Decentralizzare la logica del flusso di lavoro e distribuire le responsabilità ad altri componenti all'interno di un sistema.
Contesto e problema
Un'applicazione basata sul cloud è spesso suddivisa in diversi servizi di piccole dimensioni che interagiscono per elaborare una transazione aziendale end-to-end. Anche una singola operazione (all'interno di una transazione) può comportare più chiamate da punto a punto tra tutti i servizi. Idealmente, questi servizi devono essere ad accoppiamento libero. È difficile progettare un flusso di lavoro distribuito, efficiente e scalabile perché comporta spesso comunicazioni interservizi complesse.
Un modello comune per la comunicazione consiste nell'usare un servizio centralizzato o un agente di orchestrazione. Le richieste in ingresso passano attraverso l'agente di orchestrazione mentre delega le operazioni ai rispettivi servizi. Ogni servizio completa solo la propria responsabilità e non è a conoscenza del flusso di lavoro complessivo.
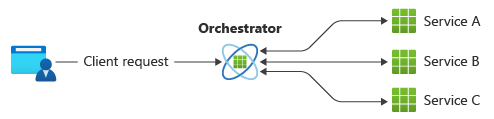
Il modello dell'agente di orchestrazione viene in genere implementato come software personalizzato e ha una conoscenza del dominio sulle responsabilità di tali servizi. Un vantaggio è che l'agente di orchestrazione può consolidare lo stato di una transazione in base ai risultati delle singole operazioni eseguite dai servizi downstream.
Tuttavia, ci sono alcuni svantaggi. L'aggiunta o la rimozione di servizi potrebbe interrompere la logica esistente perché è necessario collegare parti del percorso di comunicazione. Questa dipendenza rende l'implementazione dell'agente di orchestrazione complessa e difficile da gestire. L'agente di orchestrazione potrebbe avere un impatto negativo sull'affidabilità del carico di lavoro. In fase di caricamento, può introdurre colli di bottiglia delle prestazioni e essere il singolo punto di guasto. Può anche causare errori a catena nei servizi downstream.
Soluzione
Delegare la logica di gestione delle transazioni tra i servizi. Consentire a ogni servizio di decidere e partecipare al flusso di lavoro di comunicazione per un'operazione aziendale.
Il modello è un modo per ridurre al minimo la dipendenza dal software personalizzato che centralizza il flusso di lavoro di comunicazione. I componenti implementano la logica comune mentre coreografano il flusso di lavoro tra loro senza avere una comunicazione diretta tra loro.
Un modo comune per implementare la coreografia consiste nell'usare un broker di messaggi che memorizza nel buffer le richieste fino a quando i componenti downstream non sostengono e li elaborano. L'immagine mostra la gestione delle richieste tramite un modello publisher-subscriber.
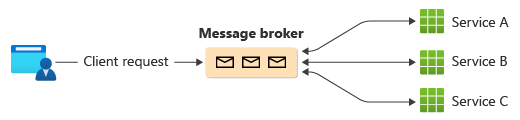
Le richieste client vengono accodate come messaggi in un broker di messaggi.
I servizi o il sottoscrittore eseguono il polling del broker per determinare se possono elaborare tale messaggio in base alla logica di business implementata. Il broker può anche effettuare il push dei messaggi ai sottoscrittori interessati a tale messaggio.
Ogni servizio sottoscritto esegue l'operazione come indicato dal messaggio e risponde al broker con esito positivo o negativo dell'operazione.
In caso di esito positivo, il servizio può eseguire il push di un messaggio nella stessa coda o in una coda di messaggi diversa in modo che un altro servizio possa continuare il flusso di lavoro, se necessario. Se l'operazione non riesce, il broker messaggi funziona con altri servizi per compensare tale operazione o l'intera transazione.
Considerazioni e problemi
La decentralizzazione dell'agente di orchestrazione può causare problemi durante la gestione del flusso di lavoro.
Gli errori di consegna possono essere difficili. I componenti in un'applicazione possono eseguire attività atomica, ma potrebbero avere ancora un livello di dipendenza. L'errore in un componente può influire su altri, causando ritardi nel completamento della richiesta complessiva.
Per gestire correttamente gli errori, l'implementazione di transazioni di compensazione potrebbe introdurre complessità. Anche la logica di gestione degli errori, ad esempio le transazioni di compensazione, è soggetta a errori.
