Configurare i flussi di dati nelle operazioni di Azure IoT
Importante
Questa pagina include istruzioni per la gestione dei componenti di Operazioni IoT di Azure usando i manifesti di distribuzione kubernetes, disponibile in anteprima. Questa funzionalità viene fornita con diverse limitazioni e non deve essere usata per i carichi di lavoro di produzione.
Vedere le condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure per termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale.
Un flusso di dati è il percorso che i dati prendono dall'origine alla destinazione con trasformazioni facoltative. È possibile configurare il flusso di dati creando una risorsa personalizzata flusso di dati o usando il portale di Azure IoT Operations Studio. Un flusso di dati è costituito da tre parti: l'origine, la trasformazione e la destinazione.

Per definire l'origine e la destinazione, è necessario configurare gli endpoint del flusso di dati. La trasformazione è facoltativa e può includere operazioni come l'arricchimento dei dati, il filtro dei dati e il mapping dei dati a un altro campo.
Importante
Ogni flusso di dati deve avere l'endpoint predefinito del broker MQTT locale di Operazioni IoT di Azure come origine o destinazione.
È possibile usare l'esperienza operativa in Operazioni IoT di Azure per creare un flusso di dati. L'esperienza operativa fornisce un'interfaccia visiva per configurare il flusso di dati. È anche possibile usare Bicep per creare un flusso di dati usando un file modello Bicep oppure usare Kubernetes per creare un flusso di dati usando un file YAML.
Continuare a leggere per informazioni su come configurare l'origine, la trasformazione e la destinazione.
Prerequisiti
È possibile distribuire flussi di dati non appena si dispone di un'istanza di Operazioni IoT di Azure usando il profilo e l'endpoint del flusso di dati predefiniti. Tuttavia, è possibile configurare profili ed endpoint del flusso di dati per personalizzare il flusso di dati.
Profilo del flusso di dati
Se non sono necessarie impostazioni di ridimensionamento diverse per i flussi di dati, usare il profilo del flusso di dati predefinito fornito dalle operazioni IoT di Azure. Per informazioni su come configurare un profilo del flusso di dati, vedere Configurare i profili del flusso di dati.
Endpoint del flusso di dati
Gli endpoint del flusso di dati sono necessari per configurare l'origine e la destinazione per il flusso di dati. Per iniziare rapidamente, è possibile usare l'endpoint del flusso di dati predefinito per il broker MQTT locale. È anche possibile creare altri tipi di endpoint del flusso di dati, ad esempio Kafka, Hub eventi o Azure Data Lake Storage. Per informazioni su come configurare ogni tipo di endpoint del flusso di dati, vedere Configurare gli endpoint del flusso di dati.
Operazioni preliminari
Dopo aver ottenuto i prerequisiti, è possibile iniziare a creare un flusso di dati.
Per creare un flusso di dati nell'esperienza operativa, selezionare Flusso>di dati Crea flusso di dati. Verrà quindi visualizzata la pagina in cui è possibile configurare l'origine, la trasformazione e la destinazione per il flusso di dati.
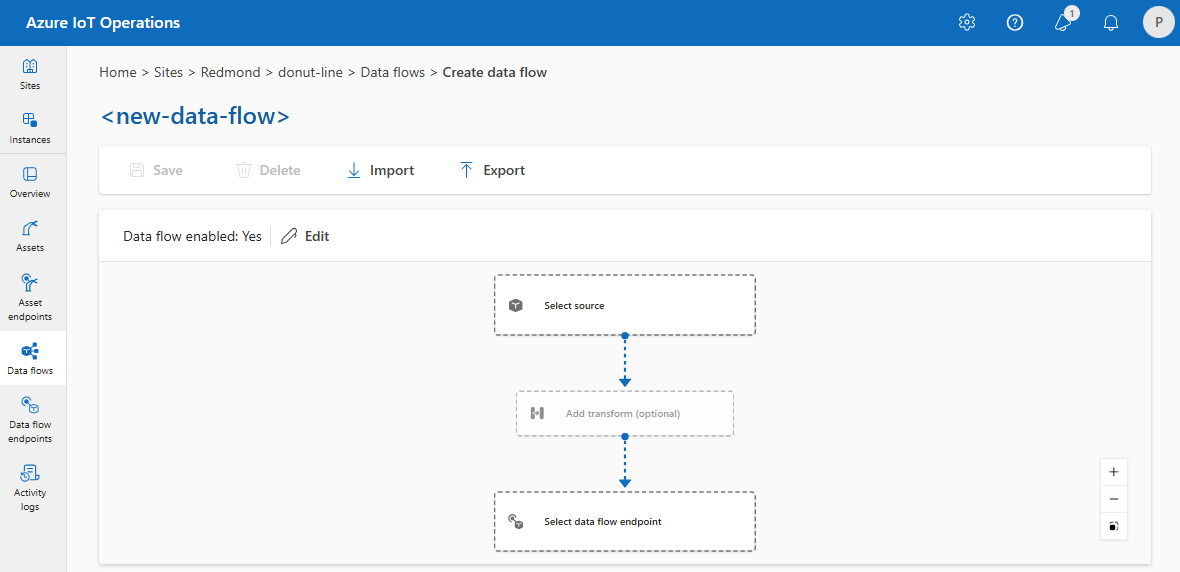
Esaminare le sezioni seguenti per informazioni su come configurare i tipi di operazione del flusso di dati.
Origine
Per configurare un'origine per il flusso di dati, specificare il riferimento all'endpoint e un elenco di origini dati per l'endpoint. Scegliere una delle opzioni seguenti come origine per il flusso di dati.
Se l'endpoint predefinito non viene usato come origine, deve essere usato come destinazione. Per altre informazioni, vedere Flussi di dati che devono usare l'endpoint broker MQTT locale.
Opzione 1: Usare l'endpoint predefinito di Message Broker come origine
In Dettagli origine selezionare Broker messaggi.
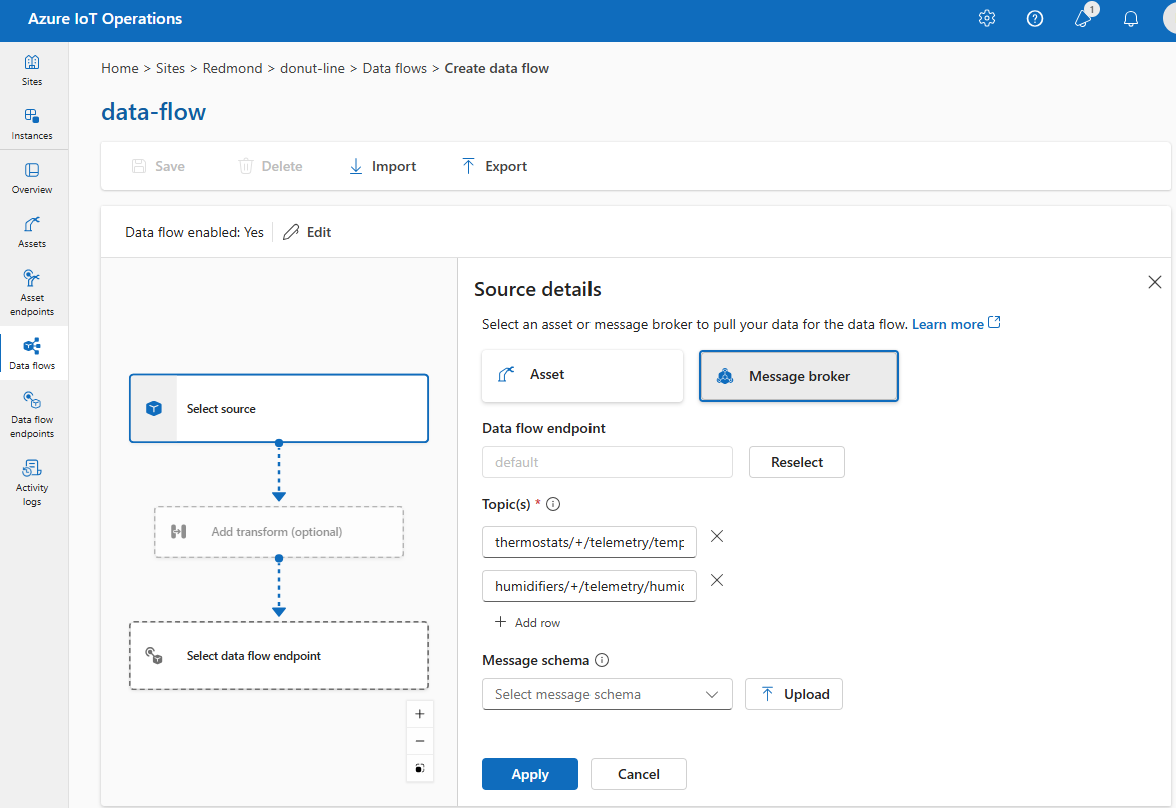
Immettere le impostazioni seguenti per l'origine del broker di messaggi:
Impostazione Descrizione Endpoint del flusso di dati Selezionare l'impostazione predefinita per usare l'endpoint predefinito del broker messaggi MQTT. Argomento Filtro dell'argomento per sottoscrivere i messaggi in arrivo. Vedere Configurare MQTT o Kafka argomenti. Schema del messaggio Schema da utilizzare per deserializzare i messaggi in arrivo. Vedere Specificare lo schema per deserializzare i dati. Selezionare Applica.
