Gestire gli errori il cui ripristino potrebbe richiedere una quantità variabile di tempo in fase di connessione a una risorsa o a un servizio remoto. Questo modello può migliorare la stabilità e la resilienza di un'applicazione.
Contesto e problema
In un ambiente distribuito, le chiamate a risorse e servizi remoti possono non riuscire a causa di errori temporanei, ad esempio connessioni di rete lente, timeout o risorse sottoposte a overcommitted o temporaneamente non disponibili. Questi errori in genere si risolvono autonomamente dopo un breve periodo di tempo. Un'applicazione cloud affidabile deve essere preparata per gestirli tramite una strategia, ad esempio un modello di ripetizione dei tentativi.
Tuttavia, possono anche verificarsi situazioni in cui gli errori sono causati da eventi imprevisti, per cui la risoluzione potrebbe richiedere molto più tempo. Questi errori possono variare, in base alla gravità, dalla perdita parziale della connettività alla totale interruzione di un servizio. In queste situazioni, potrebbe non essere opportuno che un'applicazione riprova continuamente a eseguire un'operazione che non sia probabile che abbia esito positivo e che l'applicazione accetti rapidamente che l'operazione non sia riuscita e gestisca questo errore di conseguenza.
Se un servizio è molto occupato, è inoltre possibile che un errore in una parte del sistema generi errori a cascata. Ad esempio, un'operazione che richiama un servizio può essere configurata per implementare un timeout e rispondere con un messaggio di errore se il servizio non risponde entro questo periodo. Tuttavia, questa strategia potrebbe causare il blocco di molte richieste simultanee alla stessa operazione fino alla scadenza del periodo di timeout. Le richieste bloccate potrebbero tenere in sospeso risorse di sistema critiche quali la memoria, i thread, le connessioni database e così via. Queste risorse potrebbero quindi essere esaurite, causando un errore di altre parti eventualmente non correlate del sistema che devono usare le stesse risorse. In questi casi, sarebbe preferibile che l'operazione restituisse immediatamente un esito negativo e tentasse di richiamare il servizio solo se è probabile che questo venga eseguito correttamente. L'impostazione di un timeout più breve potrebbe contribuire a risolvere questo problema, ma il timeout non dovrebbe essere così breve che l'operazione non riesce per la maggior parte del tempo, anche se la richiesta al servizio avrà esito positivo.
Soluzione
Il modello di interruttore può impedire a un'applicazione di tentare ripetutamente di eseguire un'operazione che potrebbe non riuscire. in modo da poter continuare l'esecuzione senza attendere la risoluzione dell'errore o senza sprecare cicli della CPU, mentre si stabilisce che l'errore è di lunga durata. Grazie al modello a interruttore, inoltre, un'applicazione è in grado di rilevare se l'errore è stato risolto. In questo caso, l'applicazione potrà provare a richiamare l'operazione.
Lo scopo del modello a interruttore è diverso da quello del modello di ripetizione dei tentativi. Il criterio di ripetizione consente a un'applicazione di ripetere un'operazione quando si prevede che avrà esito positivo. Il modello a interruttore impedisce che un'applicazione tenti un'operazione che probabilmente continuerà a restituire un errore. Un'applicazione può combinare questi due modelli, usando il modello di ripetizione dei tentativi per richiamare un'operazione tramite un interruttore. Tuttavia, la logica di riesecuzione deve essere sensibile alle eventuali eccezioni restituite dall'interruttore e abbandonare i tentativi di ripetizione se l'interruttore indica che un errore non è temporaneo.
Un interruttore funge da proxy per le operazioni che potrebbero non riuscire. Il proxy deve monitorare il numero di errori recenti che si sono verificati e usare queste informazioni per decidere se consentire l'esecuzione dell'operazione o restituire immediatamente un'eccezione.
