Copier les données Dataverse dans Azure SQL
Utilisez Azure Synapse Link pour connecter les données Microsoft Dataverse à Azure Synapse Analytics pour explorer vos données et accélérer le délai d’obtention d’informations. Cet article vous montre comment exécuter des pipelines Azure Synapse ou Azure Data Factory pour copier des données de Azure Data Lake Storage Gen2 dans Azure SQL Database avec la fonctionnalité de mises à jour incrémentielles activée dans Azure Synapse Link.
Notes
Azure Synapse Link for Microsoft Dataverse était auparavant connu sous le nom de Exporter vers le lac de données. Ce service a été renommé en mai 2021 et continuera d’exporter des données vers Azure Data Lake ainsi que vers Azure Synapse Analytics. Ce modèle est un exemple de code. Nous vous encourageons à utiliser ce modèle comme guide pour tester la fonctionnalité de récupération des données de Azure Data Lake Storage Gen2 vers Azure SQL Database à l’aide du pipeline fourni.
Conditions préalables
- Azure Synapse Link for Dataverse. Ce guide suppose que vous avez déjà rempli les conditions préalables pour créer un Azure Synapse Link avec Azure Data Lake. Plus d’informations : Conditions préalables pour un Azure Synapse Link for Dataverse avec votre Azure Data Lake
- Créez un Azure Synapse Workspace ou un Azure Data Factory dans le même client Microsoft Entra que votre client Power Apps.
- Créez un Azure Synapse Link for Dataverse avec la mise à jour incrémentielle de dossiers activée pour définir l’intervalle de temps. Plus d’informations : Interroger et analyser les mises à jour incrémentielles
- Le fournisseur Microsoft.EventGrid doit être enregistré pour le déclencheur. Plus d’informations : Portail Azure. Remarque : si vous utilisez cette fonctionnalité dans Azure Synapse Analytics, assurez-vous que votre abonnement est également enregistré auprès du fournisseur de ressources Data Factory ; sinon, vous obtiendrez une erreur indiquant que la création d’un « abonnement à un événement » a échoué.
- Créez une base de données Azure SQL avec la propriété Autoriser les services et ressources Azure à accéder à ce serveur activée. Plus d’informations : Que dois-je savoir lors de la configuration de mon Azure SQL Database (PaaS) ?
- Créez et configurez un Azure Integration Runtime. Plus d’informations : Créer un Azure Integration Runtime - Azure Data Factory & Azure Synapse
Important
L’utilisation de ce modèle peut entraîner des coûts supplémentaires. Ces coûts sont liés à l’utilisation d’Azure Data Factory ou du pipeline de l’espace de travail Synapse et sont facturés sur une base mensuelle. Le coût d’utilisation des pipelines dépend principalement de l’intervalle de temps pour la mise à jour incrémentielle et des volumes de données. Pour planifier et gérer le coût d’utilisation de cette fonctionnalité, accédez à : Surveiller les coûts au niveau du pipeline avec l’analyse des coûts
Il est important de prendre en compte ces coûts supplémentaires lorsque vous décidez d’utiliser ce modèle, car ils ne sont pas facultatifs et doivent être payés pour continuer à utiliser cette fonctionnalité.
Utiliser le modèle de solution
- Accédez au portail Azure et ouvrez Azure Synapse workspace.
- Sélectionnez Intégrer > Parcourir la galerie.
- Sélectionnez Copier les données Dataverse dans Azure SQL en utilisant Synapse Link dans la galerie d’intégration.
Configurer le modèle de solution
Créez un service lié à Azure Data Lake Storage Gen2, qui est connecté à Dataverse en utilisant le type d’authentification approprié. Pour ce faire, sélectionnez Tester la connexion pour valider la connectivité, puis sélectionnez Créer.
Comme pour les étapes précédentes, créez un service lié à Azure SQL Database où les données Dataverse seront synchronisées.
Une fois que les Entrées sont configurées, sélectionnez Utiliser ce modèle.
