Implémenter l’architecture de lakehouse en médaillon dans Microsoft Fabric
Cet article présente l’architecture de lac en médaillon et décrit comment implémenter une lakehouse dans Microsoft Fabric. Il s’adresse à plusieurs publics :
- Ingénieurs de données : les effectifs techniques qui conçoivent, créent et gèrent des infrastructures et systèmes permettant à leur organisation de collecter, stocker, traiter et analyser de grands volumes de données.
- Équipes informatique, décisionnelle et du Centre d’excellence : les équipes chargées de superviser les analyses au sein de l’organisation.
- Administrateurs Fabric : administrateurs chargés de superviser Fabric dans l’organisation.
L’architecture de lakehouse en médaillon, communément appelée architecture de médaillon, est un modèle de conception utilisé par les organisations pour organiser logiquement les données dans un lakehouse. Il s’agit de l’approche de conception recommandée pour Fabric.
L’architecture de médaillon comprend trois couches distinctes, également appelées zones. Chaque couche indique la qualité des données stockées dans le lakehouse, où les niveaux supérieurs représentant une qualité supérieure. Cette approche multicouches vous permet de générer une source unique de vérité pour les produits de données d’entreprise.
Il est important de noter que l'architecture en médaillon garantit l'ensemble des propriétés d'atomicité, de cohérence, d'isolation et de durabilité (ACID) au fur et à mesure que les données progressent à travers les couches. À partir de données brutes, une série de validations et de transformations prépare des données optimisées pour une analytique efficace. Il existe trois étapes de médaillon : bronze (brute), argent (validée) et or (enrichie).
Pour plus d’informations, consultez Qu’est-ce que l’architecture de lakehouse en médaillon ?
OneLake et lakehouse dans Fabric
Le lac de données forme la base d’un entrepôt de données moderne. Microsoft OneLake est un lac de données unique, unifié et logique pour l'ensemble de votre organisation. Cette solution est automatiquement approvisionnée avec chaque locataire Fabric et est conçue afin d’être l’unique emplacement pour toutes vos données d’analyse.
Vous pouvez utiliser OneLake pour :
- Supprimer les silos et réduire les efforts de gestion. Toutes les données organisationnelles sont stockées, gérées et sécurisées au sein d’une seule ressource de lac de données. Étant donné que OneLake est approvisionné par votre locataire Fabric, il n’y a pas d’autres ressources à gérer ou approvisionner.
- Réduire le déplacement et la duplication des données. L’objectif de OneLake est de stocker une seule copie des données. Moins de copies de données entraînent moins de déplacements des données, produisant ainsi des gains d’efficacité et une réduction de la complexité. Si nécessaire, vous pouvez créer un raccourci pour référencer les données stockées dans d’autres emplacements, plutôt que de les copier dans OneLake.
- L’utilisation avec plusieurs moteurs analytiques. Les données dans OneLake sont stockées en format ouvert. De cette façon, les données peuvent être interrogées par différents moteurs analytiques, notamment Analysis Services (utilisé par Power BI), T-SQL et Apache Spark. D’autres applications hors Fabric peuvent également utiliser des API et des kits de développement logiciel (SDK) pour accéder à OneLake.
Pour plus d'informations, consultez OneLake, le OneDrive des données.
Pour stocker des données dans OneLake, vous créez une lakehouse dans Fabric. Un lakehouse est une plateforme d’architecture de données permettant de stocker, gérer et analyser des données structurées et non structurées dans un emplacement unique. Il peut facilement être mis à l’échelle vers de grands volumes de données comprenant tous types et tailles de fichiers. De plus, étant donné qu’il est stocké dans un emplacement unique, il est facilement partagé et réutilisé dans toute l’organisation.
Chaque lakehouse dispose d’un point de terminaison d’analytique SQL intégré qui déverrouille les fonctionnalités d’entrepôt de données sans devoir déplacer de données. Cela signifie que vous pouvez interroger vos données dans le lakehouse à l’aide de requêtes SQL et sans configuration spéciale.
Pour plus d’informations, consultez Qu’est-ce qu’un lakehouse dans Microsoft Fabric ?
Tables et fichiers
Lorsque vous créez un lakehouse dans Fabric, deux emplacements de stockage physiques sont automatiquement approvisionnés pour les tables et fichiers.