Il proxy può essere implementato come una macchina a stati, con gli stati seguenti che simulano le funzionalità di un interruttore elettrico:
Chiuso: la richiesta inviata dall'applicazione viene indirizzata all'operazione. Il proxy mantiene un conteggio del numero di errori recenti e, se la chiamata all'operazione ha esito negativo, incrementa il conteggio. Se il numero di errori recenti supera una soglia specificata in un determinato intervallo di tempo, il proxy viene impostato sullo stato Aperto. A questo punto, il proxy avvia un timer di timeout e quando il timer scade, il proxy viene inserito nello stato half-open.
Lo scopo del timer di timeout è quello di assegnare al sistema il tempo necessario per risolvere il problema che ha causato l'errore prima di consentire all'applicazione di provare a eseguire nuovamente l'operazione.
Aperto: la richiesta inviata dall'applicazione ha un esito negativo immediato che restituisce un'eccezione all'applicazione.
Semiaperto: solo un numero limitato di richieste inviate dall'applicazione può passare e richiamare l'operazione. Se queste richieste hanno esito positivo, si presuppone che l'errore che si è verificato in precedenza sia stato risolto e l'interruttore passa allo stato Chiuso (il contatore degli errori viene reimpostato). Se una richiesta ha esito negativo, l'interruttore presuppone che l'errore sia ancora presente in modo che venga ripristinato lo stato Open e riavvia il timer di timeout per assegnare al sistema un ulteriore periodo di tempo per il ripristino dall'errore.
Lo stato Semiaperto è utile per impedire che un servizio di recupero venga improvvisamente sommerso di richieste. Quando un servizio viene ripristinato, potrebbe essere in grado di supportare un volume limitato di richieste fino al completamento del ripristino, ma mentre il ripristino è in corso, un'inondazione del lavoro può causare il timeout o il failout del servizio.
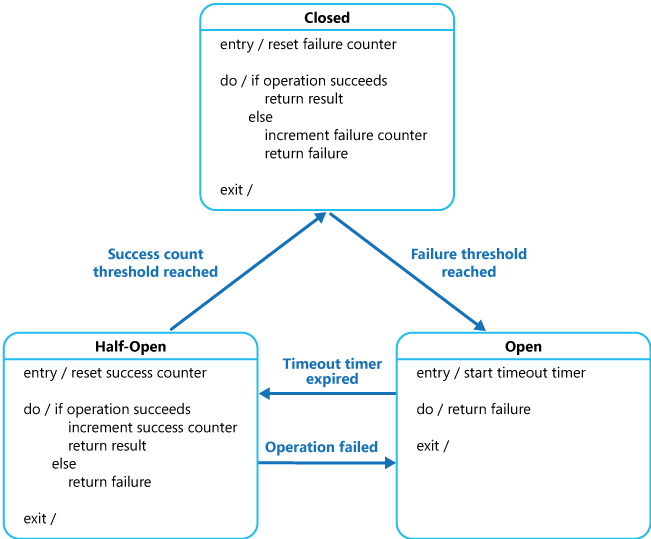
Nella figura il contatore degli errori usato dallo stato Chiuso è basato sul tempo e viene reimpostato automaticamente a intervalli periodici. Questa progettazione consente di impedire all'interruttore di entrare nello stato Open se si verificano errori occasionali. La soglia di errore che attiva lo stato Aperto dell'interruttore viene raggiunta solo quando si verifica un determinato numero di errori durante un intervallo specificato. Il contatore usato dallo stato Semiaperto registra il numero di tentativi di chiamata dell'operazione con esito positivo. L'interruttore ripristina lo stato Chiuso dopo che un determinato numero di chiamate consecutive all'operazione ha avuto esito positivo. In caso di esito negativo di una chiamata, l'interruttore attiva immediatamente lo stato Aperto e il contatore delle operazioni riuscite viene reimpostato alla successiva attivazione dello stato Semiaperto.
La modalità di ripristino del sistema viene gestita dall'esterno, verosimilmente mediante il ripristino o il riavvio di un componente in errore o il ripristino di una connessione di rete.
