Partizionamento e scalabilità orizzontale in Azure Cosmos DB
SI APPLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabella
Tabella
Azure Cosmos DB usa il partizionamento per dimensionare singoli contenitori in un database al fine di soddisfare le esigenze dell'applicazione in termini di prestazioni. Gli elementi in un contenitore sono suddivisi in sottoinsiemi distinti denominati partizioni logiche. Le partizioni logiche vengono formate in base al valore di una chiave di partizione associata a ogni elemento in un contenitore. Tutti gli elementi in una partizione logica hanno lo stesso valore di chiave di partizione.
Ad esempio, un contenitore contiene elementi. A ogni elemento è associato un valore univoco per la proprietà UserID. Se UserID funge da chiave di partizione per gli elementi in un contenitore e se sono presenti 1.000 valori UserID univoci, vengono create 1.000 partizioni logiche per il contenitore.
Oltre a una chiave di partizione che determina la partizione logica dell'elemento, ogni elemento in un contenitore ha un ID elemento (univoco all'interno di una partizione logica). La combinazione di chiave di partizione e ID elemento crea l'indice dell'elemento, che identifica l'elemento in modo univoco. La scelta di una chiave di partizione è una decisione importante che influisce sulle prestazioni dell'applicazione.
Questo articolo illustra la relazione tra partizioni logiche e fisiche. Illustra anche le procedure consigliate per il partizionamento e offre una panoramica approfondita del funzionamento del ridimensionamento orizzontale in Azure Cosmos DB. Non è necessario comprendere questi dettagli interni per selezionare la chiave di partizione, ma sono illustrati in modo da fornire maggiore chiarezza sul funzionamento di Azure Cosmos DB.
Partizioni logiche
Una partizione logica è costituita da un set di elementi che hanno la stessa chiave di partizione. Ad esempio, in un contenitore che contiene dati sull'alimentazione, tutti gli elementi contengono una proprietà foodGroup. È possibile usare foodGroup come chiave di partizione per il contenitore. I gruppi di elementi con valori specifici per foodGroup, ad esempio Beef Products, Baked Products e Sausages and Luncheon Meats, formano partizioni logiche distinte.
Una partizione logica definisce anche l'ambito delle transazioni di database. È possibile aggiornare gli elementi all'interno di una partizione logica tramite una transazione con isolamento dello snapshot. Quando vengono aggiunti nuovi elementi a un contenitore, il sistema crea nuove partizioni logiche in modo trasparente. Non è necessario preoccuparsi di eliminare una partizione logica quando i dati sottostanti vengono eliminati.
Non esiste alcun limite al numero di partizioni logiche nel contenitore. Ogni partizione logica può archiviare fino a 20 GB di dati. È possibile scegliere una buona chiave di partizione tra un'ampia gamma di possibili valori. Ad esempio, in un contenitore in cui tutti gli elementi contengono una proprietà foodGroup, i dati all'interno della partizione logica Beef Products possono aumentare fino a 20 GB. La selezione di una chiave di partizione tra un'ampia gamma di valori possibili garantisce che il contenitore sia in grado di effettuare il dimensionamento.
È possibile usare gli avvisi di Monitoraggio di Azure per monitorare se le dimensioni di una partizione logica si avvicinano a 20 GB.
Partizioni fisiche
Un contenitore viene dimensionato distribuendo dati e velocità effettiva tra partizioni fisiche. Internamente, una o più partizioni logiche vengono associate a una singola partizione fisica. In genere i contenitori più piccoli includono molte partizioni logiche, ma richiedono solo una singola partizione fisica. A differenza delle partizioni logiche, le partizioni fisiche sono un'implementazione interna del sistema, e sono interamente gestite da e Azure Cosmos DB.
Il numero di partizioni fisiche nel contenitore dipende dalle caratteristiche seguenti:
Valore di velocità effettiva con provisioning (ogni singola partizione fisica può fornire una velocità effettiva fino a 10.000 unità richiesta al secondo). Il limite di 10.000 UR/s per le partizioni fisiche implica che anche le partizioni logiche prevedono un limite di 10.000 UR/s, dal momento che ogni partizione logica viene associata a una sola partizione fisica.
L'archiviazione totale dei dati (ogni singola partizione fisica può archiviare fino a 50 GB di dati).
