Déployer et configurer la transformation OMOP dans les solutions de données de santé
Note
Ce contenu est en cours de mise à jour.
Transformations OMOP prépare les données pour des analyses standardisées via les normes communautaires ouvertes de l’Observational Medical Outcomes Partnership (OMOP). Vous pouvez utiliser cette fonctionnalité après avoir déployé les solutions de données de santé et la fonctionnalité Sources des données de santé dans votre espace de travail Fabric.
Les transformation OMOP est une fonctionnalité facultative sous les solutions de données de santé dans Microsoft Fabric. Vous avez la possibilité de décider de l’utiliser ou non, en fonction de vos besoins ou scénarios spécifiques.
Conditions préalables
- Déployer les solutions de données de santé dans Microsoft Fabric.
- Installez les notebooks et pipelines de base dans Déployer les sources des données de santé.
Déployer les transformations OMOP
Vous pouvez déployer la fonctionnalité à l’aide du module de configuration expliqué dans Solutions de données de santé : déployer les sources des données de santé. Toutefois, l’étape de sélection des exemples de données de ce module ne déploie pas les exemples de données pour cette fonctionnalité. Les exemples de données Jeux de données Transformations OMOP s’installent exclusivement dans votre environnement de solutions de données de santé une fois que vous avez terminé le déploiement de la fonctionnalité.
Si vous n’avez pas utilisé le module d’installation pour déployer la fonctionnalité et que vous souhaitez l’utiliser à la place, procédez comme suit :
Accédez à la page d’accueil des solutions de données de santé sur Fabric.
Sélectionnez la vignette Transformations OMOP.
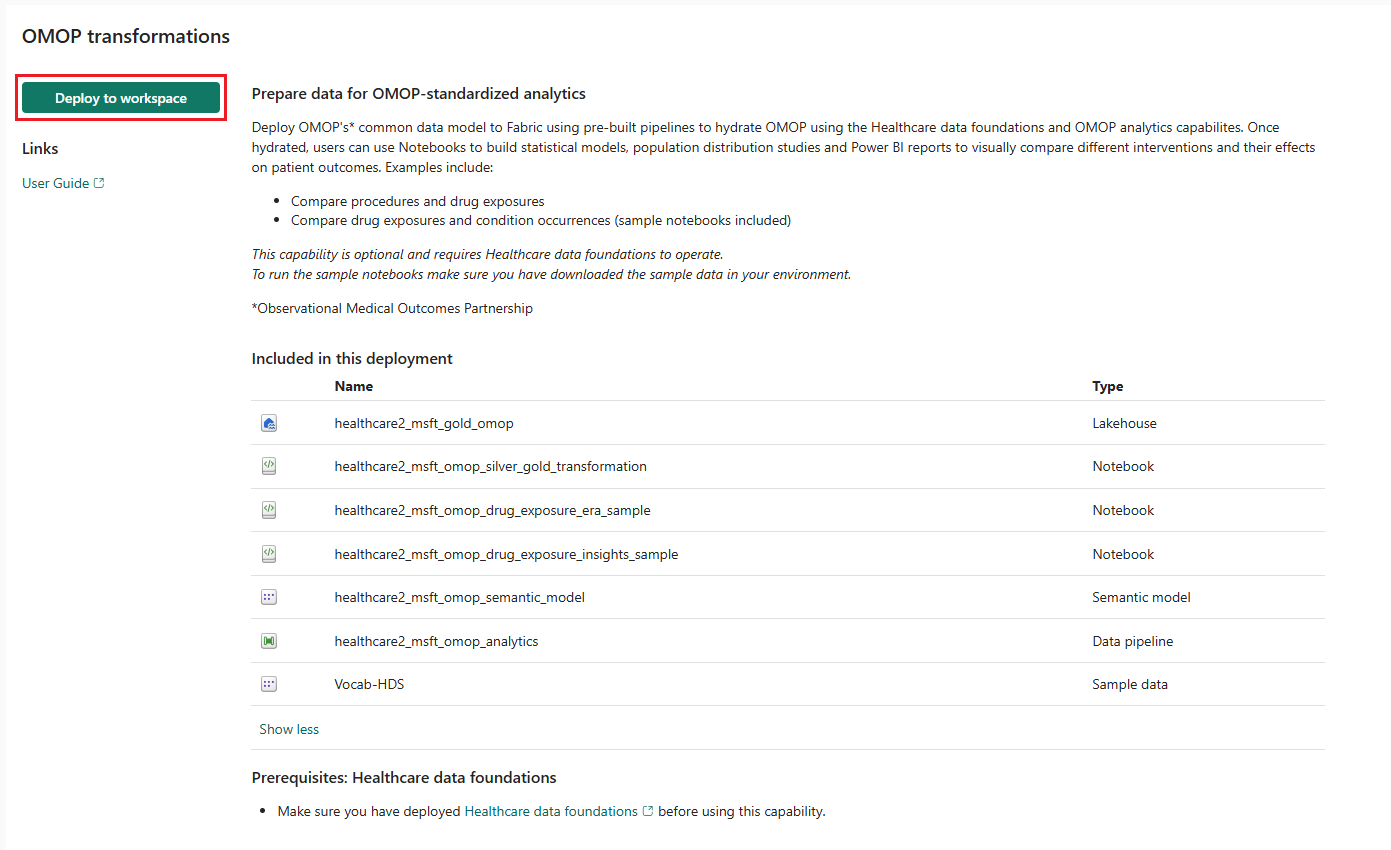
Sur la page des fonctionnalités, sélectionnez Déployer sur l’espace de travail.
Le déploiement peut prendre plusieurs minutes. Ne fermez pas l’onglet ou le navigateur pendant que le déploiement est en cours. Pendant que vous patientez, vous pouvez travailler dans un autre onglet.
Une fois le déploiement terminé, vous pouvez voir une notification dans la barre de messages.
Sélectionnez Gérer la capacité dans la barre de messages pour accéder à la page Gestion des capacités.
Ici, vous pouvez afficher, configurer et gérer les artefacts déployés avec la fonctionnalité.


Artefacts
