Guida introduttiva: Riconoscere e convertire la voce in testo scritto
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. Questa anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
In questo argomento di avvio rapido si prova a usare la sintesi vocale in tempo reale in Azure AI Foundry.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito.
- Alcune funzionalità dei servizi di intelligenza artificiale di Azure sono gratuite per provare nel portale di Azure AI Foundry. Per accedere a tutte le funzionalità descritte in questo articolo, è necessario connettere i servizi di intelligenza artificiale in Azure AI Foundry.
Provare il riconoscimento vocale in tempo reale
Passare al progetto Azure AI Foundry. Se è necessario creare un progetto, vedere Creare un progetto Azure AI Foundry.
Selezionare Playgrounds (Playground) nel riquadro sinistro e quindi selezionare un playground da usare. In questo esempio selezionare Prova il playground voce.
Facoltativamente, è possibile selezionare una connessione diversa da usare nel playground. Nel playground voce è possibile connettersi alle risorse multiservizio di Servizi di intelligenza artificiale di Azure o alle risorse del servizio Voce.
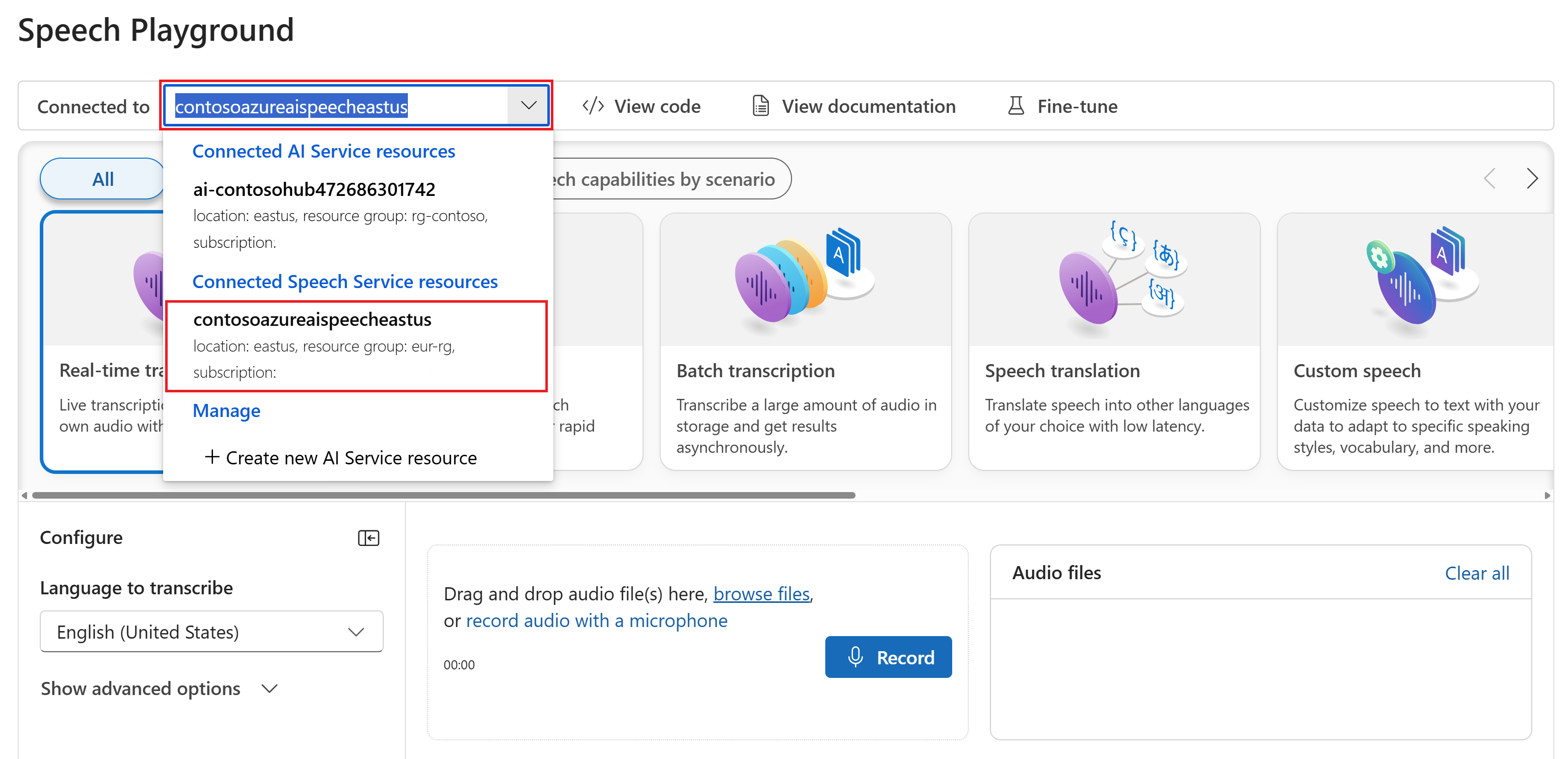
Selezionare Trascrizione in tempo reale.
Selezionare Mostra opzioni avanzate per configurare le opzioni di riconoscimento vocale, ad esempio:
- Identificazione della lingua: usata per identificare le lingue parlate nell'audio rispetto a un elenco di lingue supportate. Per altre informazioni sulle opzioni di identificazione della lingua, ad esempio l'approccio all'avvio e il riconoscimento continuo, vedere Identificazione della lingua.
- Diarizzazione del parlante: usato per identificare e separare i parlanti nell'audio. La diarizzazione distingue tra i diversi relatori che partecipano alla conversazione. Il servizio Voce fornisce informazioni sull’oratore che ha pronunciato una particolare parte del discorso trascritto. Per altre informazioni sulla diarizzazione del parlante, vedere la guida introduttiva sul riconoscimento vocale in tempo reale con diarizzazione del parlante.
- Endpoint personalizzato: usare un modello distribuito dal riconoscimento vocale personalizzato per migliorare l'accuratezza del riconoscimento. Per usare il modello di base di Microsoft, lasciare questa opzione impostata su Nessuno. Per altre informazioni sul riconoscimento vocale personalizzato, vedere Riconoscimento vocale personalizzato.
- Formato di output: scegliere tra formati di output semplici e dettagliati. L'output semplice include il formato di visualizzazione e i timestamp. L'output dettagliato include più formati (ad esempio display, lessicale, ITN e ITN mascherato), timestamp ed elenchi N-best.
- Elenco frasi: consente di migliorare l'accuratezza della trascrizione fornendo un elenco di frasi note, ad esempio nomi di persone o posizioni specifiche. Usare virgole o punti e virgola per separare ogni valore nell'elenco di frasi. Per altre informazioni sugli elenchi di frasi, vedere Elenchi di frasi.