Nota
Le partizioni fisiche sono un'implementazione interna del sistema e sono interamente gestite da Azure Cosmos DB. Durante lo sviluppo delle soluzioni, non è necessario concentrarsi sulle partizioni fisiche perché non è possibile controllarle, ma ci si deve concentrare sulle chiavi di partizione. Se si sceglie una chiave di partizione che distribuisce in modo uniforme l'utilizzo della velocità effettiva tra partizioni logiche, si garantisce che l'utilizzo della velocità effettiva tra partizioni fisiche sia bilanciato.
Non esiste alcun limite al numero totale di partizioni fisiche nel contenitore. Man mano che la velocità effettiva o le dimensioni dei dati di cui è stato effettuato il provisioning aumentano, Azure Cosmos DB crea automaticamente nuove partizioni fisiche dividendo quelle esistenti. Le divisioni delle partizioni fisiche non influiscono sulla disponibilità dell'applicazione. Dopo la divisione della partizione fisica, tutti i dati all'interno di una singola partizione logica verranno comunque archiviati nella stessa partizione fisica. Una divisione di partizione fisica crea semplicemente un nuovo mapping di partizioni logiche a partizioni fisiche.
La velocità effettiva di cui è stato effettuato il provisioning per un contenitore è divisa in modo uniforme tra le partizioni fisiche. Quando una chiave di partizione non distribuisce le richieste in modo uniforme, è possibile che un numero eccessivo di richieste indirizzate a un piccolo subset di partizioni diventino "ad accesso frequente". Le partizioni ad accesso frequente comportano un uso inefficiente della velocità effettiva di cui è stato effettuato il provisioning, che potrebbe comportare una limitazione della velocità e un incremento dei costi.
Si consideri ad esempio un contenitore con il percorso /foodGroup specificato come chiave di partizione. Il contenitore potrebbe avere un numero qualsiasi di partizioni fisiche, ma in questo esempio si presupporrà che ne abbia tre. Una singola partizione fisica può contenere più chiavi di partizione. Ad esempio, la partizione fisica più grande può contenere le prime tre partizioni logiche di dimensioni maggiori: Beef Products, Vegetable and Vegetable Products e Soups, Sauces, and Gravies.
Se si assegna una velocità effettiva di 18.000 unità richiesta al secondo (UR/sec), ognuna delle tre partizioni fisiche può usare 1/3 della velocità effettiva totale con provisioning. All'interno della partizione fisica selezionata, le chiavi di partizione logica Beef Products, Vegetable and Vegetable Products e Soups, Sauces, and Gravies possono usare collettivamente le 6.000 UR/sec della partizione fisica di cui è stato effettuato il provisioning. Poiché la velocità effettiva con provisioning è divisa uniformemente tra le partizioni fisiche del contenitore, è importante scegliere una chiave di partizione che distribuisca in modo uniforme il consumo di velocità effettiva. Per ulteriori informazioni, vedere Scelta della chiave di partizione logica corretta.
Gestione delle partizioni logiche
Azure Cosmos DB gestisce il posizionamento delle partizioni logiche su partizioni fisiche (infrastruttura server) in modo trasparente e automatico per soddisfare in modo efficiente le esigenze di scalabilità e di prestazione del contenitore. Con l'aumento dei requisiti di archiviazione e di velocità effettiva di un'applicazione, Azure Cosmos DB consente di spostare le partizioni logiche per distribuire automaticamente il carico tra un numero maggiore di server. Sono disponibili altre informazioni sulle partizioni fisiche.
Azure Cosmos DB usa il partizionamento basato su hash per distribuire le partizioni logiche tra le partizioni fisiche. Azure Cosmos DB esegue l'hash del valore della chiave di partizione di un elemento. Il risultato con hash determina la partizione logica. Quindi, Azure Cosmos DB alloca lo spazio chiave degli hash delle chiavi di partizione in modo uniforme tra le partizioni fisiche.
Le transazioni (in procedure stored o trigger) sono consentite solo sugli elementi all'interno di una singola partizione logica.
Set di repliche
Ogni partizione fisica è costituita da un set di repliche, detto anche set di repliche. Ogni replica ospita un'istanza del motore di database. Un set di repliche rende i dati archiviati nella partizione fisica durevoli, altamente disponibili e coerenti. Ogni replica che costituisce la partizione fisica eredita la quota di archiviazione della partizione. Tutte repliche di una partizione fisica supportano complessivamente la velocità effettiva allocata alla partizione stessa. Azure Cosmos DB gestisce automaticamente i set di repliche.
In genere, i contenitori più piccoli richiedono solo una partizione fisica, ma hanno comunque almeno quattro repliche.
