Informazioni sul Servizio di riconoscimento vocale
Il servizio Voce offre funzionalità di riconoscimento vocale e sintesi vocale con una risorsa Voce. È possibile convertire la voce in testo scritto con elevata precisione, produrre sintesi vocale che abbia un suono naturale, tradurre audio parlato e usare il riconoscimento del parlante durante le conversazioni.

Crea voci personalizzate, aggiungi parole specifiche al vocabolario di base o crea modelli personalizzati. Esegui il servizio Voce ovunque, sul cloud o nella rete perimetrale in contenitori. È facile abilitare le applicazioni, gli strumenti e i dispositivi con la Interfaccia della riga di comando Voce, SDK Voce e le API REST.
Il riconoscimento vocale è disponibile per molte lingue, aree geografiche e punti di prezzo.
Scenari di riconoscimento vocale
Gli scenari comuni per il riconoscimento vocale includono:
- Didascalia: Informazioni su come sincronizzare le didascalie con l'audio di input, applicare filtri per i contenuti volgari, ottenere risultati parziali, applicare personalizzazioni e identificare le lingue parlate per scenari multilingue.
- Creazione di contenuti audio: è possibile usare le voci neurali per rendere più naturali e coinvolgenti le interazioni con chatbot e assistenti vocali, per convertire testo digitale, come gli e-book, in audiolibri e per migliorare i sistemi dei navigatori per le automobili.
- Call Center: trascrivere le chiamate in tempo reale o elaborare batch di chiamate, oscurare le informazioni personali ed estrarre informazioni dettagliate, ad esempio il sentiment per facilitare il caso d'uso dei call center.
- Apprendimento linguistico: fornire feedback sulla valutazione della pronuncia agli studenti di lingua, supportare la trascrizione in tempo reale per conversazioni di apprendimento remoto e leggere materiali didattici ad alta voce con voci neurali.
- Assistenti vocali: creare interfacce naturali e umane come le interfacce di conversazione per le applicazioni e le esperienze. La funzionalità assistente vocale offre un'interazione rapida e affidabile tra un dispositivo e un'implementazione dell'assistente.
Microsoft usa il riconoscimento vocale per molti scenari, ad esempio le didascalie in Teams, la dettatura in Office 365 e Leggi ad alta voce nel browser Microsoft Edge.
Funzionalità di riconoscimento vocale
Queste sezioni riepilogano le funzionalità di Riconoscimento vocale con collegamenti per altre informazioni.
Riconoscimento vocale
Usare il riconoscimento vocale per trascrivere l'audio in testo, in tempo reale o in modo asincrono con la trascrizione batch.
Suggerimento
È possibile provare il riconoscimento vocale in tempo reale in Speech Studio senza iscriversi o scrivere codice.
Converti l'audio in testo da una vasta gamma di origini, tra cui microfoni, file audio e archivio BLOB. Usare la diarizzazione del parlante per determinare chi ha detto cosa e quando. Ottieni trascrizioni leggibili con formattazione e punteggiatura automatiche.
Il modello di base potrebbe non essere sufficiente se l'audio contiene rumore ambientale o include numeroso gergo specifico del settore e del dominio. In questi casi, è possibile creare ed eseguire il training di modelli di riconoscimento vocale personalizzati con dati acustici, linguistici e di pronuncia. I modelli di riconoscimento vocale personalizzati sono privati e possono offrire un vantaggio competitivo.
Riconoscimento vocale in tempo reale
Con il riconoscimento vocale in tempo reale, l'audio viene trascritto come riconoscimento vocale da un microfono o da un file. Usare il riconoscimento vocale in tempo reale per le applicazioni che devono trascrivere audio in tempo reale, ad esempio:
- Trascrizioni, didascalie o sottotitoli per riunioni live
- Diarizzazione
- Valutazione della pronuncia
- Assistenza per gli agenti del Centro contatti
- Dettatura
- Agenti vocali
API di trascrizione rapida
L'API di Trascrizione rapida viene usata per trascrivere i file audio e ottenere risultati in modo sincrono e molto più veloce rispetto all'audio in tempo reale. Usare Trascrizione rapida negli scenari in cui è necessario trascrivere una registrazione audio il più rapidamente possibile con una latenza prevedibile, ad esempio:
- Trascrizione rapida di audio o video, sottotitoli e modifica.
- Traduzione video
Per iniziare a usare la trascrizione rapida, vedere Usare l'API di trascrizione rapida.
Trascrizione batch
La trascrizione batch viene usata per trascrivere una grande quantità di dati audio nella risorsa di archiviazione. È possibile puntare a file audio con un URI di firma di accesso condiviso (SAS) e ricevere in modo asincrono i risultati della trascrizione. Usare la trascrizione batch per le applicazioni che devono trascrivere l'audio in blocco, ad esempio:
- Trascrizioni, didascalie o sottotitoli per l'audio preregistrato
- Analisi post-chiamata del centro contatti
- Diarizzazione
Sintesi vocale
Con la sintesi vocale, è possibile convertire il testo di input in testo umano come la sintesi vocale. Usare le voci neurali, che sono umane come voci basate su reti neurali profonde. Usare Speech Synthesis Markup Language (SSML) per ottimizzare l’intonazione, la pronuncia, la frequenza di pronuncia, il volume e altro ancora.