Opzione 2: Usare asset come origine
È possibile usare un asset come origine per il flusso di dati. L'uso di un asset come origine è disponibile solo nell'esperienza operativa.
In Dettagli origine selezionare Asset.
Selezionare l'asset da usare come endpoint di origine.
Selezionare Continua.
Viene visualizzato un elenco di punti dati per l'asset selezionato.
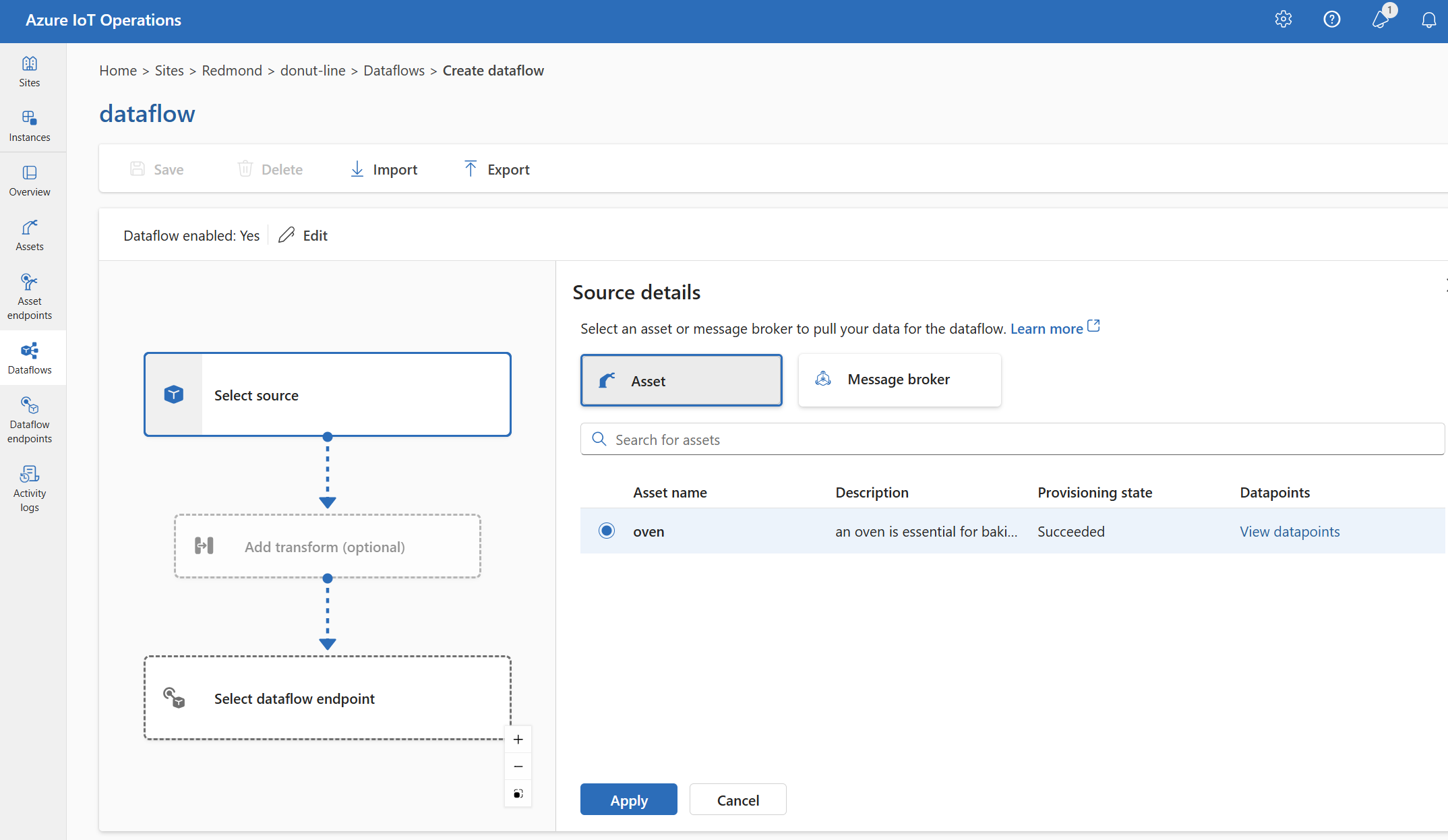
Selezionare Applica per usare l'asset come endpoint di origine.
Quando si usa un asset come origine, la definizione dell'asset viene usata per dedurre lo schema per il flusso di dati. La definizione dell'asset include lo schema per i punti dati dell'asset. Per altre informazioni, vedere Gestire le configurazioni degli asset in modalità remota.
Una volta configurati, i dati dell'asset raggiungono il flusso di dati tramite il broker MQTT locale. Pertanto, quando si usa un asset come origine, il flusso di dati usa l'endpoint predefinito del broker MQTT locale come origine in realtà.
Opzione 3: Usare l'endpoint del flusso di dati MQTT o Kafka personalizzato come origine
Se è stato creato un endpoint del flusso di dati MQTT o Kafka personalizzato (ad esempio, da usare con Griglia di eventi o Hub eventi), è possibile usarlo come origine per il flusso di dati. Tenere presente che gli endpoint dei tipi di archiviazione, ad esempio Data Lake o Fabric OneLake, non possono essere usati come origine.
In Dettagli origine selezionare Broker messaggi.
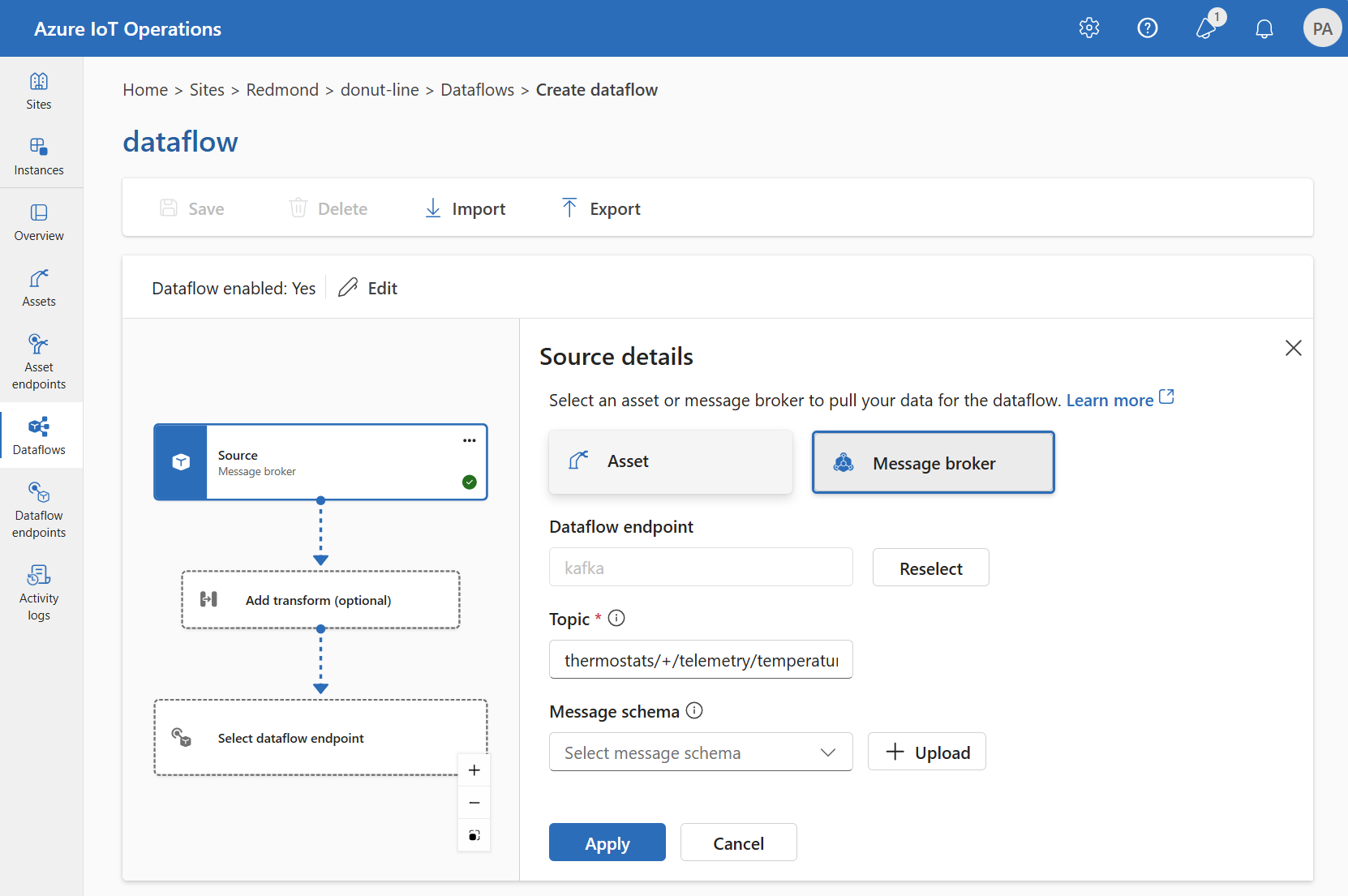
Immettere le impostazioni seguenti per l'origine del broker di messaggi:
Impostazione Descrizione Endpoint del flusso di dati Usare il pulsante Riseleziona per selezionare un endpoint del flusso di dati MQTT o Kafka personalizzato. Per altre informazioni, vedere Configurare gli endpoint del flusso di dati MQTT o Configurare gli endpoint del flusso di dati Hub eventi di Azure e Kafka. Argomento Filtro dell'argomento per sottoscrivere i messaggi in arrivo. Vedere Configurare MQTT o Kafka argomenti. Schema del messaggio Schema da utilizzare per deserializzare i messaggi in arrivo. Vedere Specificare lo schema per deserializzare i dati. Selezionare Applica.
Configurare le origini dati (argomenti MQTT o Kafka)
È possibile specificare più argomenti MQTT o Kafka in un'origine senza dover modificare la configurazione dell'endpoint del flusso di dati. Questa flessibilità significa che lo stesso endpoint può essere riutilizzato in più flussi di dati, anche se gli argomenti variano. Per altre informazioni, vedere Riutilizzare gli endpoint del flusso di dati.
Argomenti relativi a MQTT
Quando l'origine è un endpoint MQTT (Griglia di eventi incluso), è possibile usare il filtro dell'argomento MQTT per sottoscrivere i messaggi in arrivo. Il filtro dell'argomento può includere caratteri jolly per sottoscrivere più argomenti. Ad esempio, thermostats/+/telemetry/temperature/# sottoscrive tutti i messaggi di telemetria relativi alla temperatura dai termostati. Per configurare i filtri degli argomenti MQTT:
Nei dettagli dell'origine del flusso di dati dell'esperienza operativa selezionare Broker messaggi, quindi usare il campo Argomento per specificare il filtro dell'argomento MQTT per sottoscrivere i messaggi in arrivo.
Nota
Nell'esperienza operativa è possibile specificare un solo filtro di argomenti. Per usare più filtri di argomento, usare Bicep o Kubernetes.
Sottoscrizioni condivise
Per usare sottoscrizioni condivise con origini di Broker messaggi, è possibile specificare l'argomento sottoscrizione condivisa sotto forma di $shared/<GROUP_NAME>/<TOPIC_FILTER>.
In Dettagli origine flusso di dati dell'esperienza operativa selezionare Broker messaggi e usare il campo Argomento per specificare il gruppo di sottoscrizioni e l'argomento condivisi.
Se il numero di istanze nel profilo del flusso di dati è maggiore di uno, la sottoscrizione condivisa viene abilitata automaticamente per tutti i flussi di dati che usano un'origine del broker di messaggi. In questo caso, viene aggiunto il $shared prefisso e il nome del gruppo di sottoscrizioni condiviso generato automaticamente. Ad esempio, se si dispone di un profilo di flusso di dati con un numero di istanze pari a 3 e il flusso di dati usa un endpoint di Broker messaggi come origine configurata con gli argomenti topic1 e topic2, questi vengono convertiti automaticamente in sottoscrizioni condivise come $shared/<GENERATED_GROUP_NAME>/topic1 e $shared/<GENERATED_GROUP_NAME>/topic2.
È possibile creare in modo esplicito un argomento denominato $shared/mygroup/topic nella configurazione. Tuttavia, l'aggiunta esplicita dell'argomento $shared non è consigliata perché il $shared prefisso viene aggiunto automaticamente quando necessario. I flussi di dati possono apportare ottimizzazioni con il nome del gruppo, se non è impostato. Ad esempio, $share non è impostato e i flussi di dati deve operare solo sul nome dell'argomento.
Importante
I flussi di dati che richiedono una sottoscrizione condivisa quando il numero di istanze è maggiore di uno è importante quando si usa il broker MQTT di Griglia di eventi come origine perché non supporta le sottoscrizioni condivise. Per evitare messaggi mancanti, impostare il numero di istanze del profilo del flusso di dati su uno quando si usa il broker MQTT di Griglia di eventi come origine. Ovvero quando il flusso di dati è il sottoscrittore e riceve messaggi dal cloud.
Argomenti Kafka
Quando l'origine è un endpoint Kafka (hub eventi incluso), specificare i singoli argomenti Kafka a cui sottoscrivere i messaggi in arrivo. I caratteri jolly non sono supportati, pertanto è necessario specificare ogni argomento in modo statico.
Nota
Quando si usano Hub eventi tramite l'endpoint Kafka, ogni singolo hub eventi all'interno dello spazio dei nomi è l'argomento Kafka. Ad esempio, se si dispone di uno spazio dei nomi di Hub eventi con due hub thermostats eventi e humidifiers, è possibile specificare ogni hub eventi come argomento Kafka.
Per configurare gli argomenti kafka:
Nei dettagli dell'origine del flusso di dati dell'esperienza operativa selezionare Broker messaggi, quindi usare il campo Argomento per specificare il filtro dell'argomento Kafka per sottoscrivere i messaggi in arrivo.
Nota
Nell'esperienza operativa è possibile specificare un solo filtro di argomenti. Per usare più filtri di argomento, usare Bicep o Kubernetes.
Specificare lo schema di origine
Quando si usa MQTT o Kafka come origine, è possibile specificare uno schema per visualizzare l'elenco dei punti dati nel portale dell'esperienza operativa. L'uso di uno schema per deserializzare e convalidare i messaggi in ingresso non è attualmente supportato.
Se l'origine è un asset, lo schema viene dedotto automaticamente dalla definizione dell'asset.
Suggerimento
Per generare lo schema da un file di dati di esempio, usare l'helper di generazione dello schema.
Per configurare lo schema usato per deserializzare i messaggi in ingresso da un'origine:
In Dettagli origine flusso di dati dell'esperienza operativa selezionare Broker messaggi e usare il campo Schema messaggio per specificare lo schema. È possibile usare prima il pulsante Carica per caricare un file di schema. Per altre informazioni, vedere Informazioni sugli schemi dei messaggi.
Per altre informazioni, vedere Informazioni sugli schemi dei messaggi.
Trasformazione
L'operazione di trasformazione consente di trasformare i dati dall'origine prima di inviarli alla destinazione. Le trasformazioni sono facoltative. Se non è necessario apportare modifiche ai dati, non includere l'operazione di trasformazione nella configurazione del flusso di dati. Più trasformazioni vengono concatenate in fasi indipendentemente dall'ordine in cui sono specificate nella configurazione. L'ordine delle fasi è sempre:
- Arricchimento: aggiungere dati aggiuntivi ai dati di origine in base a un set di dati e a una condizione per la corrispondenza.
- Filtro: filtra i dati in base a una condizione.
- Mappa, calcolo, ridenominazione o aggiunta di una proprietà New: spostare i dati da un campo a un altro con una conversione facoltativa.