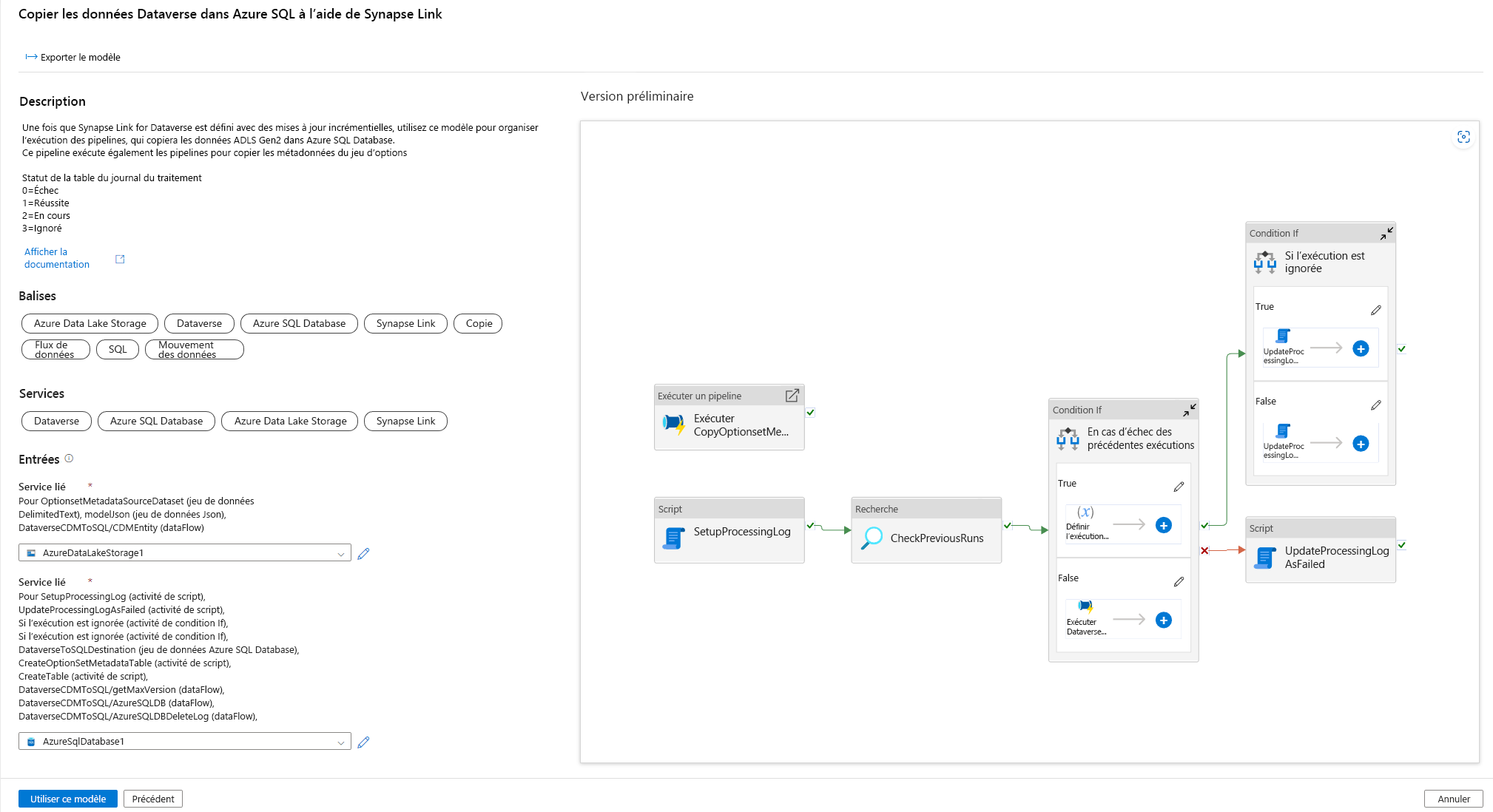
Maintenant un déclencheur peut être ajouté pour automatiser ce pipeline, afin que le pipeline puisse toujours traiter les fichiers lorsque des mises à jour incrémentielles sont effectuées régulièrement. Accédez à Gérer > Déclencheur et créez un déclencheur en utilisant les propriétés suivantes :
- Nom : entrez un nom pour le déclencheur, tel que triggerModelJson.
