Utiliser l’enrichissement de notes cliniques non structurées (version préliminaire) dans les solutions de données de santé
[Cet article fait partie de la documentation en version préliminaire et peut faire l’objet de modifications.]
Note
Ce contenu est en cours de mise à jour.
L’enrichissement de notes cliniques non structurées (version préliminaire) est une fonctionnalité qui utilise le service Text Analytics for Health d’Azure AI Language pour extraire des entités clés Fast Healthcare Interoperability Resources (FHIR) de notes cliniques non structurées. Il crée des données structurées à partir de ces notes cliniques. Vous pouvez ensuite analyser ces données structurées pour en tirer des informations, des prédictions et des mesures de qualité visant à améliorer les résultats médicaux des patients.
Pour en savoir plus sur la fonctionnalité et comprendre comment la déployer et la configurer, consultez :
- Présentation de l'enrichissement de notes cliniques non structurées (version préliminaire)
- Déployer et configurer l’enrichissement de notes cliniques non structurées (version préliminaire)
L’enrichissement de notes cliniques non structurées (version préliminaire) dépend directement de la fonctionnalité de base des données de santé. Assurez-vous au préalable de configurer et d’exécuter correctement les pipelines des sources de données de santé.
Conditions préalables
- Déployer les solutions de données de santé dans Microsoft Fabric
- Installez les notebooks et pipelines de base dans Déployer les sources des données de santé.
- Configurez le service de langage Azure comme expliqué dans Configurer le service de langage Azure.
- Déployer et configurer l’enrichissement de notes cliniques non structurées (version préliminaire)
- Déployer et configurer les transformation de OMOP. Cette étape est facultative.
Service d’ingestion NLP
Le notebook healthcare#_msft_ta4h_silver_ingestion exécute le module NLPIngestionService dans la bibliothèque de solutions de données de santé pour appeler le service Text Analytics for Health. Ce service extrait des notes cliniques non structurées de la ressource FHIR DocumentReference.Content pour créer une sortie aplatie. Pour en savoir plus, consultez Vérifier la configuration du bloc-notes.
Stockage des données dans la couche d’argent
Après l’analyse de l’API de traitement du langage naturel (NLP), la sortie structurée et aplatie est stockée dans les tables natives suivantes dans la lakehouse healthcare#_msft_silver :
- nlpentity : Contient les entités aplaties extraites des notes cliniques non structurées. Chaque ligne est un terme unique extrait du texte non structuré après avoir effectué l’analyse du texte.
- nlprelationship : fournit la relation entre les entités extraites.
- nlpfhir : contient le bundle de sortie FHIR sous forme de chaîne JSON.
Pour suivre le dernier horodatage mis à jour, le NLPIngestionService utilise le parent_meta_lastUpdated champ dans les trois tables Silver Lakehouse. Ce suivi garantit que le document source DocumentReference, qui est la ressource parent, est d’abord stocké pour maintenir l’intégrité référentielle. Ce processus permet d’éviter les incohérences dans les données et les ressources orphelines.
Important
Actuellement, Text Analytics for Health renvoie les vocabulaires répertoriés dans la documentation sur le vocabulaire du métathésaurus UMLS. Pour obtenir des conseils sur ces vocabulaires, consultez Importer des données depuis UMLS.
Pour la version préliminaire, nous utilisons les terminologies SNOMED-CT (Systematized Nomenclature of Medicine - Clinical Terms), LOINC (Logical Observation Identifiers, Names, and Codes) et RxNorm qui sont incluses dans l’exemple de jeu de données OMOP sur la base des directives de l’Observational Health Data Sciences and Informatics (OHDSI).
Transformation OMOP
Les solutions de données de santé offrent Microsoft Fabric également une autre capacité pour les transformations de l’Observational Medical Outcomes Partnership (OMOP). Lorsque vous exécutez cette fonctionnalité, la transformation sous-jacente du Silver Lakehouse au OMOP Gold Lakehouse transforme également la sortie structurée et aplatie de l’analyse des notes cliniques non structurées. La transformation lit la table nlpentity dans Silver Lakehouse et mappe la sortie à la table NOTE_NLP dans le OMOP maison de lac dorée.
Pour plus d’informations, consultez Vue d’ensemble de transformation de OMOP.
Voici le schéma des sorties NLP structurées, avec la colonne NOTE_NLP correspondante mappée au OMOP modèle de données commun :
| Référence du document aplati | Description | Mappage Note_NLP | Échantillonner des données |
|---|---|---|---|
| ID | Identificateur unique pour l'entité. Clé composite de parent_id, offset et length. |
note_nlp_id |
1380 |
| parent_id | Clé étrangère du texte documentreferencecontent aplati à partir duquel le terme a été extrait. | note_id |
625 |
| texte | Texte de l’entité tel qu’il s’affiche dans le document. | lexical_variant |
Aucune allergie connue |
| Décalage | Décalage de caractères du terme extrait dans le texte d’entrée documentreferencecontent . | offset |
294 |
| data_source_entity_id | ID de l’entité dans le catalogue source donné. | note_nlp_concept_id et note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | La date du documentreferencecontent traitement de l’analyse de texte. | nlp_date_time et nlp_date |
2023-05-17T00:00:00.0000000 |
| modèle | Nom et version du système NLP (Nom du système Text Analytics for Health NLP et la version). | nlp_system |
MSFT TA4H |

Limites du service pour Text Analytics for Health
- Le nombre maximum de caractères par document est limité à 125 000.
- La taille maximale des documents contenus dans l’ensemble de la demande est limitée à 1 Mo.
- Le nombre maximum de Documents par requête est limité à :
- 25 pour l'API basée sur web.