Questa sezione presenta un'introduzione alle trasformazioni del flusso di dati. Per informazioni più dettagliate, vedere Eseguire il mapping dei dati usando flussi di dati, Convertire i dati tramite conversioni di flussi di dati e Arricchire i dati tramite flussi di dati.
Nell'esperienza operativa selezionare Aggiungi trasformazione flusso>di dati (facoltativo) .
Arricchire: Aggiungere dati di riferimento
Per arricchire i dati, aggiungere prima di tutto il set di dati di riferimento nell'archivio stati di Azure IoT Operations. Il set di dati viene usato per aggiungere dati aggiuntivi ai dati di origine in base a una condizione. La condizione viene specificata come campo nei dati di origine che corrispondono a un campo nel set di dati.
È possibile caricare dati di esempio nell'archivio stati usando l'interfaccia della riga di comando dell'archivio stati. I nomi delle chiavi nell'archivio stati corrispondono a un set di dati nella configurazione del flusso di dati.
Attualmente, la fase Enrich non è supportata nell'esperienza operativa.
Se il set di dati ha un record con il campo asset, simile al seguente:
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
I dati dell'origine con la corrispondenza thermostat1 dei deviceId campi hanno i location campi e manufacturer disponibili nelle fasi di filtro e mappa.
Per altre informazioni sulla sintassi delle condizioni, vedere Arricchire i dati usando flussi di dati e Convertire i dati tramite flussi di dati.
Filtro: filtrare i dati in base a una condizione
Per filtrare i dati in base a una condizione, è possibile usare la fase filter. La condizione viene specificata come campo nei dati di origine che corrispondono a un valore.
In Trasforma (facoltativo) selezionare Filtro>Aggiungi.
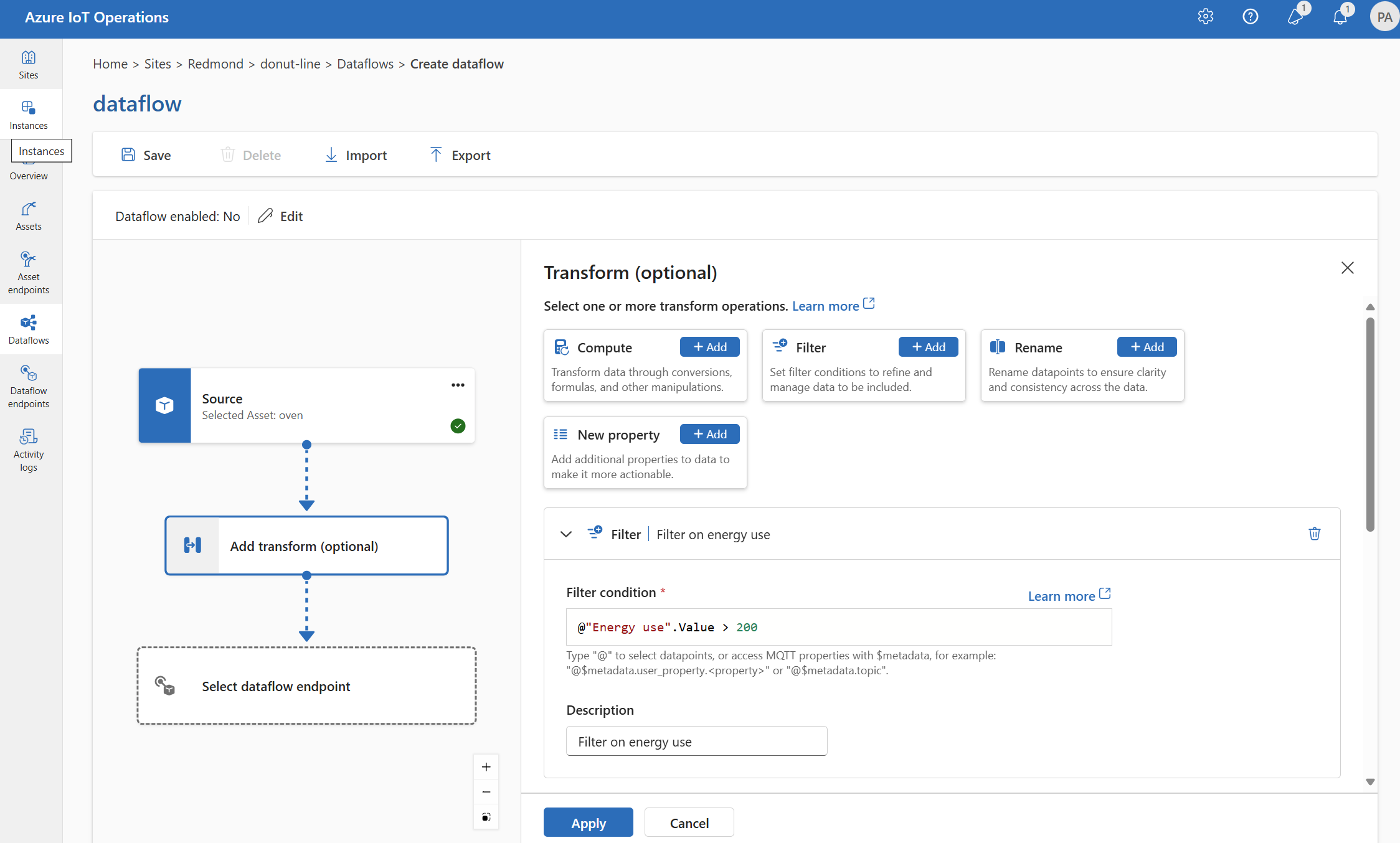
Immettere le impostazioni necessarie.
Impostazione Descrizione Condizione di filtro Condizione per filtrare i dati in base a un campo nei dati di origine. Descrizione Specificare una descrizione per la condizione di filtro. Nel campo condizione filtro immettere
@o selezionare CTRL+ SPAZIO per scegliere i punti dati da un elenco a discesa.È possibile immettere le proprietà dei metadati MQTT usando il formato
@$metadata.user_properties.<property>o@$metadata.topic. È anche possibile immettere $metadata intestazioni usando il formato@$metadata.<header>. La$metadatasintassi è necessaria solo per le proprietà MQTT che fanno parte dell'intestazione del messaggio. Per altre informazioni, vedere riferimenti ai campi.La condizione può utilizzare i campi nei dati di origine. Ad esempio, è possibile usare una condizione di filtro come
@temperature > 20filtrare i dati minori o uguali a 20 in base al campo della temperatura.Selezionare Applica.
Mappa: spostare i dati da un campo a un altro
Per eseguire il mapping dei dati a un altro campo con la conversione facoltativa, è possibile usare l'operazione map. La conversione viene specificata come formula che utilizza i campi nei dati di origine.
Nell'esperienza operativa il mapping è attualmente supportato tramite trasformazioni di calcolo, ridenominazione e nuova proprietà .
Calcolo
È possibile usare la trasformazione Calcolo per applicare una formula ai dati di origine. Questa operazione viene utilizzata per applicare una formula ai dati di origine e archiviare il campo dei risultati.
In Trasforma (facoltativo) selezionare> Calcolo aggiungi.