- Type : Événements de stockage.
- Abonnement Azure : sélectionnez l’abonnement qui contient Azure Data Lake Storage Gen2.
- Nom du compte de stockage : sélectionnez le stockage qui contient les données Dataverse.
- Nom du conteneur : sélectionnez le conteneur créé par Azure Synapse Link.
- Le chemin d’accès du blob se termine par : /model.json
- Événement : Blob créé.
- Ignorer les blobs vides : Oui.
- Lancer le déclencheur : activez Lancer le déclencheur à la création.
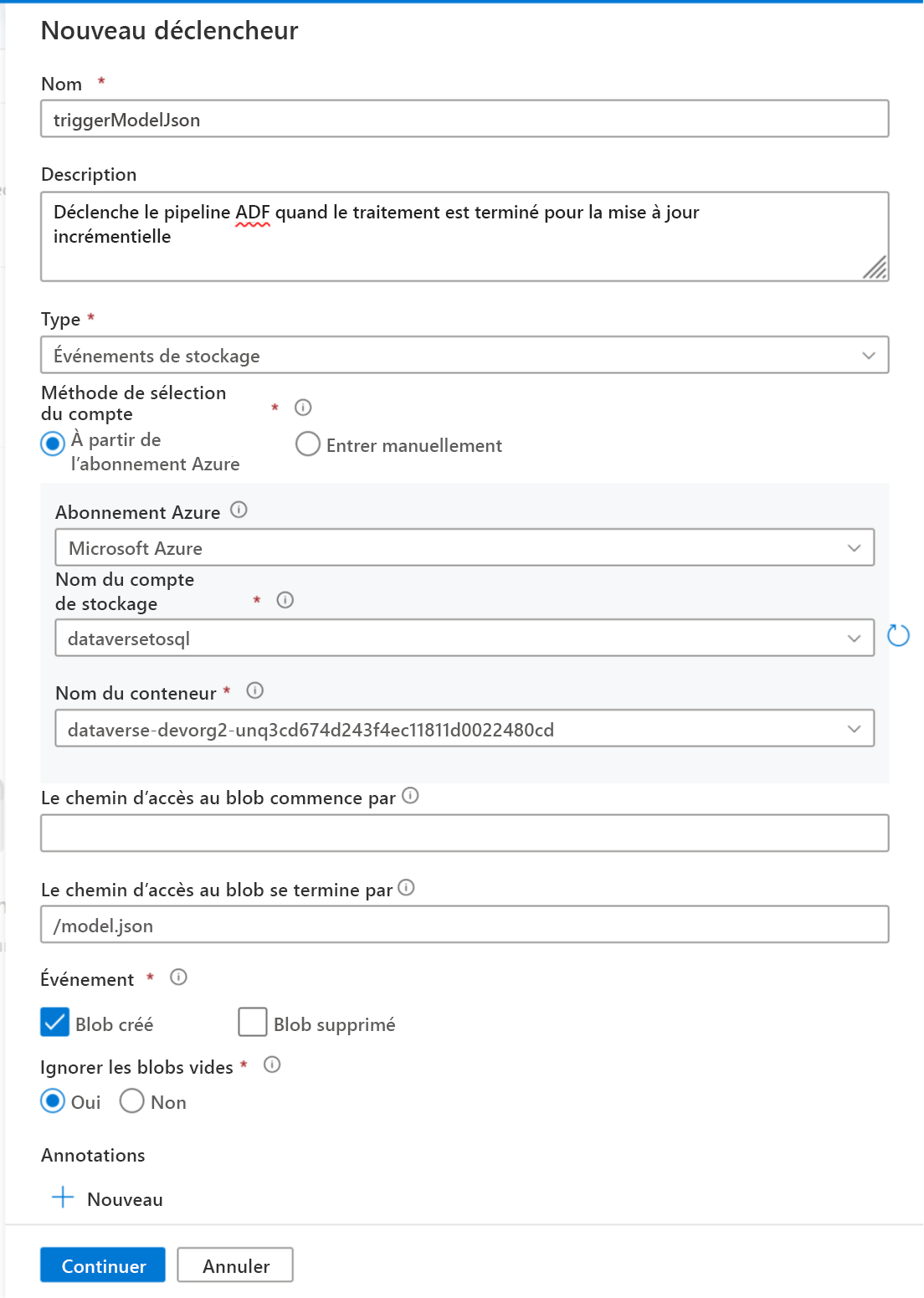
Sélectionnez Continuer pour passer à l’écran suivant.
