Architecture des données et les gestion des solutions de données de santé dans Microsoft Fabric
Le cadre des solutions de données de santé utilise une architecture médaillon spécialisée pour rationaliser l’organisation et le traitement des données. Cette conception garantit une amélioration continue de la qualité et de la structure des données, ce qui vous permet de gérer plus efficacement les données de santé. Cet article explore les principales caractéristiques et avantages de cette architecture, en fournissant une vue d’ensemble complète de la façon dont les données sont gérées dans ce cadre.
Conception de lakehouse en médaillon
Comme expliqué dans l’architecture de lasolution, les solutions de données de santé utilisent l’architecture lakehouse médaillon pour organiser et traiter les données sur plusieurs couches. Au fur et à mesure que les données se déplacent dans chaque couche, leur structure et leur qualité sont continuellement améliorées. À la base, la conception de lakehouse en médaillon dans les solutions de données de santé se compose des lakehouses clés suivants :
lakehouse en bronze : Aussi appelée zone brute, la lakehouse en bronze est la première couche qui organise les données sources dans leur format de fichier d’origine. Il ingère les fichiers sources dans OneLake et/ou crée des raccourcis à partir de sources de stockage natives. Il stocke également les données structurées et semi-structurées de la source dans des tables delta, également appelées tables intermédiaires . Ces tables sont compressées et indexées en colonnes pour prendre en charge des transformations et un traitement des données efficaces. Les données de cette couche sont généralement ajoutées uniquement et immuables.
Les fichiers de la lakehouse de bronze (qu’ils soient persistants ou qu’il s’agisse de raccourcis) servent de source de vérité. Ils jettent les bases de la traçabilité des données sur l’ensemble du paysage de données des solutions de données de santé. Les tables intermédiaires de la couche bronze se composent généralement de quelques colonnes et sont conçues pour contenir chaque modalité et format de données dans une seule table (par exemple, les tables ClinicalFhir et ImagingDicom ). Vous ne devez pas étendre, personnaliser ou créer des dépendances sur ces tables de mise en scène dans la maison du lac en bronze pour les raisons suivantes :
- Implémentation interne : les tables intermédiaires sont implémentées en interne spécifiquement aux solutions de données de santé dans Microsoft Fabric. Leur schéma est spécialement conçu pour les solutions de données de santé et ne suit aucune norme de données de l’industrie ou de la communauté.
- Magasin transitoire : une fois que les données ont été traitées et transformées des tables de mise en lots de la lakehouse en bronze vers les tables delta aplaties et normalisées dans la lakehouse argenté, les données de la table de mise en lots en bronze sont considérées comme prêtes à être purgées. Ce modèle garantit l’efficacité des coûts et du stockage et réduit la redondance des données entre les fichiers sources et les tables de mise en scène dans la lakehouse en bronze.
Lakehouse d’argent : Aussi appelée zone enrichie , la lakehouse d’argent affine les données de la maison du lac de bronze. Il comprend des contrôles de validation et des techniques d’enrichissement pour améliorer la précision des données pour les analyses en aval. Contrairement à la couche bronze, les données Silver Lakehouse utilisent des règles basées sur des identifiants déterministes et des horodatages de modification pour gérer les insertions et les mises à jour d’enregistrements.
Lakehouse d’or : Également appelée zone organisée , la lakehouse d’or affine davantage les données de la lakehouse d’argent pour répondre à des exigences commerciales et analytiques spécifiques. Cette couche sert de source principale pour des ensembles de données agrégés de haute qualité, prêts pour une analyse complète et une extraction d’informations. Alors que les solutions de données de santé déploient un lakehouse bronze et un lakehouse silver par déploiement, vous pouvez disposer de plusieurs lakehouses gold pour servir diverses unités commerciales et personas.
Lakehouse d’administration : le lakehouse d’administration contient des fichiers pour la gouvernance et la traçabilité des données à travers les couches lakehouse, y compris les erreurs de configuration et de validation globales stockées dans la table BusinessEvent. Pour en savoir plus, voir lakehouse administrateur.
Structure de dossiers unifiée
Les clients des secteurs de la santé et des sciences de la vie traitent de grandes quantités de données provenant de divers systèmes sources, dans plusieurs modalités de données et formats de fichiers, y compris les formats de fichiers suivants :
- Modalité clinique : fichiers FHIR NDJSON, offre groupée FHIR et HL7.
- Modalité d’imagerie : DICOM, NIFTI et NDPI.
- Modalité génomique : BAM, BCL, FASTQ et VCF.
- Allégations : CCLF et CSV.
Où :
- FHIR : Fast Healthcare Interoperability Resources
- HL7 : Santé Niveau Sept International
- DICOM : Imagerie numérique et communications en médecine
- NIFTI : Neuroimaging Informatics Technology Initiative (en anglais seulement)
- NDPI : Imagerie pathologique nanodimensionnelle
- BAM : Carte d’alignement binaire
- BCL : Appel de base
- FASTQ : Un format textuel pour le stockage d’une séquence biologique et de ses scores de qualité correspondants
- VCF : Format d'appel de variante
- CCLF : Réclamation et flux de ligne de revendication
- CSV : Valeurs séparées par des virgules
OneLake in Microsoft Fabric offre un lac de données logique pour votre organisation. Les solutions de données de santé fournissent Microsoft Fabric une structure de dossiers unifiée qui permet d’organiser les données selon diverses modalités et formats. Cette structure rationalise l’ingestion et le traitement des données tout en maintenant la traçabilité des données au niveau du fichier source et du système source dans la lakehouse de bronze.
Les six dossiers de niveau supérieur sont les suivants :
- Externe
- Échoué
- Ingérer
- Traiter
- Données de référence
- SampleData
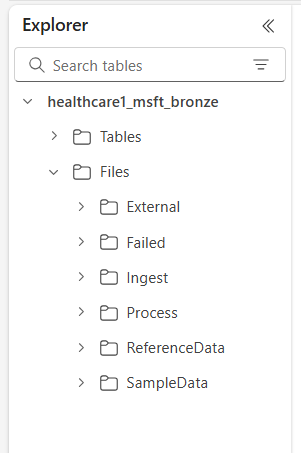
Les sous-dossiers sont organisés sont les suivantes :
Files\Ingest\[DataModality]\[DataFormat]\[Namespace]Files\External\[DataModality]\[DataFormat]\[Namespace]\[BYOSShortcutname]\Files\SampleData\[DataModality]\[DataFormat]\[Namespace]\Files\ReferenceData\[DataModality]\[DataFormat]\[Namespace]\Files\Failed\[DataModality]\[DataFormat]\[Namespace]\YYYY\MM\DDFiles\Process\[DataModality]\[DataFormat]\[Namespace]\YYYY\MM\DD
Descriptions du dossier
Espace de noms (obligatoire) : identifie le système source pour les fichiers reçus, ce qui est crucial pour garantir l’unicité de l’ID par système source.
Dossier d’ingestion : fonctionne comme un dossier de dépôt ou de file d’attente. Ce dossier vous permet de déposer les fichiers à ingérer dans les sous-dossiers de modalité et de format appropriés. Une fois l’ingestion commencée, les fichiers sont transférés dans le dossier Processus respectif ou dans le dossier Échec pour les échecs.
Dossier de processus : la destination finale de tous les fichiers traités avec succès dans chaque combinaison de modalité et de format. Ce dossier suit le
YYYY/MM/DDmodèle basé sur la date de traitement. Le partitionnement des dossiers est conforme aux meilleures pratiques d’utilisation Azure Data Lake Storage pour améliorer l’organisation, les recherches filtrées, l’automatisation et le traitement parallèle potentiel.Dossier externe : sert de dossier parent pour les dossiers de raccourcis BYOS (Bring Your Own Storage). Le déploiement par défaut fournit une structure de dossiers suggestive pour les demandes de règlement, les modalités cliniques, génomiques et d’imagerie. Les modalités d’imagerie et cliniques ont des formats et des espaces de noms par défaut configurés pour prendre en charge les services DICOM et FHIR dans Services de données de santé Azure. Ce format ne s’applique que si vous avez l’intention de raccourcir des données dans OneLake. Les solutions de données de santé disposent Microsoft Fabric d’un accès en lecture seule aux fichiers contenus dans ces dossiers contextuels.