- Voce neurale predefinita: voci predefinite altamente naturali. Controllare gli esempi predefiniti di voci neurali nella Raccolta voci e determinare la voce corretta per le esigenze aziendali.
- Voce neurale personalizzata: oltre alle voci neurali predefinite che escono dalla scatola, è anche possibile creare una voce neurale personalizzata riconoscibile e univoca per il marchio o il prodotto. Le voci neurali personalizzate sono private e possono offrire un vantaggio competitivo. Vedere qui gli esempi di voci neurali personalizzate.
Traduzione vocale
La traduzione vocale consente di attivare la traduzione vocale in tempo reale e in più lingue in applicazioni, strumenti e dispositivi. È possibile usare questa funzionalità per il riconoscimento vocale e la traduzione vocale.
Identificazione della lingua
L'identificazione della lingua viene usata per identificare le lingue parlate nell'audio rispetto a un elenco di lingue supportate. Usare l'identificazione della lingua autonomamente, con riconoscimento vocale o con la traduzione vocale.
Riconoscimento del parlante
Il riconoscimento del parlante fornisce algoritmi che verificano e identificano i parlanti in base alle relative caratteristiche vocali univoche. Il riconoscimento del parlante consente di rispondere alla domanda "chi parla?".
Valutazione della pronuncia
La valutazione della pronuncia valuta la pronuncia vocale e fornisce ai parlanti un feedback sull'accuratezza e sulla scorrevolezza dell'audio parlato. Con la valutazione della pronuncia, gli studenti di lingue possono fare pratica, ottenere feedback immediati e migliorare la pronuncia in modo da esprimersi e presentarsi in tutta sicurezza.
Riconoscimento delle finalità
Riconoscimento delle finalità: usare il riconoscimento vocale con la comprensione del linguaggio di conversazione per derivare le finalità dell'utente dal parlato trascritto e agire sui comandi vocali.
Consegna e presenza
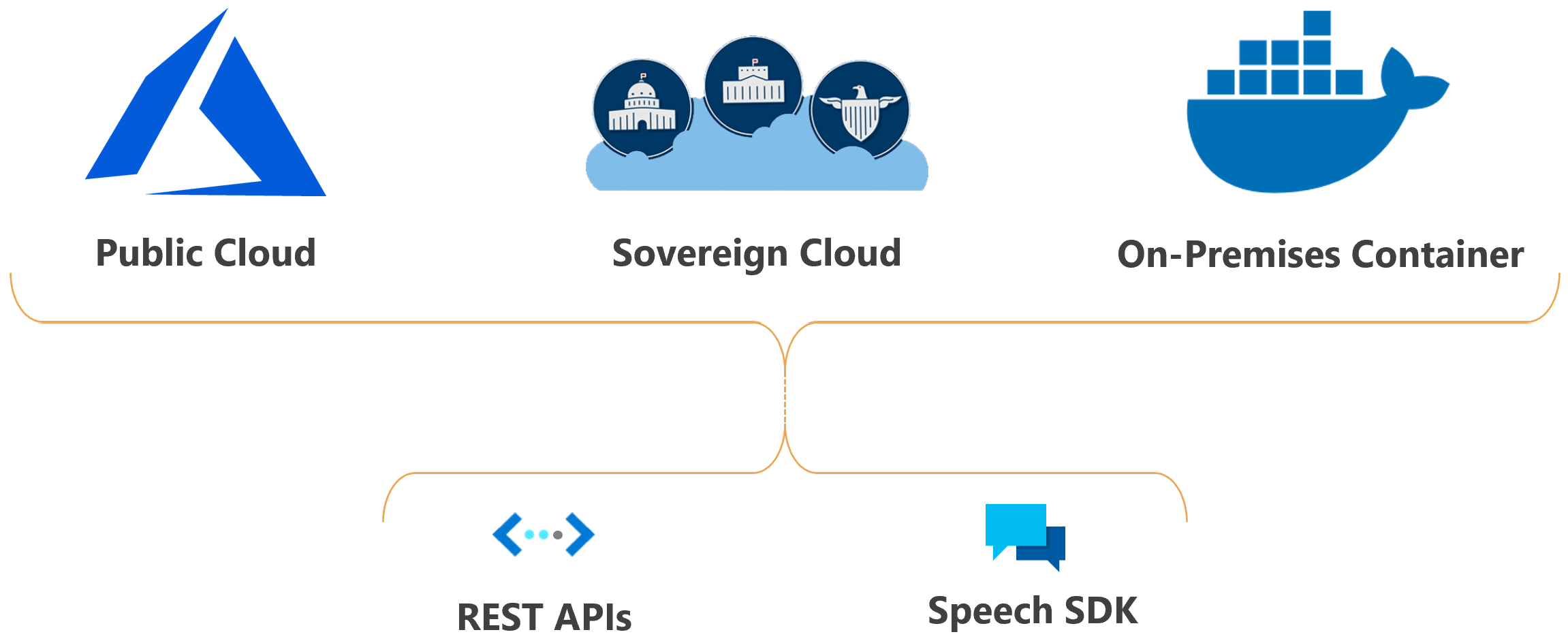
È possibile distribuire le funzionalità di Riconoscimento vocale di Intelligenza artificiale di Azure nel cloud o in locale.