Selezionare un file audio da caricare o registrare audio in tempo reale. In questo esempio viene usato il file
Call1_separated_16k_health_insurance.wavdisponibile nel repository Speech SDK in GitHub. È possibile scaricare il file o usare il proprio file audio.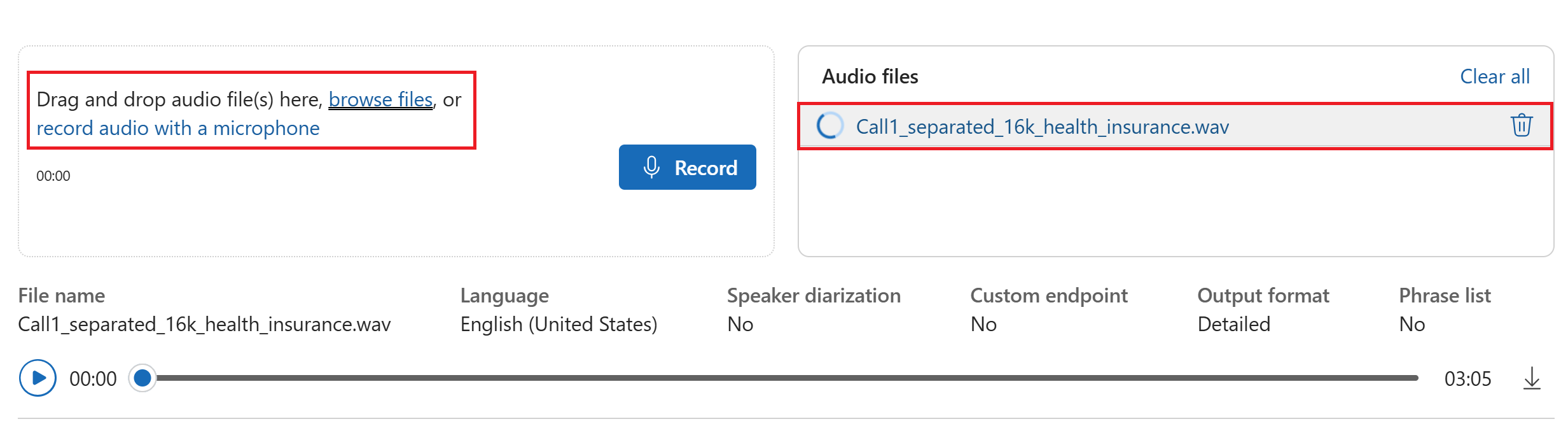
È possibile visualizzare la trascrizione in tempo reale nella parte inferiore della pagina.
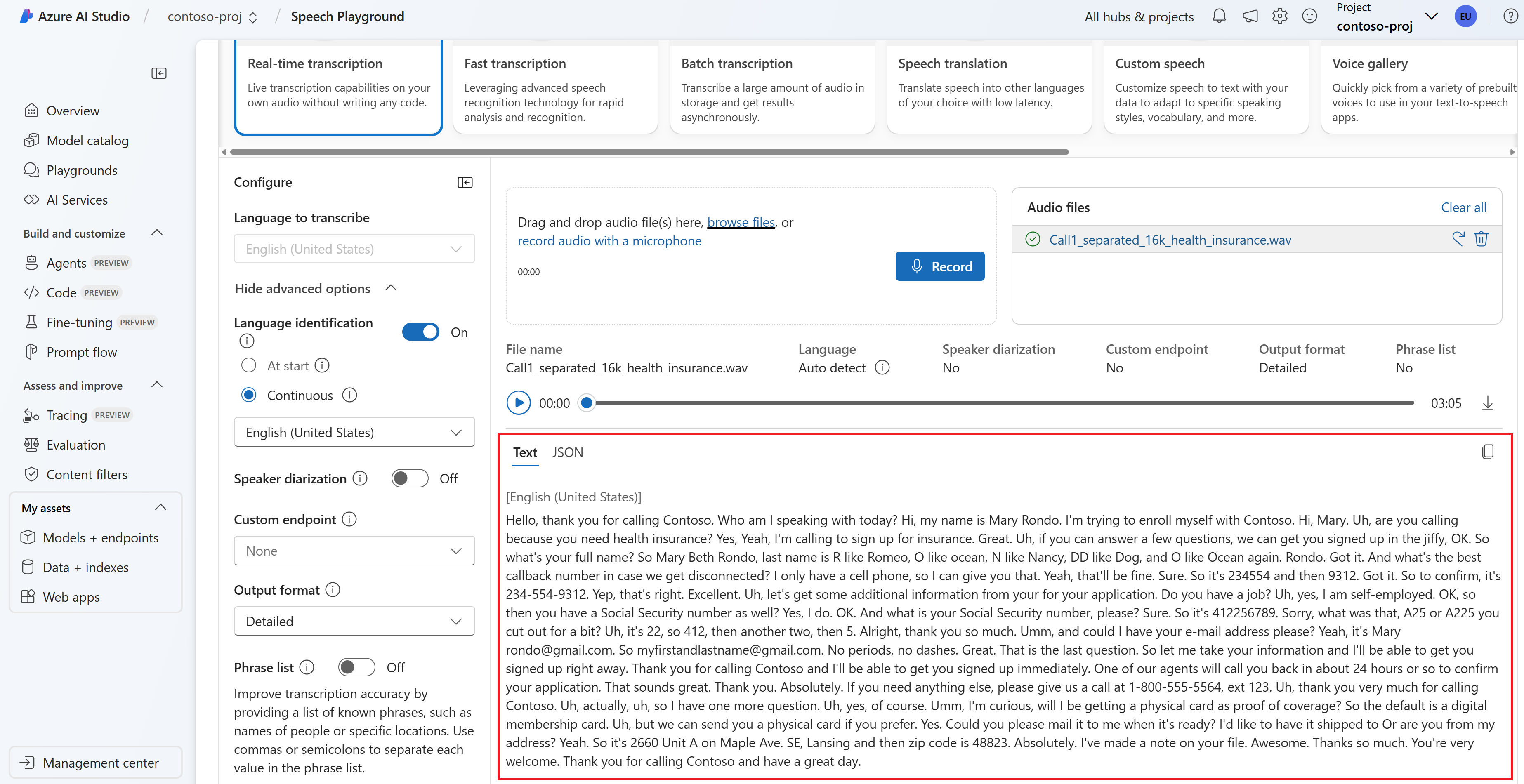
È possibile selezionare la scheda JSON per visualizzare l'output JSON della trascrizione. Le proprietà includono
Offset,Duration,DisplayRecognitionStatus,Lexical, ,ITNe altro ancora.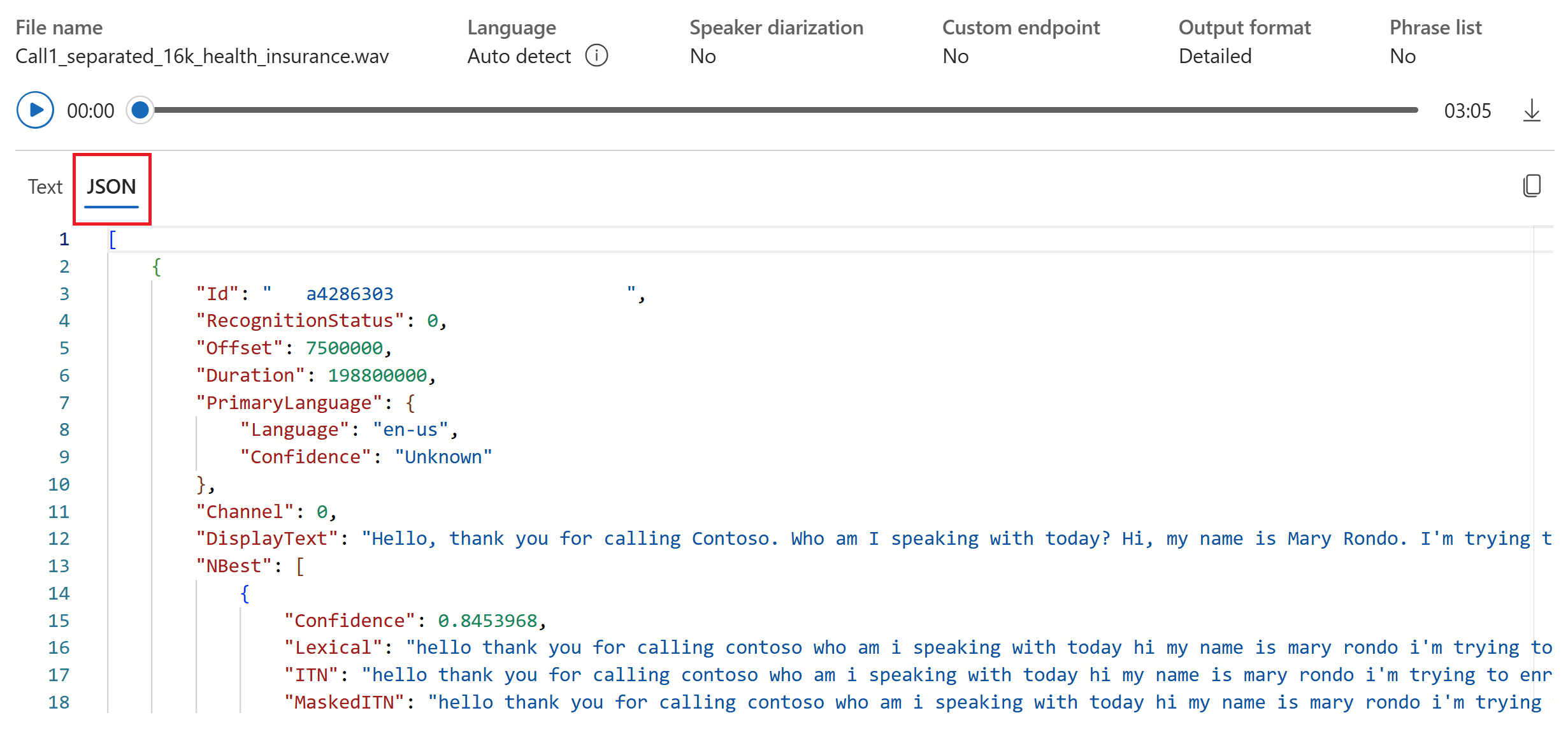





Documentazione di riferimento | Pacchetto (NuGet) | Ulteriori esempi in GitHub
Questa guida introduttiva spiega come creare ed eseguire un'applicazione per riconoscere e trascrivere il parlato in testo scritto in tempo reale.
Per trascrivere invece i file audio in modo asincrono, vedere Che cos'è la trascrizione batch. Se non si è certi della soluzione di riconoscimento vocale più adatta, vedere Che cos'è il riconoscimento vocale?
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Configurare l'ambiente
Speech SDK è disponibile come pacchetto NuGet e implementa .NET Standard 2.0. L'SDK Voce verrà installato più avanti in questa guida. Per altri requisiti, vedere Installare Speech SDK.
Impostare le variabili di ambiente
È necessario autenticare l'applicazione per accedere ai Servizi di Azure AI. Questo articolo illustra come usare le variabili di ambiente per archiviare le credenziali. È quindi possibile accedere alle variabili di ambiente dal codice per autenticare l'applicazione. Per l'ambiente di produzione, usare un modo più sicuro per archiviare e accedere alle credenziali.
Importante
Si consiglia l'autenticazione di Microsoft Entra ID insieme alle identità gestite per le risorse di Azure al fine di evitare di archiviare le credenziali con le applicazioni eseguite nel cloud.
Se si usa una chiave API, archiviarla in modo sicuro in un'altra posizione, ad esempio in Azure Key Vault. Non includere la chiave API direttamente nel codice e non esporla mai pubblicamente.
Per altre informazioni sulla sicurezza dei servizi di intelligenza artificiale, vedere Autenticare le richieste a Servizi di Azure AI.
Per impostare le variabili di ambiente per la chiave e l'area della risorsa Voce, aprire una finestra della console e seguire le istruzioni per il sistema operativo e l'ambiente di sviluppo.
- Per impostare la variabile di ambiente
SPEECH_KEY, sostituire chiave-utente con una delle chiavi della risorsa. - Per impostare la variabile di ambiente
SPEECH_REGION, sostituire area-utente con una delle aree della risorsa.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se è sufficiente accedere alla variabile di ambiente nella console corrente, è possibile impostare la variabile di ambiente con set anziché setx.
Dopo l'aggiunta delle variabili di ambiente potrebbe essere necessario riavviare eventuali programmi che devono leggere la variabile di ambiente, inclusa la finestra della console. Se ad esempio si usa Visual Studio come editor, riavviare Visual Studio prima di eseguire l'esempio.
Riconoscimento vocale da un microfono
Suggerimento
Provare Azure AI Speech Toolkit per compilare ed eseguire facilmente esempi in Visual Studio Code.
Seguire questi passaggi per creare un'applicazione console e installare Speech SDK.
Aprire una finestra del prompt dei comandi nella cartella in cui si desidera il nuovo progetto. Eseguire questo comando per creare un'applicazione console con l'interfaccia della riga di comando di .NET.
dotnet new consoleQuesto comando crea il file Program.cs nella directory del progetto.
Installare Speech SDK nel nuovo progetto con l'interfaccia della riga di comando di .NET.
dotnet add package Microsoft.CognitiveServices.SpeechSostituire il contenuto di Program.cs con il codice seguente:
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }Per modificare la lingua del riconoscimento vocale sostituire
en-UScon un'altra lingua supportata. Ad esempio,es-ESper spagnolo (Spagna). Se non si specifica un valore, il valore predefinito èen-US. Per informazioni dettagliate su come identificare una delle tante lingue da poter usare, vedere Identificazione della lingua.Eseguire la nuova applicazione console per avviare il riconoscimento vocale da microfono:
dotnet runImportante
Assicurarsi di impostare
SPEECH_KEYeSPEECH_REGIONcome variabili di ambiente. Se queste variabili non vengono impostate, l'esempio avrà esito negativo e riporterà un messaggio di errore.Parlare al microfono quando richiesto. Il parlato deve essere mostrato come testo:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Osservazioni:
Ecco alcune altre considerazioni:
In questo esempio viene usata l'operazione
RecognizeOnceAsyncper trascrivere espressioni fino a 30 secondi o fino a quando non si arresta dopo un periodo di silenzio. Per informazioni sul riconoscimento continuo di un audio più lungo, incluse le conversazioni multilingue, vedere Come riconoscere il parlato.Per riconoscere il parlato da un file audio, usare
FromWavFileInputanzichéFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");Per i file audio compressi, ad esempio MP4, installare GStreamer e usare
PullAudioInputStreamoPushAudioInputStream. Per altre informazioni vedere Come usare audio di input compresso.
Pulire le risorse
Per rimuovere la risorsa Voce creata è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.
Documentazione di riferimento | Pacchetto (NuGet) | Ulteriori esempi in GitHub
Questa guida introduttiva spiega come creare ed eseguire un'applicazione per riconoscere e trascrivere il parlato in testo scritto in tempo reale.
Per trascrivere invece i file audio in modo asincrono, vedere Che cos'è la trascrizione batch. Se non si è certi della soluzione di riconoscimento vocale più adatta, vedere Che cos'è il riconoscimento vocale?
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Configurare l'ambiente
Speech SDK è disponibile come pacchetto NuGet e implementa .NET Standard 2.0. L'SDK Voce verrà installato più avanti in questa guida. Per altri requisiti, vedere Installare Speech SDK.
Impostare le variabili di ambiente
È necessario autenticare l'applicazione per accedere ai Servizi di Azure AI. Questo articolo illustra come usare le variabili di ambiente per archiviare le credenziali. È quindi possibile accedere alle variabili di ambiente dal codice per autenticare l'applicazione. Per l'ambiente di produzione, usare un modo più sicuro per archiviare e accedere alle credenziali.
Importante
Si consiglia l'autenticazione di Microsoft Entra ID insieme alle identità gestite per le risorse di Azure al fine di evitare di archiviare le credenziali con le applicazioni eseguite nel cloud.
Se si usa una chiave API, archiviarla in modo sicuro in un'altra posizione, ad esempio in Azure Key Vault. Non includere la chiave API direttamente nel codice e non esporla mai pubblicamente.
Per altre informazioni sulla sicurezza dei servizi di intelligenza artificiale, vedere Autenticare le richieste a Servizi di Azure AI.
Per impostare le variabili di ambiente per la chiave e l'area della risorsa Voce, aprire una finestra della console e seguire le istruzioni per il sistema operativo e l'ambiente di sviluppo.
- Per impostare la variabile di ambiente
SPEECH_KEY, sostituire chiave-utente con una delle chiavi della risorsa. - Per impostare la variabile di ambiente
SPEECH_REGION, sostituire area-utente con una delle aree della risorsa.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se è sufficiente accedere alla variabile di ambiente nella console corrente, è possibile impostare la variabile di ambiente con set anziché setx.
Dopo l'aggiunta delle variabili di ambiente potrebbe essere necessario riavviare eventuali programmi che devono leggere la variabile di ambiente, inclusa la finestra della console. Se ad esempio si usa Visual Studio come editor, riavviare Visual Studio prima di eseguire l'esempio.
Riconoscimento vocale da un microfono
Suggerimento
Provare Azure AI Speech Toolkit per compilare ed eseguire facilmente esempi in Visual Studio Code.
Seguire questi passaggi per creare un'applicazione console e installare Speech SDK.
Creare un nuovo progetto console C++ in Visual Studio Community con il nome
SpeechRecognition.Fare clic su Strumenti>Gestione Pacchetti NuGet>Console di Gestione pacchetti. Nella console di Gestione pacchetti, eseguire questo comando:
Install-Package Microsoft.CognitiveServices.SpeechSostituire il contenuto di
SpeechRecognition.cppcon il codice seguente:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Per modificare la lingua del riconoscimento vocale, sostituire
en-UScon un'altra lingua supportata. Ad esempio,es-ESper spagnolo (Spagna). Se non si specifica un valore, il valore predefinito èen-US. Per informazioni dettagliate su come identificare una delle tante lingue da poter usare, vedere Identificazione della lingua.Compila ed esegui la nuova applicazione console per avviare il riconoscimento vocale da microfono.
Importante
Assicurarsi di impostare
SPEECH_KEYeSPEECH_REGIONcome variabili di ambiente. Se queste variabili non vengono impostate, l'esempio avrà esito negativo e riporterà un messaggio di errore.Parlare al microfono quando richiesto. Il parlato deve essere mostrato come testo:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Osservazioni:
Ecco alcune altre considerazioni:
In questo esempio viene usata l'operazione
RecognizeOnceAsyncper trascrivere espressioni fino a 30 secondi o fino a quando non si arresta dopo un periodo di silenzio. Per informazioni sul riconoscimento continuo di un audio più lungo, incluse le conversazioni multilingue, vedere Come riconoscere il parlato.Per riconoscere il parlato da un file audio, usare
FromWavFileInputanzichéFromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");Per i file audio compressi, ad esempio MP4, installare GStreamer e usare
PullAudioInputStreamoPushAudioInputStream. Per altre informazioni vedere Come usare audio di input compresso.
Pulire le risorse
Per rimuovere la risorsa Voce creata è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.
Documentazione di riferimento | Pacchetto (Go) | Ulteriori esempi in GitHub
Questa guida introduttiva spiega come creare ed eseguire un'applicazione per riconoscere e trascrivere il parlato in testo scritto in tempo reale.
Per trascrivere invece i file audio in modo asincrono, vedere Che cos'è la trascrizione batch. Se non si è certi della soluzione di riconoscimento vocale più adatta, vedere Che cos'è il riconoscimento vocale?
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Configurare l'ambiente
Installare Speech SDK per Go. Per i requisiti e le istruzioni, consultare Installare Speech SDK.
Impostare le variabili di ambiente
È necessario autenticare l'applicazione per accedere ai Servizi di Azure AI. Questo articolo illustra come usare le variabili di ambiente per archiviare le credenziali. È quindi possibile accedere alle variabili di ambiente dal codice per autenticare l'applicazione. Per l'ambiente di produzione, usare un modo più sicuro per archiviare e accedere alle credenziali.
Importante
Si consiglia l'autenticazione di Microsoft Entra ID insieme alle identità gestite per le risorse di Azure al fine di evitare di archiviare le credenziali con le applicazioni eseguite nel cloud.
Se si usa una chiave API, archiviarla in modo sicuro in un'altra posizione, ad esempio in Azure Key Vault. Non includere la chiave API direttamente nel codice e non esporla mai pubblicamente.
Per altre informazioni sulla sicurezza dei servizi di intelligenza artificiale, vedere Autenticare le richieste a Servizi di Azure AI.
Per impostare le variabili di ambiente per la chiave e l'area della risorsa Voce, aprire una finestra della console e seguire le istruzioni per il sistema operativo e l'ambiente di sviluppo.
- Per impostare la variabile di ambiente
SPEECH_KEY, sostituire chiave-utente con una delle chiavi della risorsa. - Per impostare la variabile di ambiente
SPEECH_REGION, sostituire area-utente con una delle aree della risorsa.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se è sufficiente accedere alla variabile di ambiente nella console corrente, è possibile impostare la variabile di ambiente con set anziché setx.
Dopo l'aggiunta delle variabili di ambiente potrebbe essere necessario riavviare eventuali programmi che devono leggere la variabile di ambiente, inclusa la finestra della console. Se ad esempio si usa Visual Studio come editor, riavviare Visual Studio prima di eseguire l'esempio.
Riconoscimento vocale da un microfono
Attenersi alla procedura seguente per creare un modulo GO.
Aprire una finestra del prompt dei comandi nella cartella in cui si desidera il nuovo progetto. Creare un nuovo file denominato speech-recognition.go.
Copiare il codice seguente in speech-recognition.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }Eseguire i comandi seguenti per creare un file go.mod che si collega ai componenti ospitati in GitHub:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goImportante
Assicurarsi di impostare
SPEECH_KEYeSPEECH_REGIONcome variabili di ambiente. Se queste variabili non vengono impostate, l'esempio avrà esito negativo e riporterà un messaggio di errore.Compilare ed eseguire il codice:
go build go run speech-recognition
Pulire le risorse
Per rimuovere la risorsa Voce creata, è possibile usare il portale di Azure o l'interfaccia della riga di comando (CLI) di Azure.
Documentazione di riferimento | Ulteriori esempi in GitHub
Questa guida introduttiva spiega come creare ed eseguire un'applicazione per riconoscere e trascrivere il parlato in testo scritto in tempo reale.
Per trascrivere invece i file audio in modo asincrono, vedere Che cos'è la trascrizione batch. Se non si è certi della soluzione di riconoscimento vocale più adatta, vedere Che cos'è il riconoscimento vocale?
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Configurare l'ambiente
Per configurare l'ambiente, installare Speech SDK. L'esempio in questo avvio rapido funziona con Runtime Java.
Installare Apache Maven. Quindi eseguire
mvn -vper confermare l'installazione corretta.Creare un nuovo file
pom.xmlnella radice del progetto copiando il codice seguente:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Installare Speech SDK e le dipendenze.
mvn clean dependency:copy-dependencies
Impostare le variabili di ambiente
È necessario autenticare l'applicazione per accedere ai Servizi di Azure AI. Questo articolo illustra come usare le variabili di ambiente per archiviare le credenziali. È quindi possibile accedere alle variabili di ambiente dal codice per autenticare l'applicazione. Per l'ambiente di produzione, usare un modo più sicuro per archiviare e accedere alle credenziali.
Importante
Si consiglia l'autenticazione di Microsoft Entra ID insieme alle identità gestite per le risorse di Azure al fine di evitare di archiviare le credenziali con le applicazioni eseguite nel cloud.
Se si usa una chiave API, archiviarla in modo sicuro in un'altra posizione, ad esempio in Azure Key Vault. Non includere la chiave API direttamente nel codice e non esporla mai pubblicamente.
Per altre informazioni sulla sicurezza dei servizi di intelligenza artificiale, vedere Autenticare le richieste a Servizi di Azure AI.
Per impostare le variabili di ambiente per la chiave e l'area della risorsa Voce, aprire una finestra della console e seguire le istruzioni per il sistema operativo e l'ambiente di sviluppo.
- Per impostare la variabile di ambiente
SPEECH_KEY, sostituire chiave-utente con una delle chiavi della risorsa. - Per impostare la variabile di ambiente
SPEECH_REGION, sostituire area-utente con una delle aree della risorsa.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se è sufficiente accedere alla variabile di ambiente nella console corrente, è possibile impostare la variabile di ambiente con set anziché setx.
Dopo l'aggiunta delle variabili di ambiente potrebbe essere necessario riavviare eventuali programmi che devono leggere la variabile di ambiente, inclusa la finestra della console. Se ad esempio si usa Visual Studio come editor, riavviare Visual Studio prima di eseguire l'esempio.
Riconoscimento vocale da un microfono
Seguire questi passaggi per creare un'applicazione console per il riconoscimento vocale.
Creare un nuovo file denominato SpeechRecognition.java nella stessa directory radice del progetto.
Copiare il codice seguente in SpeechRecognition.java:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }Per modificare la lingua del riconoscimento vocale sostituire
en-UScon un'altra lingua supportata. Ad esempio,es-ESper spagnolo (Spagna). Se non si specifica un valore, il valore predefinito èen-US. Per informazioni dettagliate su come identificare una delle tante lingue da poter usare, vedere Identificazione della lingua.Eseguire la nuova applicazione console per avviare il riconoscimento vocale da microfono:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionImportante
Assicurarsi di impostare
SPEECH_KEYeSPEECH_REGIONcome variabili di ambiente. Se queste variabili non vengono impostate, l'esempio avrà esito negativo e riporterà un messaggio di errore.Parlare al microfono quando richiesto. Il parlato deve essere mostrato come testo:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Osservazioni:
Ecco alcune altre considerazioni:
In questo esempio viene usata l'operazione
RecognizeOnceAsyncper trascrivere espressioni fino a 30 secondi o fino a quando non si arresta dopo un periodo di silenzio. Per informazioni sul riconoscimento continuo di un audio più lungo, incluse le conversazioni multilingue, vedere Come riconoscere il parlato.Per riconoscere il parlato da un file audio, usare
fromWavFileInputanzichéfromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");Per i file audio compressi, ad esempio MP4, installare GStreamer e usare
PullAudioInputStreamoPushAudioInputStream. Per altre informazioni vedere Come usare audio di input compresso.
Pulire le risorse
Per rimuovere la risorsa Voce creata è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.
Documentazione di riferimento | Pacchetto (npm) | Ulteriori esempi in GitHub | Codice sorgente della libreria
Questa guida introduttiva spiega come creare ed eseguire un'applicazione per riconoscere e trascrivere il parlato in testo scritto in tempo reale.
Per trascrivere invece i file audio in modo asincrono, vedere Che cos'è la trascrizione batch. Se non si è certi della soluzione di riconoscimento vocale più adatta, vedere Che cos'è il riconoscimento vocale?