Dossier d’échec : si une défaillance se produit lors du déplacement ou du traitement de fichiers dans les dossiers d’ingestion ou de traitement , les fichiers concernés sont déplacés vers le dossier Échec correspondant à leur modalité et à leur combinaison de format. Une erreur est consignée dans la table BusinessEvent dans le lakehouse de l’administrateur. Ce dossier utilise le
YYYY/MM/DDmodèle basé sur la date de traitement/échec. Les fichiers de ce dossier ne sont pas purgés et restent ici jusqu’à ce que vous les corrigez et les réingérez en utilisant le même modèle d’ingestion initial.Exemple de dossier de données : comprend des jeux de données synthétiques, référentiels et/ou publics. Le déploiement par défaut fournit des exemples de données pour plusieurs combinaisons de modalités et de formats afin de faciliter l’exécution immédiate des bloc-notes et des pipelines après le déploiement. Ce dossier ne créer aucun sous-dossier
YYYY/MM/DD.Dossier de données de référence : contient des jeux de données référentiels et parents provenant de sources publiques ou spécifiques à l’utilisateur. Ce dossier ne créer aucun sous-dossier
YYYY/MM/DD. Le déploiement par défaut fournit une structure de dossiers suggérée pour OMOP les vocabulaires (Observational Medical Outcomes Partnership).
Modèles d’ingestion des données
Sur la base de la structure de dossiers unifiée décrite précédemment, les solutions de données de santé prennent Microsoft Fabric en charge deux modèles d’ingestion distincts. Dans les deux cas, les solutions utilisent le streaming structuré dans Spark pour traiter les fichiers entrants dans les dossiers respectifs.
Modèle d’ingestion
Ce modèle est une approche simple dans laquelle les fichiers à ingérer sont déposés dans le dossier Ingestion sous la modalité, le format et l’espace de noms appropriés. Les pipelines d’ingestion surveillent ce dossier à la recherche de fichiers récemment abandonnés et les déplacent vers le dossier Process correspondant pour traitement. Si l’ingestion des données de fichier dans la table de mise en scène de Bronze Lakehouse réussit, le fichier est compressé et enregistré avec un préfixe d’horodatage dans le dossier Processus, en suivant le modèle basé sur le YYYY/MM/DD moment où le traitement se produit. Ce préfixe garantit des noms de fichiers uniques. Vous pouvez configurer ou désactiver la compression selon vos besoins.
Si le traitement des fichiers échoue, les fichiers ayant échoué sont déplacés du dossier Ingestion vers le dossier Échec pour chaque combinaison de modalités et de formats, et une erreur est consignée dans la table BusinessEvent du lakehouse d’administration.
Ce modèle d’ingestion est idéal pour les ingestions incrémentielles quotidiennes ou lors du déplacement physique de données vers Azure Data Lake Storage ou OneLake.
Modèle Apportez votre propre stockage (BYOS)
Vous pouvez parfois avoir des données et des fichiers déjà présents dans Azure ou d’autres services de stockage cloud, avec des implémentations en aval existantes et des dépendances sur ces fichiers. Dans le domaine de la santé et des sciences de la vie, les volumes de données peuvent atteindre plusieurs téraoctets, voire pétaoctets, notamment pour l’imagerie médicale et la génomique. Pour ces raisons, le modèle d’ingestion directe peut ne pas être réalisable.
Nous vous recommandons d’utiliser le modèle BYOS pour l’ingestion de données historiques lorsque vous disposez de volumes de données importants déjà disponibles dans Azure ou dans un autre stockage cloud et local prenant en charge le protocole S3. Ce modèle utilise les raccourcis OneLake dans Fabric et le dossier External dans la maison du lac en bronze pour permettre le traitement sur place des fichiers source. Il élimine le besoin de déplacer ou de copier des fichiers et évite les frais de sortie et la duplication des données.
Malgré les gains d’efficacité offerts par le modèle d’ingestion BYOS, vous devez tenir compte des considérations suivantes :
- Les mises à jour de fichier sur place (mises à jour de contenu dans le fichier) ne sont pas surveillées. Vous devez créer un nouveau fichier (avec un nom différent) pour toutes les mises à jour, car le pipeline d’ingestion surveille uniquement les nouveaux fichiers. Cette limitation est associée au streaming structuré dans Spark.
- Les compressions de données ne sont pas appliquées.
- Le modèle BYOS ne crée aucune structure de dossiers optimisée en fonction du
YYYY/MM/DDmodèle. - Si le traitement des fichiers échoue, les fichiers ayant échoué ne sont pas déplacés vers le dossier Échec . Toutefois, une erreur est consignée dans la table BusinessEvent dans le lakehouse de l’administrateur.
- Les données source sont supposées être en lecture seule.
- Il n’y a aucun contrôle sur la traçabilité ou la disponibilité des données sources après l’ingestion.
