Change data in Azure Data Lake
Note
Over the past 12 months, we've been working to fill in gaps and add new features that members of the user community have highlighted. Synapse Link for Dataverse service built into Power Apps, the successor to the Export to Data Lake feature in finance and operations apps, is generally available and ready for you. Synapse Link provides one experience for working with data from all Microsoft Dynamics 365 apps.
We want you to benefit from the enhanced performance, flexibility, and improved user experience that Synapse Link offers as soon as possible. Therefore, we've announced the deprecation of the Export to Data Lake feature, effective October 15, 2023. If you're already using the Export to Data Lake feature, you can continue to use it until November 1, 2024. If you're new to the Export to Data Lake feature or are planning to adopt this feature in the coming months, we recommend that you use Synapse Link instead.
We understand that that transition might seem daunting, but we want to provide a smoother experience and offer guidance. To get started, see the Synapse Link transition guide. We're listening closely to the community and are working on multiple features to help make the transition smoother. We'll announce these other improvements to the transition process as we bring new features online. If you want to stay in touch, join the community at https://aka.ms/SynapseLinkforDynamics.
When you select the Enable near real-time data changes option, data is inserted, updated, and deleted in your data lake in near real-time. As data changes in your finance and operations environment, the same data is updated in the data lake within a few minutes. You also get the data changes in a separate Change feed folder.
Change data in a data lake lets you build near-real-time data pipelines that react to data changes in finance and operations apps. The Change feed folder in the data lake contains every data change in finance and operations apps. This folder is automatically created and maintained by the Export to Data Lake feature.
Why do you need change data in a data lake?
Data in a data lake is often used for reporting purposes. Although you can use the table data in the data lake to create reports, you can also create more copies of the data to improve your reporting. For example, you might have a data mart that is designed to enable your power users. In this data mart, you might have simplified, often aggregated, fact tables and dimension tables.
As table data in the data lake is updated, you must keep the corresponding fact tables and dimension tables in the data lake updated. Otherwise, your reports don't reflect the latest data.
The easiest way to update fact tables and dimension tables is to periodically create a full copy by using tables. However, this approach can be inefficient. If your tables are large (for example, if they have tens of millions or hundreds of millions of rows), the process of updating a fact table by making a full copy might take hours and consume lots of compute resources. Therefore, your users might not have the reports in time (that is, they might have to wait hours to see the latest data in reports). Because compute resources are consumed every time that data is reprocessed, you might receive a larger bill from the services that you've consumed.
Incremental update of your fact tables and dimension tables provides the answer to both problems (time consumption and compute resource consumption). In an incremental update, you select only the changed records from source tables, and update them in corresponding fact tables and dimension tables.
Incremental update is a standard capability in most data transformation tools, such as Azure Data Factory. However, for the incremental update feature to work, you must identify the records that changed in source tables.
The Change feed folder provides a history of table data changes in the data lake. This history can be used for data pipelines that use incremental update.
The Change feed folder in depth
The Change feed feature relies on a SQL Server feature that is named Change Data Capture (CDC). CDC is the native approach to capturing change data in a SQL Server database, which is the data store behind finance and operations apps. The Change feed feature lets you access the CDC change log in your data lake.
The following illustration shows how change feeds work in finance and operations apps.
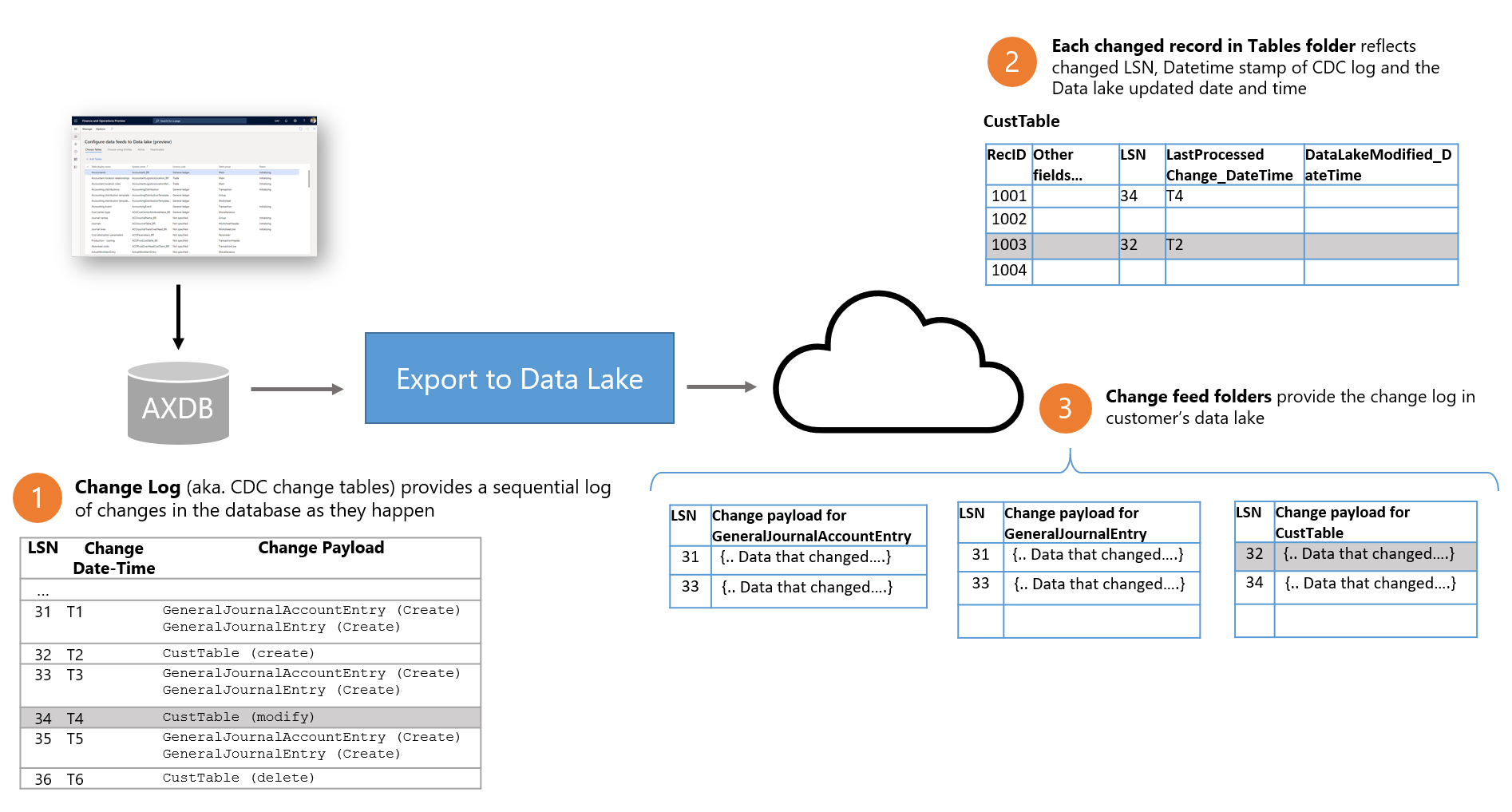
- Whenever a data change occurs in finance and operations apps, the underlying database (AXDB) is updated. The CDC feature ensures that the update is reflected in the database. CDC captures the changes in a log (the change log), together with a logical sequence number (LSN value), a date/time stamp (Change Date-Time value), and a Change Payload value that identifies the data that changed.
- Export to Data Lake microservices capture the changes in the database and write the change log to the customer's data lake. Change feed folders in the data lake are organized by table. Each folder contains the change log for a specific table.
- In addition, in the Tables folder, each row that changed also contains several new fields. Each row contains the LSN value of the corresponding change record and the Change Date-Time value. Although you can use the LSN and Change Date-Time fields in the table folders to identify whether a row changed, they contain only the latest change. If the same row changed multiple times, only the latest change is shown in the Tables folder.
- Changes are written to the Change feed folder in the same sequence (that is, LSN) in which they're committed in the database. Change feed files are written in batches in the data lake, so that their size is optimized for reading. After change feed files are written, they're never updated.
Exploring the Change feed folder in your data lake
When you enable the Enable near real-time data changes feature, change feeds are automatically added when you add tables to a data lake.
When you add a table to a data lake, or when you activate a table that has been inactivated, the system makes an initial copy of the data in the data lake. At this point, the table's status is shown as Initializing. When the initial copy is completed, the system changes the status to Running. When the table is in Running status, changes in the finance and operations database are reflected in the data lake, and change feeds are added. The Change feed folder might be empty if there have been no changes to the table since it was initialized.