- Tables est une zone gérée permettant d’héberger des tables de n’importe quel format dans Apache Spark (CSV, Parquet ou Delta). Toutes les tables, qu’elles soient créées automatiquement ou explicitement, sont reconnues en tant que tables dans le lakehouse. En outre, toutes les tables Delta, qui sont des fichiers de données Parquet avec un journal des transactions basé sur fichier, sont également reconnues en tant que tables.
- Fichiers est une zone non gérée permettant de stocker des données dans n’importe quel format de fichier. Les fichiers Delta stockés dans cette zone ne sont pas automatiquement reconnus en tant que tables. Si vous souhaitez créer une table sur un dossier Delta Lake dans la zone non gérée, vous devez créer explicitement un raccourci ou une table externe avec un emplacement orienté vers le dossier non géré qui contient les fichiers Delta Lake dans Apache Spark.
La principale distinction entre la zone gérée (tables) et la zone non gérée (fichiers) est le processus de découverte et d’inscription automatique des tables. Ce processus s’exécute sur n’importe quel dossier créé uniquement dans la zone gérée et pas dans la zone non gérée.
L’explorateur de lakehouse dans Microsoft Fabric fournit une représentation graphique unifiée de l’ensemble du lakehouse pour permettre aux utilisateurs de naviguer, accéder et mettre à jour leurs données.
Pour plus d’informations sur la découverte automatique de tables, consultez Découverte et inscription automatique de tables.
Stockage Delta Lake
Delta Lake est la couche de stockage optimisée qui fournit la base pour le stockage des données et des tables. Delta Lake prend en charge les transactions ACID pour les charges de travail Big Data. C’est pour cela que c’est le format de stockage par défaut dans un lakehouse Fabric.
Il est important de noter que Delta Lake offre une fiabilité, une sécurité et des performances dans le lakehouse pour les opérations de diffusion en continu et de traitement par lots. En interne, il stocke les données au format de fichier Parquet, mais il gère également les statistiques et journaux des transactions qui offrent des améliorations des fonctionnalités et performances par rapport au format Parquet standard.
Le format Delta Lake propose les principaux avantages suivants par rapport aux formats de fichier génériques.
- La prise en charge des propriétés ACID, dont particulièrement la durabilité pour empêcher la corruption des données.
- Des interrogations de lecture plus rapides.
- Une plus grande fraîcheur des données.
- La prise en charge des charges de travail par lots et par diffusion en continu.
- La prise en charge de la restauration des données à l’aide du voyage dans le temps Delta Lake.
- La conformité et des audits réglementaires améliorés à l’aide de l’historique des tables Delta Lake.
Fabric normalise le format de fichier de stockage avec Delta Lake. Par défaut, chaque moteur de charge de travail dans Fabric crée des tables Delta lorsque vous écrivez des données dans une nouvelle table. Pour plus d’informations, consultez Tables lakehouse et Delta Lake.
Architecture de médaillon dans Fabric
L’objectif de l’architecture de médaillon est d’améliorer de façon progressive et incrémentielle la structure et la qualité des données à mesure qu’elles progressent dans chaque étape.
L’architecture de médaillon compte trois couches distinctes, également appelées zones.
- Bronze : également appelée zone brute, cette première couche stocke les données sources dans leur format d’origine. Les données de cette couche peuvent généralement uniquement être ajoutées et sont inaltérables.
- Argent : également appelée zone enrichie, cette couche stocke les données provenant de la couche bronze. Les données brutes ont été nettoyées et normalisées. Elles sont désormais structurées en tant que tables (lignes et colonnes). Ces données peuvent également être intégrées à d’autres données pour fournir une vue d’entreprise de toutes les entités commerciales, telles que les clients et les produits, parmi d’autres.
- Or : également appelée zone organisée, cette couche stocke les données provenant de la couche argent. Les données sont affinées pour répondre à des exigences métier et d’analyse spécifiques en aval. Les tables sont généralement conformes à la conception de schéma en étoile qui prend en charge le développement de modèles de données optimisés pour les performances et la facilité d’utilisation.
Important
Étant donné qu’un lakehouse Fabric représente une seule zone, vous créez un lakehouse pour chacune des trois zones.
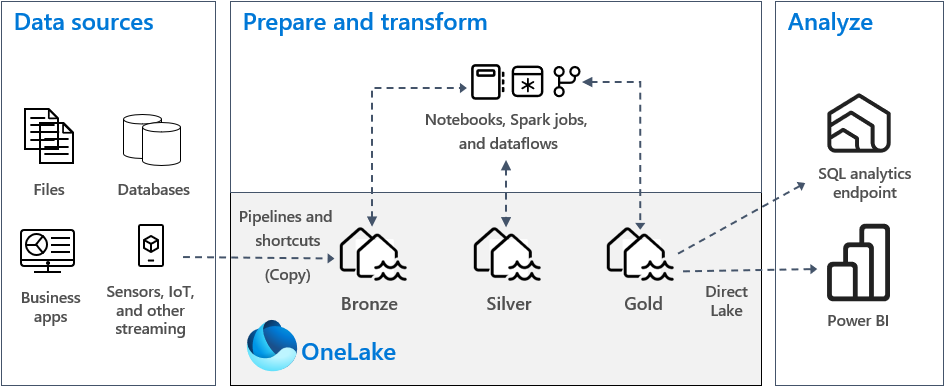
Dans une implémentation courante de l’architecture de médaillon dans Fabric, la zone bronze stocke les données au même format que la source de données. Les tables Delta sont un bon choix lorsque la source de données est une base de données relationnelle. Les zones argent et or contiennent des tables Delta.
Conseil
Pour savoir comment créer un lakehouse, parcourez le tutoriel de scénario bout-en-bout lakehouse.
Conseils à propos du lakehouse Fabric
Cette section vous conseille à propos de l’implémentation de votre lakehouse Fabric avec l’architecture de médaillon.
Modèle de déploiement
Pour implémenter l’architecture de médaillon dans Fabric, vous pouvez utiliser des lakehouses (un pour chaque zone), un entrepôt de données ou les deux à la fois. Votre décision doit se baser sur votre préférence et l’expertise de votre équipe. N’oubliez pas que Fabric vous offre de la flexibilité—vous pouvez utiliser différents moteurs analytiques qui fonctionnent sur la seule copie de vos données dans OneLake.
Voici deux modèles à prendre en compte.
- Modèle 1 : créer chaque zone en tant que lakehouse. Dans ce cas, les utilisateurs d’entreprise accèdent aux données à l’aide du point de terminaison d’analytique SQL.
- Modèle 2 : créer les zones bronze et argent en tant que lakehouses, et la zone or en tant qu’entrepôt de données. Dans ce cas, les utilisateurs d’entreprise accèdent aux données à l’aide du point de terminaison de l’entrepôt de données.
Bien que vous puissiez créer tous les lakehouses dans un seul espace de travail Fabric, nous vous conseillons de créer chaque lakehouse dans son propre espace de travail Fabric séparé. Cette approche vous offre plus de contrôle et une meilleure gouvernance au niveau des zones.
Pour la zone bronze, nous vous recommandons de stocker les données dans leur format d’origine, ou d’utiliser Parquet ou Delta Lake. Dans la mesure du possible, conservez les données dans leur format d’origine. Si les données sources proviennent de OneLake, Azure Data Lake Storage Gen2 (ADLS Gen2), Amazon S3 ou Google, créez un raccourci dans la zone bronze au lieu de copier les données.
Pour les zones argent et or, nous vous recommandons d’utiliser des tables Delta en raison des fonctionnalités supplémentaires et des améliorations de performances qu’elles proposent. Fabric standardise le format Delta Lake et chaque moteur dans Fabric écrit par défaut des données dans ce format. En outre, ces moteurs utilisent l’optimisation de temps d’écriture V-Order vers le format de fichier Parquet. Cette optimisation permet des lectures extrêmement rapides par les moteurs de calcul Fabric, tels que Power BI, SQL, Apache Spark et d’autres encore. Pour plus d'informations, consultez Optimisation de la table Delta Lake et V-Order.
Enfin, les organisations d’aujourd’hui sont confrontées à une croissance massive des volumes de données ainsi qu’au besoin d’organiser et de gérer ces données de manière logique, tout en facilitant une utilisation et une gouvernance plus ciblées et efficaces. Cela peut vous conduire à établir et gérer une organisation de données décentralisée ou fédérée avec gouvernance.
Pour atteindre cet objectif, vous pouvez envisager d’implémenter une architecture de maillage des données. Le maillage des données est un modèle d’architecture qui se concentre sur la création de domaines de données proposant des données en tant que produit.
Vous pouvez créer une architecture de maillage de données pour votre patrimoine de données dans Fabric en créant des domaines de données. Vous pouvez choisir de créer des domaines qui correspondent à vos domaines d’entreprise, dont le marketing, les ventes, l’inventaire et les ressources humaines, parmi d’autres. Vous pouvez alors implémenter l’architecture de médaillon en configurant des zones de données dans chacun de vos domaines.
Pour plus d'informations sur les domaines, consultez Domaines.
Comprendre le stockage des données dans les tables Delta
Cette section décrit d’autres rubriques d’aide à l’implémentation d’une architecture de lakehouse en médaillon dans Fabric.
Taille du fichier
En règle générale, une plateforme Big Data s’exécute mieux lorsqu’elle a un petit nombre de fichiers volumineux plutôt qu’un grand nombre de petits fichiers. Cela est dû au fait qu’une détérioration des performances se produit lorsque le moteur de calcul doit gérer de nombreuses opérations de métadonnées et de fichiers. Pour de meilleures performances d’interrogation, nous vous recommandons de viser des fichiers de données d’une taille d’environ 1 Go.
Delta Lake a une fonctionnalité appelée optimisation prédictive. L’optimisation des prédictions supprime la nécessité de gérer manuellement les opérations de maintenance pour les tables Delta. Lorsque cette fonctionnalité est activée, Delta Lake identifie automatiquement les tables qui peuvent bénéficier d’opérations de maintenance, puis optimise leur stockage. Elle peut fusionner de manière transparente de nombreux fichiers plus petits en fichiers volumineux, sans aucun impact sur d’autres lecteurs et enregistreurs de données. Bien que cette fonctionnalité doive constituer une partie de votre excellence opérationnelle et de votre travail de préparation des données, Fabric peut également optimiser ces fichiers de données pendant l’écriture des données. Pour plus d’informations, consultez Optimisation prédictive pour Delta Lake.
Conservation des données historique
Par défaut, Delta Lake conserve un historique de toutes les modifications apportées. Cela signifie que la taille des métadonnées historiques augmente au fil du temps. En fonction des besoins de votre entreprise, vous devez essayer de conserver les données historiques uniquement pendant un certain temps pour réduire vos coûts de stockage. Envisagez de conserver des données historiques uniquement pour le mois passé ou pendant une autre période appropriée.
Vous pouvez supprimer des données historiques plus anciennes d’une table Delta à l’aide de la commande VACUUM. Toutefois, n’oubliez pas que vous ne pouvez pas supprimer les données historiques des sept derniers jours (par défaut), afin de maintenir la cohérence des données. Le nombre de jours par défaut est contrôlé par la propriété de table delta.deletedFileRetentionDuration = "interval <interval>". Elle définit la période pendant laquelle un fichier doit être supprimé avant de pouvoir être considéré comme éligible à une opération « vacuum ».
Partitions de table
Lorsque vous stockez des données dans chaque zone, nous vous recommandons d’utiliser une structure de dossiers partitionnée, le cas échéant. Cette technique permet d’améliorer la facilité de gestion des données et les performances des requêtes. En règle générale, les données partitionnées dans une structure de dossiers entraînent une recherche d’entrées de données spécifiques plus rapide grâce à la taille/élimination de partition.
En règle générale, vous ajoutez des données à votre table cible à mesure que de nouvelles données arrivent. Toutefois, vous pouvez choisir de fusionner des données dans certains cas, car vous devez mettre à jour les données existantes en même temps. Dans ce cas, vous pouvez effectuer une opération upsert avec la commande MERGE. Lorsque votre table cible est partitionnée, veillez à utiliser un filtre de partition pour accélérer l’opération. De cette façon, le moteur peut éliminer les partitions qui n’ont pas besoin d’être mises à jour.
Accès aux données
Enfin, vous devez planifier et contrôler les personnes qui ont besoin d’accéder à des données spécifiques dans le lakehouse. Vous devez également comprendre les différents modèles de transaction que ces personnes utilisent lorsqu’elles accèdent à ces données. Vous pouvez ensuite définir le schéma de partitionnement de table approprié et la colocation des données avec les indexes Z-Order de Delta Lake.
Contenu connexe
Pour plus d’informations sur l’implémentation d’un lakehouse Fabric, consultez les ressources suivantes.
- Tutoriel : Scénario bout-en-bout lakehouse
- Tables lakehouse et Delta Lake
- Guide de décision Microsoft Fabric : choisir un magasin de données
- Optimisation de table Delta Lake et V-Order
- La nécessité d’optimiser l’écriture sur Apache Spark
- Des questions ? Essayez de demander à la communauté Fabric.
- Vous avez des suggestions ? Contribuez des idées pour améliorer Fabric.