Modèles sémantiques Power BI par défaut dans Microsoft Fabric
S'applique à :✅point de terminaison d'analytique SQL, Entrepôt et Base de données miroir dans Microsoft Fabric
Dans Microsoft Fabric, les modèles sémantiques Power BI sont une description logique d’un domaine analytique, avec des métriques, une terminologie et une représentation adaptées à l’entreprise, pour permettre une analyse plus approfondie. Ce modèle sémantique est généralement un schéma en étoile constitué de faits qui représentent un domaine, ainsi que de dimensions qui vous permettent d’analyser (c’est-à-dire de décomposer) le domaine afin d’explorer, de filtrer et de calculer différentes analyses. Le modèle sémantique est créé automatiquement, vous choisissez les tables, relations et mesures doivent être ajoutées, et la logique métier susmentionnée est héritée du lakehouse ou de l’entrepôt parent respectivement. L’expérience analytique peut ainsi démarrer rapidement en aval pour des besoins de logique métier et d’analyse avec un élément de Microsoft Fabric qui est géré, optimisé et synchronisé sans aucune intervention de l’utilisateur.
Les visualisations et les analyses contenues dans les rapports Power BI peuvent désormais être générées sur le web (ou en quelques étapes dans Power BI Desktop), permettant ainsi aux utilisateurs de gagner du temps, des ressources et, par défaut, de fournir une expérience de consommation transparente aux utilisateurs finaux. Le modèle sémantique Power BI par défaut suit la convention d’affectation de noms du lakehouse.
Les modèles sémantiques Power BI représentent une source de données prêtes pour la création de rapports, la visualisation, la découverte et la consommation. Les modèles sémantiques Power BI fournissent :
- Extension des constructions d’entrepôts pour inclure des hiérarchies, des descriptions, des relations. Cela autorise une compréhension sémantique plus approfondie d’un domaine.
- La possibilité de cataloguer, de rechercher et de trouver des informations du modèle sémantique Power BI dans le catalogue OneLake.
- Définition d’autorisations sur mesure pour l’isolation et la sécurité des charges de travail.
- Création de mesures et de métriques standardisées à des fins d’analyses reproductibles.
- Création de rapports Power BI à des fins d’analyses visuelles.
- Découverte et utilisation de données dans Excel.
- Connexion et analyse de données à l’aide d’outils tiers comme Tableau.
Pour plus d’informations sur Power BI, consultez Assistance sur Power BI.
Remarque
Microsoft a renommé le type de contenu jeu de données Power BI en modèle sémantique. Cela s’applique également à Microsoft Fabric. Pour plus d’informations, consultez Nouveau nom pour les jeux de données Power BI.
Mode Direct Lake
Le mode Direct Lake est une nouvelle fonctionnalité de moteur révolutionnaire permettant d’analyser des jeux de données très volumineux dans Power BI. La technologie est basée sur l’idée de consommation de fichiers au format parquet directement depuis un lac de données, sans avoir à interroger un entrepôt ou un point de terminaison d’analytique SQL, ni à importer ou dupliquer des données dans un modèle sémantique Power BI. Cette intégration native offre un mode unique d’accès aux données à partir de l’entrepôt ou du point de terminaison d’analytique SQL, appelé Direct Lake. La vue d’ensemble de Direct Lake contient des informations supplémentaires sur ce mode de stockage pour les modèles sémantiques Power BI.
Direct Lake offre les expériences d’interrogation et de création de rapports les plus performantes. Direct Lake est un chemin d’accès rapide pour consommer les données, prêtes pour l’analyse, depuis le lac directement dans le moteur Power BI.
En mode DirectQuery traditionnel, le moteur Power BI interroge directement les données de la source pour chaque exécution de requête, et les performances des requêtes dépendent de la vitesse de récupération des données. DirectQuery élimine la nécessité de copier des données, garantissant ainsi que toutes les modifications apportées à la source sont immédiatement répercutées dans les résultats de la requête.
En mode Importation, les performances sont meilleures, car les données sont facilement disponibles en mémoire, sans avoir à interroger les données à partir de la source pour chaque exécution de requête. Toutefois, le moteur Power BI doit d’abord copier les données dans la mémoire, au moment de l’actualisation des données. Toutes les modifications apportées à la source de données sous-jacente sont récupérées lors de la prochaine actualisation des données.