Dans l’écran suivant, le déclencheur valide les fichiers correspondants. Sélectionnez OK pour créer le déclencheur.
Associez le déclencheur à un pipeline. Accédez au pipeline importé précédemment, puis sélectionnez Ajouter un déclencheur > Nouveau/Modifier.
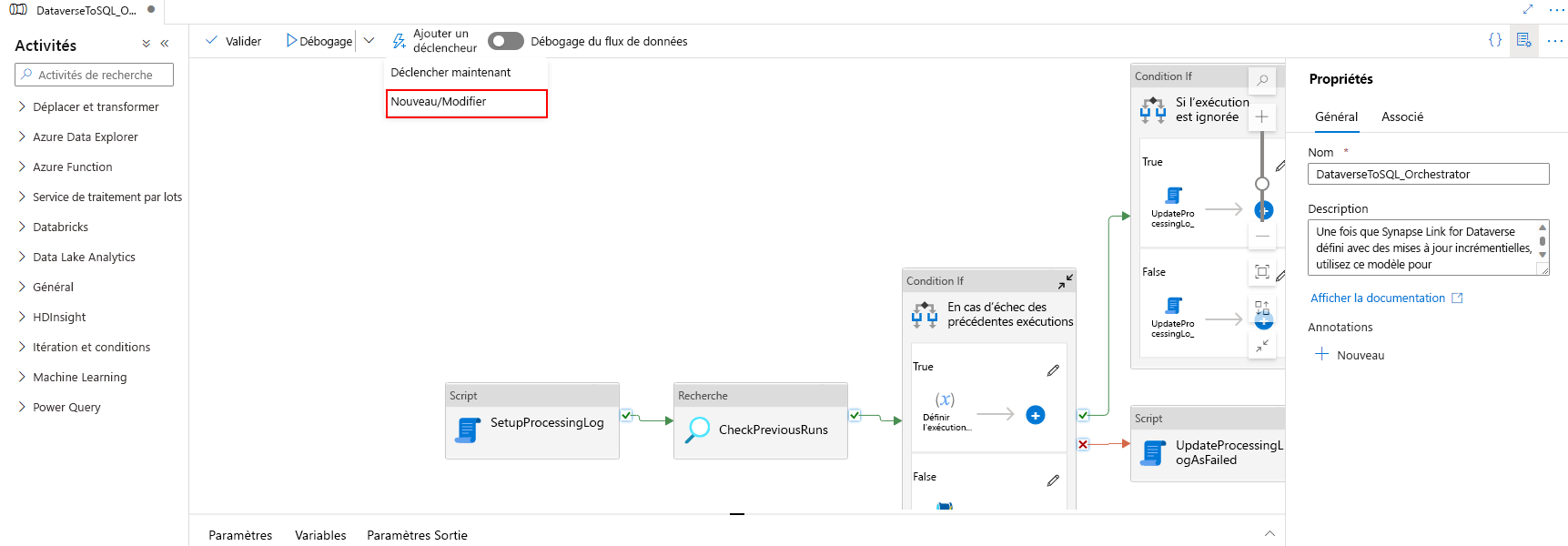
Sélectionnez le déclencheur à l’étape précédente, puis sélectionnez Continuer pour passer à l’écran suivant où le déclencheur valide les fichiers correspondants.