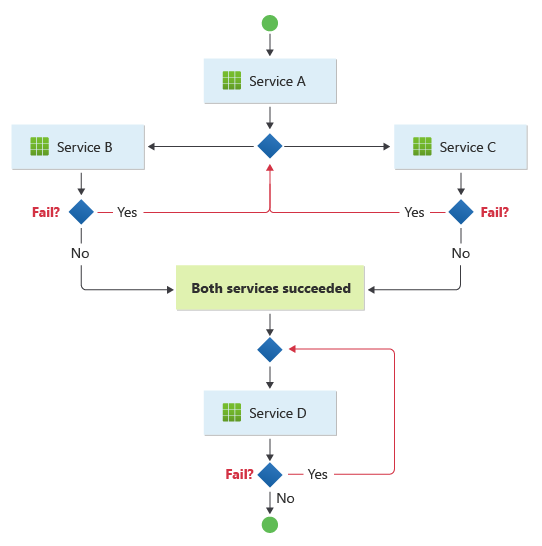
Il modello è adatto per un flusso di lavoro in cui le operazioni aziendali indipendenti vengono elaborate in parallelo. Il flusso di lavoro può diventare complicato quando la coreografia deve verificarsi in una sequenza. Ad esempio, Il servizio D può avviare l'operazione solo dopo che il servizio B e il servizio C hanno completato le operazioni con esito positivo.
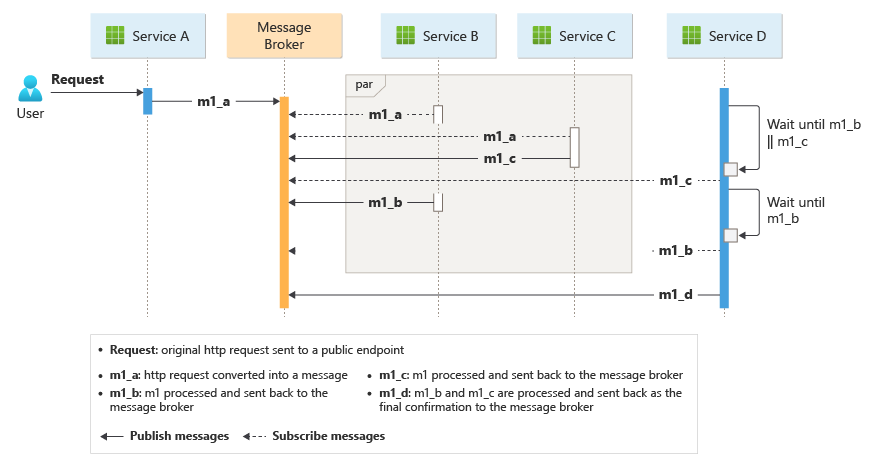
Il modello diventa una sfida se il numero di servizi cresce rapidamente. Dato il numero elevato di parti in movimento indipendenti, il flusso di lavoro tra i servizi tende a diventare complesso. Inoltre, la traccia distribuita diventa difficile, anche se gli strumenti come ServiceInsight insieme a NServiceBus possono contribuire a ridurre queste sfide.
In una progettazione guidata dall'agente di orchestrazione, il componente centrale può partecipare parzialmente e delegare la logica di resilienza a un altro componente che ritenta gli errori temporanei, non transazioni e timeout, in modo coerente. Con la dissoluzione dell'agente di orchestrazione nel modello coreografico, i componenti downstream non dovrebbero raccogliere tali attività di resilienza. Tali elementi devono comunque essere gestiti dal gestore di resilienza. Ma ora, i componenti downstream devono comunicare direttamente con il gestore di resilienza, aumentando la comunicazione da punto a punto.
Quando usare questo modello
Usare questo modello quando:
I componenti downstream gestiscono le operazioni atomica in modo indipendente. Pensaci come un meccanismo di "fuoco e dimentica". Un componente è responsabile di un'attività che non deve essere gestita attivamente. Al termine dell'attività, invia una notifica agli altri componenti.
Si prevede che i componenti vengano aggiornati e sostituiti frequentemente. Il modello consente di modificare l'applicazione con minore impegno e con un'interruzione minima dei servizi esistenti.
Il modello è una soluzione naturale per le architetture serverless appropriate per flussi di lavoro semplici. I componenti possono essere di breve durata e basati su eventi. Quando si verifica un evento, i componenti vengono attivati, eseguono le attività e vengono rimossi al termine dell'attività.
Questo modello può essere una scelta ottimale per le comunicazioni tra contesti delimitati. Per le comunicazioni all'interno di un singolo contesto delimitato, è possibile considerare un modello di agente di orchestrazione.