Il modello interruttore offre stabilità mentre il sistema esegue il recupero da un errore e riduce al minimo l'impatto sulle prestazioni. Può aiutare a gestire i tempi di risposta del sistema rifiutando rapidamente una richiesta per un'operazione con scarsa probabilità di riuscita, anziché attendere il timeout o addirittura l'arresto dell'operazione. Se l'interruttore genera un evento a ogni cambiamento di stato, queste informazioni possono essere usate per monitorare l'integrità della parte del sistema protetta dall'interruttore o per avvisare un amministratore quando un interruttore attiva lo stato Aperto.
Il modello è personalizzabile e può essere adattato in base al tipo di errore possibile. Ad esempio, è possibile applicare un timer di timeout crescente a un interruttore. È possibile posizionare l'interruttore nello stato Open per alcuni secondi inizialmente e quindi, se l'errore non è stato risolto, aumentare il timeout a pochi minuti e così via. In alcuni casi, anziché impostare lo stato Aperto in modo da restituire un errore che genera un'eccezione, potrebbe essere utile restituire un valore predefinito significativo per l'applicazione.
Nota
Tradizionalmente, gli interruttori si basavano su soglie preconfigurate, ad esempio il numero di errori e la durata del timeout, causando un comportamento deterministico ma talvolta non ottimale. Tuttavia, le tecniche adattive che usano intelligenza artificiale e Machine Learning possono regolare dinamicamente le soglie in base a modelli di traffico in tempo reale, anomalie e tassi di errore cronologici, rendendo l'interruttore più resiliente ed efficiente.
Considerazioni e problemi
Prima di decidere come implementare questo schema, è opportuno considerare quanto segue:
gestione delle eccezioni: un'applicazione che richiama un'operazione tramite un interruttore deve essere preparata per gestire le eccezioni generate se l'operazione non è disponibile. La modalità di gestione delle eccezioni cambierà a seconda dell'applicazione. Le funzionalità di un'applicazione potrebbero ad esempio peggiorare temporaneamente, l'applicazione potrebbe richiamare un'operazione alternativa per provare a eseguire la stessa attività o per ottenere gli stessi dati oppure segnalare l'eccezione all'utente e chiedergli di riprovare più tardi.
Tipi di eccezioni: una richiesta potrebbe non riuscire per molti motivi, alcuni dei quali potrebbero indicare un tipo di errore più grave rispetto ad altri. Ad esempio, una richiesta potrebbe non riuscire perché un servizio remoto si è arrestato in modo anomalo e richiederà alcuni minuti per il ripristino o a causa di un timeout dovuto all'overload temporaneamente del servizio. Un interruttore potrebbe essere in grado di esaminare i tipi di eccezioni che si verificano e adattare la propria strategia alla natura di tali eccezioni. Ad esempio, potrebbe essere necessario un numero maggiore di eccezioni di timeout per eseguire il trasferimento dell'interruttore al stato Open rispetto al numero di errori dovuti al fatto che il servizio non è completamente disponibile.
Monitoraggio: un interruttore deve fornire una chiara osservabilità sia nelle richieste non riuscite che nelle richieste riuscite, consentendo ai team operativi di valutare l'integrità del sistema. Usare la traccia distribuita per la visibilità end-to-end tra i servizi.
Ripristinabilità: è necessario configurare l'interruttore in modo che corrisponda al modello di recupero probabile dell'operazione che protegge. Se, ad esempio, l'interruttore rimane a lungo nello stato Aperto, potrebbe generare eccezioni anche se il motivo dell'errore è stato risolto. Analogamente, un interruttore potrebbe fluttuare e ridurre i tempi di risposta delle applicazioni se passa dallo stato Aperto allo stato Semiaperto troppo rapidamente.
Le operazioni di test non riuscite: nello stato Open, anziché usare un timer per determinare quando passare allo stato Half-Open, un interruttore può invece effettuare periodicamente il ping del servizio remoto o della risorsa per determinare se diventa nuovamente disponibile. Questo ping potrebbe assumere la forma di un tentativo di richiamo di un'operazione precedentemente non riuscita oppure potrebbe usare un'operazione speciale, specificamente fornita dal servizio remoto per il test dell'integrità del servizio, come descritto dal modello di monitoraggio degli endpoint di integrità.