Compression de données
Les solutions de données de santé prennent en Microsoft Fabric charge la compression dès la conception dans la conception lakehouse du médaillon. Les données ingérées dans les tables delta du lakehouse médaillon sont stockées dans un format en colonnes compressé à l’aide de fichiers parquet. Dans le modèle d’ingestion, lorsque les fichiers sont déplacés du dossier d’ingestion vers le dossier Processus, ils sont compressés par défaut après un traitement réussi. Vous pouvez configurer ou désactiver la compression selon vos besoins. Pour les fonctionnalités d’imagerie et de revendication, les pipelines d’ingestion peuvent également traiter les fichiers bruts dans un format compressé ZIP.
Modèle de données de santé
Comme décrit dans la conception du médaillon lakehouse, les tables de mise en scène lakehouse bronze mettent en œuvre en interne des tables spécialement conçues pour les solutions de données de santé et ne suivent aucune norme de données de l’industrie ou de la communauté.
Le modèle de données de santé de la Silver Lakehouse est basé sur la norme FHIR R4 . Il fournit un langage de données commun aux analystes de données, aux scientifiques des données et aux développeurs pour qu’ils puissent collaborer et créer des solutions axées sur les données qui améliorent les résultats pour les patients et les performances de l’entreprise. Il prend en charge les données dans différents domaines de la santé, tels que clinique, administratif, financier et social. Le modèle de données de santé capture les données définies par la norme FHIR et organise les ressources FHIR à l’aide de tables et de colonnes au sein de lakehouse.
En aplatissant les données FHIR dans des tables Delta Parquet, vous pouvez utiliser des outils familiers tels que T-SQL et Spark SQL pour l’exploration et l’analyse des données. Pour les données non cliniques en dehors du champ d’application de FHIR, nous utilisons les schémas des modèles de base de Azure Synapse données. Cette mise en œuvre permet l’intégration d’informations non cliniques, telles que les données d’engagement des patients, dans le profil du patient.
Le modèle de données de santé de la Silver Lakehouse est conçu pour représenter une vue d’entreprise de bout en bout des données de santé dans les divisions et les domaines de recherche.

Traçabilité des données
Pour assurer la traçabilité au niveau de l’enregistrement et du fichier, les tables du modèle de données de santé comprennent les colonnes suivantes :
| Column | Description |
|---|---|
msftCreatedDatetime |
Horodatage de la date de création de l’enregistrement dans la maison du lac d’argent. |
msftModifiedDatetime |
Horodatage de la dernière modification de l’enregistrement. |
msftFilePath |
Chemin d’accès complet au fichier source dans la lakehouse de bronze, y compris les raccourcis. |
msftSourceSystem |
Système source de l’enregistrement, correspondant à celui Namespace spécifié dans la structure de dossiers unifiée. |
Si un champ est normalisé, aplati ou modifié, la valeur d’origine est conservée dans une {columnName}Orig colonne. Par exemple, dans la table Patient de Silver Lakehouse , vous pouvez trouver les colonnes suivantes :
| Column | Description |
|---|---|
meta_lastUpdatedOrig |
Conserve la valeur d’origine dans son format brut (chaîne ou date) et la stocke sous forme de date/heure. |
idOrig et identifierOrig |
Identifiants et identificateurs harmonisés dans la maison du lac d’argent. |
birthdateOrig et deceasedDateTimeOrig |
Conserve les valeurs de date d’origine avec une mise en forme d’horodatage différente. |
Si une colonne s’aplatit (par exemple meta_lastUpdated) ou se convertit en chaîne (par exemple, meta_string) nous la désignons par un suffixe commençant par un trait de soulignement (_).
Gestion de mettre à jour
Lorsque de nouvelles données sont ingérées de lakehouse bronze vers la lakehouse argenté, une opération de mise à jour compare les enregistrements entrants avec les tables cibles lakehouse pour chaque ressource et type de table. Pour les tables FHIR dans la lakehouse d’argent, cette comparaison vérifie les valeurs {FHIRResource}.id et {FHIRResource}.meta_lastUpdated par rapport aux id colonnes et lastUpdated de la table de mise en scène de la lakehouse de bronze ClinicalFhir .
- Si une correspondance est identifiée avec le nouvel enregistrement entrant, l’enregistrement argent est mis à jour.
- Si l’enregistrement entrant est ancien, l’enregistrement argenté est ignoré.