To access change folders, open the Azure portal, and find and select the storage account that is associated with your finance and operations environment. You should see the Change feed folder in the data lake folder structure. The following illustration shows an example.
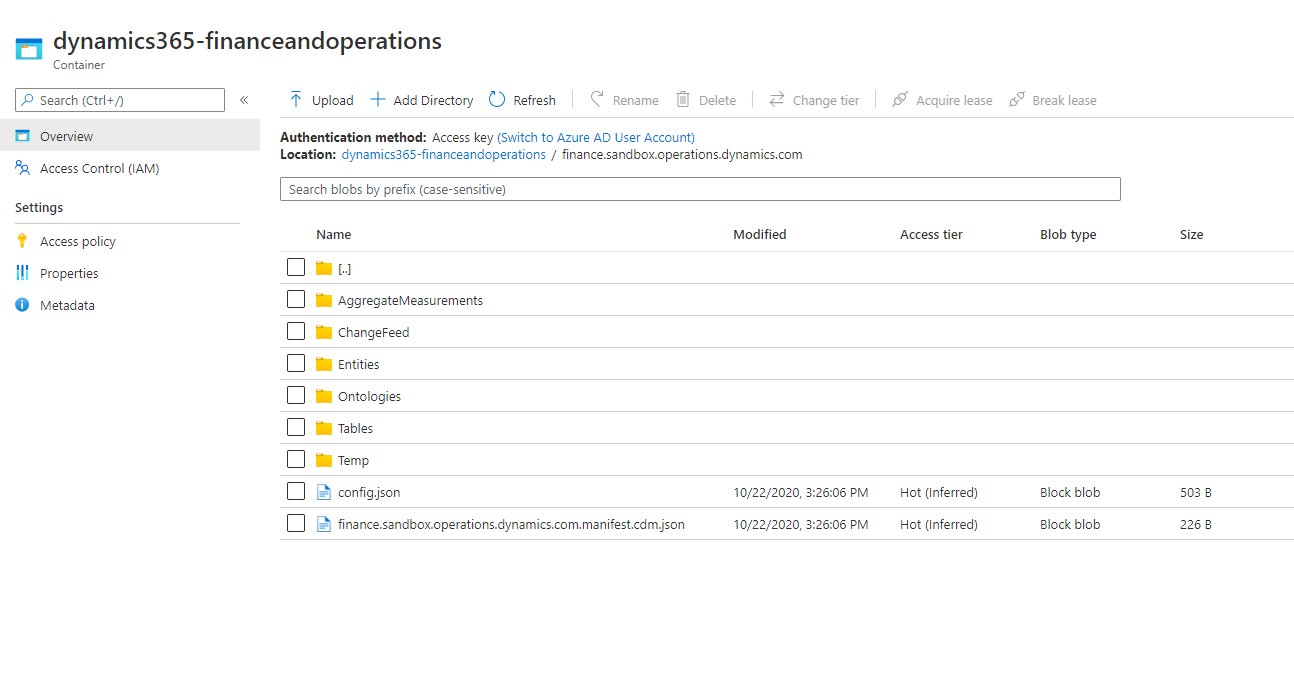
When you open the Change feed folder, you should see folders that correspond to the tables that you've added to the data lake. You should also see CDM metadata files that describe the change folder data. The following illustration shows an example.