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
È necessario anche un file audio .wav nel computer locale. È possibile usare il proprio file .wav (fino a 30 secondi) o scaricare il file di esempio https://crbn.us/whatstheweatherlike.wav.
Configurare l'ambiente
Per configurare l'ambiente, installare Speech SDK per JavaScript. Eseguire questo comando: npm install microsoft-cognitiveservices-speech-sdk. Per le istruzioni di installazione guidata, consultare Installare Speech SDK.
Impostare le variabili di ambiente
È necessario autenticare l'applicazione per accedere ai Servizi di Azure AI. Questo articolo illustra come usare le variabili di ambiente per archiviare le credenziali. È quindi possibile accedere alle variabili di ambiente dal codice per autenticare l'applicazione. Per l'ambiente di produzione, usare un modo più sicuro per archiviare e accedere alle credenziali.
Importante
Si consiglia l'autenticazione di Microsoft Entra ID insieme alle identità gestite per le risorse di Azure al fine di evitare di archiviare le credenziali con le applicazioni eseguite nel cloud.
Se si usa una chiave API, archiviarla in modo sicuro in un'altra posizione, ad esempio in Azure Key Vault. Non includere la chiave API direttamente nel codice e non esporla mai pubblicamente.
Per altre informazioni sulla sicurezza dei servizi di intelligenza artificiale, vedere Autenticare le richieste a Servizi di Azure AI.
Per impostare le variabili di ambiente per la chiave e l'area della risorsa Voce, aprire una finestra della console e seguire le istruzioni per il sistema operativo e l'ambiente di sviluppo.
- Per impostare la variabile di ambiente
SPEECH_KEY, sostituire chiave-utente con una delle chiavi della risorsa. - Per impostare la variabile di ambiente
SPEECH_REGION, sostituire area-utente con una delle aree della risorsa.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se è sufficiente accedere alla variabile di ambiente nella console corrente, è possibile impostare la variabile di ambiente con set anziché setx.
Dopo l'aggiunta delle variabili di ambiente potrebbe essere necessario riavviare eventuali programmi che devono leggere la variabile di ambiente, inclusa la finestra della console. Se ad esempio si usa Visual Studio come editor, riavviare Visual Studio prima di eseguire l'esempio.
Riconoscimento vocale da un file
Suggerimento
Provare Azure AI Speech Toolkit per compilare ed eseguire facilmente esempi in Visual Studio Code.
Seguire questi passaggi per creare un'applicazione console Node.js per il riconoscimento vocale.
Aprire una finestra del prompt dei comandi in cui si desidera posizionare il nuovo progetto e creare un nuovo file denominato SpeechRecognition.js.
Installare Speech SDK per JavaScript:
npm install microsoft-cognitiveservices-speech-sdkCopiare il codice seguente in SpeechRecognition.js:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();In SpeechRecognition.js sostituire YourAudioFile.wav con il proprio file .wav. Questo esempio supporta solo il riconoscimento vocale da file .wav. Per informazioni su altri formati audio vedere Come usare audio di input compresso. Questo esempio supporta fino a 30 secondi di audio.
Per modificare la lingua del riconoscimento vocale sostituire
en-UScon un'altra lingua supportata. Ad esempio,es-ESper spagnolo (Spagna). Se non si specifica un valore, il valore predefinito èen-US. Per informazioni dettagliate su come identificare una delle tante lingue da poter usare, vedere Identificazione della lingua.Eseguire la nuova applicazione console per avviare il riconoscimento vocale da file:
node.exe SpeechRecognition.jsImportante
Assicurarsi di impostare
SPEECH_KEYeSPEECH_REGIONcome variabili di ambiente. Se queste variabili non vengono impostate, l'esempio avrà esito negativo e riporterà un messaggio di errore.Il parlato nel file audio deve essere restituito come testo:
RECOGNIZED: Text=I'm excited to try speech to text.
Osservazioni:
In questo esempio viene usata l'operazione recognizeOnceAsync per trascrivere espressioni fino a 30 secondi o fino a quando non si arresta dopo un periodo di silenzio. Per informazioni sul riconoscimento continuo di un audio più lungo, incluse le conversazioni multilingue, vedere Come riconoscere il parlato.
Nota
Il riconoscimento vocale da microfono non è supportato in Node.js. È supportato solo in un ambiente JavaScript basato su browser. Per altre informazioni, vedere l'esempio React e l'implementazione del riconoscimento vocale da un microfono in GitHub.
L'esempio React mostra modelli di progettazione per lo scambio e la gestione dei token di autenticazione. Mostra anche l'acquisizione dell'audio da un microfono o da un file per le conversioni della voce in testo scritto.
Pulire le risorse
Per rimuovere la risorsa Voce creata è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.
Documentazione di riferimento | Pacchetto (PyPi) | Ulteriori esempi in GitHub
Questa guida introduttiva spiega come creare ed eseguire un'applicazione per riconoscere e trascrivere il parlato in testo scritto in tempo reale.
Per trascrivere invece i file audio in modo asincrono, vedere Che cos'è la trascrizione batch. Se non si è certi della soluzione di riconoscimento vocale più adatta, vedere Che cos'è il riconoscimento vocale?
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Configurare l'ambiente
Speech SDK per Python è disponibile come modulo Python Package Index (PyPI). Speech SDK per Python è compatibile con Windows, Linux e macOS.
- Per Windows, installare Microsoft Visual C++ Redistributable per Visual Studio 2015, 2017, 2019 e 2022 per la piattaforma. La prima installazione di questo pacchetto potrebbe richiedere un riavvio.
- In Linux è necessario usare l'architettura di destinazione x64.
Installare Python 3.7 o una versione successiva. Per altri requisiti, vedere Installare Speech SDK.
Impostare le variabili di ambiente
È necessario autenticare l'applicazione per accedere ai Servizi di Azure AI. Questo articolo illustra come usare le variabili di ambiente per archiviare le credenziali. È quindi possibile accedere alle variabili di ambiente dal codice per autenticare l'applicazione. Per l'ambiente di produzione, usare un modo più sicuro per archiviare e accedere alle credenziali.
Importante
Si consiglia l'autenticazione di Microsoft Entra ID insieme alle identità gestite per le risorse di Azure al fine di evitare di archiviare le credenziali con le applicazioni eseguite nel cloud.
Se si usa una chiave API, archiviarla in modo sicuro in un'altra posizione, ad esempio in Azure Key Vault. Non includere la chiave API direttamente nel codice e non esporla mai pubblicamente.
Per altre informazioni sulla sicurezza dei servizi di intelligenza artificiale, vedere Autenticare le richieste a Servizi di Azure AI.
Per impostare le variabili di ambiente per la chiave e l'area della risorsa Voce, aprire una finestra della console e seguire le istruzioni per il sistema operativo e l'ambiente di sviluppo.
- Per impostare la variabile di ambiente
SPEECH_KEY, sostituire chiave-utente con una delle chiavi della risorsa. - Per impostare la variabile di ambiente
SPEECH_REGION, sostituire area-utente con una delle aree della risorsa.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se è sufficiente accedere alla variabile di ambiente nella console corrente, è possibile impostare la variabile di ambiente con set anziché setx.
Dopo l'aggiunta delle variabili di ambiente potrebbe essere necessario riavviare eventuali programmi che devono leggere la variabile di ambiente, inclusa la finestra della console. Se ad esempio si usa Visual Studio come editor, riavviare Visual Studio prima di eseguire l'esempio.
Riconoscimento vocale da un microfono
Suggerimento
Provare Azure AI Speech Toolkit per compilare ed eseguire facilmente esempi in Visual Studio Code.
Seguire questi passaggi per creare un'applicazione console.
Aprire una finestra del prompt dei comandi nella cartella in cui si desidera il nuovo progetto. Creare un nuovo file denominato speech_recognition.py.
Eseguire questo comando per installare Speech SDK:
pip install azure-cognitiveservices-speechCopiare il codice seguente in speech_recognition.py:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()Per modificare la lingua del riconoscimento vocale sostituire
en-UScon un'altra lingua supportata. Ad esempio,es-ESper spagnolo (Spagna). Se non si specifica un valore, il valore predefinito èen-US. Per informazioni dettagliate su come identificare una delle tante lingue da poter usare, vedere Identificazione della lingua.Eseguire la nuova applicazione console per avviare il riconoscimento vocale da microfono:
python speech_recognition.pyImportante
Assicurarsi di impostare
SPEECH_KEYeSPEECH_REGIONcome variabili di ambiente. Se queste variabili non vengono impostate, l'esempio avrà esito negativo e riporterà un messaggio di errore.Parlare al microfono quando richiesto. Il parlato deve essere mostrato come testo:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Osservazioni:
Ecco alcune altre considerazioni:
In questo esempio viene usata l'operazione
recognize_once_asyncper trascrivere espressioni fino a 30 secondi o fino a quando non si arresta dopo un periodo di silenzio. Per informazioni sul riconoscimento continuo di un audio più lungo, incluse le conversazioni multilingue, vedere Come riconoscere il parlato.Per riconoscere il parlato da un file audio, usare
filenameanzichéuse_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")Per i file audio compressi, ad esempio MP4, installare GStreamer e usare
PullAudioInputStreamoPushAudioInputStream. Per altre informazioni vedere Come usare audio di input compresso.
Pulire le risorse
Per rimuovere la risorsa Voce creata è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.
Documentazione di riferimento | Pacchetto (download) | Ulteriori esempi in GitHub
Questa guida introduttiva spiega come creare ed eseguire un'applicazione per riconoscere e trascrivere il parlato in testo scritto in tempo reale.
Per trascrivere invece i file audio in modo asincrono, vedere Che cos'è la trascrizione batch. Se non si è certi della soluzione di riconoscimento vocale più adatta, vedere Che cos'è il riconoscimento vocale?
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Configurare l'ambiente
Speech SDK per Swift viene distribuito come bundle framework. Il framework supporta sia Objective-C che Swift sia in iOS che in macOS.
Speech SDK può essere usato nei progetti Xcode come CocoaPod o scaricato direttamente qui e collegato manualmente. Questa guida usa CocoaPod. Installare il gestore di dipendenze di CocoaPod come descritto in queste istruzioni per l'installazione.
Impostare le variabili di ambiente
È necessario autenticare l'applicazione per accedere ai Servizi di Azure AI. Questo articolo illustra come usare le variabili di ambiente per archiviare le credenziali. È quindi possibile accedere alle variabili di ambiente dal codice per autenticare l'applicazione. Per l'ambiente di produzione, usare un modo più sicuro per archiviare e accedere alle credenziali.
Importante
Si consiglia l'autenticazione di Microsoft Entra ID insieme alle identità gestite per le risorse di Azure al fine di evitare di archiviare le credenziali con le applicazioni eseguite nel cloud.
Se si usa una chiave API, archiviarla in modo sicuro in un'altra posizione, ad esempio in Azure Key Vault. Non includere la chiave API direttamente nel codice e non esporla mai pubblicamente.
Per altre informazioni sulla sicurezza dei servizi di intelligenza artificiale, vedere Autenticare le richieste a Servizi di Azure AI.
Per impostare le variabili di ambiente per la chiave e l'area della risorsa Voce, aprire una finestra della console e seguire le istruzioni per il sistema operativo e l'ambiente di sviluppo.
- Per impostare la variabile di ambiente
SPEECH_KEY, sostituire chiave-utente con una delle chiavi della risorsa. - Per impostare la variabile di ambiente
SPEECH_REGION, sostituire area-utente con una delle aree della risorsa.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se è sufficiente accedere alla variabile di ambiente nella console corrente, è possibile impostare la variabile di ambiente con set anziché setx.
Dopo l'aggiunta delle variabili di ambiente potrebbe essere necessario riavviare eventuali programmi che devono leggere la variabile di ambiente, inclusa la finestra della console. Se ad esempio si usa Visual Studio come editor, riavviare Visual Studio prima di eseguire l'esempio.
Riconoscimento vocale da un microfono
Seguire questa procedura per riconoscere il parlato in un'applicazione macOS.
Clonare il repository Azure-Samples/cognitive-services-speech-sdk per ottenere il progetto di esempio Riconosci parlato da un microfono in Swift su macOS usando Speech SDK. Il repository include anche esempi di iOS.
Passare alla directory dell'app di esempio scaricata (
helloworld) in un terminale.Eseguire il comando
pod install. Verrà generata un'area di lavoro Xcodehelloworld.xcworkspacecontenente l'app di esempio e Speech SDK come dipendenza.Aprire l'area di lavoro
helloworld.xcworkspacein Xcode.Aprire il file denominato AppDelegate.swift e individuare i metodi
applicationDidFinishLaunchingerecognizeFromMiccome illustrato di seguito.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }In AppDelegate.m usare le variabili di ambiente impostate in precedenza per la chiave e l'area della risorsa Voce.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]Per modificare la lingua del riconoscimento vocale sostituire
en-UScon un'altra lingua supportata. Ad esempio,es-ESper spagnolo (Spagna). Se non si specifica un valore, il valore predefinito èen-US. Per informazioni dettagliate su come identificare una delle tante lingue da poter usare, vedere Identificazione della lingua.Per rendere visibile l'output di debug, selezionare Visualizza>Area di debug>Attiva console.
Compilare ed eseguire il codice di esempio scegliendo Prodotto>Esegui dal menu o selezionando il pulsante Riproduci.
Importante
Assicurarsi di impostare
SPEECH_KEYeSPEECH_REGIONcome variabili di ambiente. Se queste variabili non vengono impostate, l'esempio avrà esito negativo e riporterà un messaggio di errore.
Dopo avere selezionato il pulsante Riconosci nell'app e aver pronunciato alcune parole, verrà visualizzata la trascrizione di testo del parlato nella parte inferiore dello schermo. Quando si esegue l'app per la prima volta, chiede l'accesso al microfono del computer.
Osservazioni:
In questo esempio viene usata l'operazione recognizeOnce per trascrivere espressioni fino a 30 secondi o fino a quando non si arresta dopo un periodo di silenzio. Per informazioni sul riconoscimento continuo di un audio più lungo, incluse le conversazioni multilingue, vedere Come riconoscere il parlato.
Objective-C
Speech SDK per Objective-C condivide le librerie client e la documentazione di riferimento con Speech SDK per Swift. Per esempi di codice Objective-C, vedere il progetto di esempio riconoscimento vocale da un microfono in Objective-C in macOS in GitHub.
Pulire le risorse
Per rimuovere la risorsa Voce creata è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.
Informazioni di riferimento sull'API REST di riconoscimento vocale | Informazioni di riferimento sull'API REST di riconoscimento vocale per audio brevi | Ulteriori esempi in GitHub
Questa guida introduttiva spiega come creare ed eseguire un'applicazione per riconoscere e trascrivere il parlato in testo scritto in tempo reale.
Per trascrivere invece i file audio in modo asincrono, vedere Che cos'è la trascrizione batch. Se non si è certi della soluzione di riconoscimento vocale più adatta, vedere Che cos'è il riconoscimento vocale?
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
È necessario anche un file audio .wav nel computer locale. È possibile usare il proprio file .wav fino a 60 secondi o scaricare il file di esempio https://crbn.us/whatstheweatherlike.wav.
Impostare le variabili di ambiente
È necessario autenticare l'applicazione per accedere ai Servizi di Azure AI. Questo articolo illustra come usare le variabili di ambiente per archiviare le credenziali. È quindi possibile accedere alle variabili di ambiente dal codice per autenticare l'applicazione. Per l'ambiente di produzione, usare un modo più sicuro per archiviare e accedere alle credenziali.
Importante
Si consiglia l'autenticazione di Microsoft Entra ID insieme alle identità gestite per le risorse di Azure al fine di evitare di archiviare le credenziali con le applicazioni eseguite nel cloud.
Se si usa una chiave API, archiviarla in modo sicuro in un'altra posizione, ad esempio in Azure Key Vault. Non includere la chiave API direttamente nel codice e non esporla mai pubblicamente.
Per altre informazioni sulla sicurezza dei servizi di intelligenza artificiale, vedere Autenticare le richieste a Servizi di Azure AI.
Per impostare le variabili di ambiente per la chiave e l'area della risorsa Voce, aprire una finestra della console e seguire le istruzioni per il sistema operativo e l'ambiente di sviluppo.
- Per impostare la variabile di ambiente
SPEECH_KEY, sostituire chiave-utente con una delle chiavi della risorsa. - Per impostare la variabile di ambiente
SPEECH_REGION, sostituire area-utente con una delle aree della risorsa.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se è sufficiente accedere alla variabile di ambiente nella console corrente, è possibile impostare la variabile di ambiente con set anziché setx.
Dopo l'aggiunta delle variabili di ambiente potrebbe essere necessario riavviare eventuali programmi che devono leggere la variabile di ambiente, inclusa la finestra della console. Se ad esempio si usa Visual Studio come editor, riavviare Visual Studio prima di eseguire l'esempio.
Riconoscimento vocale da un file
Aprire una finestra della console ed eseguire il comando cURL seguente. Sostituire YourAudioFile.wav con il percorso e il nome del file audio.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Importante
Assicurarsi di impostare SPEECH_KEY e SPEECH_REGION come variabili di ambiente. Se queste variabili non vengono impostate, l'esempio avrà esito negativo e riporterà un messaggio di errore.
Si dovrebbe ricevere una risposta simile a quella mostrata qui.
DisplayText deve essere il testo riconosciuto dal file audio. Il comando riconosce fino a 60 secondi di audio e lo converte in testo.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
Per altre informazioni, vedere API REST di riconoscimento vocale per audio brevi.
Pulire le risorse
Per rimuovere la risorsa Voce creata è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.
Questa guida introduttiva spiega come creare ed eseguire un'applicazione per riconoscere e trascrivere il parlato in testo scritto in tempo reale.
Per trascrivere invece i file audio in modo asincrono, vedere Che cos'è la trascrizione batch. Se non si è certi della soluzione di riconoscimento vocale più adatta, vedere Che cos'è il riconoscimento vocale?
Prerequisiti
- Una sottoscrizione di Azure. È possibile crearne uno gratuitamente.
- Creare una risorsa Voce nel portale di Azure.
- Ottenere la chiave e l'area della risorsa Voce. Dopo aver distribuito la risorsa Voce, selezionare Vai alla risorsa per visualizzare e gestire le chiavi.
Configurare l'ambiente
Seguire questi passaggi e vedere la guida di Avvio rapido sull'interfaccia della riga di comando di Voce per altri requisiti della piattaforma.
Eseguire il comando seguente dell'interfaccia della riga di comando di .NET per installare l'interfaccia della riga di comando di Voce:
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIEseguire i comandi seguenti per configurare la chiave e l'area della risorsa Voce. Sostituire
SUBSCRIPTION-KEYcon la chiave della risorsa Voce eREGIONcon l'area della risorsa Voce.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
Riconoscimento vocale da un microfono
Eseguire il comando seguente per avviare il riconoscimento vocale da un microfono:
spx recognize --microphone --source en-USParlare nel microfono e sarà possibile vedere la trascrizione delle parole in testo in tempo reale. L'interfaccia della riga di comando di Voce si arresta dopo un periodo di silenzio di 30 secondi o premendo CTRL+C.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
Osservazioni:
Ecco alcune altre considerazioni:
Per riconoscere il parlato da un file audio usare
--fileanziché--microphone. Per i file audio compressi, ad esempio MP4, installare GStreamer e usare--format. Per altre informazioni vedere Come usare audio di input compresso.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyPer migliorare l'accuratezza del riconoscimento di parole o espressioni specifiche usare un elenco di frasi. È possibile includere un elenco di frasi in linea o con un file di testo insieme al comando
recognize:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtPer modificare la lingua del riconoscimento vocale, sostituire
en-UScon un'altra lingua supportata. Ad esempio,es-ESper spagnolo (Spagna). Se non si specifica un valore, il valore predefinito èen-US.spx recognize --microphone --source es-ESPer il riconoscimento continuo di un audio più lungo di 30 secondi aggiungere
--continuous:spx recognize --microphone --source es-ES --continuousEseguire questo comando per informazioni sulle opzioni di riconoscimento vocale aggiuntive, ad esempio l'input e l'output del file:
spx help recognize
Pulire le risorse
Per rimuovere la risorsa Voce creata è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.