Il collo di bottiglia delle prestazioni è stato introdotto dall'agente di orchestrazione centrale.
Questo modello potrebbe non essere utile quando:
L'applicazione è complessa e richiede un componente centrale per gestire la logica condivisa per mantenere leggeri i componenti downstream.
Ci sono situazioni in cui la comunicazione da punto a punto tra i componenti è inevitabile.
È necessario consolidare tutte le operazioni gestite dai componenti downstream usando la logica di business.
Progettazione del carico di lavoro
Un architetto deve valutare il modo in cui il modello coreografico può essere usato nella progettazione del carico di lavoro per soddisfare gli obiettivi e i principi trattati nei pilastri di Azure Well-Architected Framework. Ad esempio:
| Concetto fondamentale | Come questo modello supporta gli obiettivi di pilastro |
|---|---|
| L'eccellenza operativa consente di offrire la qualità del carico di lavoro attraverso processi standardizzati e coesione del team. | Poiché i componenti distribuiti in questo modello sono autonomi e progettati per essere sostituibili, è possibile modificare il carico di lavoro con modifiche meno complessive al sistema. - Strumenti e processi di OE:04 |
| L'efficienza delle prestazioni consente al carico di lavoro di soddisfare in modo efficiente le richieste tramite ottimizzazioni in termini di scalabilità, dati, codice. | Questo modello offre un'alternativa quando si verificano colli di bottiglia delle prestazioni in una topologia di orchestrazione centralizzata. - PE:02 Pianificazione della capacità - PE:05 Ridimensionamento e partizionamento |
Come per qualsiasi decisione di progettazione, prendere in considerazione eventuali compromessi rispetto agli obiettivi degli altri pilastri che potrebbero essere introdotti con questo modello.
Esempio
Questo esempio illustra il modello coreografico creando un carico di lavoro nativo del cloud basato su eventi che esegue funzioni insieme ai microservizi. Quando un client richiede la spedizione di un pacchetto, il carico di lavoro assegna un drone. Una volta che il pacchetto è pronto per il ritiro dal drone pianificato, viene avviato il processo di consegna. Durante il transito, il carico di lavoro gestisce il recapito fino a quando non ottiene lo stato spedito.
Questo esempio è un refactoring dell'implementazione del recapito tramite drone che sostituisce il modello Orchestrator con il modello Coreografia.
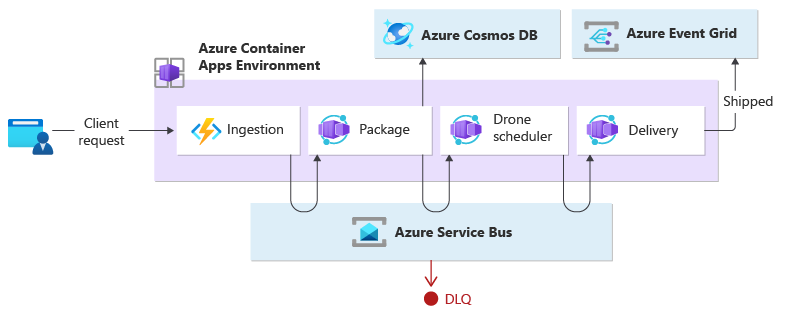
Il servizio di inserimento gestisce le richieste client e le converte in messaggi, inclusi i dettagli del recapito. Le transazioni aziendali vengono avviate dopo l'utilizzo di tali nuovi messaggi.
Una singola transazione aziendale client richiede tre operazioni aziendali distinte:
- Creare o aggiornare un pacchetto
- Assegnare un drone per recapitare il pacchetto
- Gestire il recapito costituito dal controllo e alla fine aumentare la consapevolezza quando viene spedito.
Tre microservizi eseguono l'elaborazione aziendale: Pacchetti, Utilità di pianificazione droni e Servizi di recapito. Anziché un agente di orchestrazione centrale, i servizi usano la messaggistica per comunicare tra loro. Ogni servizio sarà responsabile dell'implementazione anticipata di un protocollo che coordina in modo decentralizzato il flusso di lavoro aziendale.
Progettazione
La transazione aziendale viene elaborata in una sequenza tramite più hop. Ogni hop condivide un singolo bus di messaggi tra tutti i servizi aziendali.
Quando un client invia una richiesta di recapito tramite un endpoint HTTP, il servizio di inserimento lo riceve, converte tale richiesta in un messaggio e quindi pubblica il messaggio nel bus di messaggi condiviso. I servizi aziendali sottoscritti stanno per consumare nuovi messaggi aggiunti al bus. Quando si riceve il messaggio, i servizi aziendali possono completare l'operazione con esito positivo, negativo o il timeout della richiesta. In caso di esito positivo, i servizi rispondono al bus con il codice di stato Ok, genera un nuovo messaggio di operazione e lo invia al bus di messaggi. Se si verifica un errore o un timeout, il servizio segnala un errore inviando il codice motivo al bus di messaggi. Inoltre, il messaggio viene aggiunto a una coda di messaggi non recapitabili. I messaggi che non possono essere ricevuti o elaborati entro un periodo di tempo ragionevole e appropriato vengono spostati anche la DQ.
La progettazione usa più bus di messaggio per elaborare l'intera transazione aziendale. bus di servizio di Microsoft Azure e Microsoft Griglia di eventi di Azure sono composti per fornire la piattaforma del servizio di messaggistica per questa progettazione. Il carico di lavoro viene distribuito in App Contenitore di Azure che ospita Funzioni di Azure per l'inserimento e le app che gestiscono l'elaborazione basata su eventi che esegue la logica di business.
Il design garantisce che la coreografia venga eseguita in una sequenza. Un singolo spazio dei nomi bus di servizio di Azure contiene un argomento con due sottoscrizioni e una coda compatibile con la sessione. Il servizio di inserimento pubblica messaggi nell'argomento. Il servizio Package e drone Scheduler sottoscrivono l'argomento e pubblicano messaggi che comunicano l'esito positivo alla coda. Includendo un identificatore di sessione comune associato a un GUID associato all'identificatore di recapito, consente la gestione ordinata di sequenze non associate di messaggi correlati. Il servizio di recapito attende due messaggi correlati per transazione. Il primo messaggio indica che il pacchetto è pronto per essere spedito e il secondo segnala che un drone è pianificato.
Questa progettazione usa bus di servizio di Azure per gestire messaggi di valore elevato che non possono essere persi o duplicati durante l'intero processo di recapito. Quando il pacchetto viene spedito, viene pubblicato anche un cambiamento di stato in Griglia di eventi di Azure. In questa progettazione, il mittente dell'evento non si aspetta come viene gestita la modifica dello stato. I servizi dell'organizzazione downstream che non sono inclusi nell'ambito di questa progettazione potrebbero essere in ascolto di questo tipo di evento e reagire eseguendo una logica specifica per lo scopo aziendale, ovvero inviare un messaggio di posta elettronica allo stato dell'ordine spedito all'utente.
Se si prevede di distribuirlo in un altro servizio di calcolo, ad esempio il modello pub-sub del servizio Azure Kubernetes, boilerplate può essere implementato con due contenitori nello stesso pod. Un contenitore esegue l'ambassador che interagisce con il bus di messaggi di preferenza mentre l'altro esegue la logica di business. L'approccio con due contenitori nello stesso pod migliora le prestazioni e la scalabilità. L'ambasciatore e il servizio aziendale condividono la stessa rete consentendo bassa latenza e velocità effettiva elevata.
Per evitare operazioni di ripetizione dei tentativi a catena che potrebbero portare a più sforzi, i servizi aziendali devono contrassegnare immediatamente messaggi inaccettabili. È possibile arricchire tali messaggi usando codici motivo noti o un codice dell'applicazione definito, in modo che possa essere spostato in una coda di messaggi non recapitabili (DLQ). Valutare la possibilità di gestire i problemi di coerenza che implementano Saga dai servizi downstream. Ad esempio, un altro servizio potrebbe gestire messaggi non recapitabili a scopo di correzione solo eseguendo una compensazione, un nuovo tentativo o una transazione pivot.
I servizi aziendali sono idempotenti per assicurarsi che le operazioni di ripetizione dei tentativi non comportino risorse duplicate. Ad esempio, il servizio pacchetto usa operazioni upsert per aggiungere dati all'archivio dati.
Risorse correlate
Considera questi modelli nel tuo design per la coreografia.
Modularizzare il servizio aziendale usando il modello di progettazione ambassador.
Implementare un modello di livellamento del carico basato su coda per gestire i picchi del carico di lavoro.
Usare la messaggistica distribuita asincrona tramite il modello publisher-subscriber.
Usare transazioni di compensazione per annullare una serie di operazioni riuscite in caso di esito negativo di una o più operazioni correlate.
Per informazioni sull'uso di un broker di messaggi in un'infrastruttura di messaggistica, vedere Opzioni di messaggistica asincrona in Azure.