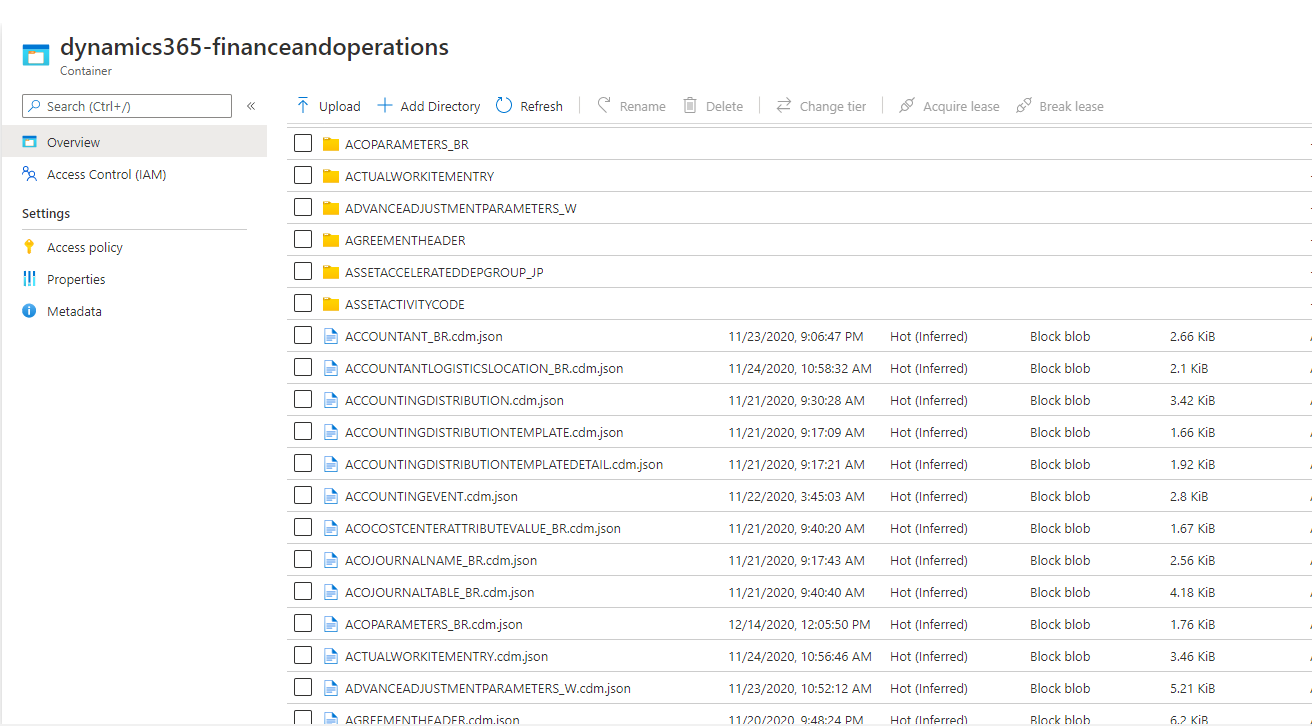
CDM metadata files describe the structure of change feed data that is contained in folders. You can use the CDM metadata files and data transformation tools such as Data Factory to read change feed data without having to read raw comma-separated values (CSV) files. To examine the metadata, select a metadata file, and then open it in a text editor.
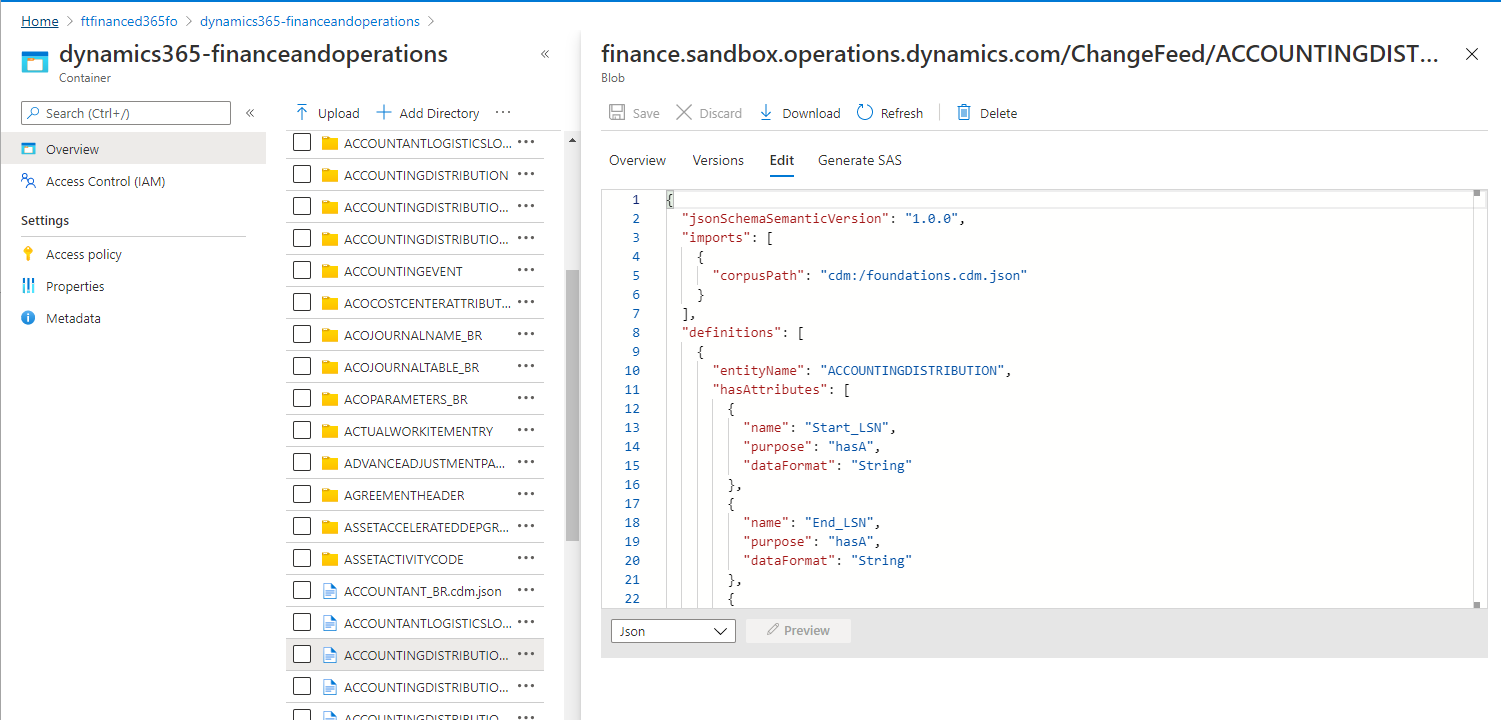
As you should notice from the metadata definitions, the Change feed folder contains the CDC change log details, together with more fields. The following illustration and table provide details about the format of changes in change folders.

| Field name | Contents |
|---|---|
| Start_LSN | This field identifies the LSN of the transaction that changed source data in the finance and operations database. Note: The Start_LSN value is not enclosed in double quotation marks in CSV files. It's a hexadecimal value, as represented in the SQL Server database. Example value: 0X00011E9F00000FB00001. |
| End_LSN | This field isn't used. |
| DML_Action | Each change is stored as a separate record. The DML_Action field identifies the change that was made to the record.
Note: The system doesn't add a BEFORE_UPDATE record to change feeds. |
| Seq_Val | This field identifies the sequence number within the LSN that changed data in the source. Because a transaction might update more than one table in the finance and operations database, the Seq_Val field indicates the sequence number that CDC assigned to the table. A change record is added for every change that is made to a table in a transaction. If the same record was updated multiple times in a single transaction, you find multiple change records that have a separate sequence number. In the future, in extreme cases (for example, when there are thousands of updates to the same record in a single transaction), the system might store the latest update record. |