Cette fonctionnalité installe les artefacts suivants dans votre environnement de solutions de données de santé :
| Artefact | Type |
|---|---|
| healthcare#_msft_gold_omop | Lakehouse |
| healthcare#_msft_omop_silver_gold_transformation | Bloc-notes |
| healthcare#_msft_omop_drug_exposure_era_sample | Bloc-notes |
| healthcare#_msft_omop_drug_exposure_insights_sample | Bloc-notes |
| healthcare#_msft_omop_analytics | Pipeline de données |
| healthcare#_msft_omop_semantic_model | Modèle sémantique |
| Vocab-HDS | Échantillonner des données |
Examiner le bloc-notes argent OMOP
Le notebook healthcare#_msft_omop_silver_gold_transformation utilise les API OMOP fournies dans le cadre de la bibliothèque de solutions de données de santé pour la transformation des données. Le bloc-notes transforme les ressources du healthcare#_msft_silver lakehouse en OMOP Common Data Model. Les données transformées sont ensuite insérées dans la maison du OMOP lac.
Le notebook se déploie avec les valeurs préconfigurées requises pour exécuter le pipeline de données transformation OMOP. Certains paramètres de configuration sont hérités de la configuration globale et peuvent être remplacés au niveau du notebook. Par défaut, il n’est pas nécessaire d’apporter des modifications à la fichiers de configuration du notebook. Si nécessaire, vous pouvez examiner ou modifier la configuration en sélectionnant les blocs-notes et fichiers de configuration respectifs dans votre environnement.
Pour en savoir plus sur l’exécution du notebook, consultez Utiliser les transformation OMOP.
Passez en revue le modèle sémantique OMOP
Le OMOP modèle sémantique, healthcare#_msft_omop_semantic_model, est un modèle sémantique construit sur mesure basé sur la maison du lac d’or OMOP . Il inclut quelques relations CDM version 5.4 OMOP clés entre les tables suivantes OMOP :
- Emplacement
- Personne
- Observation
- Procedure_Occurrence
- Condition_Occurrence
- Note
- Drug_Exposure
- Visit_Ocurrence
- Image_Occurrence
- Mesure
Ces relations proviennent de l’ensemble minimal nécessaire pour générer des Power BI rapports dans la fonctionnalité Découvrir et créer des cohortes (version préliminaire) dans les solutions de données de santé. Vous pouvez utiliser ce modèle sémantique comme base, en ajoutant d’autres OMOP tables et relations à partir de la OMOP lakehouse pour créer des rapports personnalisés Power BI à partir de vos OMOP données lakehouse standard.
