioni migliori dal client Azure Cosmos DB, è consigliabile usare una singola istanza del client Azure Cosmos DB per la durata dell'applicazione.
Quando si crea un CosmosClient, la coerenza predefinita usata, se non impostata in modo esplicito, è Session. Se la coerenza Session non è richiesta dalla logica dell'applicazione, impostare Consistency su Eventual. Nota: è consigliabile impostare almeno la coerenza Session nelle applicazioni che usano il processore del feed di modifiche di Azure Cosmos DB.
- Usare l'API Async per la massima velocità effettiva di cui viene effettuato il provisioning
Azure Cosmos DB Java SDK v4 include due API, Sync e Async. In linea generale, l'API Async implementa la funzionalità dell'SDK, mentre l'API Sync è un thin wrapper che blocca le chiamate all'API Async. Questo approccio è in contrasto con le versioni precedenti dell'SDK, ovvero Azure Cosmos DB Async Java SDK v2, che era solo asincrono, e Azure Cosmos DB Sync Java SDK v2, che era solo sincrono e aveva un'implementazione separata.
La scelta dell'API viene determinata durante l'inizializzazione del client. CosmosAsyncClient supporta l'API Async, mentre CosmosClient supporta l'API Sync.
L'API Async implementa l'I/O non bloccante ed è la scelta ottimale se l'obiettivo è massimizzare la velocità effettiva quando vengono inviate richieste ad Azure Cosmos DB.
L'uso dell'API Sync può essere la scelta ottimale se si vuole o se è necessaria un'API che si blocchi in risposta a ogni richiesta o se il funzionamento sincrono costituisce il paradigma dominante nell'applicazione. Può ad esempio essere opportuno usare l'API Sync quando si salvano in modo permanente i dati di Azure Cosmos DB in un'applicazione di microservizi, purché la velocità effettiva non sia fondamentale.
Notare che la velocità effettiva dell'API Sync peggiora con tempi crescenti di risposta alla richiesta, mentre l'API Async può saturare l'intera capacità di larghezza di banda dell'hardware.
La collocazione geografica può offrire una velocità effettiva più elevata e coerente quando si usa l'API Sync (vedere Collocare i client nella stessa area di Azure per ottenere migliori prestazioni), ma non si prevede ancora di superare la velocità effettiva ottenibile dall'API Async.
Alcuni utenti potrebbero anche non avere familiarità con Project Reactor, il framework dei flussi reattivi usato per implementare l'API Async di Azure Cosmos DB Java SDK v4. Se questo rappresenta un problema, è consigliabile leggere la guida introduttiva ai modelli di Reactor e quindi esaminare l'introduzione alla programmazione reattiva per acquisire familiarità con questi concetti. Se si è già usato Azure Cosmos DB con un'interfaccia asincrona e l'SDK usato era Azure Cosmos DB Async Java SDK v2, è possibile che si abbia già familiarità con ReactiveX/RxJava ma non si sappia esattamente cosa è cambiato in Project Reactor. In tal caso, consultare l'articolo sul confronto dei framework Reactor. e RxJava per informazioni al riguardo.
I frammenti di codice seguenti mostrano come inizializzare il client di Azure Cosmos DB rispettivamente per il funzionamento dell'API Async o dell'API Sync:
API asincrona Java SDK V4 (Maven com.azure::azure-cosmos)
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Aumentare il carico di lavoro client
Se si sta eseguendo il test a livelli di velocità effettiva elevati, l'applicazione client può diventare un collo di bottiglia a causa della limitazione di uso della CPU o della rete. In questo caso, è possibile continuare a effettuare il push dell'account Azure Cosmos DB aumentando il numero di istanze delle applicazioni client in più server.
Una regola empirica efficace è quella di non superare del valore >50% l'utilizzo della CPU su un determinato server, per mantenere bassa la latenza.
- Usare l'utilità di pianificazione appropriata (evitare l'acquisizione di thread Netty di I/O EventLoop)
La funzionalità asincrona di Azure Cosmos DB Java SDK si basa sull'I/O non bloccante Netty. L'SDK usa un numero fisso di thread Netty di I/O EventLoop (corrispondente al numero di core della CPU del computer) per l'esecuzione di operazioni di I/O. La sequenza Flux restituita dall'API genera il risultato in uno dei thread Netty di I/O EventLoop condiviso. Per questo motivo è importante non bloccare i thread Netty di I/O EventLoop condivisi. L'esecuzione di operazioni con utilizzo intensivo della CPU oppure di operazioni di blocco sul thread Netty di I/O EventLoop può causare deadlock o ridurre in modo significativo la velocità effettiva dell'SDK.
Ad esempio il codice seguente esegue un'operazione con utilizzo intensivo della CPU sul thread Netty di I/O EventLoop:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
Dopo aver ricevuto il risultato, è consigliabile evitare di eseguire operazioni con un utilizzo intensivo della CPU sul risultato nel thread Netty di I/O del ciclo di eventi. In alternativa, è possibile specificare la propria utilità di pianificazione per fornire il proprio thread per l'esecuzione del lavoro, come mostrato di seguito (import reactor.core.scheduler.Schedulers necessario).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
In base al tipo di lavoro è necessario usare l'utilità di pianificazione Reactor esistente appropriata. Per altre informazioni, vedere qui Schedulers.