I contenitori consentono di avvicinare il servizio ai dati per motivi di conformità, sicurezza o di altro tipo.
La distribuzione del servizio Voce nei cloud sovrani è disponibile per alcune entità governative e i relativi partner. Ad esempio, il cloud di Azure per enti pubblici è disponibile per le entità governative degli Stati Uniti e i relativi partner. Microsoft Azure gestito dal cloud 21Vianet è disponibile per le organizzazioni con una presenza aziendale in Cina. Per altre informazioni, vedere Cloud sovrani.
Usare Riconoscimento vocale nell'applicazione
Speech Studio è un set di strumenti basati sull'interfaccia utente per la creazione e l'integrazione di funzionalità del servizio Voce di Intelligenza artificiale di Azure nelle applicazioni. È possibile creare progetti in Speech Studio usando un approccio senza codice e quindi fare riferimento a tali asset nelle proprie applicazioni usando Speech SDK, l'interfaccia della riga di comando di Voce o le API REST.
L'interfaccia della riga di comando di Voce è uno strumento da riga di comando per l'uso del servizio Voce senza dover scrivere codice. La maggior parte delle funzionalità di Speech SDK è disponibile nell'interfaccia della riga di comando per Voce e alcune funzionalità e personalizzazioni avanzate sono semplificate nell'interfaccia della riga di comando per Voce.
Speech SDK espone molte delle funzionalità del servizio Voce che è possibile usare per sviluppare applicazioni abilitate per il riconoscimento vocale. L'SDK Voce è disponibile in molti linguaggi di programmazione e in tutte le piattaforme.
In alcuni casi, non è possibile o non è consono usare l’SDK di Voce. In questi casi, è possibile usare le API REST per accedere al servizio Voce. Ad esempio, usare le API REST per la trascrizione batch e le API REST di riconoscimento del parlante.
Operazioni preliminari
Sono disponibili guide introduttive in molti linguaggi di programmazione noti. Ognuna di esse è progettata per insegnare gli schemi progettuali di base e consentire all'utente di eseguire il codice in meno di 10 minuti. Per accedere alla guida di avvio rapido per ogni funzionalità, vedere l'elenco seguente:
- Guida di avvio rapido sul riconoscimento vocale
- Guida di avvio rapido sulla sintesi vocale
- Guida di avvio rapido sulla traduzione vocale
Esempi di codice
Il codice di esempio per il servizio Voce è disponibile in GitHub. Questi esempi esaminano gli scenari comuni, ad esempio la lettura di audio da un file o streaming, il riconoscimento continuo e singolo e l'uso di modelli personalizzati. Usare i collegamenti seguenti per visualizzare esempi SDK e REST:
- Esempi di riconoscimento vocale, sintesi vocale e traduzione vocale (SDK)
- Batch transcription samples (REST) (Esempi di trascrizione batch (REST))
- Esempi di sintesi vocale (REST)
- Voice assistant samples (SDK) (Esempi di assistente vocale - SDK)
Intelligenza artificiale responsabile
Un sistema di intelligenza artificiale include non solo la tecnologia ma anche le persone che ne fanno uso, le persone interessate e l'ambiente di distribuzione. Leggere le note sulla trasparenza per informazioni sull'uso e sulla distribuzione di intelligenza artificiale responsabile nei sistemi.
Riconoscimento vocale
- Nota sulla trasparenza e casi d'uso
- Caratteristiche e limitazioni
- Integrazione e uso responsabile
- Dati, privacy e sicurezza
Valutazione della pronuncia
Sintesi vocale neurale
- Nota sulla trasparenza e casi d'uso
- Caratteristiche e limitazioni
- Accesso limitato
- Distribuzione responsabile della sintesi vocale
- Informativa per i talenti vocali
- Informativa per i modelli di progettazione
- Informativa per gli schemi progettuali
- Codice di comportamento
- Dati, privacy e sicurezza
Riconoscimento del parlante
- Note sulla trasparenza e casi d'uso
- Caratteristiche e limitazioni
- Accesso limitato
- Linee guida generali
- Dati, privacy e sicurezza