| Update_Mask | A bitmap that identifies the fields that changed. This bitmap resembles the update mask in Change tracking. However, by examining the bitmap, you can identify the fields that changed. |
| List of fields and values | The remaining columns provide a list of fields that are present in the table, together with the values. You should use the update mask to identify fields that changed as part of the transaction. |
| LastProcessedChange_DateTime | This field provides the value of the CDC Change Date-Time field from the finance and operations database. The date/time is expressed in Coordinated Universal Time (UTC), per ISO 8601. Example value: "2020-08-24T05:26:03.8622647Z". Notice that this value is enclosed in double quotation marks. It includes the default seven digits of precision after the second value, and a Z that signifies UTC. |
| DataLakeModified_DateTime | This field provides the date and time of writing to the data lake. The date/time is expressed in UTC, per ISO 8601. Example value: "2020-08-24T05:26:03.8622647Z". Notice that this value is enclosed in double quotation marks. It includes the default seven digits of precision after the second value, and a Z that signifies UTC. |
Best practices when change feeds are used
Change feeds are a powerful feature that is enabled by the Export to Data Lake feature in finance and operations apps. This section examines some best practices that you should follow when change feeds are used.
Updating near-real-time data marts
If you require that your data warehouse or data marts be updated in near-real time (in other words, if they must be updated within minutes of a data change in finance and operations apps), you should use change feeds.
However, there are several important concepts that must be understood:
- Change records are grouped into files that are around 4 megabytes (MB) or 8 MB in size. Microsoft has optimized file sizes so that they provide optimum query response times when the files are queried by Synapse SQL Serverless. Optimized file sizes (and batched writes) also reduce the Azure charges that you might incur as the data lake is updated.