- Si aucune correspondance n’est trouvée, le nouvel enregistrement est inséré dans la maison du lac d’argent.
Lakehouse administrateur
L’administrateur lakehouse gère la configuration inter-lakehouse, la configuration globale, les rapports d’état et le suivi des solutions de données de santé dans Microsoft Fabric.
Configuration globale
Le dossier d’administration lakehouse system-configurations centralise les paramètres de configuration globaux. Les trois fichiers de configuration contiennent des valeurs préconfigurées pour le déploiement par défaut de toutes les fonctionnalités des solutions de données de santé. Vous n’avez pas besoin de reconfigurer ces valeurs pour exécuter les exemples de données ou les pipelines de données pour n’importe quelle fonctionnalité.

Le fichier deploymentParametersConfiguration.json contient des paramètres globaux sous activitiesGlobalParameters et des paramètres spécifiques à l’activité pour les blocs-notes et les pipelines sous activities. Les conseils de capacité respectifs couvrent les détails de configuration spécifiques pour chaque capacité. Les paramètres du fichier validation_config.json sont expliqués dans la section Validation des données.
Le tableau suivant répertorie tous les paramètres de configuration globaux.
| Section | Paramètres de configuration |
|---|---|
activitiesGlobalParameters |
•administration_lakehouse_id : Identifiant de l’administrateur lakehouse.• bronze_lakehouse_id : identificateur de la lakehouse bronze.• silver_lakehouse_id : identificateur de la lakehouse argent.• keyvault_name : Azure valeur Key Vault lorsqu’elle est déployée avec l’offre Azure Marketplace.• enable_hds_logs : active la journalisation la valeur par défaut définie sur true.• movement_config_path : Chemin d’accès au fichier file_orchestration_config .• : Chemin d’accès bronze_imaging_delta_table_path de la structure pour la table des modalités d’imagerie (si déployée).• : Chemin d’accès bronze_imaging_table_schema_path de la structure pour la schéma des modalités d’imagerie (si déployée).• omop_lakehouse_id : Identificateur de la maison du lakehouse (si déployé). |
| Activités pour healthcare#_msft_fhir_ndjson_bronze_ingestion | •source_path_pattern : Chemin d’accès OneLake au dossier processus.• move_failed_files_enabled : Indicateur permettant de déterminer si un fichier ayant échoué doit être déplacé du dossier Ingestion vers le dossier Échec .• compression_enabled : Indicateur pour déterminer si les fichiers NDJSON bruts seront compressés après le traitement.• target_table_name : Nom de la table d’ingestion clinique dans la maison du lac en bronze.• target_tables_path : Chemin OneLake pour toutes les tables delta dans la maison du lac en bronze.• max_files_per_trigger : Nombre de fichiers traités à chaque exécution.• max_structured_streaming_queries : Nombre de requêtes de traitement pouvant s’exécuter en parallèle.• : Chemin d’accès checkpoint_path OneLake pour le dossier de point de contrôle.• : Chemin d’accès schema_dir_path OneLake pour le dossier de schéma bronze.• : Configuration de validation_config_key la validation au niveau parent. Pour plus d’informations, consultez validation des données.• file_extension: Extension du fichier brut ingéré. |
| Activités healthcare#_msft_bronze_silver_flatten | •source_table_name : Nom de la table d’ingestion clinique dans la maison du lac en bronze.• config_path : Chemin d’accès OneLake au fichier config aplati.• source_tables_path : Chemin OneLake vers la source pour toutes les tables delta dans la lakehouse en bronze.• target_tables_path : Chemin OneLake vers la cible pour toutes les tables delta dans la lakehouse en argent.• : Chemin d’accès checkpoint_path OneLake pour le dossier de point de contrôle.• : Chemin d’accès schema_dir_path OneLake pour le dossier de schéma bronze.• max_files_per_trigger : Nombre de fichiers traités dans chaque exécution.• max_bytes_per_trigger : Nombre de octets traités dans chaque exécution.• max_structured_streaming_queries : Nombre de requêtes de traitement pouvant s’exécuter en parallèle. |