Le mode Direct Lake élimine l’exigence d’importation de copier les données en consommant les fichiers de données directement en mémoire. Étant donné qu’il n’existe aucun processus d’importation explicite, il est possible de récupérer les modifications apportées à la source au fur et à mesure qu’elles se produisent. Direct Lake combine les avantages de DirectQuery et du mode Importation tout en évitant leurs inconvénients. Le mode Direct Lake est le choix approprié pour analyser des jeux de données très volumineux et des jeux de données avec des mises à jour fréquentes au niveau de la source de données. Direct Lake bascule automatiquement sur DirectQuery avec le point de terminaison d’analytique SQL de l’entrepôt ou le point de terminaison d’analytique SQL lorsque Direct Lake dépasse les limites de la SKU ou utilise des fonctionnalités non prises en charge, afin de permettre aux utilisateurs des rapports de continuer sans interruption.
Le mode Direct Lake est le mode de stockage pour les modèles sémantiques Power BI par défaut, ainsi que pour les nouveaux modèles sémantiques Power BI créés dans un point de terminaison d’entrepôt ou d’analytique SQL. Avec Power BI Desktop, vous pouvez également créer des modèles sémantiques Power BI à l’aide du point de terminaison d’analytique SQL de l’entrepôt ou du point de terminaison d’analytique SQL comme source de données pour les modèles sémantiques en mode d’importation ou de stockage DirectQuery.
Comprendre ce qui se trouve dans le modèle sémantique Power BI par défaut
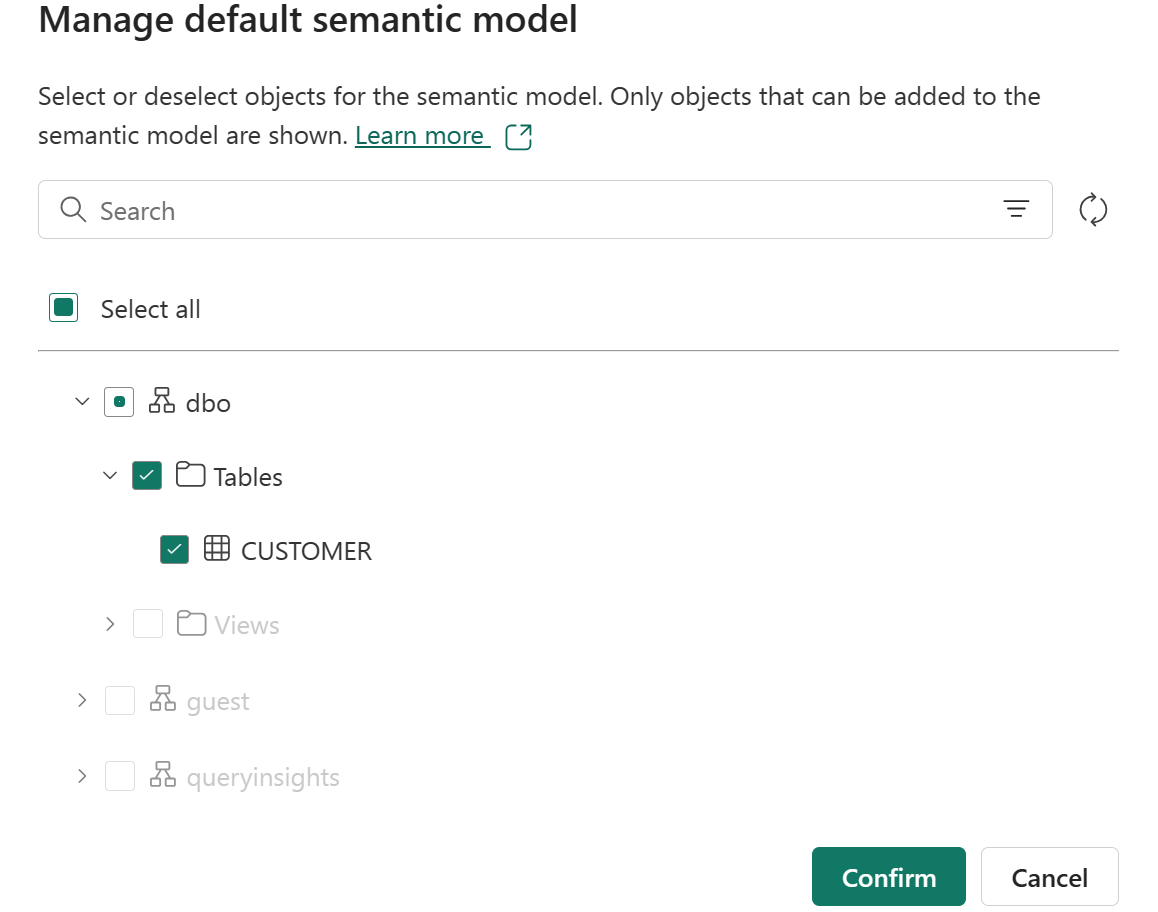
Lorsque vous créez un Entrepôt ou un point de terminaison d’analytique SQL, un modèle sémantique Power BI par défaut est créé. Le modèle sémantique par défaut est représenté avec le suffixe (par défaut). Vous pouvez utiliser Gérer le modèle sémantique par défaut pour choisir des tables à ajouter.