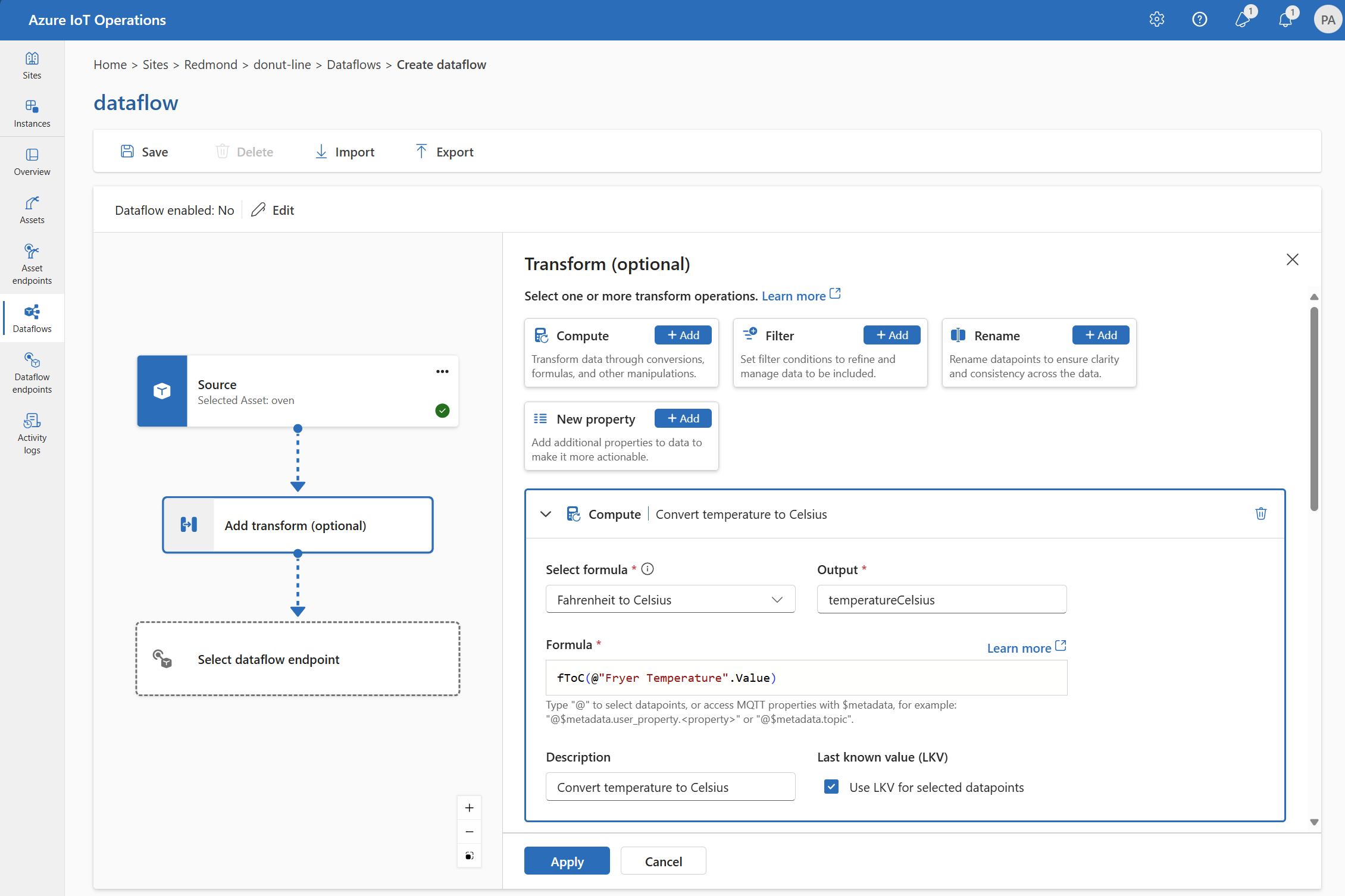
Immettere le impostazioni necessarie.
Impostazione Descrizione Selezionare la formula Scegliere una formula esistente dall'elenco a discesa o selezionare Personalizzato per immettere una formula manualmente. Output Specificare il nome visualizzato dell'output per il risultato. Formula Immettere la formula da applicare ai dati di origine. Descrizione Specificare una descrizione per la trasformazione. Ultimo valore noto Facoltativamente, usare l'ultimo valore noto se il valore corrente non è disponibile. È possibile immettere o modificare una formula nel campo Formula . La formula può utilizzare i campi nei dati di origine. Immettere
@o selezionare CTRL+SPAZIO per scegliere i punti dati da un elenco a discesa.È possibile immettere le proprietà dei metadati MQTT usando il formato
@$metadata.user_properties.<property>o@$metadata.topic. È anche possibile immettere $metadata intestazioni usando il formato@$metadata.<header>. La$metadatasintassi è necessaria solo per le proprietà MQTT che fanno parte dell'intestazione del messaggio. Per altre informazioni, vedere riferimenti ai campi.La formula può utilizzare i campi nei dati di origine. Ad esempio, è possibile usare il
temperaturecampo nei dati di origine per convertire la temperatura in Celsius e archiviarla neltemperatureCelsiuscampo di output.Selezionare Applica.
Rinomina
È possibile rinominare un punto dati usando la trasformazione Rinomina . Questa operazione viene utilizzata per rinominare un punto dati nei dati di origine in un nuovo nome. Il nuovo nome può essere usato nelle fasi successive del flusso di dati.
In Trasforma (facoltativo) selezionare Rinomina>aggiungi.
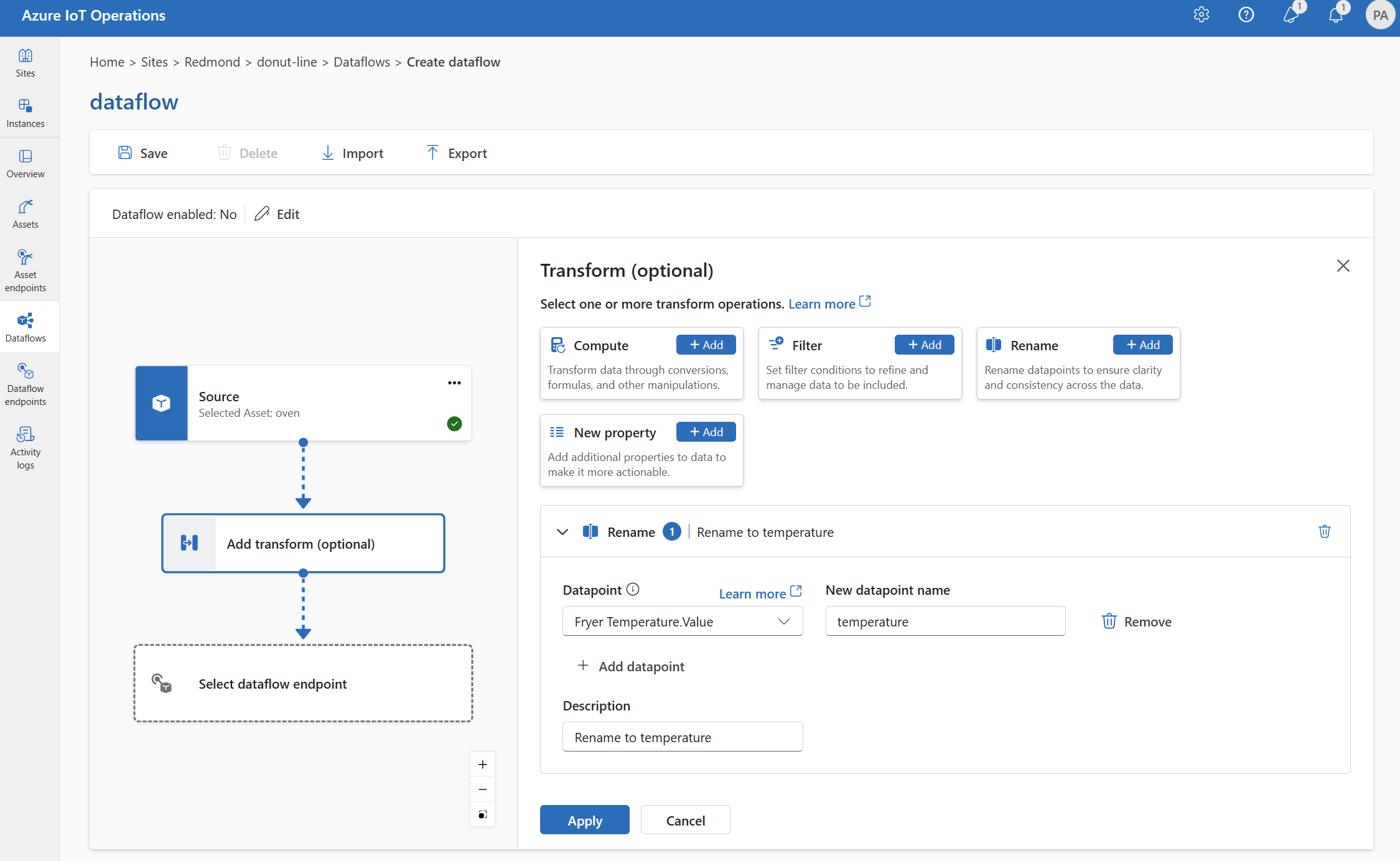
Immettere le impostazioni necessarie.
Impostazione Descrizione Datapoint Selezionare un punto dati dall'elenco a discesa o immettere un'intestazione $metadata. Nuovo nome del punto dati Immettere il nuovo nome per il punto dati. Descrizione Specificare una descrizione per la trasformazione. Immettere
@o selezionare CTRL+SPAZIO per scegliere i punti dati da un elenco a discesa.È possibile immettere le proprietà dei metadati MQTT usando il formato
@$metadata.user_properties.<property>o@$metadata.topic. È anche possibile immettere $metadata intestazioni usando il formato@$metadata.<header>. La$metadatasintassi è necessaria solo per le proprietà MQTT che fanno parte dell'intestazione del messaggio. Per altre informazioni, vedere riferimenti ai campi.Selezionare Applica.