Per altre informazioni sul modello di threading e pianificazione del progetto Reactor, fare riferimento a questo post di blog di Project Reactor.
Per altre informazioni su Azure Cosmos DB Java SDK v4, vedere la directory Azure Cosmos DB del mono repository di Azure SDK per Java su GitHub.
- Ottimizzare le impostazioni di registrazione nell'applicazione
Per vari motivi, è necessario aggiungere la registrazione in un thread che genera una velocità effettiva elevata delle richieste. Se l'obiettivo è quello di saturare completamente, con le richieste generate da questo thread, la velocità effettiva di un contenitore di cui viene effettuato il provisioning, le ottimizzazioni della registrazione possono migliorare significativamente le prestazioni.
- Configurare un logger asincrono
La latenza di un logger sincrono implica necessariamente il calcolo della latenza complessiva del thread che genera richieste. È consigliabile un logger asincrono, ad esempio log4j2, per separare l'overhead di registrazione dai thread dell'applicazione a prestazioni elevate.
- Disabilitare la registrazione di Netty
La registrazione della libreria Netty è molto dettagliata e deve essere disattivata (la soppressione dell'accesso alla configurazione potrebbe non essere sufficiente) per evitare costi aggiuntivi di CPU. Se non si è in modalità di debug, disabilitare del tutto la registrazione di Netty. Pertanto, se si usa Log4j per evitare i costi della CPU aggiuntivi causati da org.apache.log4j.Category.callAppenders() da Netty aggiungere la riga seguente alla codebase:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- Limite di risorse per i file aperti del sistema operativo
Alcuni sistemi Linux (ad esempio Red Hat) prevedono un limite massimo per il numero di file aperti e quindi per il numero totale di connessioni. Eseguire il comando seguente per visualizzare i limiti correnti:
ulimit -a
Il numero di file aperti (nofile) deve essere sufficientemente grande da disporre di spazio sufficiente per le dimensioni del pool di connessioni configurate e per altri file aperti dal sistema operativo. Può essere modificato per consentire dimensioni del pool di connessioni più grandi.
Aprire il file limits.conf:
vim /etc/security/limits.conf
Aggiungere/modificare le righe seguenti:
* - nofile 100000
- Specificare la chiave della partizione nelle scritture di punti
Per migliorare le prestazioni delle scritture di punti, specificare la chiave della partizione dell'elemento nella chiamata all'API per le scritture di punti, come mostrato di seguito:
API asincrona Java SDK V4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
Anziché fornire solo l'istanza dell'elemento, come mostrato di seguito:
API asincrona Java SDK V4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item).block();
Quest'ultima è supportata, ma aggiungerà latenza all'applicazione. L'SDK deve analizzare l'elemento ed estrarre la chiave della partizione.
Operazioni di query
Per le operazioni di query, vedere i suggerimenti sulle prestazioni per le query.
Criteri di indicizzazione
- Escludere i percorsi non usati dall'indicizzazione per scritture più veloci
I criteri di indicizzazione di Azure Cosmos DB consentono di specificare i percorsi dei documenti da includere o escludere dall'indicizzazione usando i percorsi di indicizzazione (setIncludedPaths e setExcludedPaths). L'uso dei percorsi di indicizzazione può consentire di ottenere prestazioni migliori e di ridurre le risorse di archiviazione dell'indice per gli scenari in cui i modelli di query sono noti in anticipo, poiché i costi dell'indicizzazione sono correlati direttamente al numero di percorsi univoci indicizzati. Il codice seguente, ad esempio, mostra come includere ed escludere dall'indicizzazione intere sezioni dei documenti (note anche come sottoalbero) usando il carattere jolly "*".
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
Per altre informazioni, vedere l'articolo relativo ai criteri di indicizzazione di Azure Cosmos DB.
Velocità effettiva
- Misurare e ottimizzare per ottenere un utilizzo minore di unità richiesta al secondo
Azure Cosmos DB offre un'ampia gamma di operazioni di database, incluse le query relazionali e gerarchiche con funzioni definite dall'utente, stored procedure e trigger, operative nei documenti in una raccolta di database. Il costo associato a ognuna di queste operazioni dipende da CPU, I/O e memoria necessari per il completamento dell'operazione. Invece di occuparsi della pianificazione e della gestione delle risorse hardware, sarà possibile usare un'unità di richiesta come misura singola per le risorse necessarie per eseguire diverse operazioni di database e rispondere a una richiesta dell'applicazione.
Viene eseguito il provisioning della velocità effettiva in base al numero di unità richiesta impostato per ogni contenitore. Il consumo delle unità di richiesta è valutato in base alla frequenza al secondo. Le applicazioni che superano la frequenza di unità richiesta con provisioning previsto per il contenitore sono limitate fino al ritorno della frequenza sotto il valore riservato per il contenitore. Se l'applicazione necessita di un livello superiore di velocità effettiva, sarà possibile aumentare la velocità effettiva eseguendo il provisioning di unità di richiesta aggiuntive.