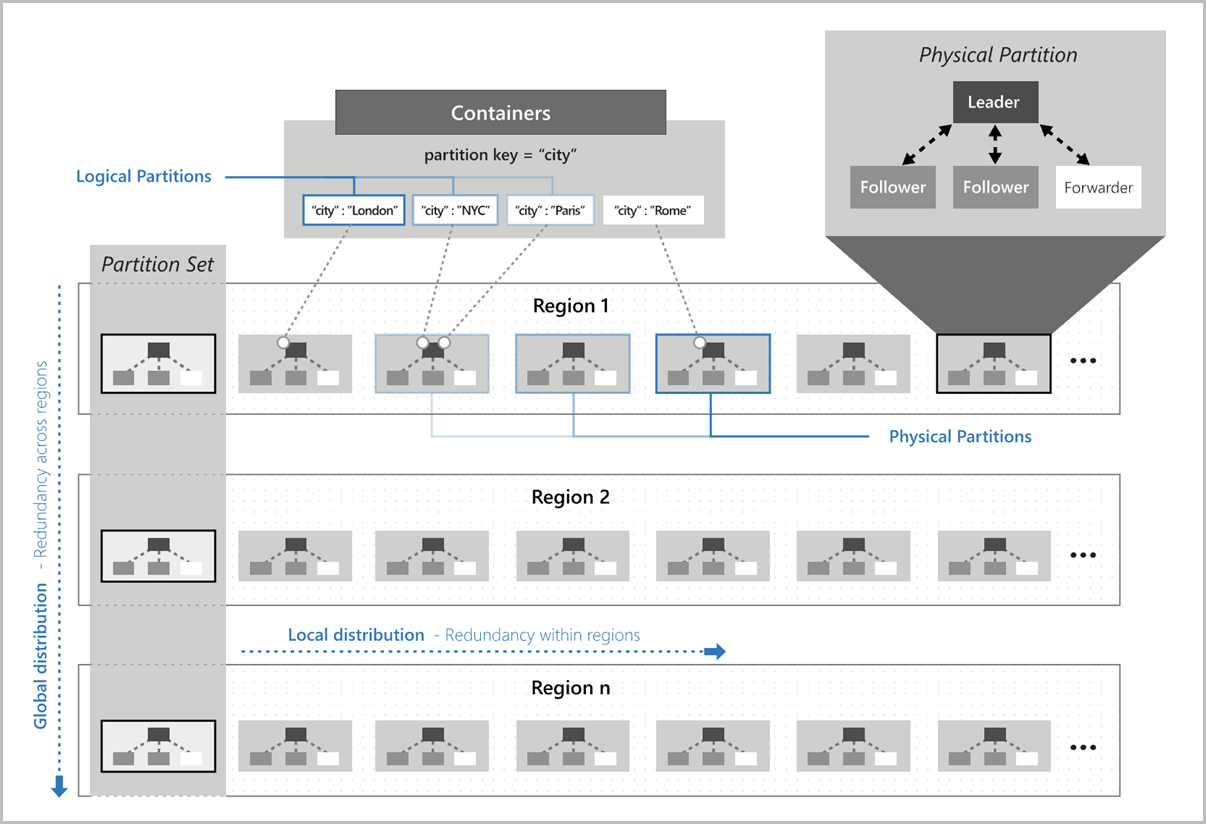
La figura seguente mostra come le partizioni logiche vengono mappate alle partizioni fisiche distribuite a livello globale: Il set di partizioni nell'immagine fa riferimento a un gruppo di partizioni fisiche che gestiscono le stesse chiavi di partizione logica in più aree:
Scegliere una chiave di partizione
Una chiave di partizione include due componenti: il percorso della chiave di partizione e il valore della chiave di partizione. Si consideri ad esempio un elemento { "userId" : "Andrew", "worksFor": "Microsoft" }. Se si sceglie "userId" come chiave di partizione, i due componenti della chiave di partizione saranno i seguenti:
Percorso della chiave di partizione (ad esempio: "/userId"). Il percorso della chiave di partizione accetta caratteri alfanumerici e caratteri trattino basso (_). È anche possibile usare oggetti annidati usando la notazione di percorso standard (/).
Valore della chiave di partizione (ad esempio: "Andrew"). Il valore della chiave di partizione può essere di tipo stringa o numerico.
Per informazioni sui limiti di velocità effettiva, archiviazione e lunghezza della chiave di partizione, vedere l'articolo Quote del servizio Azure Cosmos DB.
La selezione della chiave di partizione è una scelta di progettazione semplice ma importante in Azure Cosmos DB. Dopo aver selezionato la chiave di partizione, non è possibile modificarla sul posto. Per modificare la chiave di partizione, sarà necessario spostare i dati in un nuovo contenitore con la nuova chiave di partizione desiderata. (I Processi di copia del contenitore sono utili per questo processo.)
Per tutti i contenitori, la chiave di partizione deve avere le caratteristiche seguenti:
Una proprietà con un valore invariabile. Se la chiave di partizione è una proprietà, non è possibile aggiornarne il valore.
Dovrebbe contenere solo valori
Stringo, idealmente, tutti i numeri dovrebbero essere convertiti aString, se c'è una possibilità che essi non rientrino nei limiti dei numeri a precisione doppia in base a IEEE 754 binary64. La specifica JSON indica le ragioni per cui l'uso dei numeri al di fuori di questo limite è in generale una procedura non consigliata a causa di possibili problemi di interoperabilità. Questi problemi sono particolarmente rilevanti per la colonna chiave della partizione, poiché essa è invariabile e richiede che la migrazione dei dati la modifichi in un secondo momento.Avere una cardinalità elevata. In altre parole, la proprietà deve prevedere un'ampia gamma di valori possibili.
Ripartire in modo uniforme l'utilizzo dell'unità richiesta (UR) e l'archiviazione dati in tutte le partizioni logiche. Questa ripartizione garantisce anche la distribuzione uniforme dell'utilizzo di UR e dello spazio di archiviazione tra le partizioni fisiche.
In genere, i valori non superano i 2048 byte, o 101 byte se le chiavi di partizione di grandi dimensioni non sono abilitate. Per ulteriori informazioni, vedere Chiavi di partizione di grandi dimensioni
Se si necessita di transazioni ACID a più elementi in Azure Cosmos DB, è necessario usare stored procedure o trigger. Tutte le stored procedure e i trigger basati su JavaScript hanno come ambito una singola partizione logica.
Nota
Se si dispone di una sola partizione fisica, il valore della chiave di partizione potrebbe non essere rilevante perché tutte le query saranno destinate alla stessa partizione fisica.
Tipi di chiavi di partizione
| Strategia di partizionamento | Utilizzo | Vantaggi | Svantaggi |
|---|---|---|---|
| Chiave di partizione regolare (ad esempio, CustomerId, OrderId) | - Usare quando la chiave di partizione ha cardinalità elevata ed è allineata ai modelli di query( ad esempio, il filtro in base a CustomerId). - Adatto per i carichi di lavoro in cui le query sono destinate principalmente ai dati di un singolo cliente (ad esempio, il recupero di tutti gli ordini per un cliente). |
- Semplice da gestire. - Query efficienti quando il modello di accesso corrisponde alla chiave di partizione , ad esempio eseguendo query su tutti gli ordini in base a CustomerId. - Impedisce le query tra partizioni se i modelli di accesso sono coerenti. |
- Rischio di partizioni ad accesso frequente se alcuni valori (ad esempio, alcuni clienti ad alto traffico) generano più dati di altri. - Può raggiungere il limite di 20 GB per partizione logica se il volume di dati per una chiave specifica cresce rapidamente. |
| Chiave di partizione sintetica (ad esempio, CustomerId + OrderDate) | - Usare quando nessun singolo campo ha cardinalità elevata e corrisponde ai modelli di query. - Valido per carichi di lavoro con carichi di lavoro con operazioni di scrittura in cui i dati devono essere distribuiti uniformemente tra le partizioni fisiche ,ad esempio molti ordini effettuati nella stessa data. |
- Consente di distribuire i dati in modo uniforme tra le partizioni, riducendo le partizioni ad accesso frequente (ad esempio, la distribuzione degli ordini sia da CustomerId che da OrderDate). - Distribuisce le scritture tra più partizioni, migliorando la velocità effettiva. |
- Le query che filtrano solo in base a un campo (ad esempio, solo CustomerId) potrebbero generare query tra partizioni. - Le query tra partizioni possono comportare un maggiore consumo di UR (2-3 UR/sec aggiuntive per ogni partizione fisica esistente) e una latenza aggiunta. |
| Chiave di partizione gerarchica (HPK) (ad esempio, CustomerId/OrderId, StoreId/ProductId) | - Usare quando è necessario il partizionamento a più livelli per supportare set di dati su larga scala. - Ideale quando le query filtrano i primi e i secondi livelli della gerarchia. |
- Consente di evitare il limite di 20 GB creando più livelli di partizionamento. - Esecuzione efficiente di query su entrambi i livelli gerarchici,ad esempio filtrando prima in base a CustomerID e quindi in base a OrderID. - Riduce al minimo le query tra partizioni per le query destinate al livello principale( ad esempio, il recupero di tutti i dati da un CustomerID specifico). |
- Richiede un'attenta pianificazione per garantire che la chiave di primo livello abbia una cardinalità elevata ed è inclusa nella maggior parte delle query. - Più complesso da gestire rispetto a una normale chiave di partizione. - Se le query non sono allineate alla gerarchia ( ad esempio, filtrando solo in base a OrderID quando CustomerID è il primo livello), le prestazioni delle query potrebbero risentire. |
Chiavi di partizione per contenitori con intensa attività di lettura
Per la maggior parte dei contenitori, i criteri precedenti sono tutto ciò da tenere in considerazione nella selezione una chiave di partizione. Per contenitori di grandi dimensioni di lettura, tuttavia, potrebbe essere necessario scegliere una chiave di partizione che venga visualizzata di frequente come filtro nelle query. Affinché le query vengano instradate in modo efficiente solo alle partizioni fisiche pertinenti, includere la chiave di partizione nel predicato del filtro.