- Change records are only appended. Files in the Change feed folder are never updated. Although each change record contains the LSN number and date/time of a change, you can also use the date/time stamp of the CSV files to identify changes.
- When you reactivate a table in finance and operations, the Change feed folder is cleared, and the system starts change feeds from the next available change. This behavior ensures that the changes are consistent with the Tables folder. When tables are reactivated, you should consider triggering a full refresh of the downstream data pipeline.
- Your downstream jobs can be orchestrated on a periodic basis (for example, every 10 minutes), or they can be triggered when a new change feed file is added to a folder.
- In either case, your downstream data pipelines must have a last processed marker (also known as a watermark). Whenever you can, you should rely on the LSN field in the record as the watermark. However, you can also use the File Date-Time stamp as the watermark. By relying on the LSN, you ensure that you consume the changes in the same sequence in which they were committed in the finance and operations database.
For an example that shows how you can build a downstream pipeline, see the Synapse data ingestion template. You can use it to incrementally ingest data into a SQL-based data warehouse.
Simplifying BYOD-based ETL pipelines
If you're currently using the bring your own database (BYOD) feature, you can rely on exports of entities that are based on Data management framework (DMF) system tables or batch tables. You might be using export job execution data in DMF system tables to identify the time periods of export jobs. Your downstream jobs might be triggered through job execution status and details that are obtained from DMF tables.
You can simplify the orchestration pipeline by consuming change feeds.
Using the Tables folder if your data marts must be updated daily or several times per day
Change feeds are a powerful feature, but the process of constructing and maintaining a near-real-time data pipeline is complex. Although modern data transformation tools and ready-made templates can help simplify this process, you might still have to invest in building and running your pipeline.
If your users expect data marts to be updated daily or several times per day, triggering a full refresh might be an economical alternative, especially if the volume of data is low or moderate. You can also choose to update smaller tables as a periodic full refresh but create near-real-time pipelines for large, frequently updated tables.
Changing feeds to audit and verify master data updates
The Change feed folder is an exact replica of the CDC change logs that are maintained by the finance and operations database. Changes that are made to master data in finance and operations apps are reflected in CDC. Therefore, by extension, they're also reflected in change feed folders in your data lake.
You can use reports that are built over the Change feed folder to audit and verify master data changes in the system.
Periodically purging the Change feed folder
The Change feed folder isn't deleted by the Export to Data Lake process unless you reinitialize the data to recover from an error.
Because tables continue to add changes while they're in Running status, change feed folders continue to grow in the data lake. (However, the cost of retaining data in the data lake is a fraction of the cost of an SQL database. Therefore, the cost of growing data might not be a major concern.)
If you want to reduce the amount of data that is stored in your data lake, you can periodically delete the change log from the data lake. For example, you can run a job that deletes change log files that haven't been modified for 90 days or 180 days.
Periodic deletion of the change log has no impact on data in the Tables folder. However, if you run consistency checks, as described earlier in this article, you might want to keep the change log longer to facilitate those checks.
Creating reports that have header and line consistency
When a purchase order is created in a finance and operations environment, more than one table might be updated. For the sake of simplicity, assume that a record is added to the Header table, and several order lines are added to the Lines table. The system exports both the Header table and the Lines table to the data lake, and corresponding change records are added to the Change feeds folders.
However, the Export to Data Lake process doesn't sync the exact time when the header and multiple lines are written to the data lake. Because the Header table contains only one row change, it might be updated in the data lake first. The Lines table might then be updated a few moments later. Although the change feeds ensure that changes in the tables are written in the same order in which they were committed in the database, no similar assurances are made for changes between tables.
On the other hand, you might have to create reports that reflect consistent data from both the Header table and the Lines table, because your users don't want to view a purchasing report that includes only some of the lines. This pattern is common in data mart design. Change feed folders let you handle this scenario by using LSNs.
If your downstream data pipeline must ensure that Header and Line records are inserted into the data mart in a consistent manner, consider extracting headers and lines that have matching LSNs. If your data pipeline finds a Header row, but no matching Line rows that have the same LSN number, it must wait until the corresponding LSN is present in the Lines table.
Alternatively, your data pipeline can insert Header and Line rows as they arrive in the data lake, without waiting for consistency between headers and lines. Instead, you can perform a join between the Header and Lines tables in the report. In that way, you report only on consistent data.