Configurare gli endpoint del flusso di dati
Importante
Questa pagina include istruzioni per la gestione dei componenti di Operazioni IoT di Azure usando i manifesti di distribuzione kubernetes, disponibile in anteprima. Questa funzionalità viene fornita con diverse limitazioni e non deve essere usata per i carichi di lavoro di produzione.
Vedere le condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure per termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale.
Per iniziare a usare i flussi di dati, creare prima di tutto gli endpoint del flusso di dati. Un endpoint del flusso di dati è il punto di connessione per il flusso di dati. È possibile usare un endpoint come origine o destinazione per il flusso di dati. Alcuni tipi di endpoint possono essere usati sia come origini che come destinazioni, mentre altri sono solo per destinazioni. Un flusso di dati richiede almeno un endpoint di origine e un endpoint di destinazione.
Usare la tabella seguente per scegliere il tipo di endpoint da configurare:
| Tipo di endpoint | Descrizione | Può essere usato come origine | Può essere usato come destinazione |
|---|---|---|---|
| MQTT | Per la messaggistica bidirezionale con broker MQTT, incluso quello incorporato in Operazioni IoT di Azure e Griglia di eventi. | Sì | Sì |
| Kafka | Per la messaggistica bidirezionale con broker Kafka, tra cui Hub eventi di Azure. | Sì | Sì |
| Data Lake | Per caricare i dati in account di archiviazione di Azure Data Lake Gen2. | No | Sì |
| Microsoft Fabric OneLake | Per caricare i dati in microsoft Fabric OneLake lakehouses. | No | Sì |
| Esplora dati di Azure | Per caricare i dati nei database Esplora dati di Azure. | No | Sì |
| Archiviazione locale | Per l'invio di dati a un volume permanente disponibile in locale, tramite il quale è possibile caricare i dati tramite l'archiviazione di Azure Container abilitata dai volumi perimetrali di Azure Arc. | No | Sì |
Importante
Gli endpoint di archiviazione richiedono uno schema per la serializzazione. Per usare il flusso di dati con Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Esplora dati o Archiviazione locale, è necessario specificare un riferimento allo schema.
Per generare lo schema da un file di dati di esempio, usare l'helper di generazione dello schema.
I flussi di dati devono usare l'endpoint broker MQTT locale
Quando si crea un flusso di dati, si specificano gli endpoint di origine e di destinazione. Il flusso di dati sposta i dati dall'endpoint di origine all'endpoint di destinazione. È possibile usare lo stesso endpoint per più flussi di dati ed è possibile usare lo stesso endpoint sia dell'origine che della destinazione in un flusso di dati.
Tuttavia, l'uso di endpoint personalizzati sia come origine che come destinazione in un flusso di dati non è supportato. Questa restrizione indica che il broker MQTT predefinito nelle operazioni IoT di Azure deve essere almeno un endpoint. Può essere l'origine, la destinazione o entrambi. Per evitare errori di distribuzione del flusso di dati, usare l'endpoint del flusso di dati MQTT predefinito come origine o destinazione per ogni flusso di dati.
Il requisito specifico è che ogni flusso di dati deve avere l'origine o la destinazione configurata con un endpoint MQTT con l'host aio-broker. Non è quindi strettamente necessario usare l'endpoint predefinito ed è possibile creare endpoint del flusso di dati aggiuntivi che puntano al broker MQTT locale purché l'host sia aio-broker. Tuttavia, per evitare problemi di confusione e gestibilità, l'endpoint predefinito è l'approccio consigliato.
La tabella seguente illustra gli scenari supportati:
| Scenario | Supportata |
|---|---|
| Endpoint predefinito come origine | Sì |
| Endpoint predefinito come destinazione | Sì |
| Endpoint personalizzato come origine | Sì, se la destinazione è un endpoint predefinito o un endpoint MQTT con host aio-broker |
| Endpoint personalizzato come destinazione | Sì, se l'origine è un endpoint predefinito o un endpoint MQTT con host aio-broker |
| Endpoint personalizzato come origine e destinazione | No, a meno che uno di essi non sia un endpoint MQTT con host aio-broker |
Riutilizzare gli endpoint
Si consideri ogni endpoint del flusso di dati come un bundle di impostazioni di configurazione che contiene la provenienza o l'accesso dei dati (il host valore), come eseguire l'autenticazione con l'endpoint e altre impostazioni come la configurazione TLS o la preferenza di invio in batch. È quindi sufficiente crearlo una sola volta e quindi riutilizzarlo in più flussi di dati in cui queste impostazioni sarebbero le stesse.
Per semplificare il riutilizzo degli endpoint, il filtro dell'argomento MQTT o Kafka non fa parte della configurazione dell'endpoint. Specificare invece il filtro dell'argomento nella configurazione del flusso di dati. Ciò significa che è possibile usare lo stesso endpoint per più flussi di dati che usano filtri di argomento diversi.
Ad esempio, è possibile usare l'endpoint del flusso di dati del broker MQTT predefinito. È possibile usarlo sia per l'origine che per la destinazione con filtri di argomento diversi:
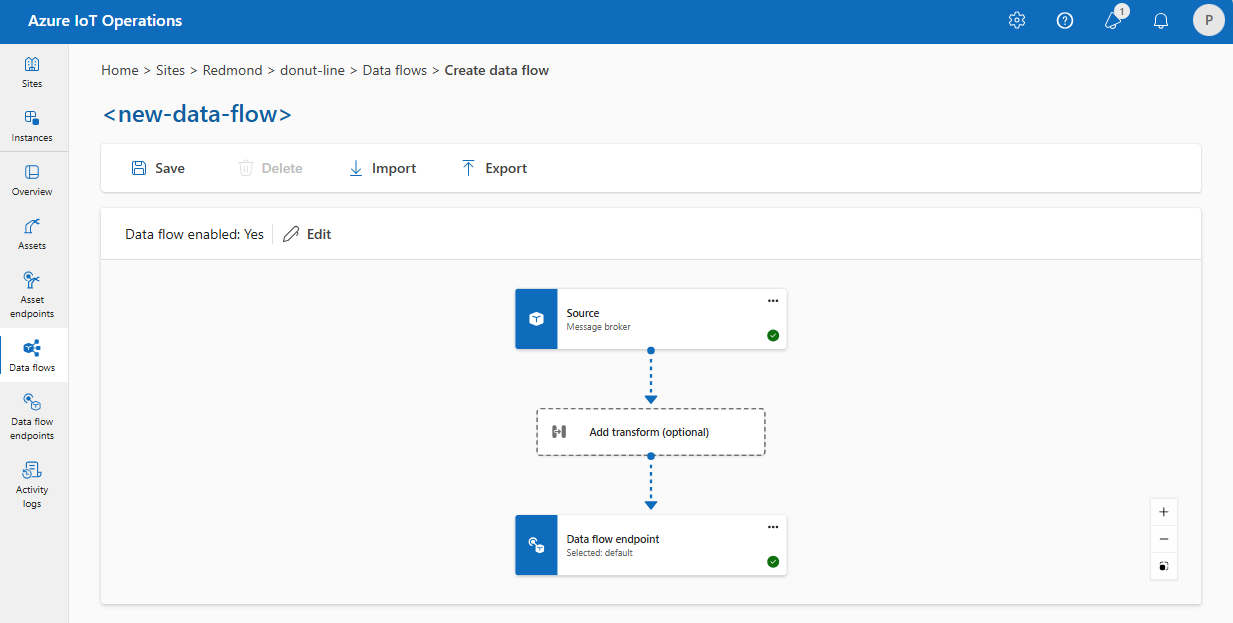
Analogamente, è possibile creare più flussi di dati che usano lo stesso endpoint MQTT per altri endpoint e argomenti. Ad esempio, è possibile usare lo stesso endpoint MQTT per un flusso di dati che invia dati a un endpoint di Hub eventi.
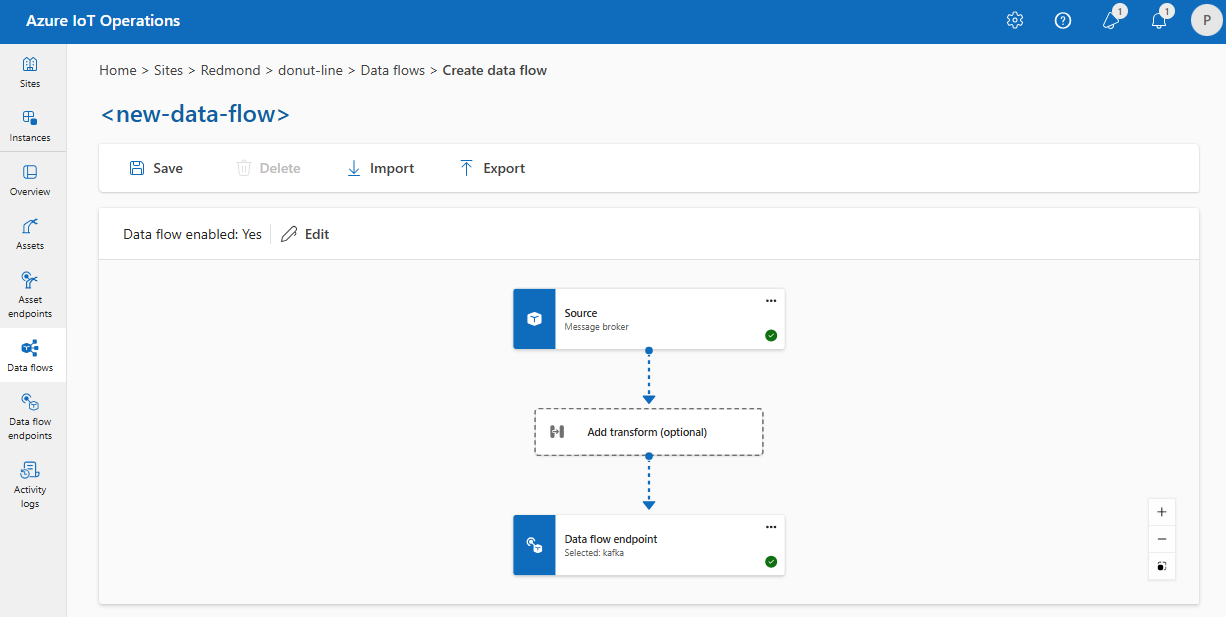
Analogamente all'esempio MQTT, è possibile creare più flussi di dati che usano lo stesso endpoint Kafka per argomenti diversi o lo stesso endpoint Data Lake per tabelle diverse.
Passaggi successivi
Creare un endpoint del flusso di dati: