Configurer Data Warehouse dans une activité de copie
Cet article explique comment utiliser l’activité de copie dans le pipeline de données pour copier des données depuis et vers un connecteur Data Warehouse.
Configuration prise en charge
Pour la configuration de chaque onglet sous l’activité de copie, accédez respectivement aux sections suivantes.
Général
Pour la configuration de l’onglet Général, accédez à Général.
Source
Les propriétés suivantes sont prises en charge pour Data Warehouse en tant que source dans une activité de copie.
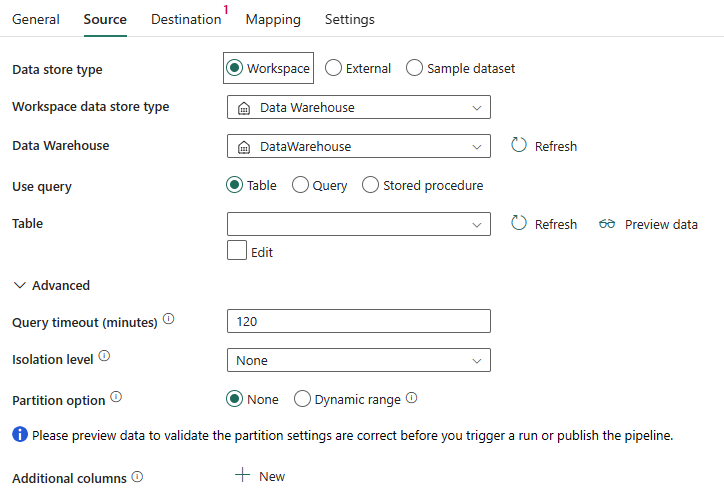
Les propriétés suivantes sont requises :
Type de magasin de données : sélectionnez Espace de travail.
Type de magasin de données de l’espace de travail : sélectionnez Data Warehouse dans la liste Type de magasin de données.
Data Warehouse : sélectionnez un connecteur Data Warehouse existant dans l’espace de travail.
Utiliser la requête : sélectionnez Table, Requête ou Procédure stockée.
Si vous sélectionnez Table, choisissez une table existante dans la liste de tables ou spécifiez manuellement un nom de table en sélectionnant la zone Modifier.

Si vous sélectionnez Requête, utilisez l’éditeur de requête SQL personnalisée pour écrire une requête SQL qui récupère les données sources.

Si vous sélectionnez Procédure stockée, choisissez une procédure stockée existante dans la liste déroulante ou spécifiez un nom de procédure stockée en tant que source en sélectionnant la zone Modifier.

Sous Avancé, vous pouvez spécifier les champs suivants :
Délai d’expiration de la requête (minutes) : délai d’expiration pour l’exécution de la commande de requête, avec une valeur par défaut de 120 minutes. Si cette propriété est définie, les valeurs autorisées sont au format d’un intervalle de temps, par exemple « 02:00:00 » (120 minutes).
Niveau d’isolation : spécifiez le comportement de verrouillage des transactions pour la source SQL.
Option de partition : spécifiez les options de partitionnement des données utilisées pour charger des données à partir de Data Warehouse. Vous pouvez sélectionner Aucun ou Plage dynamique.
Si vous sélectionnez Plage dynamique, le paramètre de partition par spécification de plages de valeurs (
?AdfDynamicRangePartitionCondition) est nécessaire lors de l’utilisation d’une requête avec le parallèle activé. Exemple de requête :SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition.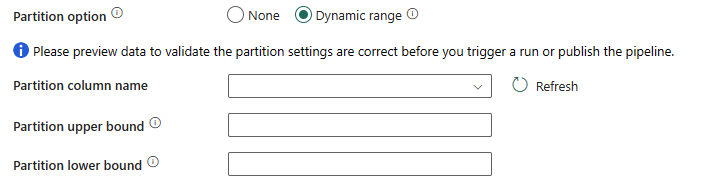
- Nom de la colonne de partition : indiquez le nom de la colonne source au format entier ou date/heure (
int,smallint,bigint,date,smalldatetime,datetime,datetime2oudatetimeoffset) qui est utilisée par le partitionnement par plages de valeurs pour la copie parallèle. S’il n’est pas spécifié, l’index ou la clé primaire de la table est détecté automatiquement et utilisé comme colonne de partition. - Limite supérieure de la partition : valeur maximale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête sont partitionnées et copiées.
- Limite inférieure de la partition : valeur minimale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête sont partitionnées et copiées.
- Nom de la colonne de partition : indiquez le nom de la colonne source au format entier ou date/heure (
Colonnes supplémentaires : ajoutez des colonnes de données supplémentaires au chemin d’accès relatif ou à la valeur statique des fichiers sources du magasin. L’expression est prise en charge pour ce dernier.


Destination
Les propriétés suivantes sont prises en charge pour Data Warehouse en tant que destination dans une activité de copie.
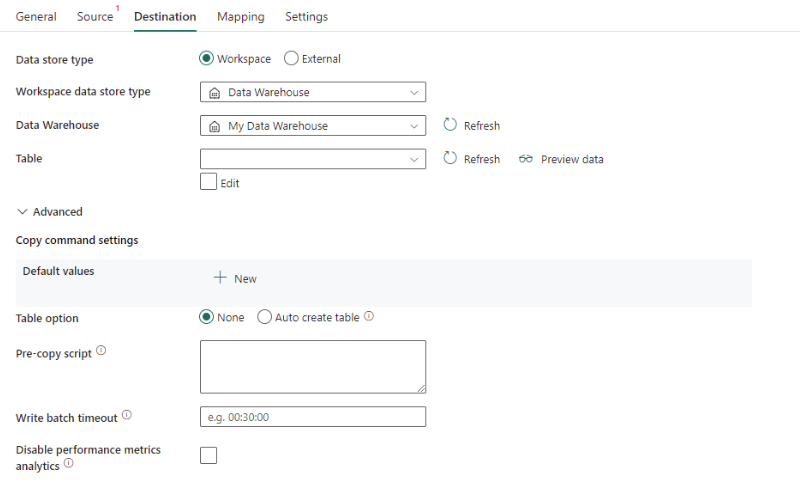
Les propriétés suivantes sont requises :
- Type de magasin de données : sélectionnez Espace de travail.
- Type de magasin de données de l’espace de travail : sélectionnez Data Warehouse dans la liste Type de magasin de données.
- Data Warehouse : sélectionnez un connecteur Data Warehouse existant dans l’espace de travail.
- Table : choisissez une table existante dans la liste de tables ou spécifiez un nom de table comme destination.
Sous Avancé, vous pouvez spécifier les champs suivants :
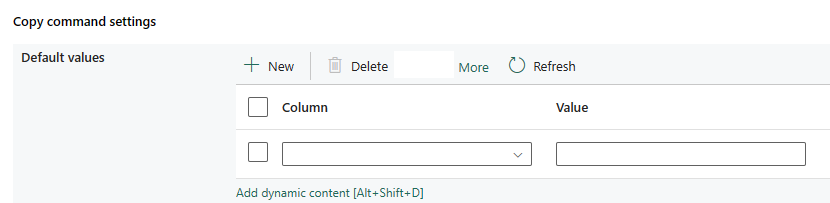
Paramètres de la commande de copie : spécifiez les propriétés de la commande de copie.
Options de table : indiquez s’il faut créer automatiquement la table de destination s’il n’en existe aucune en fonction du schéma source. Vous pouvez sélectionner Aucun ou Créer automatiquement une table.
Script de pré-copie : spécifiez une requête SQL à exécuter avant l’écriture de données dans Data Warehouse à chaque exécution. Utilisez cette propriété pour nettoyer les données préchargées.
Délai d’expiration du lot d’écriture : temps d’attente pour que l’opération d’insertion par lot soit terminée avant d’expirer. Les valeurs autorisées sont au format d’un intervalle de temps. La valeur par défaut est « 00:30:00 » (30 minutes).
Désactiver l’analytique des métriques de performances : le service collecte des métriques pour fournir des recommandations et optimiser les performances de copie. Si ce comportement vous intéresse, désactivez cette fonctionnalité.
Copie directe
L'instruction COPY est le principal moyen d'ingérer des données dans les tables Warehouse. La commande COPY de Data Warehouse prend directement en charge Stockage Blob Azure et Azure Data Lake Storage Gen2 en tant que magasins de données sources. Si vos données sources répondent aux critères décrits dans cette section, utilisez la commande COPY pour copier directement à partir du magasin de données source vers Data Warehouse.
Les données sources et le format contiennent les types et méthodes d’authentification suivants :
Type de magasin de données sources pris en charge Format pris en charge Type d’authentification source pris en charge Stockage Blob Azure Texte délimité
ParquetAuthentification anonyme
Authentification par clé de compte
Authentification avec une signature d’accès partagéAzure Data Lake Storage Gen2 Texte délimité
ParquetAuthentification par clé de compte
Authentification avec une signature d’accès partagéLes paramètres de format suivants peuvent être définis :
- Pour Parquet : le type de compression peut être Aucun, snappy ou gzip.
