Déployer et configurer l’enrichissement de notes cliniques non structurées (version préliminaire) dans les solutions de données de santé
[Cet article fait partie de la documentation en version préliminaire et peut faire l’objet de modifications.]
Note
Ce contenu est en cours de mise à jour.
L’enrichissement de notes cliniques non structurées (version préliminaire) utilise le service Text Analytics for Health d’Azure AI Language pour extraire et ajouter une structure aux notes cliniques non structurées pour l’analyse. Vous pouvez déployer et configurer la fonctionnalité après avoir déployé les solutions de données de santé (version préliminaire) et la fonctionnalité Sources des données de santé sur votre espace de travail Fabric.
Enrichissement de notes cliniques non structurées (version préliminaire) est une fonctionnalité facultative dans les solutions de données de santé dans Microsoft Fabric. Vous avez la possibilité de décider de l’utiliser ou non, en fonction de vos besoins ou scénarios spécifiques.
Conditions préalables
- Déployer les solutions de données de santé dans Microsoft Fabric.
- Installez les notebooks et pipelines de base dans Déployer les sources des données de santé.
Configurer le service de langage Azure
Accédez au portail Azure.
Sur la page d’accueil, sélectionnez Créer une ressource, recherchez Groupe de ressources et créez un nouveau groupe de ressources Azure. .
Assurez-vous de disposer du rôle de contrôle d’accès en fonction du rôle (RBAC) Azure Propriétaire ou Administrateur de l’accès utilisateur sur le groupe de ressources. Pour attribuer les autorisations, suivez les étapes décrites dans Accorder l’accès.
Après avoir créé le groupe de ressources, revenez à la page d’accueil, sélectionnez Créer une ressource, recherchez Service linguistique et déployez un nouveau service Azure Language sur votre groupe de ressources. Utilisez les paramètres de configuration par défaut.
Important
Le déploiement du service de langage nécessite que vous acceptiez les conditions de la notice sur l’utilisation responsable de l’IA sur le portail Azure. Assurez-vous de passer en revue ces conditions lorsque vous ajoutez le service de langage à votre groupe de ressources. Pour plus d’informations, consultez les notes de transparence suivantes :
Déployer Enrichissement de notes cliniques non structurées (version préliminaire)
Vous pouvez déployer la fonctionnalité à l’aide du module de configuration expliqué dans Solutions de données de santé : déployer les sources des données de santé. Dans la page des paramètres, fournissez la valeur Key Vault Azure pour lier les données de votre coffre de clés.
Si vous n’avez pas utilisé le module d’installation pour déployer la fonctionnalité et que vous souhaitez l’utiliser à la place, procédez comme suit :
Accédez à la page d’accueil des solutions de données de santé sur Fabric.
Sélectionner la vignette l'enrichissement de notes cliniques non structurées (version préliminaire).
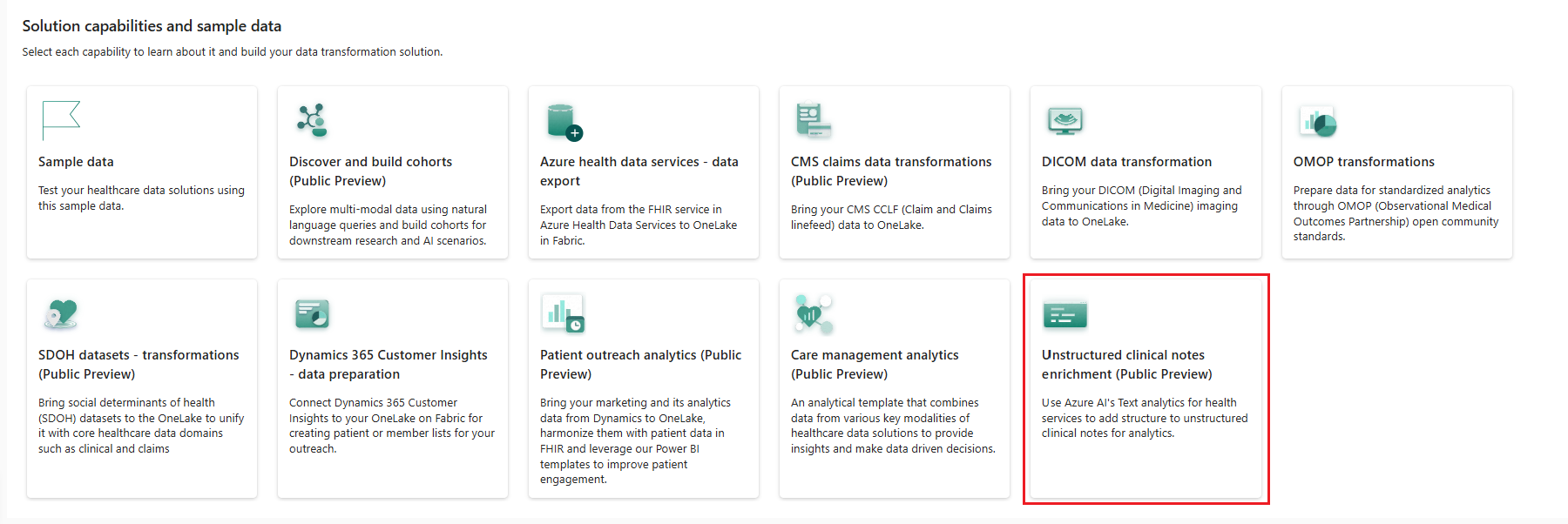
Sur la page des fonctionnalités, sélectionnez Déployer sur l’espace de travail.
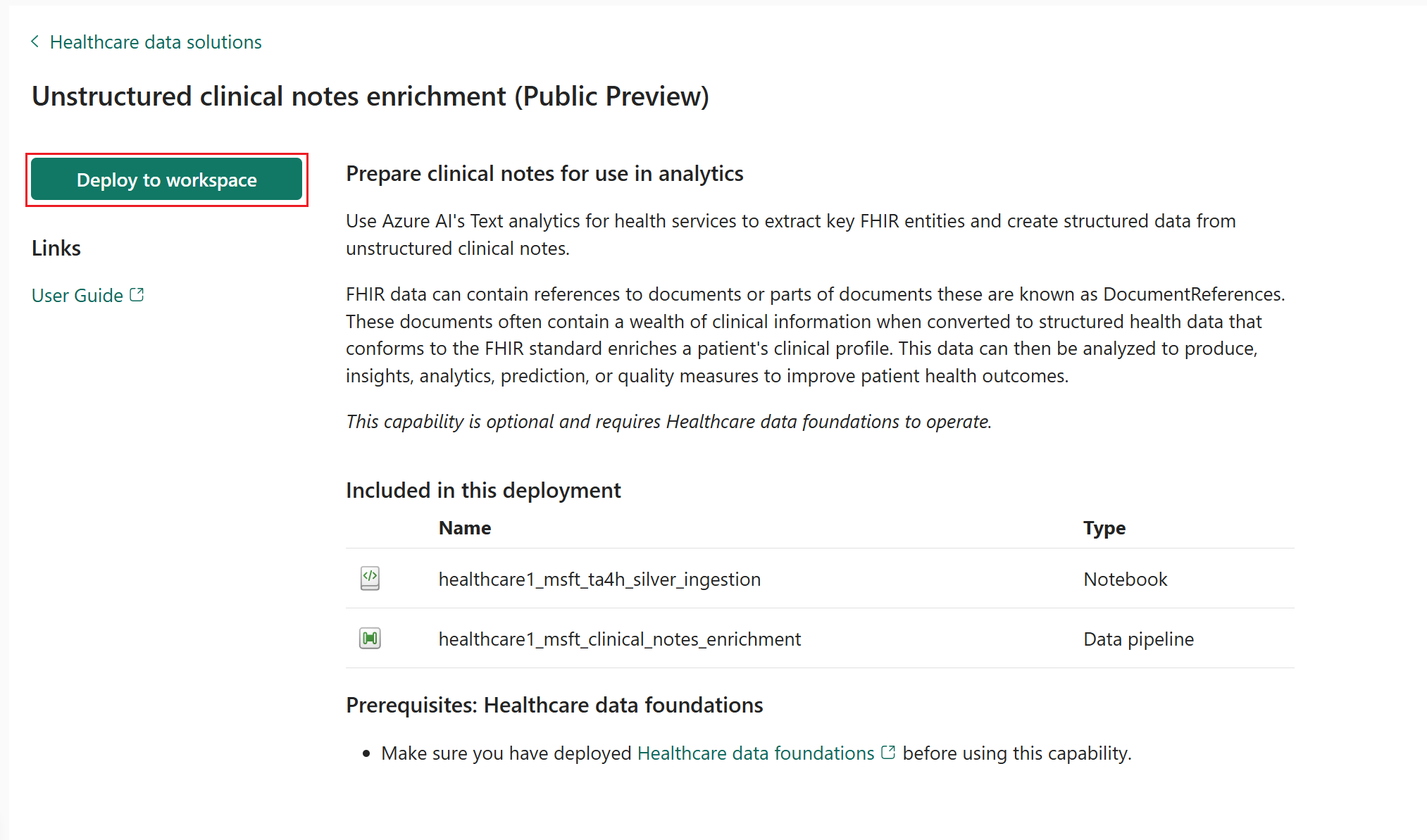
Le déploiement peut prendre plusieurs minutes. Ne fermez pas l’onglet ou le navigateur pendant que le déploiement est en cours. Pendant que vous patientez, vous pouvez travailler dans un autre onglet.
Une fois le déploiement terminé, vous pouvez voir une notification dans la barre de messages.
Sélectionnez Gérer la capacité dans la barre de messages pour accéder à la page Gestion des capacités.
Ici, vous pouvez afficher, configurer et gérer les artefacts déployés avec la fonctionnalité.


Artefacts
Cette fonctionnalité installe un notebook et un pipeline de données dans votre environnement de solutions de données de santé.
| Artefact | Type | Description |
|---|---|---|
| healthcare#_msft_ta4h_silver_ingestion | Bloc-notes | Utilise l’API Azure Text Analytics for Health NLP pour traiter et analyser des données textuelles non structurées. |
| healthcare#_msft_clinical_notes_enrichment | Pipeline de données | Exécute de manière séquentielle une série de blocs-notes pour extraire les entités clés des ressources d’interopérabilité rapide des soins de santé (FHIR) à partir de notes cliniques non structurées, structurer les données et stocker les résultats dans le Silver Lakehouse. |
Examiner la configuration du bloc-notes
Le notebook healthcare#_msft_ta4h_silver_ingestion exécute le module NLPIngestionService dans la bibliothèque de solutions de données de santé et utilise le service Azure Text Analytics for Health. Ce service est une API de traitement du langage naturel (NLP) pour traiter et analyser des données textuelles non structurées. Les résultats sont stockés dans la maison du lac healthcare#_msft_silver .
Voici les principaux paramètres de configuration de ce notebook :
Configuration PNL : vous permet de personnaliser les paramètres NLP en fonction des exigences spécifiques de l’utilisateur.
enable_text_analytics_logs: Basculez la valeur surTrueouFalsepour activer ou désactiver les journaux API. La valeur par défaut est définie surFalse. Pour plus d’informations sur l'activation de la journalisation, voir Activer journaux.nlp_source_table_name: identifie la table source à traiter par le service Text Analytics for Health.nlp_document_limit: définit la limite du nombre de documents que le service Text Analytics for Health peut traiter. La valeur par défaut est définie sur10, avec une réserve maximale de 1 000 documents. Vous pouvez ajuster cette valeur si nécessaire. Cependant, gardez à l’esprit les implications financières, comme expliqué dans Modèle de prix.
Ce notebook se déploie avec les valeurs préconfigurées requises pour exécuter le pipeline de données associé. Certains paramètres de configuration héritent de la configuration globale. Par défaut, il n’est pas nécessaire d’apporter des modifications à la fichiers de configuration du notebook. Si nécessaire, vous pouvez ouvrir le bloc-notes et examiner la configuration.