Configurer l’exemple de bloc-notes de l’ère d’exposition aux médicaments
L’exemple de notebook healthcare#_msft_omop_drug_exposure_era_sample montre comment générer les enregistrements de la table drug_era dans OMOP en utilisant le langage PySpark (Python) dans un notebook Azure Synapse Analytics, principalement à des fins exploratoires. Le drug_era la génération des enregistrements de table suit le Exemple de script de l’ère de la drogue OHDSI, qui est adapté pour fonctionner avec PySpark dans Azure Synapse Analytics. Le code générateur de l’ère du médicament est inclus dans la bibliothèque Python personnalisée, qui est empaquetée sous la forme d’un fichier WHL (Wheel) et téléchargée dans un Apache Spark pool pour un accès facile.
Avant d’exécuter le bloc-notes, gardez à l’esprit les conditions préalables suivantes :
Assurez-vous que le OMOP la base de données contient des données valides dans les tableaux suivants :
- drug_exposure
- concept
- concept_ancestor
Vous pouvez générer ces données à l’aide des exemples de données ou de vos propres données en exécutant le pipeline FHIR vers OMOP données.
Assurez-vous que le package Wheel de bibliothèque personnalisé est attaché au pool Spark que vous utilisez pour exécuter ce notebook.
Le paramètre de configuration clé de ce portable est le omop_database_name. Ce paramètre identifie le nom du OMOP base de données contenant les données permettant de générer le drug_era tableau. Ne mettez à jour cette valeur que si votre OMOP base de données diffère de la valeur par défaut dans le fichier de configuration globale.
Si la OMOP drug_exposure table se remplit avec des données valides, ce bloc-notes invoque le DrugEraGenerator module qui regroupe les périodes de temps pendant lesquelles une personne est exposée à un ingrédient médicamenteux actif, avec un intervalle de 30 jours. Le DrugEraGenerator le module supprime tous les éléments existants drug_era enregistre et génère de nouveaux enregistrements, sur la base des dernières OMOP données.
Pour en savoir plus sur l’exécution du notebook, consultez Utiliser les exemples de notebooks de transformation dans OMOP.
Configurer l’exemple de bloc-notes d'informations d’exposition aux médicaments
L’exemple de notebook healthcare#_msft_omop_drug_exposure_insights_sample illustre une analyse exploratoire sur la table drug_era à l’aide de PySpark dans un Azure Synapse Analytics notebook. L’analyse génère un histogramme affichant les expositions secondaires des patients aux principes actifs, stratifiées par sexe et par âge pour une année spécifique. La table drug_era est générée à l’aide d’une bibliothèque personnalisée DrugEraGenerator que le notebook précédent healthcare#_msft_omop_drug_exposure_era_sample appelle. Cette analyse étend la requête d’exposition aux drogues DEX03 : répartition de l’âge, stratifiée par drogue en incorporant une stratification basée à la fois sur le sexe et l’âge.
Avant d’exécuter le bloc-notes, gardez à l’esprit les conditions préalables suivantes :
- Si vous souhaitez modifier la configuration du notebook, assurez-vous d’en faire une copie. Ne mettez pas à jour le notebook directement.
- Assurez-vous que la table drug_era contient des données en exécutant le bloc-notes de l’ère d’exposition aux drogues. L’exécution de ce bloc-notes remplace tous les enregistrements drug_era existants par de nouveaux enregistrements, sur la base des OMOP données les plus récentes.
- Utilisez ce bloc-notes tel quel pour une analyse exploratoire et créez une copie pour effectuer une analyse personnalisée.
Voici les principaux paramètres de configuration du portable. Vous pouvez modifier ces paramètres pour une analyse exploratoire alternative sur les expositions aux médicaments des patients :
primary_drug_concept_id: La principale exposition aux principes actifs pour les patients.secondary_drug_concept_id: La exposition secondaire aux principes actifs pour les patients.year: L’année cible au cours de laquelle les patients ont été activement exposés aux médicaments primaires et secondaires.
Pour en savoir plus sur l’exécution du notebook, consultez Utiliser les exemples de notebooks de transformation dans OMOP.