Sélectionnez Continuer pour passer à l’écran suivant.
Dans la section Paramètre d’exécution du déclencheur, entrez les paramètres ci-dessous, puis sélectionnez OK.
- Conteneur :
@split(triggerBody().folderPath,'/')[0] - Dossier :
@split(triggerBody().folderPath,'/')[1]
- Conteneur :
Après avoir associé le déclencheur au pipeline, sélectionnez Valider tout.
Une fois la validation réussie, sélectionnez Publier tout.
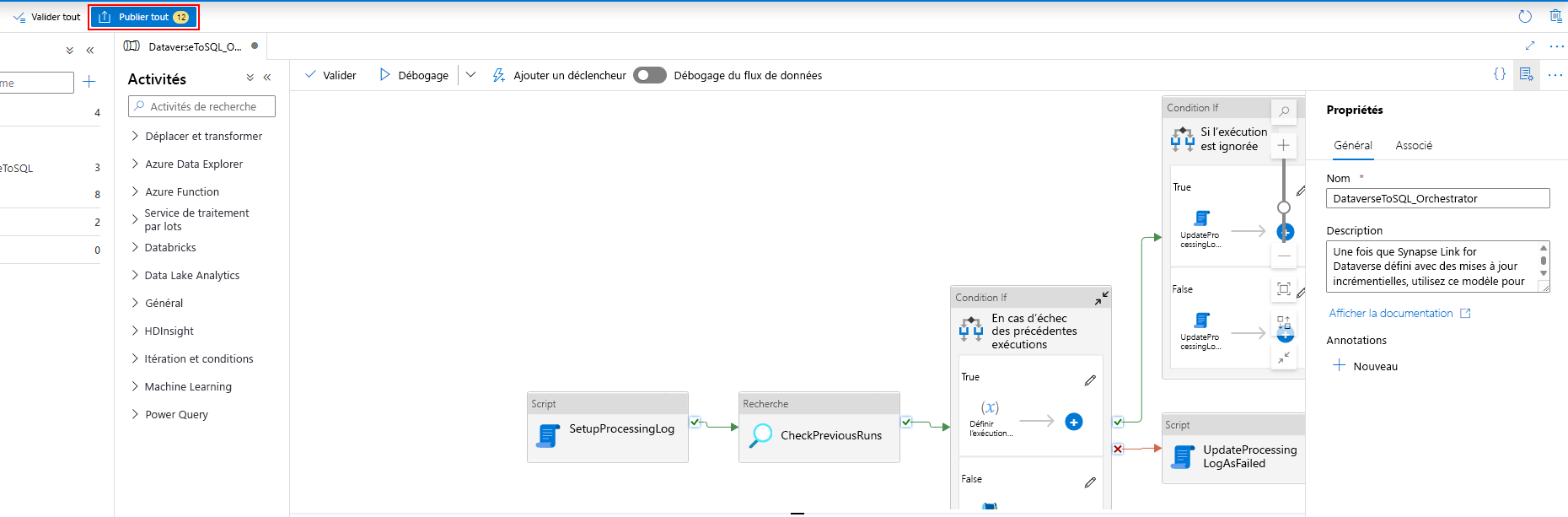
Sélectionnez Publier pour publier toutes les modifications.



Ajouter un filtre d’abonnement aux événements
Pour s’assurer que le déclencheur ne se déclenche que lorsque la création de model.json est terminée, les filtres avancés doivent être mis à jour pour l’abonnement aux événements du déclencheur. Un événement est enregistré dans le compte de stockage lors de la première exécution du déclencheur.
Une fois l’exécution d’un déclencheur terminée, accédez au compte de stockage > Événements > Abonnements aux événements.