Override manuale: in un sistema in cui il tempo di ripristino per un'operazione con errori è estremamente variabile, è utile fornire un'opzione di reimpostazione manuale che consente a un amministratore di chiudere un interruttore e reimpostare il contatore degli errori. Analogamente, un amministratore potrebbe forzare un interruttore nel stato Open (e riavviare il timer di timeout) se l'operazione protetta dall'interruttore è temporaneamente non disponibile.
la concorrenza: è possibile accedere allo stesso interruttore da un numero elevato di istanze simultanee di un'applicazione. L'implementazione non deve bloccare le richieste simultanee o aggiungere un sovraccarico eccessivo a ogni chiamata a un'operazione.
differenziazione delle risorse: prestare attenzione quando si usa un singolo interruttore per un tipo di risorsa se potrebbero essere presenti più provider indipendenti sottostanti. In un archivio dati che contiene più partizioni, ad esempio, una partizione potrebbe essere completamente accessibile mentre su un'altra si sta verificando un problema temporaneo. Se le risposte di errore in questi scenari vengono unite, un'applicazione potrebbe tentare di accedere ad alcune partizioni anche quando l'errore è molto probabile, mentre l'accesso ad altre partizioni potrebbe essere bloccato anche se è probabile che abbia esito positivo.
interruzione del circuito accelerato: a volte una risposta di errore può contenere informazioni sufficienti per l'interruzione immediata del circuito e rimanere troncato per un periodo di tempo minimo. La risposta di errore ricevuta da una risorsa condivisa sottoposta a overload potrebbe, ad esempio, indicare che un nuovo tentativo immediato non è consigliabile e che è piuttosto preferibile provare a eseguire di nuovo l'applicazione dopo qualche minuto.
distribuzioni in più aree: un interruttore può essere progettato per distribuzioni singole o in più aree. Quest'ultimo può essere implementato usando i servizi di bilanciamento del carico globale o strategie di interruzione del circuito personalizzate che garantiscono il failover controllato, l'ottimizzazione della latenza e la conformità alle normative.
interruttore mesh del servizio: gli interruttori possono essere implementati a livello di applicazione o come funzionalità di taglio incrociato e astratta. Ad esempio, le mesh di servizio spesso supportano l'interruzione del circuito come sidecar o come funzionalità autonoma senza modificare il codice dell'applicazione.
Nota
Un servizio può restituire HTTP 429 (troppe richieste) se limita il client o HTTP 503 (servizio non disponibile) se il servizio non è attualmente disponibile. La risposta può includere informazioni aggiuntive, ad esempio la durata del ritardo prevista.
La riproduzione di richieste non riuscite: nello stato Open, anziché semplicemente non riuscire rapidamente, un interruttore potrebbe registrare anche i dettagli di ogni richiesta a un journal e disporre che queste richieste vengano riprodotte quando la risorsa o il servizio remoto diventa disponibile.
timeout inappropriati nei servizi esterni: un interruttore potrebbe non essere in grado di proteggere completamente le applicazioni dalle operazioni che hanno esito negativo nei servizi esterni configurati con un lungo periodo di timeout. Se il timeout è troppo lungo, un thread che esegue un interruttore potrebbe essere bloccato per un periodo prolungato prima che l'interruttore indichi che l'operazione non è riuscita. In questo periodo di tempo, anche molte altre istanze di applicazioni potrebbero provare a richiamare il servizio tramite l'interruttore e bloccare un numero significativo di thread prima che abbiano tutti esito negativo.
adattabilità alla diversificazione dei calcoli: gli interruttori devono tenere conto di ambienti di calcolo diversi, da serverless a carichi di lavoro in contenitori, in cui fattori come l'avvio a freddo e la gestione degli errori di scalabilità influiscono sugli errori. Gli approcci adattivi possono regolare in modo dinamico le strategie in base al tipo di calcolo, garantendo la resilienza tra architetture eterogenee.
