Che cos'è il riconoscimento vocale personalizzato?
Con Riconoscimento vocale personalizzato è possibile valutare e migliorare l'accuratezza del riconoscimento vocale per le applicazioni e i prodotti in uso. È possibile usare un modello conversione voce/testo personalizzato per il riconoscimento vocale in tempo reale, la traduzione vocale e la trascrizione in batch.
Il riconoscimento vocale usa un modello linguistico universale come modello di base sottoposto a training con dati di proprietà di Microsoft e riflette la lingua parlata di uso comune. Il modello di base è sottoposto a training preliminare con dialetti e fonetici che rappresentano vari domini comuni. Quando si effettua una richiesta di riconoscimento vocale, per impostazione predefinita viene usato il modello di base più recente per ogni lingua supportata. Il modello di base funziona bene nella maggior parte degli scenari di riconoscimento vocale.
È possibile usare un modello personalizzato per aumentare il modello di base al fine di migliorare il riconoscimento del vocabolario specifico del dominio dell'applicazione fornendo dati di testo per eseguire il training del modello. Questo modello può anche essere usato per migliorare il riconoscimento in base alle specifiche condizioni audio dell'applicazione fornendo dati audio con trascrizioni di riferimento.
È anche possibile eseguire il training di un modello con testo strutturato quando i dati seguono un modello, per specificare pronunce personalizzate e per personalizzare la formattazione del testo di visualizzazione con normalizzazione del testo inversa personalizzata, riscrittura personalizzata e filtro personalizzato per il contenuto volgare.
Come funziona?
Con il riconoscimento vocale personalizzato è possibile caricare i propri dati, testare ed eseguire il training di un modello personalizzato, confrontare l'accuratezza dei modelli e distribuire un modello in un endpoint personalizzato.
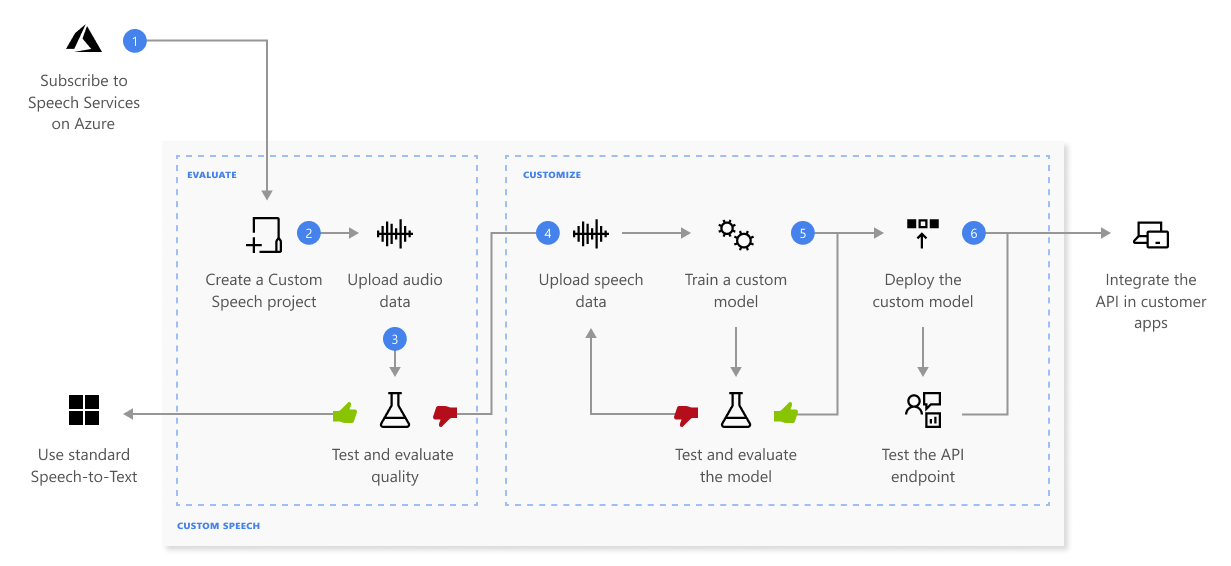
Di seguito vengono fornite informazioni più dettagliate sulla sequenza di passaggi illustrati nel diagramma precedente:
- Creare un progetto e scegliere un modello. Usare una risorsa Voce creata nel portale di Azure. Se si esegue il training di un modello personalizzato con dati audio, scegliere una risorsa di Servizi di intelligenza artificiale per l'area voce con hardware dedicato per il training dei dati audio. Per altre informazioni, vedere note a piè di pagina nella tabella delle aree.
- Caricare i dati di test. Caricare i dati di test per valutare l'offerta di riconoscimento vocale per le applicazioni, gli strumenti e i prodotti in uso.
- Testare la qualità del riconoscimento. Usare Speech Studio per riprodurre l'audio caricato ed esaminare la qualità del riconoscimento vocale dei dati di test.
- Testare un modello in modo quantitativo. Valutare e migliorare l'accuratezza del modello di riconoscimento vocale. Il servizio Voce fornisce un valore WER (Word Error Rate, Percentuale di parole errate) quantitativo, che consente di determinare se è necessario training aggiuntivo.
-
Eseguire il training di un modello. Fornire le trascrizioni scritte e il testo correlato, insieme ai dati audio corrispondenti. Testare un modello prima e dopo il training è facoltativo, ma consigliato.
Nota
Vengono addebitati l'utilizzo del modello di riconoscimento vocale personalizzato e l'hosting degli endpoint. Il training del modello di riconoscimento vocale personalizzato verrà addebitato anche se il modello di base è stato creato il 1° ottobre 2023 e in una data successiva. Non viene addebitato alcun costo per il training se il modello di base è stato creato prima di ottobre 2023. Per altre informazioni, vedere Prezzi di Voce di Azure AI e la sezione Addebito per l’adattamento nella guida alla migrazione della versione 3.2 di Riconoscimento vocale.
-
Distribuire un modello. Quando si è soddisfatti dei risultati dei test, distribuire il modello in un endpoint personalizzato. Fatta eccezione per la trascrizione batch, è necessario distribuire un endpoint personalizzato per usare un modello di Riconoscimento vocale personalizzato.
Suggerimento
Per usare Riconoscimento vocale personalizzato con l'API di trascrizione batch non è necessario un endpoint di distribuzione ospitata. È possibile risparmiare risorse se il modello di conversione voce/testo personalizzato viene usato solo per la trascrizione batch. Per altre informazioni, vedere Prezzi del servizio Voce.
Intelligenza artificiale responsabile
Un sistema di intelligenza artificiale include non solo la tecnologia ma anche le persone che ne fanno uso, le persone interessate e l'ambiente di distribuzione. Leggere le note sulla trasparenza per informazioni sull'uso e sulla distribuzione di intelligenza artificiale responsabile nei sistemi.
- Nota sulla trasparenza e casi d'uso
- Caratteristiche e limitazioni
- Integrazione e uso responsabile
- Dati, privacy e sicurezza