Synchronisation du modèle sémantique par défaut de Power BI
Auparavant, nous avons ajouté automatiquement l’ensemble des tables et des affichages de l’entrepôt au modèle sémantique Power BI par défaut. Sur la base des commentaires reçus, nous avons modifié le comportement par défaut pour ne pas ajouter automatiquement les tables et les affichages au modèle sémantique Power BI par défaut. Cette modification garantit que la synchronisation en arrière-plan n’est pas déclenchée. Cela désactive également certaines actions telles que « Nouvelle mesure », « Créer un rapport », « Analyser dans Excel ».
Si vous souhaitez changer ce comportement par défaut, vous pouvez :
Activer manuellement le paramètre Synchroniser de modèle sémantique Power BI par défaut pour chaque point de terminaison d’entrepôt ou d’analytique SQL dans l’espace de travail. Cela redémarre la synchronisation en arrière-plan qui entraîne des coûts de consommation.
Sélectionnez manuellement des tables et des affichages à ajouter au modèle sémantique par le biais de Gérer le modèle sémantique Power BI par défaut dans le ruban ou la barre d’info.


Remarque
Si vous n’utilisez pas le modèle sémantique Power BI par défaut à des fins de création de rapports, désactivez manuellement le paramètre Synchroniser le modèle sémantique Power BI par défaut pour éviter d’ajouter automatiquement des objets. La mise à jour du paramètre garantit que la synchronisation en arrière-plan n’est pas déclenchée et permet d’économiser des coûts de consommation Onelake.
Mettre à jour manuellement le modèle sémantique Power BI par défaut
Dès lors qu’il existe des objets dans le modèle sémantique Power BI par défaut, il est possible de valider ou d’inspecter visuellement les tables de deux façons :
Sélectionnez le bouton Mettre à jour manuellementle modèle sémantique dans le ruban.
Passez en revue la disposition par défaut pour les objets de modèle sémantique par défaut.
La disposition par défaut pour les tables compatibles BI persiste dans la session utilisateur et est générée chaque fois qu’un utilisateur accède à l’affichage du modèle. Recherchez l’onglet Objets de modèle sémantique par défaut.
Accéder au modèle sémantique Power BI par défaut
Pour accéder aux modèles sémantiques Power BI par défaut, accédez à votre espace de travail et recherchez le modèle sémantique qui correspond au nom du Lakehouse souhaité. Le modèle sémantique Power BI par défaut suit la convention d’affectation de noms du lakehouse.

Pour charger le modèle sémantique, sélectionnez le nom du modèle sémantique.
Surveiller le modèle sémantique Power BI par défaut
Vous pouvez surveiller et analyser l’activité sur le modèle sémantique avec SQL Server Profiler en vous connectant au point de terminaison XMLA.
SQL Server Profiler s’installe avec SQL Server Management Studio (SSMS) et permet le suivi et le débogage des événements de modèle sémantique. Bien qu’officiellement déprécié pour SQL Server, Profiler est toujours inclus dans SSMS et reste pris en charge pour Analysis Services et Power BI. L’utilisation avec le modèle sémantique Power BI de Fabric par défaut nécessite SQL Server Profiler version 18.9 ou ultérieure. Les utilisateurs doivent spécifier le modèle sémantique comme catalogue initial lors de la connexion avec le point de terminaison XMLA. Pour en savoir plus, consultez SQL Server Profiler pour Analysis Services.
Écriture du modèle sémantique par défaut de Power BI
Vous pouvez générer le script du modèle sémantique Power BI par défaut à partir du point de terminaison XMLA avec SQL Server Management Studio (SSMS).
Affichez le schéma TMSL (Tabular Model Scripting Language) du modèle sémantique en en générant le script via l’Explorateur d’objets dans SSMS. Pour vous connecter, utilisez la chaîne de connexion du modèle sémantique, qui ressemble à powerbi://api.powerbi.com/v1.0/myorg/username. Vous trouverez la chaîne de connexion de votre modèle sémantique dans les Paramètres, sous Paramètres du serveur. À partir de là, vous pouvez générer un script XMLA du modèle sémantique via l’action du menu contextuel Script de SSMS. Pour en savoir plus, consultez Connectivité des jeux de données avec le point de terminaison XMLA.
La création de scripts nécessite des autorisations d’écriture Power BI sur le modèle sémantique Power BI. Avec des autorisations de lecture, vous pouvez voir les données, mais pas le schéma du modèle sémantique Power BI.
Créer un nouveau modèle sémantique Power BI en mode de stockage Direct Lake
Vous pouvez également créer des modèles sémantiques Power BI supplémentaires en mode Direct Lake à l’aide de données d’entrepôt ou de point de terminaison d’analytique SQL. Ces nouveaux modèles sémantiques Power BI peuvent être modifiés dans l’espace de travail en sélectionnant Ouvrir le modèle de données, et peuvent être utilisés avec d’autres fonctionnalités telles que l’écriture de requêtes DAX et la sécurité au niveau des lignes du modèle sémantique.
Le bouton Nouveau modèle sémantique Power BI crée un modèle sémantique vide distinct du modèle sémantique par défaut.
Pour créer un modèle sémantique Power BI en mode Direct Lake, suivez ces étapes :
Ouvrez le lakehouse et sélectionnez Nouveau modèle sémantique Power BI dans le ruban.
Vous pouvez également ouvrir le point de terminaison d’analytique SQL d’un entrepôt ou lakehouse, en sélectionnant d’abord le ruban Rapports, puis Nouveau modèle sémantique Power BI.
Saisissez un nom pour le nouveau modèle sémantique, sélectionnez un espace de travail dans lequel l’enregistrer, puis sélectionnez les tables à inclure. Ensuite, sélectionnez Confirmer.
Le nouveau modèle sémantique Power BI peut être modifié dans l’espace de travail, où vous pouvez ajouter des relations et des mesures, renommer des tables et des colonnes, choisir la façon dont les valeurs sont affichées dans les visuels de rapport, et bien plus encore. Si la vue du modèle ne s’affiche pas après la création, vérifiez le bloqueur de fenêtres publicitaires de votre navigateur.
Pour modifier le modèle sémantique Power BI ultérieurement, sélectionnez Ouvrir le modèle de données à partir du menu contextuel du modèle sémantique ou de la page Détails de l’élément pour modifier le modèle sémantique.
Les rapports Power BI peuvent être créés dans l’espace de travail en sélectionnant Nouveau rapport à partir de la modélisation web, ou dans Power BI Desktop avec une connexion active à ce nouveau modèle sémantique.
Pour découvrir comment se connecter à des modèles sémantiques dans le service Power BI à partir de Power BI Desktop
Créer un nouveau modèle sémantique Power BI en mode d’importation ou de stockage DirectQuery
Avoir vos données dans Microsoft Fabric signifie que vous pouvez créer des modèles sémantiques Power BI en tout mode de stockage : Direct Lake, importation ou DirectQuery. Vous pouvez créer des modèles sémantiques Power BI supplémentaires en mode importation ou DirectQuery à l’aide de données d’entrepôt ou de point de terminaison d’analytique SQL.
Pour créer un modèle sémantique Power BI en mode importation ou DirectQuery, procédez comme suit :
Ouvrez Power BI Desktop, connectez-vous et sélectionnez OneLake.
Connectez-vous au point de terminaison d’analytique SQL du lakehouse ou de l’entrepôt.
Sélectionnez le bouton déroulant Se connecter, puis Se connecter au point de terminaison SQL.
Sélectionnez le mode de stockage importation ou DirectQuery, ainsi que les tables à ajouter au modèle sémantique.
À partir de là, vous pouvez créer le modèle sémantique Power BI et le rapport que vous souhaitez publier sur l’espace de travail lorsque vous êtes prêt.
Pour en savoir plus sur Power BI, consultez Power BI.
Limites
Les modèles sémantiques Power BI par défaut suivent les limitations actuelles des modèles sémantiques dans Power BI. En savoir plus :
- Limites des objets et ressources Azure Analysis Services
- Types de données dans Power BI Desktop : Power BI
Si les types de données parquet, Apache Spark ou SQL ne peuvent pas être mappés à l’un des types de données Power BI Desktop, ils sont abandonnés dans le cadre du processus de synchronisation. Cela est conforme au comportement actuel de Power BI. Pour ces colonnes, nous vous recommandons d’ajouter des conversions de type explicites dans leurs processus ETL afin de les convertir dans un type pris en charge. Si des types de données sont nécessaires en amont, les utilisateurs peuvent éventuellement spécifier une vue en SQL avec la conversion de type explicite souhaitée. Elle sera récupérée par la synchronisation ; il est également possible de l’ajouter manuellement comme indiqué précédemment.
- Les modèles sémantiques Power BI par défaut ne peuvent être modifiés que dans le point de terminaison ou l’entrepôt d’analytique SQL.