Interroger et analyser les mises à jour incrémentielles
Microsoft Dataverse les données (y compris les données des applications Dynamics 365 et des finances et opérations) peuvent changer en permanence via la création, la mise à jour et la suppression de transactions. Avec l’option de mise à jour incrémentielle, vous pouvez créer des pipelines de données incrémentiels qui appliquent ces modifications aux systèmes et bases de données en aval. Synapse Link pour Dataverse exporte des données incrémentielles dans des dossiers horotadés contenant des modifications de données dans les intervalles de temps spécifiés par l’utilisateur.
Vous pouvez exploiter la fonctionnalité de mise à jour incrémentielle pour plusieurs scénarios :
Mettre à jour un magasin de données en aval ou un entrepôt de données. Vous devrez peut-être appliquer les modifications de vos données Power Apps et Dynamics 365 dans un magasin de données en aval. La mise à jour incrémentielle est une fonctionnalité standard dans la plupart des outils de transformation de données tels qu’Azure Data Factory. Cependant, afin que la fonctionnalité de mise à jour incrémentielle fonctionne, vous devez identifier les enregistrements modifiés dans les tables source. La fonctionnalité de mise à jour incrémentielle fournit les données modifiées sous forme d’un ensemble de fichiers, de sorte que vous n’avez pas besoin de détecter les modifications en comparant les images avant et après des tables.
Analyser les changements dans de grands ensembles de données. Si vous devez analyser les modifications dans de grands ensembles de données, la fonction de mise à jour incrémentielle fournit un flux continu de données en petits lots de sorte que vous n’avez pas besoin de stocker toutes les données. Avec cette option, vous pouvez supprimer les données obsolètes et stagnantes pour économiser les coûts de stockage des données et suivre les modifications de données pertinentes pour une période spécifiée par l’utilisateur.
Azure Synapse Link for Dataverse offre également la possibilité d’exporter et de maintenir une réplique des tables dans votre stockage Azure Data Lake (Gen 2). Vous pouvez configurer Azure Synapse Link pour exporter des données incrémentielles en plus d’exporter un réplica de tables. Chaque configuration (appelée "profil Synapse Link") peut exporter soit des tables, soit des données incrémentielles. Bien que vous puissiez créer plusieurs profils, vous ne pouvez pas configurer à la fois des tables et des mises à jour incrémentielles dans le même profil.
Important
Un dossier initial horodaté est créé lorsque vous activez cette fonctionnalité avec une copie de vos données. Les dossiers d’horodatage et de table suivants sont créés uniquement lorsqu’une mise à jour des données est effectuée pendant l’intervalle de temps spécifié par l’utilisateur.
Une fois que vous avez créé un profil Synapse Link avec la fonctionnalité de mise à jour incrémentielle, la configuration s’applique à toutes les tables sélectionnées dans le profil Synapse Link.
Cette fonctionnalité ne peut pas être activée avec l’option : Se connecter à votre Azure Synapse workspace. Pour les clients qui ont besoin d’un accès Azure Synapse Analytics, suivez ces instructions pour configurer le lien : Créer un Azure Synapse Link for Dataverse avec votre Azure Synapse workspace
Cette fonctionnalité est équivalente à la fonctionnalité Flux de modifications d’exportation vers le lac de données intégrée aux applications de finances et d’opérations Dynamics 365. Les clients qui utilisent la fonctionnalité Flux de modifications ont la possibilité d’activer un profil Synapse Link avec des données de modification sans avoir à exporter les données de la table.
Conditions préalables
Ce guide suppose que vous avez déjà rempli les conditions préalables pour créer un Azure Synapse Link. Pour plus d’informations, consultez Créer un Azure Synapse Link for Dataverse avec Azure Data Lake
Créer un profil Synapse Link pour exporter des données incrémentielles
Connectez-vous à Power Apps, et sélectionnez vos environnements.
Dans le volet de navigation de gauche, sélectionnez Azure Synapse Link. Si l’élément ne se trouve pas dans le volet latéral, sélectionnez …Plus, puis sélectionnez l’élément souhaité.
Dans la barre de commandes, sélectionnez + Nouveau lien.
Sélectionnez Abonnement, Groupe de ressources et Compte de stockage. Sélectionnez Suivant.
Ne sélectionnez pas l’option Se connecter à Azure Synapse workspace. Si vous choisissez cette option, la fonctionnalité de mise à jour incrémentielle est désactivée.
