Configurer Azure Database pour PostgreSQL dans une activité de copie
Cet article explique comment utiliser l’activité de copie dans le pipeline de données pour copier des données depuis et vers Azure Database pour PostgreSQL.
Configuration prise en charge
Pour la configuration de chaque onglet sous activité de copie, accédez respectivement aux sections suivantes.
Généralités
Reportez-vous aux directives concernant les paramètres généraux pour configurer l'onglet Paramètres généraux .
Source
Accédez à l'onglet Source pour configurer votre source d'activité de copie. Consultez le contenu suivant pour obtenir la configuration détaillée.
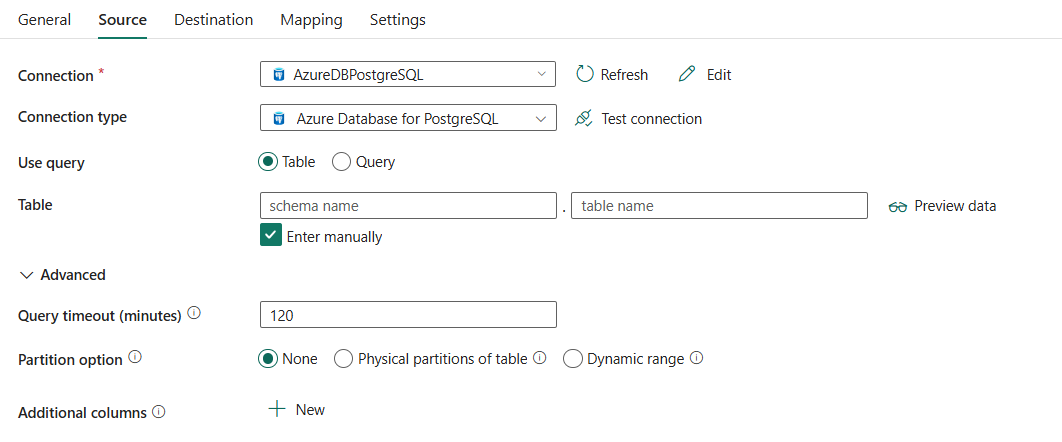
Les trois propriétés suivantes sont requises :
- Connexion: sélectionnez une connexion Azure Database pour PostgreSQL dans la liste des connexions. Si aucune connexion n’existe, créez une connexion Azure Database pour PostgreSQL.
- type de connexion: sélectionnez Azure Database pour PostgreSQL .
- Utilisez la requête: Sélectionnez Table pour lire des données à partir de la Table spécifiée ou sélectionnez Requête pour lire des données à l'aide de requêtes.
Si vous sélectionnez Table:
Table : sélectionnez la table dans la liste déroulante ou sélectionnez Entrer manuellement pour l’entrer manuellement afin de lire les données.
Une capture d’écran

Si vous sélectionnez Requête :
requête: spécifiez la requête SQL personnalisée pour lire les données. Par exemple :
SELECT * FROM mytableouSELECT * FROM "MyTable".Remarque
Dans PostgreSQL, le nom de l’entité est traité comme insensible à la casse s’il n’est pas placé entre guillemets.
capture d’écran

Sous avancé, vous pouvez spécifier les champs suivants :
délai d’expiration de la requête (minutes): spécifiez l’heure d’attente avant de terminer la tentative d’exécution d’une commande et de générer une erreur, la valeur par défaut est de 120 minutes. Si le paramètre est défini pour cette propriété, les valeurs autorisées sont un intervalle de temps, par exemple « 02:00:00 » (120 minutes). Pour plus d’informations, consultez CommandTimeout.
Option de partitionnement: Indique les options de partitionnement des données utilisées pour le chargement des données à partir d'Azure Database pour PostgreSQL. Lorsqu’une option de partition est activée (autrement dit, pas Aucun), le degré de parallélisme pour charger simultanément des données à partir d’une base de données Azure Database pour PostgreSQL est contrôlé par le Degré de parallélisme de copie dans l’onglet Paramètres de l’activité de copie.
Si vous sélectionnez Aucun, vous choisissez de ne pas utiliser la partition.
Si vous sélectionnez Partitions physiques de la table :
noms de partition: spécifiez la liste des partitions physiques à copier.
Si vous utilisez une requête pour récupérer les données sources, incluez
?AdfTabularPartitionNamedans la clause WHERE. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la Base de données pour PostgreSQL.
Si vous sélectionnez plage dynamique:
nom de colonne de partition: spécifiez le nom de la colonne source en entier ou type date/datetime (
int,smallint,bigint,date,timestamp without time zone,timestamp with time zoneoutime without time zone) qui sera utilisé par le partitionnement de plage pour la copie parallèle. Si elle n’est pas spécifiée, la clé primaire de la table est détectée automatiquement et utilisée comme colonne de partition.Si vous utilisez une requête pour récupérer les données sources, intégrez
?AdfRangePartitionColumnNamedans la clause WHERE. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la Base de données pour PostgreSQL.Limite supérieure de partition: spécifiez la valeur maximale de la colonne de partition pour extraire les données.
Si vous utilisez une requête pour récupérer les données sources, insérez
?AdfRangePartitionUpbounddans la clause WHERE. Pour un exemple, consultez la section Copie parallèle depuis Azure Database pour PostgreSQL. .limite inférieure de partition: spécifiez la valeur minimale de la colonne de partition pour copier les données.
Si vous utilisez une requête pour récupérer les données sources, insérez
?AdfRangePartitionLowbounddans la clause WHERE. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la Base de données pour PostgreSQL.
Colonnes supplémentaires: Ajoutez des colonnes de données supplémentaires pour stocker le chemin d’accès relatif ou une valeur fixe des fichiers sources. L'expression est prise en charge pour ce dernier.
Destination
Accédez à l’onglet Destination pour configurer la destination de votre activité de copie. Consultez le contenu suivant pour obtenir la configuration détaillée.
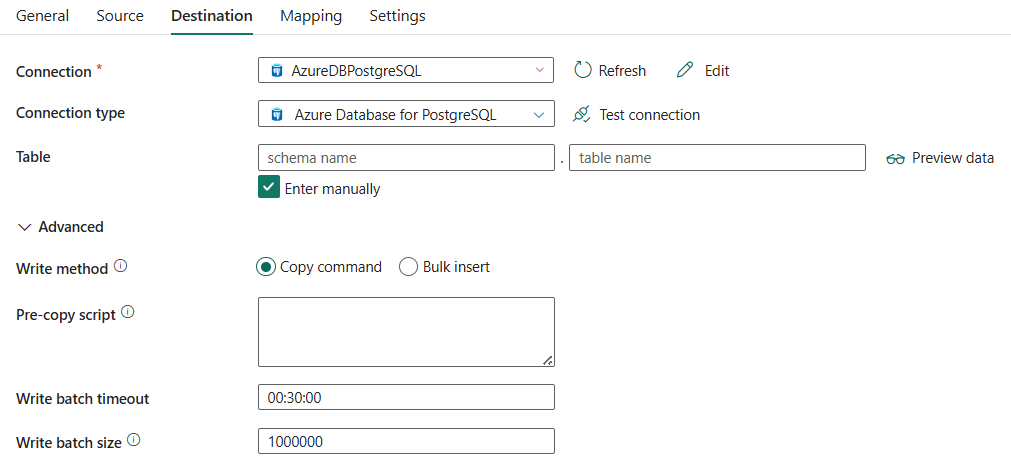
Les trois propriétés suivantes sont requises :
- Connexion: Sélectionnez une connexion Azure Database pour PostgreSQL dans la liste des connexions. Si aucune connexion n’existe, créez une connexion Azure Database pour PostgreSQL.
- type de connexion: sélectionnez Azure Database pour PostgreSQL .
- Table : sélectionnez la table dans la liste déroulante ou sélectionnez Entrer manuellement pour l’entrer manuellement afin d’écrire des données.
Sous avancé, vous pouvez spécifier les champs suivants :
méthode Write: sélectionnez la méthode utilisée pour écrire des données dans Azure Database pour PostgreSQL. Choisissez entre Copy command (valeur par défaut et la plus performante) et Bulk insert.
script de pré-copie: spécifiez une requête SQL pour l’activité de copie à exécuter avant d’écrire des données dans Azure Database pour PostgreSQL dans chaque exécution. Vous pouvez utiliser cette propriété pour nettoyer les données préchargées.
Délai d'attente du lot d'écriture : Temps d’attente pour que l’opération d’insertion par lot soit terminée avant d’expirer. La valeur autorisée est timespan. La valeur par défaut est 00:30:00 (30 minutes).
Taille de lot d’écriture : spécifiez le nombre de lignes chargées dans Azure Database pour PostgreSQL par lot. La valeur autorisée est un entier qui représente le nombre de lignes. La valeur par défaut est 1 000 000.
Cartographie
Pour la configuration de l’onglet Mappage, consultez Configurer vos mappages sous l’onglet Mappage.
Paramètres
Pour la configuration de l’onglet Paramètres, accédez à Configurer vos autres paramètres sous l’onglet Paramètres.
Copie parallèle à partir d’Azure Database pour PostgreSQL
Le connecteur Azure Database pour PostgreSQL dans l’activité de copie fournit un partitionnement de données intégré pour copier des données en parallèle. Vous trouverez les options de partitionnement des données sous l’onglet Source de l’activité de copie.
Lorsque vous activez la copie partitionnée, l’activité de copie exécute des requêtes parallèles sur votre source Azure Database pour PostgreSQL pour charger des données par partitions. Le degré parallèle est contrôlé par le Degré de parallélisme de copie dans l’onglet Paramètres de l’activité de copie. Par exemple, si vous définissez degré de parallélisme de copie sur quatre, le service génère et exécute simultanément quatre requêtes en fonction de votre option et paramètres de partition spécifiés, et chaque requête récupère une partie des données de votre instance Azure Database pour PostgreSQL.