- Pour DelimitedText :
- Séparateur de lignes : lors de la copie de texte délimité dans Data Warehouse via la commande COPY directe, spécifiez explicitement le séparateur de lignes (\r, \n ou \r\n). La valeur par défaut (\r, \n ou \r\n) ne fonctionne que si le séparateur de lignes du fichier source est \r\n. Sinon, activez la mise en lots pour votre scénario.
- La valeur null conserve sa valeur par défaut ou est définie sur chaîne vide ("").
- L’encodage conserve sa valeur par défaut ou est défini sur UTF-8 ou UTF-16.
- Le nombre de lignes à ignorer conserve sa valeur par défaut ou est défini sur 0.
- Le type de compression peut être Aucun ou gzip.
Si votre source est un dossier, vous devez activer la case à cocher Récursivement.
L’heure de début (UTC) et l’heure de fin (UTC) dans Filtrer par date de dernière modification, Préfixe, Activer la découverte de partition et Colonnes supplémentaires ne sont pas spécifiées.
Pour savoir comment ingérer des données dans Data Warehouse à l’aide de la commande COPY, consultez cet article.
Si votre magasin de données source et son format ne sont pas pris en charge à l’origine par la commande COPY, utilisez plutôt la fonctionnalité Copie intermédiaire à l’aide de la commande COPY. Elle convertit automatiquement les données dans un format compatible avec la commande COPY, puis appelle une commande COPY pour charger les données dans Data Warehouse.
copie intermédiaire
Lorsque vos données sources ne sont pas compatibles en mode natif avec la commande COPY, activez la copie des données via un stockage intermédiaire temporaire. Dans ce cas, le service convertit automatiquement les données pour répondre aux exigences de format de données de la commande COPY. Il appelle ensuite la commande COPY pour charger les données dans Data Warehouse. Enfin, il nettoie vos données temporaires du stockage.
Pour utiliser la copie intermédiaire, accédez à l’onglet Paramètres et sélectionnez Activer le mode de préproduction. Vous pouvez choisir Espace de travail pour utiliser le stockage intermédiaire créé automatiquement dans Fabric. Pour Externe, Stockage Blob Azure et Azure Data Lake Stockage Gen2 sont pris en charge comme stockage intermédiaire externe. Pour utiliser le stockage intermédiaire, vous devez d’abord créer une connexion Stockage Blob Azure ou Azure Data Lake Stockage Gen2, puis sélectionner la connexion dans la liste déroulante.
Remarque : vous devez vous assurer que la plage d’adresses IP du data warehouse a été autorisée correctement à partir du stockage intermédiaire.
Mappage
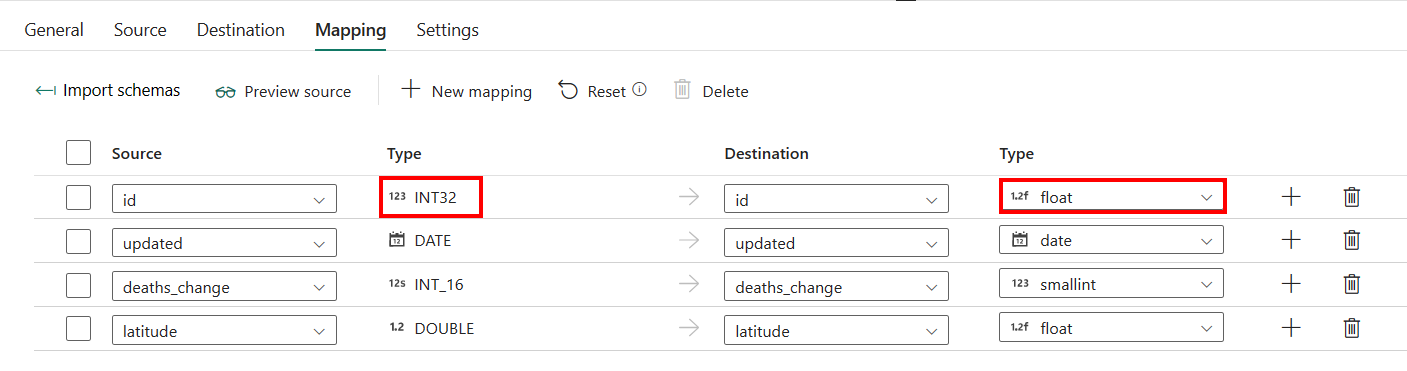
Pour la configuration de la Tabulation Mappage, si vous n'appliquez pas Data Warehouse avec une table de création automatique comme destination, allez sur Mappage.
Si vous appliquez Data Warehouse avec une table de création automatique comme destination, à l'exception de la configuration dans Mappage, vous pouvez modifier le type de vos colonnes de destination. Après avoir sélectionné Importer des schémas, vous pouvez spécifier le type de colonne dans votre destination.