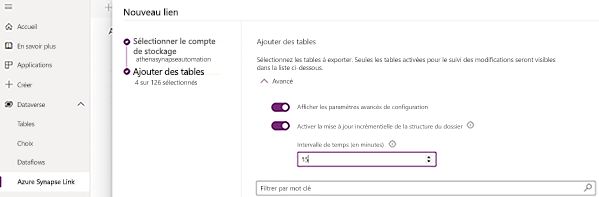
Ajoutez les tables à exporter. Si votre Dataverse environnement est lié à applications de finances et d’opérations, vous pouvez également Sélectionner tables à partir de applications de finances et d’opérations.
Sélectionnez Avancé.
Activez Afficher les paramètres de configuration avancés et Activer la structure de dossiers pour la mise à jour incrémentielle.
Entrez l’intervalle de temps (en minutes) pour la fréquence à laquelle les mises à jour incrémentielles doivent être capturées, puis sélectionnez Enregistrer.
Note
L’intervalle minimal doit être 5 minutes. Cela signifie que le dossier de mise à jour incrémentielle est créé toutes les cinq minutes et contient les modifications qui se sont produites dans l’intervalle de temps. Ce paramètre est également configurable après la création du lien via Gérer les tables. L’intervalle de temps maximum est de 1140 minutes (ou 24 heures).
Veillez à ce que l’option Se connecter à votre Azure Synapse workspace Azure Synapse workspace ne soit pas cochée sur la première page de configuration.
Les données incrémentielles dans les dossiers horodatés sont stockées sous forme de fichiers texte à valeurs séparées par des virgules (fichiers CSV). Vous ne pouvez pas utiliser la fonctionnalité de conversion Delta pour les données incrémentielles et obtenir des fichiers incrémentiels au format Delta Parquet.
Afficher le dossier incrémentiel dans le stockage Microsoft Azure
Lorsque vous créez un profil Synapse Link avec des données incrémentielles, le système effectue une copie initiale de toutes les tables et la stocke dans le premier dossier de mise à jour incrémentielle. Une fois la copie initiale créée, le système crée des dossiers de mise à jour ultérieurs avec les données modifiées. S’il n’y a aucune modification dans l’une des tables sélectionnées, vous ne verrez pas les dossiers de données incrémentielles.
Pour voir les dossiers de données incrémentiels dans le compte de stockage :
Sélectionnez le Azure Synapse Link souhaité, puis sélectionnez Accéder à Azure Data Lake dans la barre de commandes.
Sélectionnez les Conteneurs en dessous de Stockage de données.
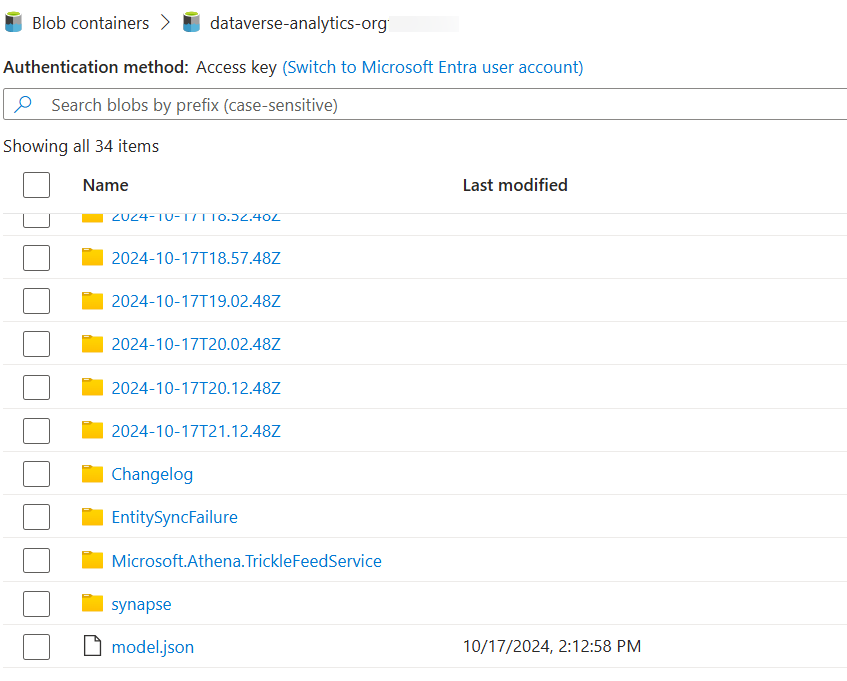
Sélectionnez dataverse-NomEnvironnement-NomUniqueOrganisation. Les dossiers de mises à jour incrémentielles sont nommés selon l’horodatage de création (« aaaa-MM-jj’T’HH:mm:ss.SSSz ») en UTC. Notez que la différence de temps entre les dossiers horodatés correspond à l’intervalle de temps que vous avez spécifié dans les paramètres avancés.
Dans chaque dossier horodaté, il existe des dossiers pour chaque table. Toutes les tables choisies n’ont peut-être pas été modifiées au cours de l’intervalle de temps et vous ne voyez que les dossiers correspondant aux tables dont les données ont été modifiées.
Note
En raison des fonctionnalités du mécanismes de nouvelle tentative, un dossier d’horodatage vide supplémentaire pourrait être créé dans l’intervalle de temps spécifié par l’utilisateur.
Consommer des données incrémentielles
Vous pouvez copier des données incrémentielles dans une base de données Azure SQL ou un entrepôt de données à l’aide d’outils d’intégration de données tels que Azure Data Factory ou Azure Synapse Analytics des pipelines. Nous fournissons un exemple de pipeline de données qui peut être utilisé à cette fin. Pour plus d’informations : Copier des données Dataverse dans Azure SQL.
Si vous êtes un client des applications de finances et d’opérations Dynamics 365 qui effectue une transition depuis la fonctionnalité de flux de modifications, vous pouvez utiliser les Exemples d’outils d’intégration de données fournis dans GitHub pour mettre à jour les pipelines de données existants utilisés avec la fonctionnalité de flux de modifications.
Vous pouvez également créer votre propre pipeline de données pour consommer des données incrémentielles. Cependant, vous devez prendre en compte les bonnes pratiques suivantes lors de la conception de votre propre pipeline :
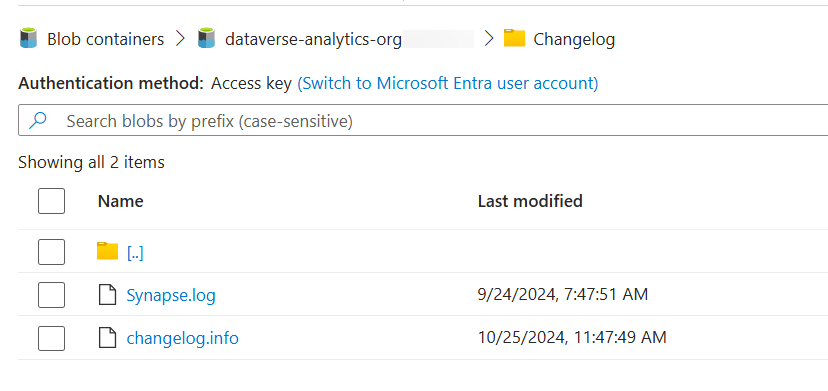
- Consommer des données à partir des dossiers horodatés précédents uniquement : de cette façon, vous pouvez éviter les conflits de lecture-écriture avec le service Synapse Link, qui met à jour en continu les données dans le dossier actuel. Vous pouvez trouver le dossier actuel en consultant le fichier Changelog/changelog.info . Ce fichier est un fichier en lecture seule qui contient une seule ligne avec le nom du dossier actuellement mis à jour. Vous ne devez pas mettre à jour ce fichier car cela peut provoquer une instabilité du système.
- Vous pouvez afficher le fichier model.json situé dans chaque dossier horodaté pour lire des métadonnées telles que les noms de colonne pour les données contenues dans les dossiers de table. Notez que chaque fichier model.json dans le dossier situé dans les dossiers horodatés contient des métadonnées pour toutes les tables, et pas seulement pour les tables contenues dans le dossier horodaté.
- Évitez d’utiliser d’autres fichiers journaux tels que le fichier Synapse.log. Ce fichier est utilisé à des fins internes et peut ne pas refléter des données exactes.
- Envisagez de supprimer les dossiers incrémentiels obsolètes de votre Azure Data Lake une fois le traitement terminé. Actuellement, Synapse Link maintient un bail sur ces fichiers dans le stockage Azure pour la récupération en cas de défaillance. Le système peut libérer le bail après un certain temps.