Quando usare questo modello
Usare questo schema:
- Per evitare errori a catena arrestando un numero eccessivo di chiamate da un servizio remoto o le richieste di accesso a una risorsa condivisa se queste operazioni hanno una probabilità elevata di esito negativo.
- Per migliorare la resilienza in più aree instradando il traffico in modo intelligente in base ai segnali di errore in tempo reale.
- Per proteggersi da dipendenze lente, consentendo di mantenere il passo con gli obiettivi del livello di servizio e di evitare una riduzione delle prestazioni a causa di servizi a latenza elevata.
- Per gestire problemi di connettività intermittenti e ridurre gli errori delle richieste negli ambienti distribuiti.
Questo modello non è consigliato:
- Per gestire l'accesso alle risorse private locali in un'applicazione, ad esempio una struttura di dati in memoria. In questo ambiente, l'uso di un interruttore aggiungerebbe un overhead per il sistema.
- Come soluzione alternativa per la gestione delle eccezioni nella logica di business delle applicazioni.
- Quando gli algoritmi di ripetizione noti sono sufficienti e le dipendenze sono progettate per gestire i meccanismi di ripetizione dei tentativi. L'implementazione di un interruttore nell'applicazione in questo caso potrebbe aggiungere complessità non necessarie al sistema.
- Quando si attende che un interruttore venga reimpostato potrebbe introdurre ritardi inaccettabili.When waiting for a circuit breaker to reset might introduce ritardi inaccettabili.
- Se si dispone di un'architettura basata su messaggi o basata su eventi, poiché spesso instradano messaggi non riusciti a una coda di messaggi non recapitabili (DLQ) per l'elaborazione manuale o posticipata. I meccanismi predefiniti di isolamento e ripetizione degli errori implementati in genere in queste progettazioni sono spesso sufficienti.
- Se il ripristino degli errori viene gestito a livello di infrastruttura o piattaforma, ad esempio con i controlli di integrità nei servizi di bilanciamento del carico globale o nelle mesh di servizi, gli interruttori di circuito potrebbero non essere necessari.
Progettazione del carico di lavoro
Un architetto deve valutare il modo in cui il modello di interruttore può essere usato nella progettazione del carico di lavoro per soddisfare gli obiettivi e i principi trattati nei pilastri di Azure Well-Architected Framework. Ad esempio:
| Concetto fondamentale | Come questo modello supporta gli obiettivi di pilastro |
|---|---|
| Le decisioni di progettazione dell'affidabilità consentono al carico di lavoro di diventare resilienti a malfunzionamenti e di assicurarsi che venga ripristinato in uno stato completamente funzionante dopo che si verifica un errore. | Questo modello impedisce l'overload di una dipendenza con errori. È anche possibile usare questo modello per attivare una riduzione normale del carico di lavoro. Gli interruttori sono spesso associati al recupero automatico per fornire la riparazione automatica e la conservazione automatica. - Analisi della modalità errore RE:03 - RE:07 Errori temporanei - RE:07 Conservazione automatica |
| L'efficienza delle prestazioni consente al carico di lavoro di soddisfare in modo efficiente le richieste tramite ottimizzazioni in termini di scalabilità, dati, codice. | Questo modello evita l'approccio di ripetizione degli errori che può causare un utilizzo eccessivo delle risorse durante il ripristino delle dipendenze e può anche eseguire l'overload delle prestazioni in una dipendenza che tenta il ripristino. - PE:07 Codice e infrastruttura - Risposte ai problemi live PE:11 |
Come per qualsiasi decisione di progettazione, prendere in considerazione eventuali compromessi rispetto agli obiettivi degli altri pilastri che potrebbero essere introdotti con questo modello.