- 1 000 pour le conteneur.
Activer les journaux
Suivez ces étapes pour activer la journalisation des demandes et des réponses pour l’API Text Analytics for Health :
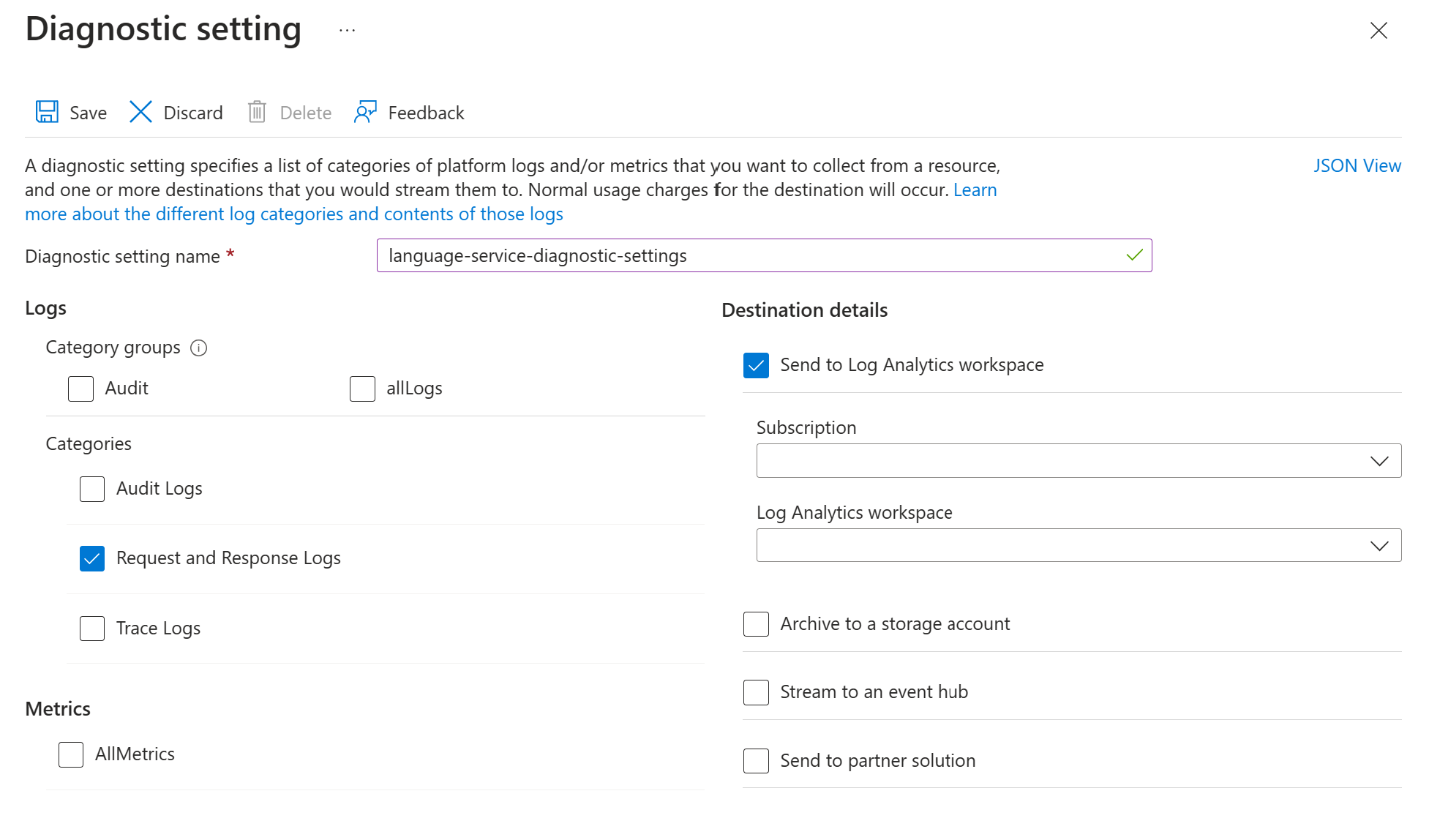
Activez les paramètres de diagnostic pour votre ressource de service Azure Language en suivant les instructions dans Activer la journalisation des diagnostics pour les services Azure AI. Cette ressource est le même service linguistique que celui que vous avez créé lors de la Configurer le service de langue Azure étape de déploiement.
- Entrez un nom de paramètre de diagnostic.
- Définissez la catégorie sur Journaux de demandes et de réponses.
- Pour plus de détails sur la destination, sélectionnez Envoyer à l’espace de travail Log Analytics, puis sélectionnez l’espace de travail Log Analytics requis. Si vous n’avez pas d’espace de travail, suivez les instructions pour en créer.
- Enregistrez les paramètres.
Accédez à la section Configuration NLP dans le bloc-notes du service d’ingestion NLP. Mettre à jour la valeur du paramètre de configuration
enable_text_analytics_logsàTrue. Pour plus d’informations sur ce notebook, consultez Vérifier la configuration du bloc-notes.

Afficher les journaux dans Azure Log Analytics
Pour explorer les données d’analyse des journaux :
- Naviguez vers votre espace de travail Log Analytics.
- Localisez et sélectionnez Journaux. À partir de cette page, vous pouvez exécuter des requêtes sur vos journaux.
Exemple de requête
Voici une requête Kusto de base que vous pouvez utiliser pour explorer vos données de journal. Cet exemple de requête récupère toutes les demandes ayant échoué auprès du fournisseur de ressources Azure Cognitive Services au cours de la dernière journée, regroupées par type d’erreur :
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature