Lo schema di progettazione Saga consente di mantenere la coerenza dei dati nei sistemi distribuiti coordinando le transazioni tra più servizi. Una saga è una sequenza di transazioni locali in cui ogni servizio esegue l'operazione e avvia il passaggio successivo tramite eventi o messaggi. Se un passaggio della sequenza ha esito negativo, la saga esegue transazioni di compensazione per annullare i passaggi completati, mantenendo la coerenza dei dati.
Contesto e problema
Una transazione rappresenta un'unità di lavoro, che può includere più operazioni. All'interno di una transazione, un evento fa riferimento a una modifica dello stato che interessa un'entità. Un comando incapsula tutte le informazioni necessarie per eseguire un'azione o attivare un evento successivo.
Le transazioni devono rispettare i principi di atomicità, coerenza, isolamento e durabilità (ACID).
- atomicità: tutte le operazioni hanno esito positivo o nessuna operazione.
- Consistency: transizioni di dati da uno stato valido a un altro.
- Isolamento: le transazioni simultanee producono gli stessi risultati di quelli sequenziali.
- durabilità: dopo il commit, le modifiche vengono mantenute anche in caso di errori.
In un singolo servizio le transazioni seguono i principi ACID perché operano all'interno di un singolo database. Tuttavia, il raggiungimento della conformità ACID tra più servizi è più complesso.
Sfide nelle architetture di microservizi
Le architetture di microservizi assegnano in genere un database dedicato a ogni microservizio, che offre diversi vantaggi:
- Ogni servizio incapsula i propri dati.
- Ogni servizio può usare la tecnologia e lo schema di database più adatti per le esigenze specifiche.
- Scalabilità indipendente dei database per ogni servizio.
- Gli errori in un servizio sono isolati da altri.
Nonostante questi vantaggi, questa architettura complica la coerenza dei dati tra servizi. Le garanzie di database tradizionali, ad esempio ACID, non sono direttamente applicabili a più archivi dati gestiti in modo indipendente. A causa di queste limitazioni, le architetture che si basano su modelli di comunicazione interprocesso (IPC) o tradizionali, come il protocollo 2PC (Two-Phase Commit), sono spesso più adatti per il modello Saga.
Soluzione
Il modello Saga gestisce le transazioni suddividendole in una sequenza di transazioni locali (vedere la figura 1).
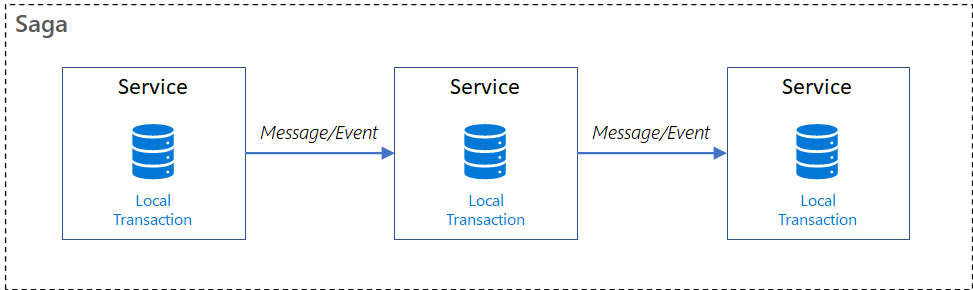
Figura 1. Una saga con tre servizi.
Ogni transazione locale:
- Completa il lavoro in modo atomico all'interno di un singolo servizio.
- Aggiorna il database del servizio.
- Avvia la transazione successiva tramite un evento o un messaggio.
- Se una transazione locale ha esito negativo, la saga esegue una serie di transazioni di compensazione per invertire le modifiche apportate dalle transazioni locali precedenti.
Concetti chiave nel modello Saga
transazioni compensabili: transazioni che altre transazioni possono annullare o compensare con l'effetto opposto. Se un passaggio della saga ha esito negativo, le transazioni di compensazione annullano le modifiche apportate alle transazioni compensabili.
transazione pivot: la transazione pivot funge da "punto di nessun ritorno" nella saga. Una volta completata la transazione pivot, le transazioni compensabili (che potrebbero essere annullate) non sono più rilevanti. Tutte le azioni successive devono essere completate affinché il sistema ottenga uno stato finale coerente. Una transazione pivot può rientrare in ruoli diversi a seconda del flusso della saga:
irreversibile (non verificabile): non può essere annullata o ritentata.
Limite tra ireversibili e di cui è stato eseguito il commit: può essere l'ultima transazione (compensabile) annullabile oppure può essere la prima operazione riprovabile nella saga.
transazioni ritentabili: queste transazioni seguono la transazione pivot. Le transazioni riprovabili sono idempotenti e assicurano che la saga possa raggiungere lo stato finale, anche se si verificano errori temporanei. Garantisce che la saga raggiunga alla fine uno stato coerente.
Approcci all'implementazione di Saga
Esistono due approcci comuni di implementazione della saga, coreografia e orchestrazione. Ogni approccio ha un proprio set di sfide e tecnologie per coordinare il flusso di lavoro.
Coreografia
Nella coreografia, i servizi scambiano eventi senza un controller centralizzato. Con la coreografia, ogni transazione locale pubblica eventi di dominio che attivano transazioni locali in altri servizi (vedere la figura 2).
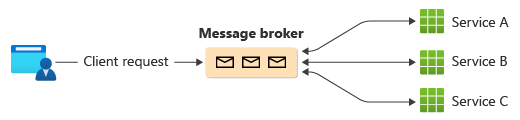
Figura 2. Una saga che usa coreografie.
| Vantaggi della coreografia | Svantaggi della coreografia |
|---|---|
| È utile per flussi di lavoro semplici con pochi servizi e non è necessaria una logica di coordinamento. | Il flusso di lavoro può creare confusione quando si aggiungono nuovi passaggi. È difficile tenere traccia di quali partecipanti della saga ascoltano i comandi. |
| Nessun altro servizio è necessario per il coordinamento. | C'è il rischio di dipendenza ciclico tra i partecipanti alla saga perché devono usare i comandi dell'altro. |
| Non introduce un singolo punto di guasto, perché le responsabilità vengono distribuite tra i partecipanti alla saga. | Il test di integrazione è difficile perché tutti i servizi devono essere in esecuzione per simulare una transazione. |
Orchestrazione
Nell'orchestrazione un controller centralizzato (agente di orchestrazione) gestisce tutte le transazioni e indica ai partecipanti quale operazione eseguire in base agli eventi. L'agente di orchestrazione esegue richieste saga, archivia e interpreta gli stati di ogni attività e gestisce il ripristino degli errori con transazioni di compensazione (vedere la figura 3).
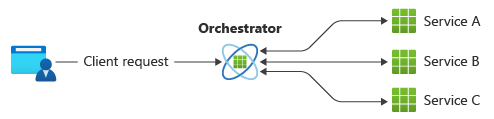
Figura 3. Una saga che usa l'orchestrazione.
| Vantaggi dell'orchestrazione | svantaggi della di orchestrazione |
|---|---|
| Più adatto per flussi di lavoro complessi o quando si aggiungono nuovi servizi. | Altre complessità di progettazione richiedono un'implementazione di una logica di coordinamento. |
| Evita le dipendenze cicliche perché l'agente di orchestrazione gestisce il flusso. | Introduce un punto di errore perché l'agente di orchestrazione gestisce il flusso di lavoro completo. |
| La separazione chiara delle responsabilità semplifica la logica del servizio. |
Problemi e considerazioni
Quando si implementa il modello Saga, tenere presente quanto segue:
Cambiamento nel pensiero progettuale: l'adozione del modello Saga richiede una mentalità diversa, concentrandosi sul coordinamento delle transazioni e sulla coerenza dei dati tra più microservizi.
complessità delle saghe di debug: il debug delle saghe può essere complesso, soprattutto quando aumenta il numero di servizi partecipanti.
Modifiche irreversibili del database locale: non è possibile eseguire il rollback dei dati perché i partecipanti della saga eseguono il commit delle modifiche ai rispettivi database.
Gestione degli errori temporanei e dell'idempotenza: il sistema deve gestire in modo efficace gli errori temporanei e garantire l'idempotenza, in cui la ripetizione della stessa operazione non altera il risultato. Per altre informazioni, vedere 'elaborazione di messaggi Idempotenti.
La necessità di monitorare e tenere traccia delle saghe: il monitoraggio e il monitoraggio del flusso di lavoro di una saga sono essenziali per mantenere la supervisione operativa.
Limitazioni delle transazioni di compensazione: le transazioni di compensazione potrebbero non sempre avere esito positivo, lasciando il sistema in uno stato incoerente.
Potenziali anomalie dei dati nelle saghe
Le anomalie dei dati sono incoerenze che possono verificarsi quando le saghe vengono eseguite in più servizi. Poiché ogni servizio gestisce i propri dati (dati dei partecipanti), non esiste un isolamento predefinito tra i servizi. Questa configurazione può causare incoerenze o problemi di durabilità dei dati, ad esempio aggiornamenti parzialmente applicati o conflitti tra i servizi. I problemi comuni includono:
aggiornamenti persi: quando una saga modifica i dati senza considerare le modifiche apportate da un'altra saga, comporta aggiornamenti sovrascritti o mancanti.
Dirty legge: quando una saga o una transazione legge i dati modificati da un'altra saga ma non ancora completata.
Fuzzy (nonrepeatable) legge: quando passaggi diversi di una saga leggono dati incoerenti perché si verificano aggiornamenti tra le letture.
Strategie per risolvere le anomalie dei dati
Per ridurre o prevenire queste anomalie, considerare queste contromisure:
blocco semantico: usare blocchi a livello di applicazione in cui la transazione compensabile di una saga usa un semaforo per indicare che è in corso un aggiornamento.
aggiornamenti commutative: progettare gli aggiornamenti in modo che possano essere applicati in qualsiasi ordine, producendo comunque lo stesso risultato, riducendo i conflitti tra le saghe.
vista pessimistica: riordinare la sequenza della saga in modo che gli aggiornamenti dei dati si verifichino in transazioni ritentabili per eliminare le letture dirty. In caso contrario, una saga potrebbe leggere i dati dirty (modifiche di cui non è stato eseguito il commit) mentre un'altra saga sta eseguendo contemporaneamente una transazione compensabile per eseguire il rollback degli aggiornamenti.
i valori di rilettura: verificare che i dati rimangano invariati prima di apportare aggiornamenti. Se i dati cambiano, interrompere il passaggio corrente e riavviare la saga in base alle esigenze.
file di versione: mantenere un log di tutte le operazioni su un record e assicurarsi che vengano eseguiti nella sequenza corretta per evitare conflitti.
concorrenza basata sul rischio (per valore): scegliere dinamicamente il meccanismo di concorrenza appropriato in base al potenziale rischio aziendale. Ad esempio, usare le saghe per gli aggiornamenti a basso rischio e le transazioni distribuite per quelle ad alto rischio.
Quando usare questo modello
Usare il modello Saga quando è necessario:
- Garantire la coerenza dei dati in un sistema distribuito senza accoppiamento stretto.
- Eseguire il rollback o compensare se una delle operazioni nella sequenza ha esito negativo.
Il modello Saga è meno adatto per:
- Transazioni strettamente associate.
- Compensazione delle transazioni che si verificano nei partecipanti precedenti.
- Dipendenze cicliche.
Passaggi successivi
Risorse correlate
I modelli seguenti possono essere utili anche quando si implementa questo modello:
- Coreografia ha ogni componente del sistema che partecipa al processo decisionale sul flusso di lavoro di una transazione aziendale, invece di basarsi su un punto centrale di controllo.
- transazioni di compensazione annullare il lavoro eseguito da una serie di passaggi e infine definire un'operazione coerente in caso di esito negativo di uno o più passaggi. Le applicazioni ospitate nel cloud che implementano processi aziendali e flussi di lavoro complessi spesso seguono questo modello di coerenza finale.
- riprovare consente a un'applicazione di gestire gli errori temporanei quando tenta di connettersi a un servizio o a una risorsa di rete, ritentando in modo trasparente l'operazione non riuscita. I tentativi possono migliorare la stabilità dell'applicazione.
- interruttore gestisce gli errori che richiedono una quantità variabile di tempo per il ripristino, durante la connessione a un servizio remoto o a una risorsa. L'interruttore può migliorare la stabilità e la resilienza di un'applicazione.
- monitoraggio degli endpoint di integrità implementa controlli funzionali in un'applicazione a cui gli strumenti esterni possono accedere tramite endpoint esposti a intervalli regolari. Il monitoraggio degli endpoint di integrità consente di verificare che le applicazioni e i servizi funzionino correttamente.