Esempio
Questo esempio illustra il modello di interruttore implementato per evitare il sovraccarico della quota usando il livello gratuito di durata Azure Cosmos DB. Questo livello viene usato principalmente per i dati non critici, la velocità effettiva è governata da un piano di capacità che effettua il provisioning di una quota designata di unità di risorse al secondo. Durante gli eventi stagionali, la domanda potrebbe superare la capacità fornita, determinando 429 risposte (troppe richieste).
Quando si verificano picchi di domanda, avvisi di Monitoraggio di Azure con soglie dinamiche rileva e notifica in modo proattivo ai team operativi e di gestione che indicano che potrebbe essere necessario aumentare la capacità del database. Contemporaneamente, un interruttore, ottimizzato usando modelli di errore cronologici, consente di evitare errori a catena. In questo stato, l'applicazione degrada normalmente restituendo risposte predefinite o memorizzate nella cache, informando gli utenti dell'indisponibilità temporanea di determinati dati mantenendo al tempo stesso la stabilità complessiva del sistema.
Questa strategia migliora la resilienza allineata alla motivazione aziendale. Il controllo delle picchi di capacità consente al team del carico di lavoro di gestire gli aumenti dei costi deliberatamente e la qualità del servizio viene mantenuta senza aumentare in modo imprevisto le spese operative. Una volta che la domanda diminuisce o aumenta la capacità, e l'interruttore viene reimpostato e l'applicazione torna a piena funzionalità in linea con gli obiettivi tecnici e di bilancio.

Il diagramma è organizzato in tre sezioni principali. La prima sezione contiene due icone identiche del Web browser, in cui la prima icona visualizza un'interfaccia utente completamente funzionale, mentre la seconda icona mostra un'esperienza utente danneggiata con un avviso sullo schermo per indicare il problema agli utenti. La seconda sezione è racchiusa all'interno di un rettangolo linea tratteggiata, diviso in due gruppi. Il gruppo principale include le risorse del carico di lavoro, costituite da Servizi applicazioni di Azure e Azure Cosmos DB. Le frecce provenienti da entrambe le icone del Web browser puntano all'istanza di Servizi applicazioni di Azure, che rappresentano le richieste in ingresso dal client. Inoltre, le frecce dell'istanza di Servizi applicazioni di Azure puntano ad Azure Cosmos DB, che indicano le interazioni tra i servizi dell'applicazione e il database. Un ciclo freccia aggiuntivo dall'istanza di Servizi applicazioni di Azure a se stesso, simbolizzando il meccanismo di timeout dell'interruttore. Questo ciclo indica che quando viene rilevata una risposta 429 Troppe richieste, il sistema torna a gestire le risposte memorizzate nella cache, degradando l'esperienza utente fino a quando la situazione non viene risolta. Il gruppo inferiore di questa sezione è incentrato sull'osservabilità e sugli avvisi, con Monitoraggio di Azure che raccoglie i dati dalle risorse di Azure nel gruppo superiore e si connette a un'icona di regola di avviso. La terza sezione illustra il flusso di lavoro di scalabilità attivato al momento della generazione dell'avviso. Una freccia connette l'icona dell'avviso ai responsabili approvazione, a indicare che la notifica viene inviata per la revisione. Un'altra freccia conduce dai responsabili approvazione a una console di sviluppo, che indica il processo di approvazione per il ridimensionamento del database. Infine, una freccia successiva si estende dalla console di sviluppo ad Azure Cosmos DB, che illustra l'azione di ridimensionamento del database in risposta alla condizione di overload.
Flusso A - Stato chiuso
- Il sistema funziona normalmente e tutte le richieste raggiungono il database senza restituire alcuna
429(troppe richieste) risposte HTTP. - L'interruttore rimane chiuso e non sono necessarie risposte predefinite o memorizzate nella cache.
Flusso B - Stato aperto
- Dopo aver ricevuto la prima risposta
429, l'interruttore viene inviato a uno stato aperto. - Le richieste successive vengono immediatamente a corto circuito, restituendo risposte predefinite o memorizzate nella cache, informando gli utenti della riduzione temporanea e l'applicazione è protetta da un ulteriore overload.
