Déployer et configurer l’analyse de la gestion des soins dans les solutions de données de santé
Nonte
Cet article fournit des informations en version préliminaire et décrit le comportement de la fonctionnalité en version préliminaire publique. Le contenu est susceptible d’être modifié lorsque la fonctionnalité sera mise à la disposition générale.
L’analyse de la gestion des soins permet aux organisations de soins de santé de créer des scénarios analytiques qui améliorent les résultats pour les patients et soutiennent la prise de décision basée sur les données. Vous pouvez déployer et configurer cette fonctionnalité après avoir déployé les solutions de données de santé (version préliminaire) et la fonctionnalité Sources des données de santé sur votre espace de travail Fabric. Cet article décrit le processus de déploiement et explique comment configurer les exemples de données.
L’analyse de la gestion des soins est une fonctionnalité facultative sous les solutions de données de santé dans Microsoft Fabric. Vous avez la possibilité de décider de l’utiliser ou non, en fonction de vos besoins ou scénarios spécifiques.
Conditions préalables
Déployer les solutions de données de santé dans Microsoft Fabric
Installez les notebooks et pipelines de base dans Déployer les sources des données de santé.
Déployez et configurez les transformations des données de réclamations CMS et exécutez le pipeline de transformations des données de réclamations.
Déployez les jeux de données FHIR/échantillons cliniques comme expliqué dans Déployer les exemples de données. Nous utilisons cet exemple de données pour tester la capacité.
Déployer les analyse de la gestion des soins
Vous pouvez déployer la fonctionnalité à l’aide du module de configuration expliqué dans Solutions de données de santé : déployer les sources des données de santé.
Si vous n’avez pas utilisé le module d’installation pour déployer la fonctionnalité et que vous souhaitez l’utiliser à la place, procédez comme suit :
Accédez à la page d’accueil des solutions de données de santé sur Fabric.
Sélectionnez la vignette Analyse de la gestion des soins.
Sur la page des fonctionnalités, sélectionnez Déployer sur l’espace de travail.
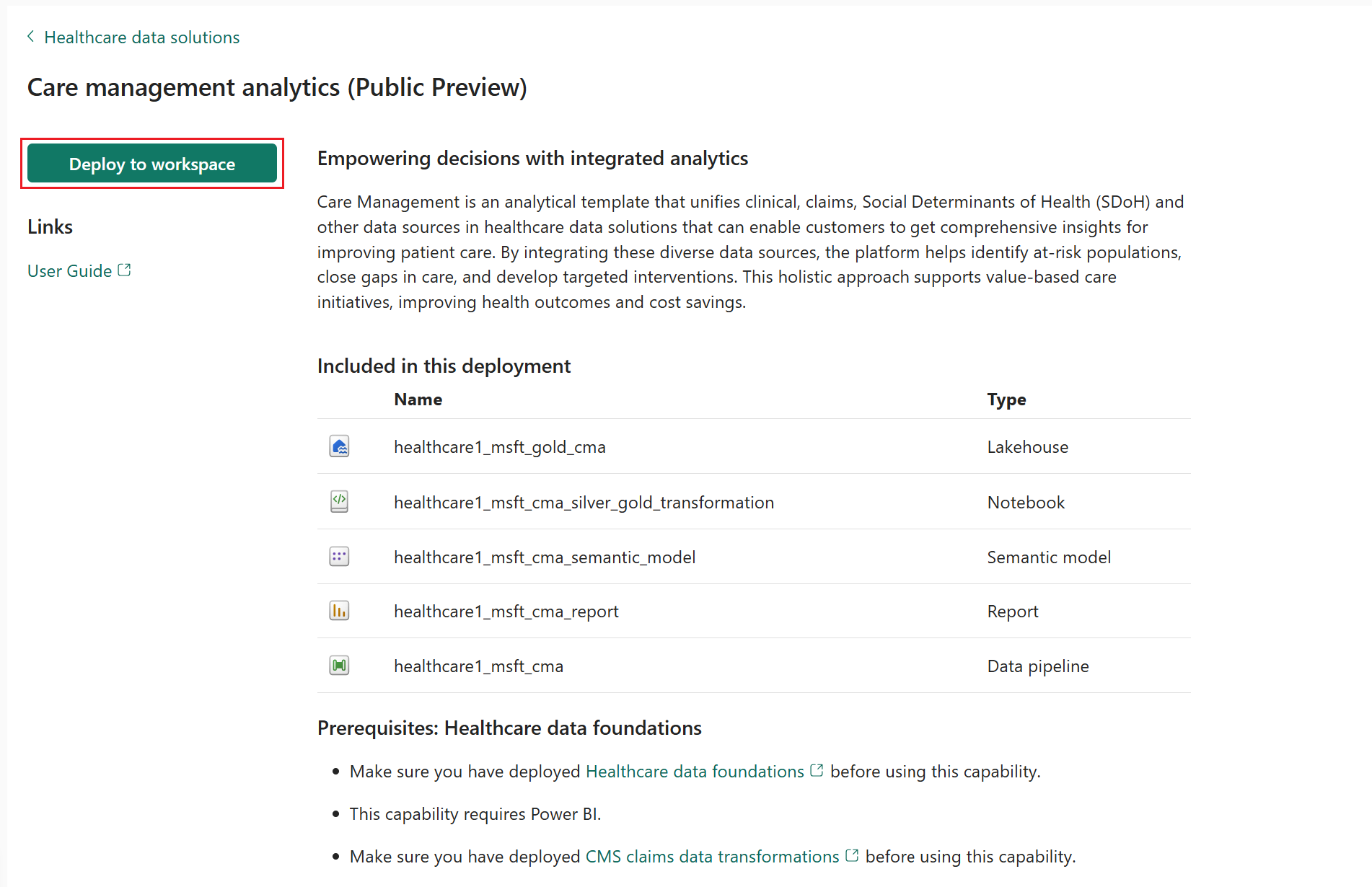
Le déploiement peut prendre plusieurs minutes. Ne fermez pas l’onglet ou le navigateur pendant que le déploiement est en cours. Pendant que vous patientez, vous pouvez travailler dans un autre onglet.
Une fois le déploiement terminé, vous pouvez voir une notification dans la barre de messages.
Sélectionnez Gérer la capacité dans la barre de messages pour accéder à la page Gestion des capacités.
Ici, vous pouvez afficher, configurer et gérer les artefacts déployés avec la fonctionnalité.


Artefacts
Cette fonctionnalité installe les artefacts suivants dans votre environnement de solutions de données de santé :
| Artefact | Type | Description |
|---|---|---|
| healthcare#_msft_gold_cma | Lakehouse | Une maison en or construite sur mesure pour l’analyse de la gestion des soins, où les données sont affinées et structurées pour des analyses et des rapports avancés. |
| healthcare#_msft_cma_silver_gold_transformation | Bloc-notes | Transforme et agrège les données de la maison du lac d’argent vers l’analyse de la gestion des soins de la maison du lac d’or. |
| healthcare#_msft_cma | Pipeline de données | Exécute de manière séquentielle une série de blocs-notes pour transformer les données de leur état brut dans la maison du lac en bronze à un état transformé dans la maison du lac en argent. Il agrège également les données de la maison du lac d’or. |
| healthcare#_msft_cma_semantic_model | Modèle sémantique | Un modèle de données complet optimisé pour les tableaux de bord d’analyse prédictive et de reporting, fournissant des informations sur la qualité des soins, les résultats pour les patients et l’efficacité opérationnelle. |
| healthcare#_msft_cma_report | Créer un rapport | Un Power BI modèle de tableau de bord, avec des rapports interactifs issus du modèle de données d’analyse de la gestion des soins, pour vous aider à prendre des décisions fondées sur les données. |
Configurer les exemples de données
Les exemples de données fournis avec les solutions de données de santé comprennent des exemples de jeux de données FHIR (cliniques). Nous utilisons ces exemples de données pour exécuter et tester le pipeline d’analyse de la gestion des soins. Vous pouvez également explorer la transformation et la progression des données à travers les lakehouses bronze, argent et or.
Pour accéder aux exemples de jeux de données, vérifiez si vous avez téléchargé les données de l’échantillon clinique dans le dossier suivant dans la maison du lac en bronze : SampleData\Clinical\FHIR-NDJSON\FHIR-HDS\51KSyntheticPatients L’étape Déployer les exemples de données déploie automatiquement l’exemple de jeu de données 51KSyntheticPatients dans le dossier des exemples de données.
Ensuite, vous devez charger les exemples de données dans le dossier Processus. Déposez les fichiers de données d’échantillons cliniques dans ce dossier, afin qu’ils puissent être automatiquement déplacés vers une structure de dossiers organisée dans la maison du lac en bronze. Pour en savoir plus sur la structure dossiers unifié, reportez-vous à la section Structure unifiée des dossiers.
Pour charger les exemples de données :
- Allez dans la maison du
Process\Clinical\FHIR-NDJSON\FHIR-HDS\<namespace_folder>lakehouse en bronze. - Sélectionnez les points de suspension (...) à côté du nom du dossier, puis sélectionnez >Charger>Charger le dossier.
- Sélectionnez et chargez les données d’échantillon clinique à partir du dossier de données d’exemple.
Vous pouvez également exécuter l’extrait de code suivant dans un notebook pour copier les exemples de données dans le dossier Processus.
Dans votre espace de travail Fabric, Sélectionner + Nouvel élément.
Dans le volet Nouvel élément , recherchez et sélectionnez Notebook.
Copiez l’extrait de code suivant dans le notebook :
from notebookutils import mssparkutils source_path = 'abfss://<workspace_name>@onelake.dfs.fabric.microsoft.com/<bronze_lakehouse_name>/Files/SampleData/Clinical/FHIR-NDJSON/FHIR-HDS/51KSyntheticPatients' target_path = 'abfss://<workspace_name>@onelake.dfs.fabric.microsoft.com/<bronze_lakehouse_name>/Files/Process/Clinical/FHIR-NDJSON/FHIR-HDS/' mssparkutils.fs.fastcp(source_path,target_path)Exécuter le notebook. Les ensembles de données cliniques sont maintenant déplacés vers l’emplacement désigné dans le dossier Processus.