Guide pratique pour copier des données à l'aide de l'activité Copy
Dans le pipeline de données, vous pouvez utiliser l’activité Copy pour copier des données entre des banques de données dans le cloud.
Une fois que vous avez copié les données, vous pouvez utiliser d’autres activités pour les transformer et les analyser ultérieurement. Vous pouvez également utiliser l’activité de copie pour publier les résultats de transformation et d’analyse pour l’aide à la décision (BI) et l’utilisation d’application.
Pour copier des données d’une source vers une destination, le service qui exécute l’activité Copy effectue les étapes suivantes :
- Lit les données d’une banque de données source.
- Effectue les opérations de sérialisation/désérialisation, de compression/décompression, de mappage de colonnes, et ainsi de suite. Il effectue ces opérations en fonction de la configuration.
- Écrit les données dans le magasin de données de destination.
Prérequis
Pour commencer, vous devez remplir les conditions préalables suivantes :
Un compte de locataire Microsoft Fabric avec un abonnement actif. Créez un compte gratuitement.
Vérifiez que vous disposez d’un espace de travail avec Microsoft Fabric activé.
Ajouter une activité Copy à l’aide de l’assistant de copie
Procédez comme suit pour configurer votre activité Copy à l’aide de assistant de copie.
Démarrer avec l’assistant de copie
Ouvrez un pipeline de données existant ou créez un pipeline de données.
Sélectionnez Copier les données sur le canevas pour ouvrir l’outil Assistant de copie pour commencer. Vous pouvez également sélectionner Utiliser l’assistant de copie dans la liste déroulante Copier les données sous l’onglet Activités du ruban.


Configurer votre source
Sélectionnez un type de source de données dans la catégorie. Vous allez utiliser Stockage Blob Azure comme exemple. Sélectionnez Stockage Blob Azure, puis Suivant.

Créez une connexion à votre source de données en sélectionnant Créer une connexion.

Après avoir sélectionné Créer une connexion, renseignez les informations de connexion requises, puis sélectionnez Suivant. Pour plus d’informations sur la création de connexion pour chaque type de source de données, vous pouvez vous reporter à chaque article sur les connecteurs.
Si vous avez des connexions existantes, vous pouvez sélectionner Connexion existante et sélectionner votre connexion dans la liste déroulante.

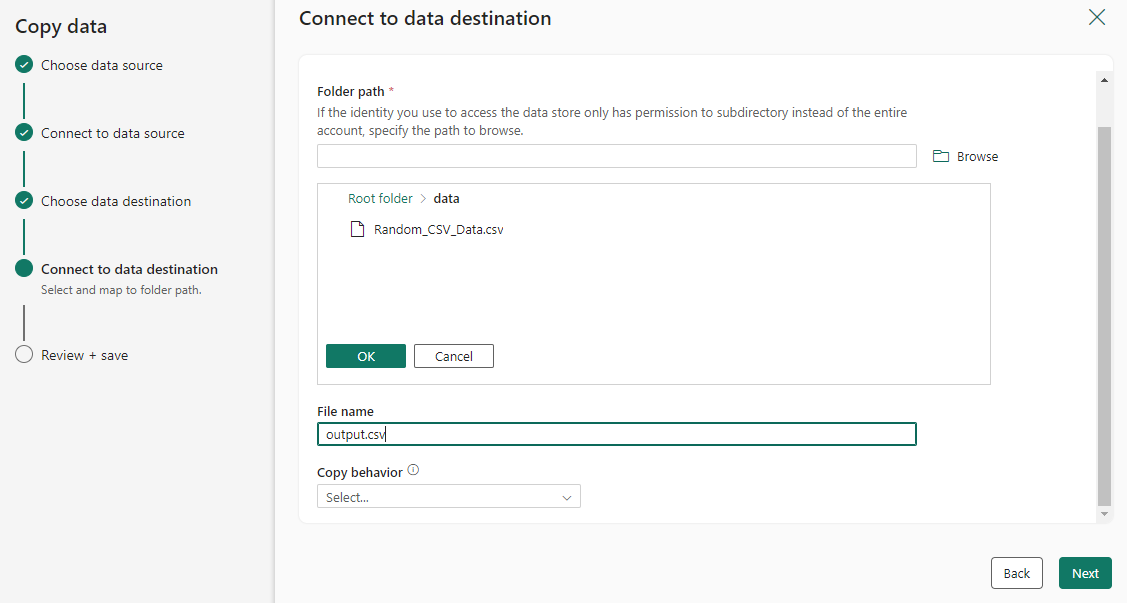
Choisissez le fichier ou le dossier à copier dans cette étape de configuration de la source, puis sélectionnez Suivant.





Configurer votre destination
Sélectionnez un type de source de données dans la catégorie. Vous allez utiliser Stockage Blob Azure comme exemple. Vous pouvez créer une connexion liée à un nouveau compte Stockage Blob Azure en suivant les étapes de la section précédente ou utiliser une connexion existante dans la liste déroulante des connexions. Les fonctionnalités Tester la connexion et Modifier sont disponibles pour chaque connexion sélectionnée.

Configurez et mappez vos données sources à votre destination. Sélectionnez ensuite Suivant pour terminer vos configurations de destination.

Remarque
Vous ne pouvez utiliser qu’une seule passerelle de données locale au sein de la même activité Copy. Si la source et le récepteur sont des sources de données locales, ils doivent utiliser la même passerelle. Pour déplacer des données entre des sources de données locales avec différentes passerelles, vous devez copier à l’aide de la première passerelle vers une source cloud intermédiaire dans un activité Copy. Vous pouvez ensuite utiliser une autre activité Copy pour la copier à partir de la source cloud intermédiaire à l’aide de la deuxième passerelle.



Examiner et créer votre activité Copy
Passez en revue vos paramètres d’activité Copy dans les étapes précédentes, puis sélectionnez OK pour terminer. Vous pouvez également revenir aux étapes précédentes pour modifier vos paramètres si nécessaire dans l’outil.


Une fois terminée, l’activité Copy est ajoutée à votre canevas de pipeline de données. Tous les paramètres, y compris les paramètres avancés de cette activité Copy, sont disponibles sous les onglets lorsqu’ils sont sélectionnés.

Vous pouvez maintenant enregistrer votre pipeline de données avec cette seule activité de copie ou continuer à concevoir votre pipeline de données.
Ajouter une activité Copy directement
Suivez ces étapes pour ajouter directement une activité Copy.
Ajouter une activité Copy
Ouvrez un pipeline de données existant ou créez un pipeline de données.
Ajoutez une activité de copie en sélectionnant Ajouter une activité de pipeline>Activité Copy ou en sélectionnant Copier les données>Ajouter dans le canevas sous l’onglet Activités.


Configurer vos paramètres généraux sous l’onglet Général
Pour savoir comment configurer vos paramètres généraux, consultez Général.
Configurer votre source sous l’onglet Source
Sélectionnez + Nouveau en regard de Connexion pour créer une connexion à votre source de données.

Choisissez le type de source de données dans la fenêtre contextuelle. Vous allez utiliser Azure SQL Database comme exemple. Sélectionnez Azure SQL Database, puis Continuer.

Il accède à la page de création de connexion. Remplissez les informations de connexion requises dans le panneau, puis sélectionner Créer. Pour plus d’informations sur la création de connexion pour chaque type de source de données, vous pouvez vous reporter à chaque article sur les connecteurs.

Une fois votre connexion créée, vous êtes redirigé vers la page du pipeline de données. Sélectionnez ensuite Actualiser pour récupérer la connexion que vous avez créée dans la liste déroulante. Vous pouvez également choisir une connexion Azure SQL Database existante directement dans la liste déroulante si vous l’avez déjà créée auparavant. Les fonctionnalités Tester la connexion et Modifier sont disponibles pour chaque connexion sélectionnée. Sélectionnez ensuite Azure SQL Database dans type de Connexion.

Spécifiez une table à copier. Sélectionnez Aperçu des données pour afficher un aperçu de votre table source. Vous pouvez également utiliser Requête et Procédure stockée pour lire des données à partir de votre source.

Développez Avancé pour les paramètres plus avancés.







Configurer votre destination sous l’onglet Destination
Choisissez votre type de destination. Il peut s’agir de votre magasin de données interne de première classe à partir de votre espace de travail, tel qu’un lakehouse, ou de vos magasins de données externes. Vous allez utiliser Lakehouse comme exemple.

Choisissez d’utiliser Lakehouse dans Type de magasin de données de l’espace de travail. Sélectionnez + Nouveau, et vous accédez à la page de création de lakehouse. Spécifiez le nom de votre lakehouse, puis sélectionnez Créer.

Une fois votre connexion créée, vous êtes redirigé vers la page du pipeline de données. Sélectionnez ensuite Actualiser pour récupérer la connexion que vous avez créée dans la liste déroulante. Vous pouvez également choisir une connexion Lakehouse existante dans la liste déroulante directement si vous l’avez déjà créée auparavant.

Spécifiez une table ou configurez le chemin du fichier pour définir le fichier ou le dossier comme destination. Ici, sélectionnez Tables et spécifiez une table pour écrire des données.

Développez Avancé pour accéder aux paramètres plus avancés.






Vous pouvez maintenant enregistrer votre pipeline de données avec cette seule activité Copy ou continuer à concevoir votre pipeline de données.
Configurer vos mappages sous l’onglet Mappage
Si le connecteur que vous appliquez prend en charge le mappage, vous pouvez accéder à l’onglet Mappage pour configurer votre mappage.
Sélectionnez Importer des schémas pour importer votre schéma de données.

Vous pouvez voir que le mappage automatique s’affiche. Spécifiez votre colonne Source et votre colonne Destination. Si vous créez une table dans la destination, vous pouvez personnaliser le nom de votre colonne Destination ici. Si vous souhaitez écrire des données dans la table de destination existante, vous ne pouvez pas modifier le nom de la colonne Destination existante. Vous pouvez également afficher le type de colonnes source et de destination.



En outre, vous pouvez sélectionner + Nouveau mappage pour ajouter un nouveau mappage, Effacer pour effacer tous les paramètres de mappage, puis Réinitialiser pour réinitialiser la colonne Source de l’ensemble du mappage.
Configurer vos autres paramètres sous l’onglet Paramètres
L’onglet Paramètres contient les paramètres de performances, de mise en lots, etc.

Reportez-vous au tableau suivant pour une description de chaque paramètre.
| Paramètre | Description | Propriété de script JSON |
|---|---|---|
| Optimisation intelligente du débit | Spécifiez pour optimiser le débit. Vous pouvez choisir : • Auto • Standard • Équilibrée • Maximum Lorsque vous choisissez Auto, le paramètre optimal est appliqué dynamiquement en fonction de votre paire source-destination et de votre modèle de données. Vous pouvez également personnaliser votre débit. La valeur personnalisée peut être comprise entre 2 et 256, tandis qu’une valeur plus élevée implique plus de gains. |
dataIntegrationUnits |
| Degré de parallélisme de copie | Spécifiez le degré de parallélisme utilisé par le chargement des données. | parallelCopies |
| Tolérance de panne | Lorsque vous sélectionnez cette option, vous pouvez ignorer certaines erreurs qui se sont produites au milieu du processus de copie. Par exemple, les lignes incompatibles entre le magasin source et le magasin de destination, le fichier en cours de suppression pendant le déplacement des données, etc. | • enableSkipIncompatibleRow • skipErrorFile: fileMissing fileForbidden invalidFileName |
| Activation de la journalisation | Lorsque vous sélectionnez cette option, vous pouvez consigner les fichiers copiés, ainsi que les fichiers et les lignes ignorés. | / |
| Activer le mode de préproduction | Indiquez si vous souhaitez copier les données via un magasin de données intermédiaire. Activez la mise en lots uniquement pour les scénarios avantageux. | enableStaging |
| Type de banque de données | Lorsque vous activez la gestion intermédiaire, vous pouvez choisir Espace de travail et Externe comme type de magasin de données. | / |
| Pour Espace de travail | ||
| Espace de travail | Spécifiez l’utilisation d’un stockage intermédiaire intégré. | / |
| Pour Externe | ||
| Connexion du compte de mise en lots | Spécifiez la connexion d’une instance Stockage Blob Azure ou Azure Data Lake Storage Gen2 faisant référence à l’instance de stockage que vous utilisez comme magasin de données intermédiaire. Créez une connexion intermédiaire si vous n’en avez pas. | connexion (sous externalReferences) |
| Chemin de stockage | Spécifiez le chemin dans lequel vous souhaitez placer les données intermédiaires. Si vous ne renseignez pas le chemin d’accès, le service crée un conteneur pour stocker les données temporaires. Ne spécifiez un chemin d’accès que si vous utilisez le stockage avec une signature d’accès partagé, ou si vous avez besoin de données temporaires dans un emplacement spécifique. | path |
| Activer la compression | Spécifie si les données doivent être compressées avant d’être copiées vers la destination. Ce paramètre réduit le volume de données transférées. | enableCompression |
| Preserve | Spécifiez s’il faut conserver les métadonnées/ACL lors de la copie des données. | conserves |
Remarque
Si vous utilisez une copie intermédiaire avec la compression activée, l’authentification du principal de service pour la connexion de blob intermédiaire n’est pas prise en charge.
Configurer les paramètres dans une activité de copie
Les paramètres peuvent être utilisés pour contrôler le comportement d’un pipeline et de ses activités. Vous pouvez utiliser Ajouter du contenu dynamique pour spécifier des paramètres pour vos propriétés d’activité de copie. Prenons la spécification de Lakehouse/Data Warehouse/Base de données KQL comme exemple pour voir comment l’utiliser.
Dans votre source ou destination, après avoir sélectionné Espace de travail en tant que type de magasin de données et spécifié Lakehouse/Data Warehouse/Base de données KQL en tant que type de magasin de données d’espace de travail, sélectionnez Ajouter du contenu dynamique dans la liste déroulante Lakehouse, Data Warehouse ou Base de données KQL.
Dans le volet contextuel Ajouter du contenu dynamique, sous l’onglet Paramètres, sélectionnez +.
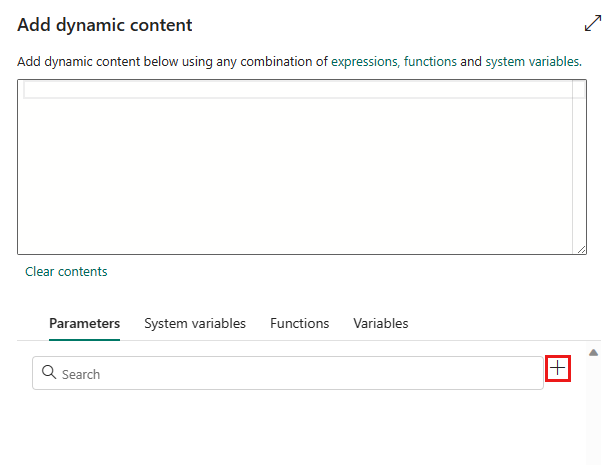
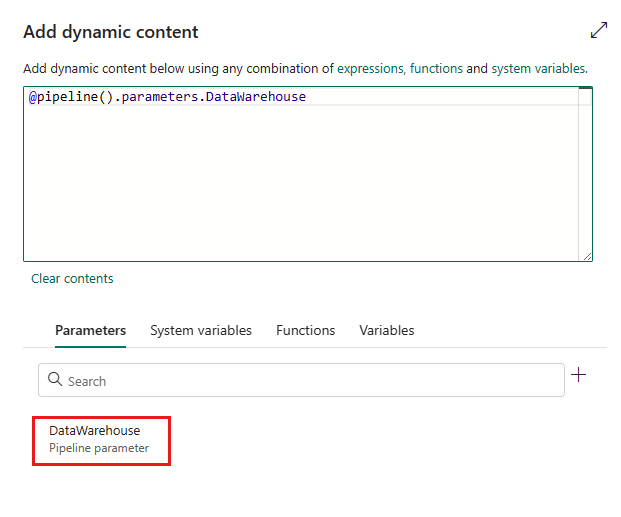
Spécifiez le nom de votre paramètre et attribuez-lui une valeur par défaut si vous le souhaitez, ou vous pouvez spécifier la valeur du paramètre après avoir sélectionné Exécuter dans le pipeline.

Notez que la valeur du paramètre doit être l’ID d’objet Lakehouse/Data Warehouse/Base de données KQL. Pour obtenir votre ID d’objet Lakehouse/Data Warehouse/Base de données KQL, ouvrez votre Lakehouse/Data Warehouse/Base de données KQL dans votre espace de travail, et l’ID est indiqué après
/lakehouses/,/datawarehouses/ou/databases/dans votre URL.ID d’objet Lakehouse :

ID d’objet Data Warehouse :

ID d’objet de base de données KQL :

Sélectionnez Enregistrer pour revenir au volet Ajouter du contenu dynamique. Sélectionnez ensuite votre paramètre pour qu’il apparaisse dans la zone Expression. Sélectionnez ensuite OK. Vous revenez à la page de pipeline et vous pouvez voir que l’expression de paramètre est spécifiée après ID d’objet Lakehouse/ID d’objet Data Warehouse/ID d’objet de base de données KQL.