- I log e i dati di telemetria vengono acquisiti e inviati a Monitoraggio di Azure da valutare in base alle soglie dinamiche. Se vengono soddisfatte le condizioni della regola di avviso, viene attivato un avviso.
- Un gruppo di azioni notifica in modo proattivo al team operativo della condizione di overload.
- Dopo l'approvazione del team del carico di lavoro, il team operativo potrebbe aumentare la velocità effettiva di cui è stato effettuato il provisioning per ridurre l'overload o ritardare il ridimensionamento se il carico si riduce naturalmente.
Flow C - Stato semi-aperto
- Dopo un timeout predefinito, l'interruttore entra in uno stato semi-aperto, consentendo un numero limitato di richieste di valutazione.
- Se queste richieste di valutazione hanno esito positivo senza restituire risposte
429, il breaker viene reimpostato su uno stato chiuso, ripristinando le normali operazioni su Flow A. Se gli errori vengono mantenuti, viene ripristinato lo stato di apertura, ovvero Flow B.
Progettazione
- Servizi app di Azure ospita l'applicazione Web che funge da punto di ingresso primario per le richieste client. Il codice dell'applicazione implementa la logica che applica i criteri di interruttore e fornisce risposte predefinite o memorizzate nella cache quando il circuito è aperto. Questa architettura impedisce l'overload nei sistemi downstream e garantisce che l'esperienza utente venga mantenuta durante il picco della domanda o degli errori.
- azure Cosmos DB è uno degli archivi dati dell'applicazione. Gestisce i dati non critici usando il livello gratuito. Il livello gratuito è ideale per l'esecuzione di carichi di lavoro di produzione di piccole dimensioni. Il meccanismo di interruttore consente di limitare il traffico al database durante i periodi di domanda elevata.
-
Monitoraggio di Azure funziona come soluzione di monitoraggio centralizzata, aggregando tutti i log attività per garantire un'osservabilità completa e end-to-end. I log e i dati di telemetria di Servizi app di Azure e le metriche chiave di Azure Cosmos DB (ad esempio il numero di risposte
429) vengono inviati a Monitoraggio di Azure per l'aggregazione e l'analisi. -
gli avvisi di Monitoraggio di Azure valutare le regole di avviso rispetto alle soglie dinamiche per identificare potenziali interruzioni in base ai dati cronologici. Gli avvisi predefiniti notificano al team operativo quando vengono superate le soglie. In alcuni casi il team del carico di lavoro approva l'aumento della velocità effettiva con provisioning, ma il team operativo prevede che il sistema venga ripristinato autonomamente perché il carico non è troppo elevato. In questi casi, il timeout dell'interruttore è trascorso naturalmente. Durante questo periodo di tempo, se le risposte
429cessano, il calcolo della soglia rileva le interruzioni prolungate ed esclude tali risposte dall'algoritmo di apprendimento. Di conseguenza, la volta successiva che si verifica un overload, la soglia attende una frequenza di errore maggiore in Azure Cosmos DB e la notifica viene ritardata. Questa modifica consente all'interruttore di gestire il problema senza un avviso immediato e vengono realizzati efficienza in termini di costi e carico operativo.
Risorse correlate
Quando si implementa questo modello, possono essere utili anche i modelli seguenti:
Il modello di app Web affidabile illustra come applicare il modello di interruttore alle applicazioni Web convergenti nel cloud.
Modello di ripetizione dei tentativi. Descrive in che modo un'applicazione può gestire gli errori temporanei previsti durante il tentativo di connessione a un servizio o a una risorsa di rete ritentando in modo trasparente un'operazione non riuscita in precedenza.
Modello di monitoraggio endpoint di integrità. Un interruttore potrebbe essere in grado di verificare l'integrità di un servizio inviando una richiesta a un endpoint esposto dal servizio. Il servizio dovrebbe restituire informazioni che ne indicano lo stato.