La complessità di una query influisce sulla quantità di unità richiesta usate per un'operazione. Il numero di predicati, la natura dei predicati, il numero di funzioni definite dall'utente e le dimensioni del set di dati di origine sono tutti fattori che incidono sul costo delle operazioni di query.
Per misurare l'overhead di qualsiasi operazione (create, update o delete), esaminare l'intestazione x-ms-request-charge per determinare il numero di unità richiesta usate da queste operazioni. È anche possibile esaminare la proprietà RequestCharge equivalente in ResourceResponse<T> o FeedResponse<T>.
API asincrona Java SDK V4 (Maven com.azure::azure-cosmos)
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
L'addebito richiesta restituito in questa intestazione è una frazione della velocità effettiva con provisioning. Se, ad esempio, sono presenti 2000 UR/secondo e se la query precedente restituisce 1000 documenti da 1 KB, il costo dell'operazione è 1000. Entro un secondo, il server rispetterà quindi solo due richieste di questo tipo prima di limitare la velocità delle richieste successive. Per altre informazioni, vedere Unità richiesta e il calcolatore di unità richiesta.
- Gestire la limitazione della frequenza o una frequenza di richieste troppo elevata
Quando un client prova a superare la velocità effettiva riservata per un account, non si verifica alcun calo delle prestazioni del server e l'uso della capacità della velocità effettiva non supera il livello riservato. Il server termina preventivamente la richiesta con RequestRateTooLarge (codice di stato HTTP 429) e restituisce l'intestazione x-ms-retry-after-ms, che indica la quantità di tempo, in millisecondi, che l'utente deve attendere prima di eseguire di nuovo la richiesta.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Tutti gli SDK intercettano implicitamente questa risposta, rispettano l'intestazione retry-after specificata dal server e ripetono la richiesta. A meno che all'account non accedano contemporaneamente più client, il tentativo successivo riuscirà.
Se più client operano cumulativamente in modo costante al di sopra della frequenza delle richieste, il numero di ripetizioni dei tentativi predefinito attualmente impostato su 9 internamente dal client potrebbe non essere sufficiente. In questo caso, il client genererà un'eccezione CosmosClientException con codice di stato 429 per l'applicazione. Il numero di tentativi predefinito può essere modificato usando setMaxRetryAttemptsOnThrottledRequests() nell'istanza di ThrottlingRetryOptions . Per impostazione predefinita, l'eccezione CosmosClientException con codice di stato 429 viene restituita dopo un tempo di attesa cumulativo di 30 secondi, se la richiesta continua a funzionare al di sopra della frequenza delle richieste. Ciò si verifica anche quando il numero di ripetizioni dei tentativi corrente è inferiore al numero massimo di tentativi, indipendentemente dal fatto che si tratti del valore predefinito 9 o di un valore definito dall'utente.
Benché il comportamento automatizzato per la ripetizione dei tentativi consenta di migliorare la resilienza e l'usabilità per la maggior parte delle applicazioni, è possibile che provochi conflitti durante l'esecuzione dei benchmark delle prestazioni, in particolare durante la misurazione della latenza. La latenza osservata dal client presenterà dei picchi se l'esperimento raggiunge il limite del server e fa in modo che l'SDK client ripeta automaticamente i tentativi. Per evitare i picchi di latenza durante gli esperimenti relativi alle prestazioni, misurare l'addebito restituito da ogni operazione e assicurarsi che le richieste operino al di sotto della frequenza delle richieste riservata. Per altre informazioni, vedere Unità richiesta.
- Progettare documenti di dimensioni minori per ottenere una velocità effettiva maggiore
L'addebito per le richieste, ovvero il costo di elaborazione delle richieste, per un'operazione specifica è correlato direttamente alle dimensioni del documento. Le operazioni sui documenti di grandi dimensioni sono più costose rispetto alle operazioni per i documenti di piccole dimensioni. In teoria, l'applicazione e i flussi di lavoro devono essere progettati in modo che la dimensione dell'elemento sia pari a ~1 KB o di un ordine di grandezza simile. Per le applicazioni sensibili alla latenza è consigliabile evitare elementi di grandi dimensioni. I documenti di più MB rallentano l'applicazione.
Passaggi successivi
Per altre informazioni sulla progettazione dell'applicazione per scalabilità e prestazioni elevate, vedere l'articolo relativo a partizionamento e ridimensionamento in Azure Cosmos DB.
Si sta tentando di pianificare la capacità per una migrazione ad Azure Cosmos DB? È possibile usare le informazioni del cluster di database esistente per la pianificazione della capacità.
- Se si conosce solo il numero di vCore e server nel cluster di database esistente, leggere le informazioni sulla stima delle unità richieste con vCore o vCPU
- Se si conosce la frequenza delle richieste tipiche per il carico di lavoro corrente del database, leggere le informazioni sulla stima delle unità richieste con lo strumento di pianificazione della capacità di Azure Cosmos DB