Nuova proprietà
È possibile aggiungere una nuova proprietà ai dati di origine usando la trasformazione Nuova proprietà . Questa operazione viene utilizzata per aggiungere una nuova proprietà ai dati di origine. La nuova proprietà può essere utilizzata nelle fasi successive del flusso di dati.
In Trasforma (facoltativo) selezionare Nuova proprietà>Aggiungi.
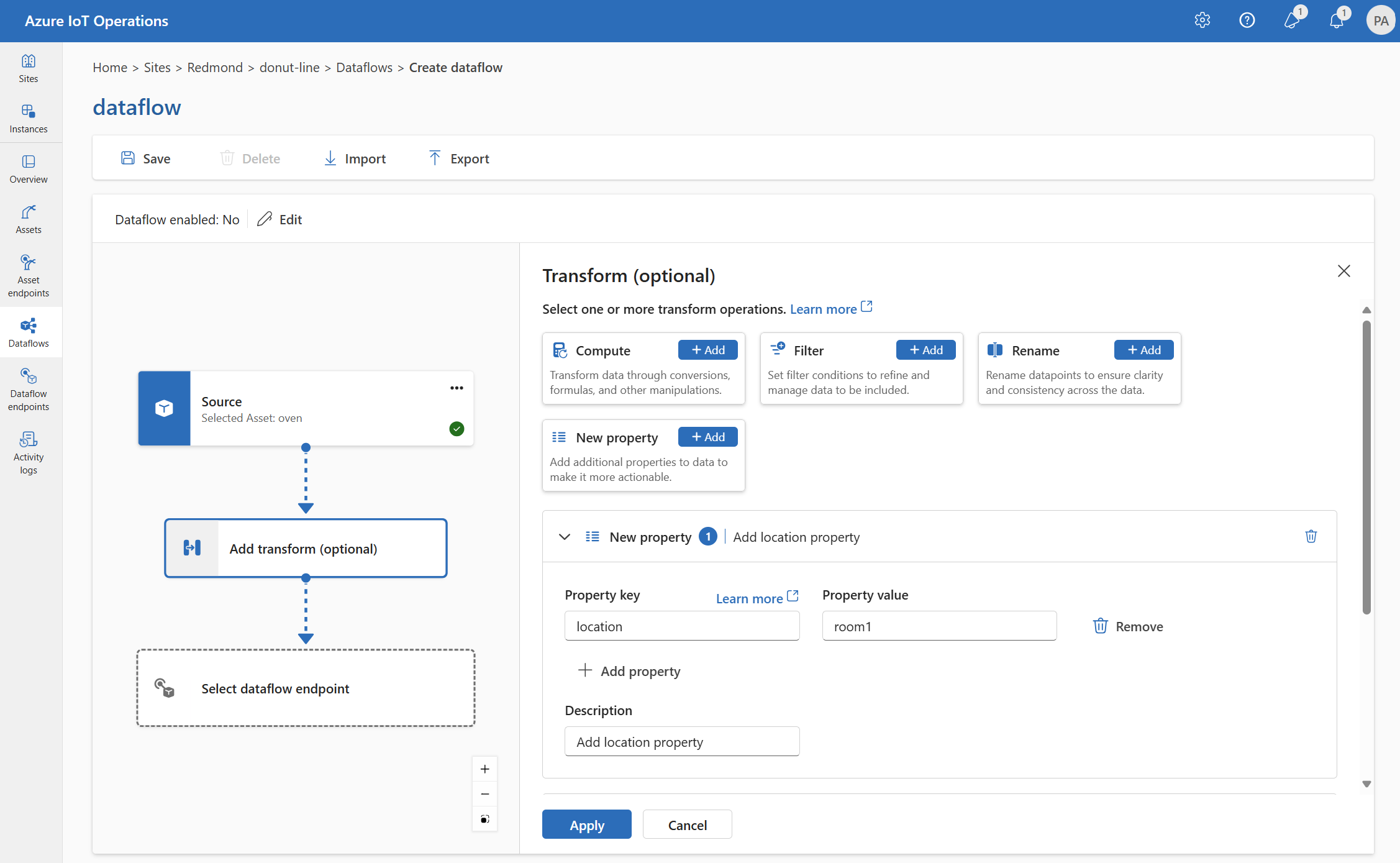
Immettere le impostazioni necessarie.
Impostazione Descrizione Chiave della proprietà Immettere la chiave per la nuova proprietà. Valore proprietà Immettere il valore per la nuova proprietà. Descrizione Specificare una descrizione per la nuova proprietà. Selezionare Applica.
Per altre informazioni, vedere Eseguire il mapping dei dati usando flussi di dati e Convertire i dati usando i flussi di dati.
Serializzare i dati in base a uno schema
Se si desidera serializzare i dati prima di inviarli alla destinazione, è necessario specificare uno schema e un formato di serializzazione. In caso contrario, i dati vengono serializzati in JSON con i tipi dedotti. Gli endpoint di archiviazione come Microsoft Fabric o Azure Data Lake richiedono uno schema per garantire la coerenza dei dati. I formati di serializzazione supportati sono Parquet e Delta.
Suggerimento
Per generare lo schema da un file di dati di esempio, usare l'helper di generazione dello schema.
Per l'esperienza operativa, specificare lo schema e il formato di serializzazione nei dettagli dell'endpoint del flusso di dati. Gli endpoint che supportano i formati di serializzazione sono Microsoft Fabric OneLake, Azure Data Lake Storage Gen 2, Azure Esplora dati e archiviazione locale. Ad esempio, per serializzare i dati in formato Delta, è necessario caricare uno schema nel Registro di sistema dello schema e farvi riferimento nella configurazione dell'endpoint di destinazione del flusso di dati.
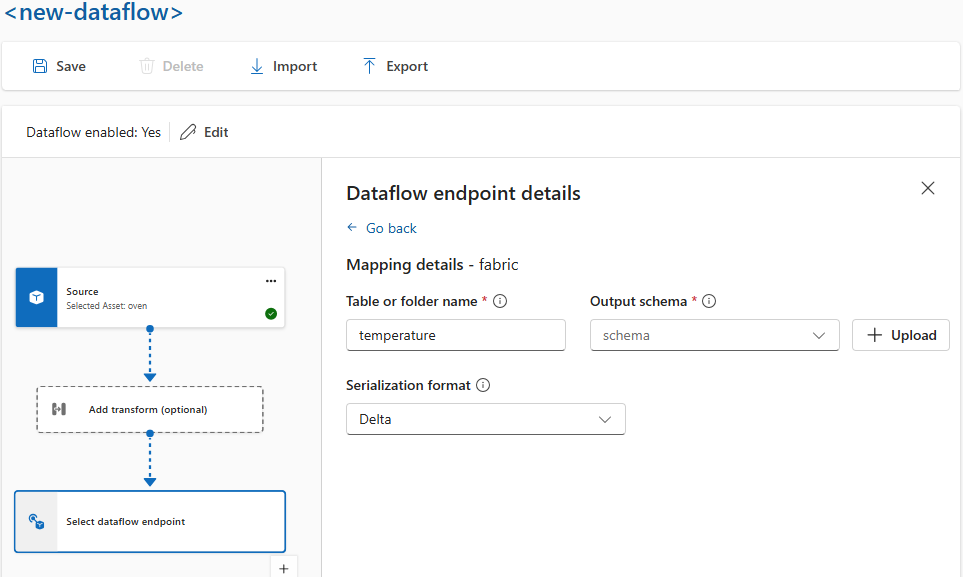
Per altre informazioni sul Registro di sistema dello schema, vedere Informazioni sugli schemi dei messaggi.
Destinazione
Per configurare una destinazione per il flusso di dati, specificare il riferimento all'endpoint e la destinazione dei dati. È possibile specificare un elenco di destinazioni dati per l'endpoint.
Per inviare dati a una destinazione diversa dal broker MQTT locale, creare un endpoint del flusso di dati. Per informazioni su come, vedere Configurare gli endpoint del flusso di dati. Se la destinazione non è il broker MQTT locale, deve essere usata come origine. Per altre informazioni, vedere Flussi di dati che devono usare l'endpoint broker MQTT locale.
Importante
Gli endpoint di archiviazione richiedono uno schema per la serializzazione. Per usare il flusso di dati con Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Esplora dati o Archiviazione locale, è necessario specificare un riferimento allo schema.
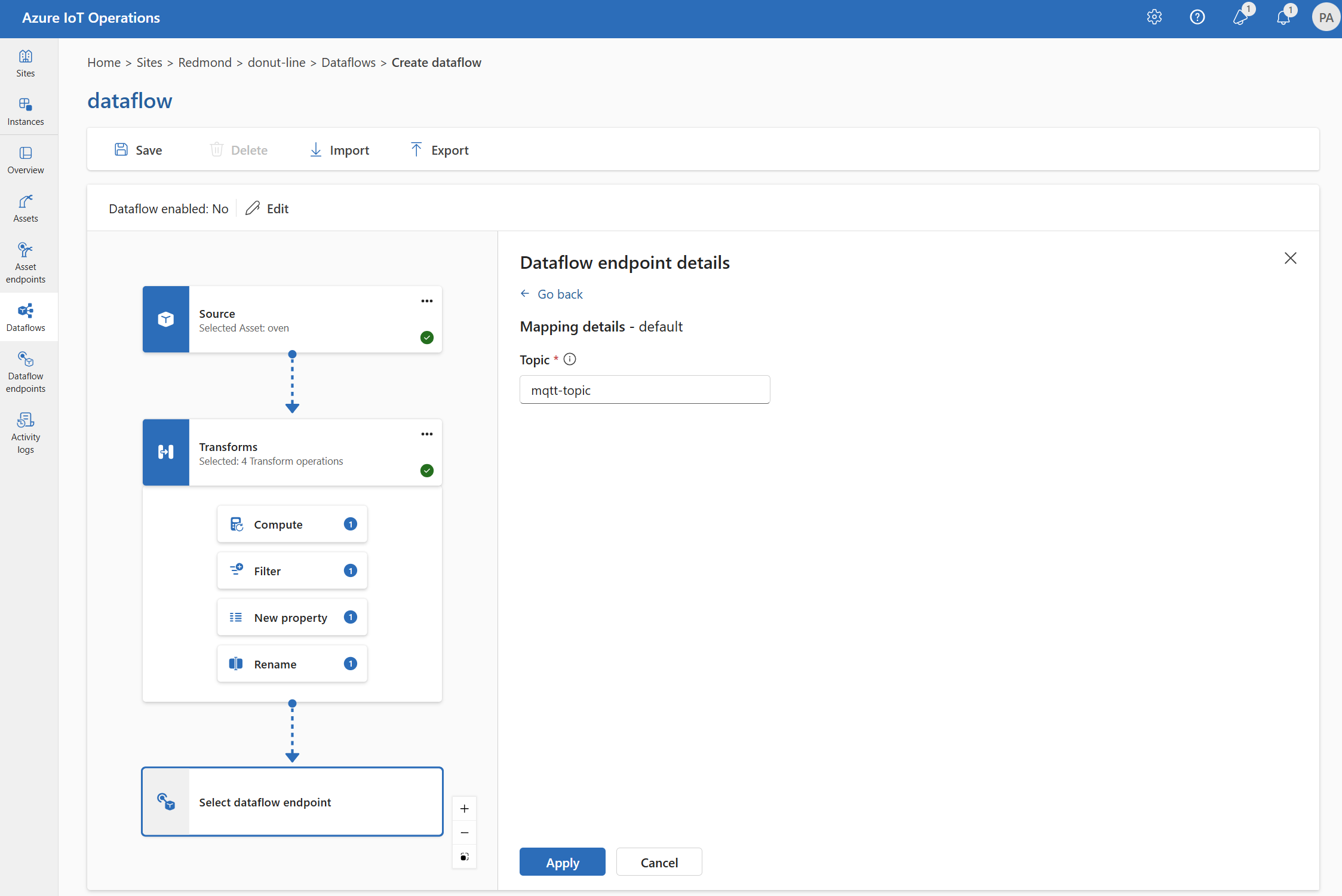
Selezionare l'endpoint del flusso di dati da usare come destinazione.
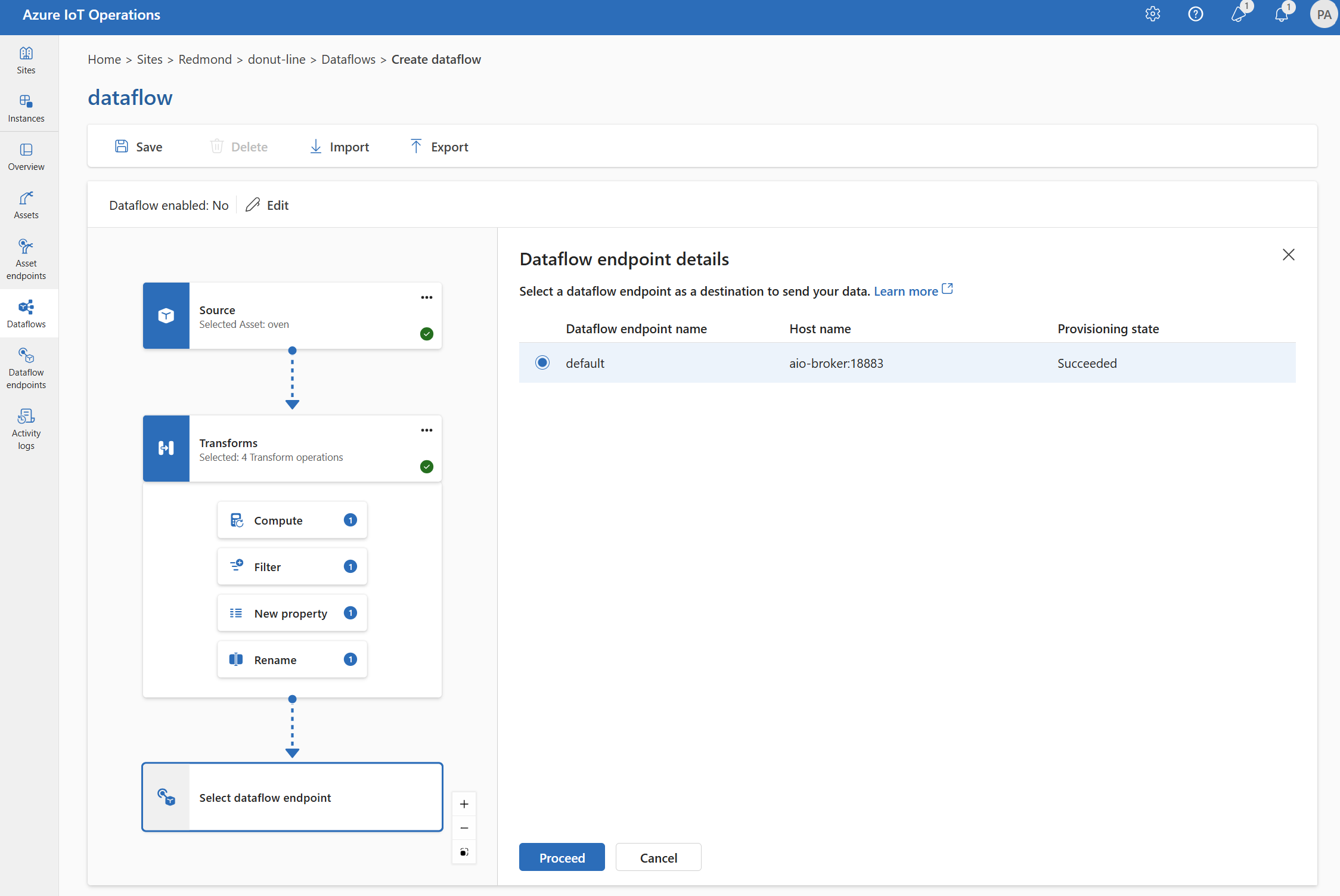
Gli endpoint di archiviazione richiedono uno schema per la serializzazione. Se si sceglie un endpoint di destinazione di Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Esplora dati o Archiviazione locale, è necessario specificare un riferimento allo schema. Ad esempio, per serializzare i dati in un endpoint di Microsoft Fabric in formato Delta, è necessario caricare uno schema nel Registro di sistema dello schema e farvi riferimento nella configurazione dell'endpoint di destinazione del flusso di dati.