Sélectionnez l’événement enregistré pour le déclencheur model.json.
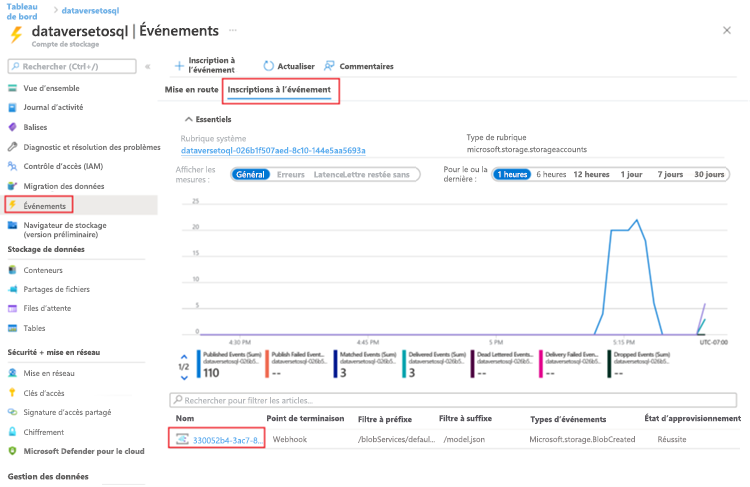
Sélectionnez l’onglet Filtres, puis sélectionnez Ajouter un nouveau filtre.
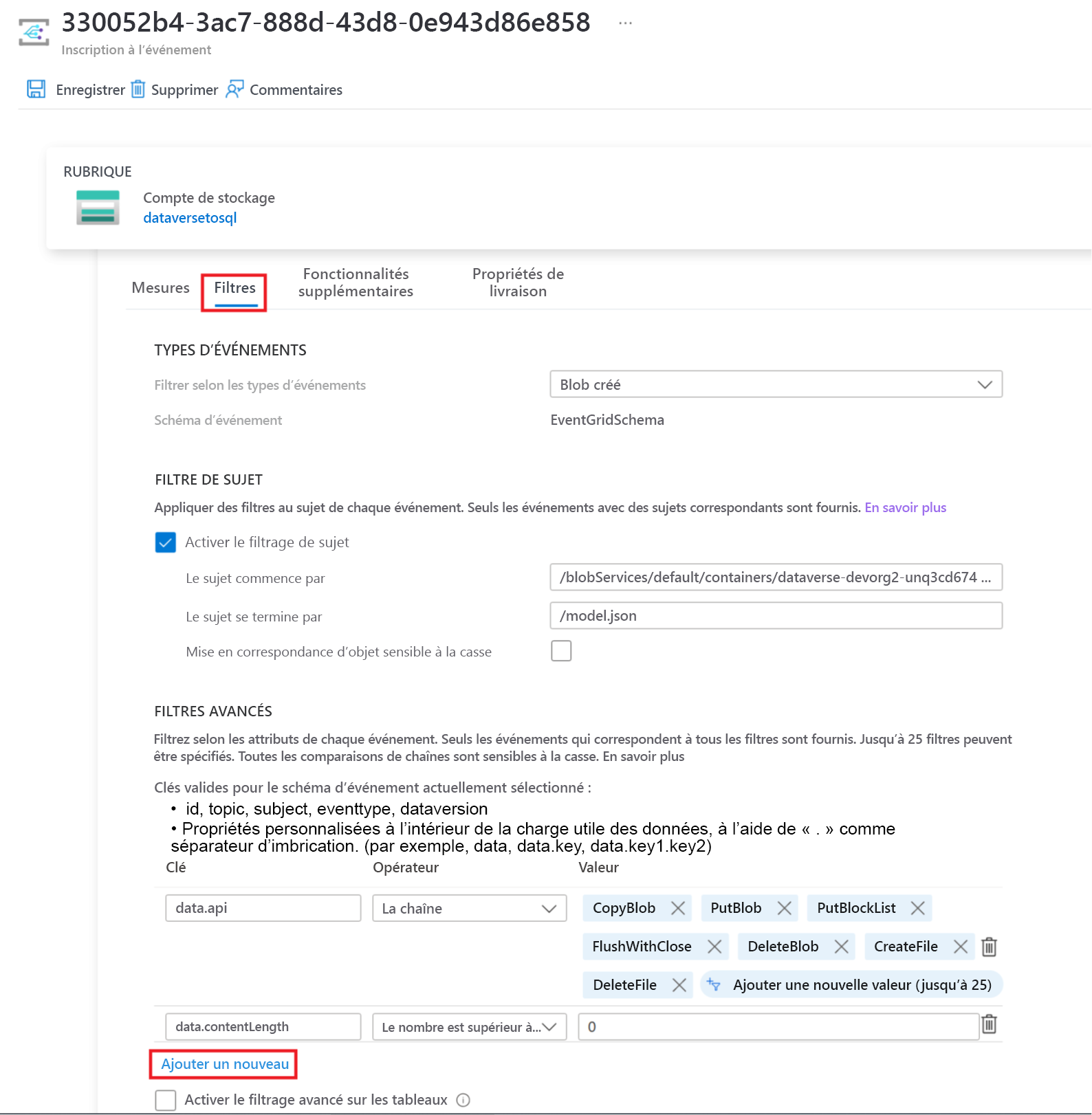
Créez le filtre :
- Clé : objet
- Opérateur : La chaîne ne se termine pas par
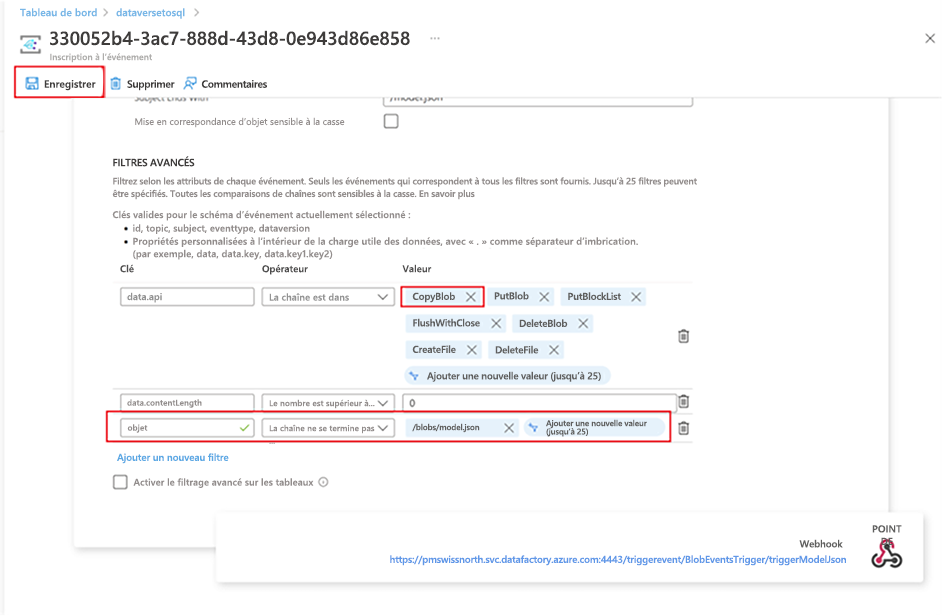
- Valeur : /blobs/model.json
Supprimez le paramètre CopyBlob du tableau de Valeurs data.api.
Sélectionnez Enregistrer pour déployer le filtre supplémentaire.
Voir aussi
Blog : Annonce d’Azure Synapse Link for Dataverse
Notes
Pouvez-vous nous indiquer vos préférences de langue pour la documentation ? Répondez à un court questionnaire. (veuillez noter que ce questionnaire est en anglais)
Le questionnaire vous prendra environ sept minutes. Aucune donnée personnelle n’est collectée (déclaration de confidentialité).