| Activités pour healthcare#_msft_imaging_dicom_extract_bronze_ingestion | •byos_enabled : Indicateur qui détermine si l’ingestion du jeu de données d’imagerie DICOM dans la lakehouse en bronze provient d’un emplacement de stockage externe via des raccourcis OneLake. Dans ce cas, les fichiers ne sont pas déplacés vers le dossier Process comme ils le seraient autrement.• external_source_path : Chemin OneLake pour le raccourci Dossier externe dans la maison du lac en bronze.• process_source_path : Chemin OneLake pour le raccourci processus dans la maison du lac en bronze.• : Chemin d’accès checkpoint_path OneLake pour le dossier de point de contrôle.• move_failed_files : Indicateur déterminer si un fichier ayant échoué est déplacé du Ingestion vers le dossier Échec .• compression_enabled : Indicateur pour déterminer si les fichiers NDJSON bruts sont compressés après le traitement.• max_files_per_trigger : Nombre de fichiers traités dans chaque exécution.• num_retries : Nombre de nouvelles tentatives pour chaque traitement de fichier avant une erreur. |
| Activités pour healthcare#_msft_imaging_dicom_fhir_conversion | •fhir_ndjson_files_root_path : Chemin d’accès OneLake au dossier processus.• : Chemin d’accès avro_schema_path OneLake pour le dossier de schéma argent.• dicom_to_fhir_config_path : Chemin OneLake pour la configuration de mappage des métabalises DICOM vers la ressource FHIR ImagingStudy.• : Chemin d’accès checkpoint_path OneLake pour le dossier de point de contrôle.• max_records_per_ndjson : Nombre d’enregistrements traités dans un seul fichier NDJSON à chaque exécution.• subject_id_type_code : Code de valeur pour le numéro médical du patient dans les métadonnées DICOM. La valeur par défaut est définie sur MR, qui est Medical Record Number dans FHIR.• subject_id_type_code_system : système de code pour le numéro médical du patient dans les métadonnées DICOM.• subject_id_system : ID d'objet pour le numéro médical du patient dans les métadonnées DICOM. |
| Activités pour healthcare#_msft_omop_silver_gold_transformation | •vocab_path : Chemin d’accès OneLake au dossier de données de référence dans la lakehouse en bronze où sont stockés les OMOP jeux de données de vocabulaire.• : Chemin d’accès vocab_checkpoint_path OneLake pour le dossier de point de contrôle.• omop_config_path : Chemin OneLake pour la configuration de mappage de la maison du lac d’argent à la maison du lac d’or OMOP . |
Table BusinessEvents
La table delta BusinessEvents capture toutes les erreurs de validation, avertissements et autres notifications ou exceptions qui peuvent se produire pendant les processus d’ingestion et de transformation. Utilisez ce tableau pour surveiller la progression de l’exécution de l’ingestion au niveau de l’utilisateur et au niveau fonctionnel, plutôt qu’au niveau du journal système. Par exemple, il identifie les fichiers bruts qui ont introduit des erreurs de validation ou des avertissements lors de l’ingestion. Pour les journaux au niveau du système et pour surveiller Apache Spark les activités dans tous les lakehouses, vous pouvez utiliser le hub de surveillance Fabric, avec la possibilité d’intégrer Azure Log Analytics.
La table suivante répertorie les colonnes de la table BusinessEvent :
| Column | Description |
|---|---|
id |
Identificateur unique (GUID) de chaque ligne de données dans la table. |
activityName |
Nom de l’activité/du bloc-notes qui a généré l’échec et/ou l’erreur ou l’avertissement de validation. |
targetTableName |
Table cible pour l’activité de données qui a généré l’événement. |
targetFilePath |
Chemin au fichier cible pour l’activité de données qui a généré l’événement. |
sourceTableName |
Table source pour l’activité de données qui a généré l’événement. |
sourceLakehouseName |
Lakehouse source pour l’activité de données qui a généré l’événement. |
targetLakehouseName |
Lakehouse cible pour l’activité de données qui a généré l’événement. |
sourceFilePath |
Chemin au fichier source pour l’activité de données qui a généré l’événement. |
runId |
ID exécution pour l’activité de données qui a généré l’événement. |
severity |
Niveau de gravité de l’événement, qui peut avoir l’une des deux valeurs suivantes : Error ou Warning. Error Signifie que vous devez résoudre cet événement avant de poursuivre l’activité de données. Warning sert de notification passive, ne nécessitant généralement aucune action immédiate. |
eventType |
Fait la distinction entre les événements générés par le moteur de validation et les événements génériques générés par les utilisateurs ou les exceptions non gérées/système que les utilisateurs souhaitent faire apparaître dans la table BusinessEvent . |
recordIdentifier |
Identificateur de l'enregistrement source. Cette colonne diffère de la id colonne car elle représente un nouvel identificateur unique pour chaque événement dans la table BusinessEvents . |