Par exemple, le type de la colonne ID dans la source est int. Vous pouvez le changer par le type float lors du mappage vers la colonne de destination.
Paramètres
Pour la configuration de l’onglet Paramètres, accédez à Paramètres.
Résumé de la table
Les tableaux suivants contiennent plus d’informations sur une activité de copie dans Data Warehouse.
Informations sur la source
| Nom | Description | Valeur | Obligatoire | Propriété de script JSON |
|---|---|---|---|---|
| Type de banque de données | Votre type de magasin de données. | Espace de travail | Oui | / |
| Type de magasin de données de l’espace de travail | Section permettant de sélectionner le type de magasin de données de votre espace de travail. | Data Warehouse | Oui | type |
| Data Warehouse | Entrepôt de données à utiliser. | <votre entrepôt de données> | Oui | endpoint artifactId |
| Utiliser la requête | Mode de lecture des données à partir de Data Warehouse. | • Tables • Requête • Procédure stockée |
Non | (sous typeProperties ->source)• typeProperties : schéma table • sqlReaderQuery • sqlReaderStoredProcedureName |
| Délai d’expiration de la requête (minutes) | Délai d’expiration pour l’exécution de la commande de requête, avec une valeur par défaut de 120 minutes. Si cette propriété est définie, les valeurs autorisées sont au format d’un intervalle de temps, par exemple « 02:00:00 » (120 minutes). | intervalle de temps | Non | queryTimeout |
| Niveau d’isolation | Comportement de verrouillage des transactions pour la source SQL. | • Aucun • Instantané |
Non | isolationLevel |
| Option de partition | Options de partitionnement des données utilisées pour charger des données à partir de Data Warehouse. | • Aucun • Plage dynamique |
Non | partitionOption |
| Nom de la colonne de partition | Nom de la colonne source au format entier ou date/DateHeure (int, smallint, bigint, date, smalldatetime, datetime, datetime2 ou datetimeoffset) utilisée par le partitionnement par plages de valeurs pour la copie en parallèle. S’il n’est pas spécifié, l’index ou la clé primaire de la table est détecté automatiquement et utilisé comme colonne de partition. |
<nom de la colonne de partition> | Non | partitionColumnName |
| Limite supérieure de partition | Valeur maximale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête sont partitionnées et copiées. | <limite supérieure de partition> | Non | partitionUpperBound |
| Limite inférieure de partition | Valeur minimale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête sont partitionnées et copiées. | <limite inférieure de partition> | Non | partitionLowerBound |
| Colonnes supplémentaires | Ajouter les colonnes de données supplémentaires pour stocker le chemin d’accès relatif ou la valeur statique des fichiers sources. | • Nom • Valeur |
Non | additionalColumns : • nom • valeur |
Informations de destination
| Nom | Description | Valeur | Obligatoire | Propriété de script JSON |
|---|---|---|---|---|
| Type de banque de données | Votre type de magasin de données. | Espace de travail | Oui | / |
| Type de magasin de données de l’espace de travail | Section permettant de sélectionner le type de magasin de données de votre espace de travail. | Data Warehouse | Oui | type |
| Data Warehouse | Entrepôt de données à utiliser. | <votre entrepôt de données> | Oui | endpoint artifactId |
| Table | Table de destination pour l’écriture des données. | <nom de votre table de destination> | Oui | schéma table |
| Paramètres de la commande de copie | Paramètres de propriété de la commande de copie. Contient les paramètres par défaut. | Valeur par défaut : • Colonne • Valeur |
Non | copyCommandSettings : defaultValues : • columnName • defaultValue |
| Option de table | Créer automatiquement la table de destination s’il n’en existe aucune en fonction du schéma source. | • Aucun • Auto créer la table |
Non | tableOption : • autoCreate |
| Script de pré-copie | Requête SQL à exécuter avant l’écriture de données dans Data Warehouse à chaque exécution. Utilisez cette propriété pour nettoyer les données préchargées. | <script de pré-copie> | Non | preCopyScript |
| Délai d’expiration du lot d’écriture | Temps d’attente pour que l’opération d’insertion par lot soit terminée avant d’expirer. Les valeurs autorisées sont au format d’un intervalle de temps. La valeur par défaut est « 00:30:00 » (30 minutes). | intervalle de temps | Non | writeBatchTimeout |
| Désactiver l’analytique des métriques de performances | Le service collecte des métriques pour fournir des recommandations et optimiser les performances de copie, introduisant un accès de base de données master supplémentaire. | sélectionner ou désélectionner | Non | disableMetricsCollection : True ou False |