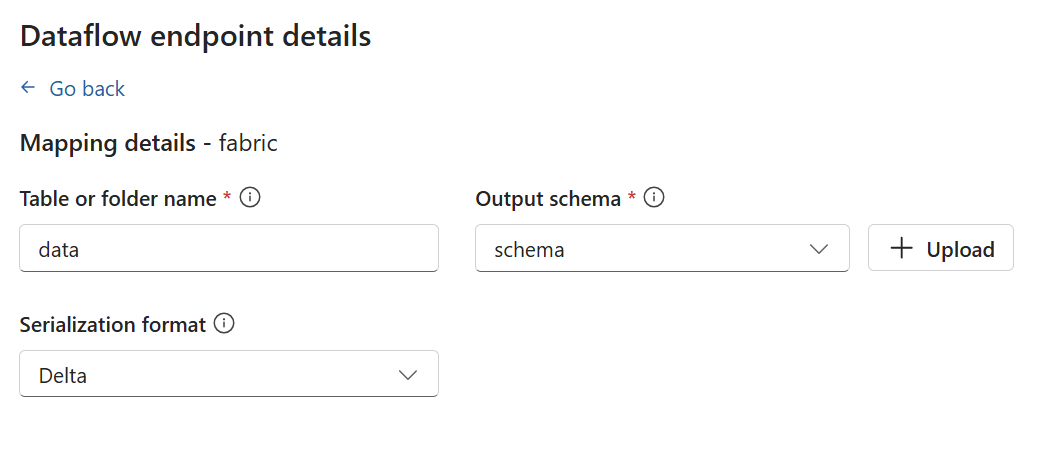
Selezionare Continua per configurare la destinazione.
Immettere le impostazioni necessarie per la destinazione, incluso l'argomento o la tabella a cui inviare i dati. Per altre informazioni, vedere Configurare la destinazione dati (argomento, contenitore o tabella ).
Configurare la destinazione dati (argomento, contenitore o tabella)
Analogamente alle origini dati, la destinazione dati è un concetto usato per mantenere riutilizzabili gli endpoint del flusso di dati tra più flussi di dati. Essenzialmente, rappresenta la sottodirectory nella configurazione dell'endpoint del flusso di dati. Ad esempio, se l'endpoint del flusso di dati è un endpoint di archiviazione, la destinazione dei dati è la tabella nell'account di archiviazione. Se l'endpoint del flusso di dati è un endpoint Kafka, la destinazione dei dati è l'argomento Kafka.
| Tipo di endpoint | Significato della destinazione dei dati | Descrizione |
|---|---|---|
| MQTT (o Griglia di eventi) | Argomento | Argomento MQTT in cui vengono inviati i dati. Sono supportati solo gli argomenti statici, senza caratteri jolly. |
| Kafka (o Hub eventi) | Argomento | Argomento Kafka in cui vengono inviati i dati. Sono supportati solo gli argomenti statici, senza caratteri jolly. Se l'endpoint è uno spazio dei nomi di Hub eventi, la destinazione dei dati è l'hub eventi singolo all'interno dello spazio dei nomi. |
| Azure Data Lake Storage | Contenitore | Contenitore nell'account di archiviazione. Non la tabella. |
| Microsoft Fabric OneLake | Tabella o cartella | Corrisponde al tipo di percorso configurato per l'endpoint. |
| Esplora dati di Azure | Tabella | Tabella nel database Esplora dati di Azure. |
| Archiviazione locale | Cartella | Nome della cartella o della directory nel montaggio permanente del volume di archiviazione locale. Quando si usa Archiviazione Azure Container abilitata dai volumi edge di inserimento cloud di Azure Arc, questo deve corrispondere al spec.path parametro per la sottovolume creata. |
Per configurare la destinazione dati:
Quando si usa l'esperienza operativa, il campo destinazione dati viene interpretato automaticamente in base al tipo di endpoint. Ad esempio, se l'endpoint del flusso di dati è un endpoint di archiviazione, la pagina dei dettagli di destinazione richiede di immettere il nome del contenitore. Se l'endpoint del flusso di dati è un endpoint MQTT, la pagina dei dettagli di destinazione richiede di immettere l'argomento e così via.
Esempio
L'esempio seguente è una configurazione del flusso di dati che usa l'endpoint MQTT per l'origine e la destinazione. L'origine filtra i dati dall'argomento azure-iot-operations/data/thermostatMQTT . La trasformazione converte la temperatura in Fahrenheit e filtra i dati in cui la temperatura moltiplicata per l'umidità è minore di 100000. La destinazione invia i dati all'argomento factoryMQTT .

Per altri esempi di configurazioni del flusso di dati, vedere API REST di Azure - Flusso di dati e Bicep di avvio rapido.
Verificare che un flusso di dati funzioni
Seguire l'esercitazione: Bridge MQTT bidirezionale per Griglia di eventi di Azure per verificare che il flusso di dati funzioni.
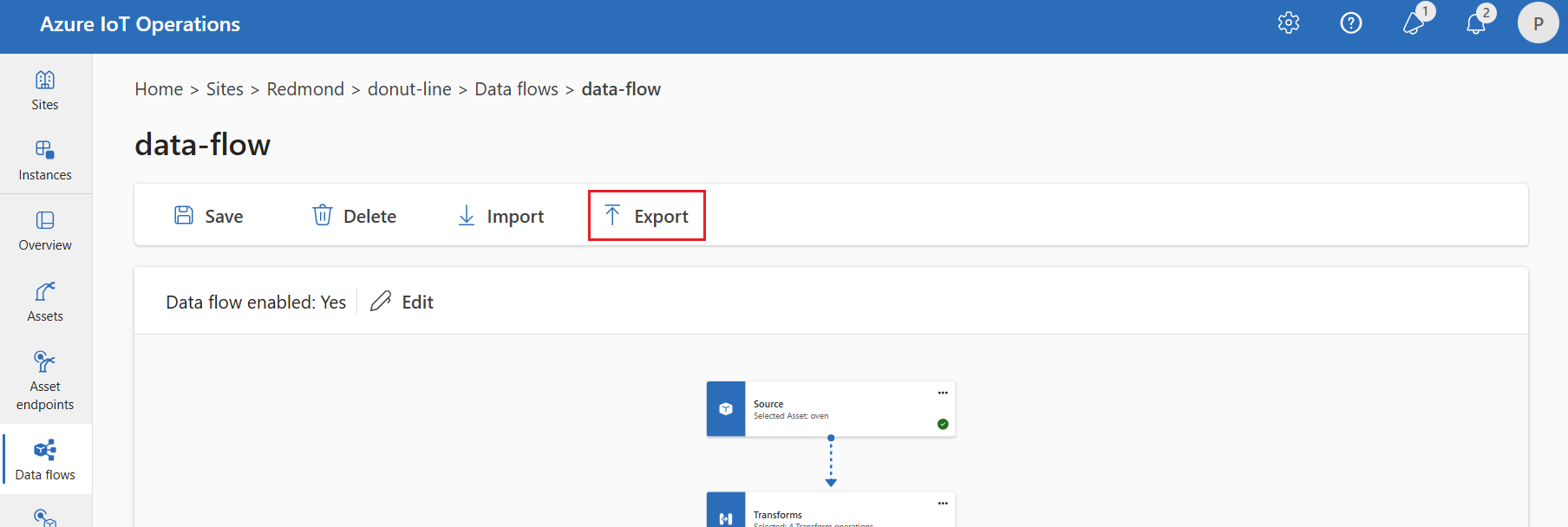
Esportare la configurazione del flusso di dati
Per esportare la configurazione del flusso di dati, è possibile usare l'esperienza operativa o esportando la risorsa personalizzata Flusso di dati.
Selezionare il flusso di dati da esportare e selezionare Esporta sulla barra degli strumenti.
Configurazione corretta del flusso di dati
Per assicurarsi che il flusso di dati funzioni come previsto, verificare quanto segue:
- L'endpoint del flusso di dati MQTT predefinito deve essere usato come origine o destinazione.
- Il profilo del flusso di dati esiste e viene fatto riferimento nella configurazione del flusso di dati.
- L'origine è un endpoint MQTT, un endpoint Kafka o un asset. Gli endpoint del tipo di archiviazione non possono essere usati come origine.
- Quando si usa Griglia di eventi come origine, il numero di istanze del profilo del flusso di dati è impostato su 1 perché il broker MQTT di Griglia di eventi non supporta le sottoscrizioni condivise.
- Quando si usano Hub eventi come origine, ogni hub eventi nello spazio dei nomi è un argomento Kafka separato e deve essere specificato come origine dati.
- La trasformazione, se usata, viene configurata con la sintassi corretta, inclusa l'escape corretto di caratteri speciali.
- Quando si usano endpoint di tipo di archiviazione come destinazione, viene specificato uno schema.