recordIdentifierSource |
Système source pour l’identificateur de l’enregistrement source. Par exemple, si le système source est le DME, le nom ou l’URL du DME sert de source. |
active |
Indicateur indiquant si l’événement (erreur ou avertissement) est résolu. |
message |
Message descriptif de l’événement, de l’erreur ou de l’avertissement. |
exception |
Message d’exception non gérée/système. |
customDimensions |
Applicable lorsque les données source de la validation ou de l’exception ne sont pas une colonne discrète dans une table. Par exemple, lorsque les données source sont un attribut dans un objet JSON enregistré sous forme de chaîne dans une seule colonne, l’objet JSON complet est fourni comme dimension personnalisée. |
eventDateTime |
Horodatage auquel l’événement ou l’exception est généré. |
Validation des données
Le moteur de validation des données dans les solutions de données de santé garantit Microsoft Fabric que les données brutes répondent à des critères prédéfinis avant d’être ingérées dans la maison du lac de bronze. Vous pouvez configurer les règles de validation au niveau de la table et de la colonne dans la maison de lac bronze. À l’heure actuelle, ces règles s’appliquent exclusivement pendant le processus d’ingestion, des fichiers bruts aux tables delta dans la maison du lac en bronze.
Lorsqu’un fichier brut est traité, les règles de validation s’appliquent au niveau de l’ingestion. Il existe deux niveaux de gravité pour la validation : Error et Warning. Si une règle de validation est définie Error, le pipeline s’arrête lorsque la règle n’est pas respectée et le fichier défectueux est déplacé vers le dossier Échec . Si la gravité est définie Warning, le pipeline poursuit le traitement et le fichier est déplacé vers le dossier Processus. Dans les deux cas, les entrées reflétant les erreurs ou les avertissements sont créées dans la table BusinessEvents au sein du lakehouse d’administration.
La table BusinessEvents capture les journaux et les événements au niveau de l’entreprise dans tous les lakehouses pour n’importe quelle activité, bloc-notes ou pipeline de données dans les solutions de données de santé. Toutefois, la configuration actuelle n’applique les règles de validation que lors de l’ingestion, ce qui peut entraîner le non-remplissage de certaines colonnes de la table BusinessEvents en raison d’erreurs de validation et d’avertissements.
Vous pouvez configurer les règles de validation des données dans le fichier validation_config.json dans le lakehouse d’administration. Par défaut, les meta.lastUpdated colonnes et id de la table ClinicalFhir de la maison du lac de bronze sont définies selon les besoins. Ces colonnes sont essentielles pour déterminer comment les mises à jour et les insertions sont gérées dans le Silver Lakehouse, comme expliqué dans Gestion des mises à jour.
Le tableau suivant répertorie les paramètres de configuration pour la validation des données :
| Type de configuration | Paramètres |
|---|---|
| Niveau de la maison du lac | bronze : étendue des nœuds de validation et d’identificateur d’enregistrement. Dans ce cas, la valeur est définie sur la maison du lac en bronze. |
| Contrôles | •validationType type de exists validation vérifie si une valeur pour l’attribut configuré est fournie dans le fichier brut (données source).• attributeName: Nom d’attribut de l’attribut à valider.• validationMessage : Message décrivant l’erreur ou l’avertissement de validation.• severity : Indique le niveau du problème, qui peut être l’un ou Error l’autre Warning.• tableName: Nom de table de l’attribut à valider. Un astérisque (*) indique que cette règle s’applique à toutes les tables comprises dans le champ d’application de ce lakehouse. |
recordIdentifier |
•attributeName : Identificateur d’enregistrement du fichier source/brut placé dans la recordIdentifier colonne de la table BusinessEvent .• jsonPath : valeur facultative qui représente le chemin d’accès JSON d’une colonne ou d’un attribut pour la valeur à placer dans la recordIdentifier colonne de la table BusinessEvent . Cette valeur est applicable lorsque les données source de la validation ne sont pas une colonne discrète dans une table. Par exemple, si les données source sont un attribut dans un objet JSON stocké sous forme de chaîne dans une seule colonne, le chemin JSON dirige vers l’attribut spécifique qui sert d’identificateur d’enregistrement. |