Questa proprietà può essere un’ottima scelta per la chiave di partizione se la maggior parte delle richieste del carico di lavoro sono query e la maggior parte delle query dispone di un filtro di uguaglianza sulla stessa proprietà. Ad esempio, se si esegue spesso una query che filtra in UserID, la selezione di UserID come chiave di partizione riduce il numero di query tra partizioni.
Tuttavia, se il contenitore è di piccole dimensioni, probabilmente non sono presenti partizioni fisiche sufficienti a incidere negativamente sulle prestazioni delle query tra partizioni. La maggior parte dei contenitori di piccole dimensioni in Azure Cosmos DB richiede solo una o due partizioni fisiche.
Se esiste la possibilità che il contenitore si estenda a un numero di partizioni fisiche più elevato, è necessario assicurarsi di selezionare una chiave di partizione che riduca al minimo le query tra partizioni. Il contenitore richiede un numero maggiore di partizioni fisiche nel caso in cui una delle condizioni seguenti sia vera:
Il contenitore ha effettuato il provisioning di oltre 30.000 UR
Il contenitore archivia più di 100 GB di dati
Usare l'ID elemento come chiave di partizione
Nota
Questa sezione riguarda principalmente l'API per NoSQL. Altre API, ad esempio l'API per Gremlin, non supportano l'identificatore univoco come chiave di partizione.
Se il contenitore ha una proprietà con un'ampia gamma di valori possibili, sarà probabilmente una scelta ottimale per la chiave di partizione. Un esempio possibile di una proprietà di questo tipo è rappresentato dall'ID elemento. Per contenitori di piccole dimensioni o contenitori di qualsiasi dimensione ma con scrittura elevata, l'ID elemento (/id ) è naturalmente un'ottima scelta per la chiave di partizione.
L'ID elemento di una proprietà di sistema è presente in ogni elemento di un contenitore. Potrebbero essere presenti altre proprietà che rappresentano un ID logico dell'elemento. In molti casi, questi ID sono anche ottime scelte di chiave di partizione per le stesse ragioni dell'ID elemento.
L'ID elemento rappresenta un'ottima scelta come chiave di partizione per i motivi seguenti:
- Esiste un'ampia gamma di valori possibili (un ID elemento univoco per ogni elemento).
- Poiché è presente un ID elemento univoco per ogni elemento, l'ID elemento sarà efficace per bilanciare uniformemente l’utilizzo delle UR e l'archiviazione dei dati.
- È possibile eseguire facilmente ed efficacemente la lettura di punti, poiché si conoscerà sempre la chiave di partizione di un elemento se si conosce il relativo ID elemento.
Di seguito vengono elencati alcuni aspetti di cui tenere conto se si seleziona l'ID elemento come chiave di partizione:
- Se l'ID elemento è la chiave di partizione, diventerà un identificatore univoco nell'intero contenitore. Non è possibile creare elementi con ID elemento duplicati.
- Se si dispone di un contenitore con un numero elevato di letture con molte partizioni fisiche, le query saranno più efficienti se hanno un filtro di uguaglianza con l'ID elemento.
- Non è possibile eseguire stored procedure o trigger destinati a più partizioni logiche.