Vous êtes suggéré d’activer la copie parallèle avec le partitionnement des données, en particulier lorsque vous chargez une grande quantité de données à partir de votre base de données Azure pour PostgreSQL. Voici les configurations suggérées pour différents scénarios. Lors de la copie de données dans un magasin de données basé sur des fichiers, il est recommandé d’écrire dans un dossier sous la forme de plusieurs fichiers (spécifier uniquement le nom du dossier), auquel cas les performances sont meilleures que l’écriture dans un seul fichier.
| Scénario | Paramètres suggérés |
|---|---|
| Chargement complet à partir d’une table volumineuse, avec des partitions physiques. | Option de partition: partitions physiques de la table. Pendant l’exécution, le service détecte automatiquement les partitions physiques et copie les données par partitions. |
| Charge complète à partir d’une table volumineuse, sans partitions physiques, avec une colonne entière pour le partitionnement des données. | Options de partition : Plage dynamique. colonne de partition: spécifiez la colonne utilisée pour partitionner les données. Si elle n’est pas spécifiée, la colonne de clé primaire est utilisée. |
| Chargez une grande quantité de données à l’aide d’une requête personnalisée, avec des partitions physiques. | Option de partition: partitions physiques de la table. Requête : SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.nom de partition: spécifiez le ou les noms de partition à partir duquel copier des données. S’il n’est pas spécifié, le service détecte automatiquement les partitions physiques sur la table que vous avez spécifiée dans le jeu de données PostgreSQL. Pendant l’exécution, le service remplace ?AdfTabularPartitionName par le nom de partition réel et envoie à Azure Database pour PostgreSQL. |
| Chargez une grande quantité de données à l'aide d'une requête personnalisée, sans partitions physiques, en utilisant une colonne de type entier pour le partitionnement des données. | Options de partition : Plage dynamique. Requête : SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.colonne de partition: spécifiez la colonne utilisée pour partitionner les données. Vous pouvez procéder au partitionnement par rapport à la colonne avec le type de données entier ou date/DateHeure. limite supérieure de partition et limite inférieure de partition: spécifiez si vous souhaitez filtrer par rapport à la colonne de partition pour récupérer les données uniquement entre la plage inférieure et supérieure. Pendant l’exécution, le service remplace ?AdfRangePartitionColumnName, ?AdfRangePartitionUpboundet ?AdfRangePartitionLowbound par le nom de colonne et les plages de valeurs réels pour chaque partition, et les envoie à Azure Database pour PostgreSQL. Par exemple, si votre colonne de partition « ID » est définie avec la limite inférieure comme 1 et la limite supérieure comme 80, avec la copie parallèle définie sur 4, le service récupère les données par 4 partitions. Leurs ID sont compris entre [1,20], [21, 40], [41, 60] et [61, 80], respectivement. |
Bonnes pratiques pour charger des données avec l’option de partition :
- Choisissez une colonne distincte comme colonne de partition (comme la clé primaire ou une clé unique) pour éviter l’asymétrie des données.
- Si la table a une partition intégrée, utilisez l’option de partition « Partitions physiques de table » pour obtenir de meilleures performances.
Résumé du tableau
Le tableau suivant contient plus d’informations sur l’activité de copie dans Azure Database pour PostgreSQL.
Informations sur la source
| Nom | Description | Valeur | Obligatoire | Propriété de script JSON |
|---|---|---|---|---|
| Connection | Votre connexion au magasin de données source. | < votre connexion Azure Database pour PostgreSQL > | Oui | connection |
| type de connexion | Le type de votre connexion source. | Base de données Azure pour PostgreSQL | Oui | / |
| Utiliser la requête | La façon de lire des données. Appliquez Table pour lire des données à partir de la table spécifiée ou appliquez Requête pour lire des données via des requêtes. | • Table • Requête |
Oui | • typeProperties (sous typeProperties ->source)- schéma - table • requête |
| délai d’expiration de requête (minutes) | Le temps d’attente avant la fin de la tentative d’exécution d’une commande et la génération d’une erreur, la valeur par défaut est de 120 minutes. Si le paramètre est défini pour cette propriété, les valeurs autorisées sont un intervalle de temps, par exemple « 02:00:00 » (120 minutes). Pour plus d’informations, consultez CommandTimeout. | intervalle de temps | Non | queryTimeout |
| noms de partition | Liste des partitions physiques qui doivent être copiées. Si vous utilisez une requête pour récupérer les données sources, insérez ?AdfTabularPartitionName dans la clause WHERE. |
< vos noms de partition > | Non | partitionNames |
| Nom de la colonne de partition | Nom de la colonne source en entier ou type date/datetime (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone ou time without time zone) qui sera utilisé par le partitionnement de plage pour la copie parallèle. Si elle n’est pas spécifiée, la clé primaire de la table est détectée automatiquement et utilisée comme colonne de partition. |
< noms de colonne de votre partition > | Non | partitionColumnName |
| Limite supérieure de partition | Valeur maximale de la colonne de partition pour extraire des données. Si vous utilisez une requête pour récupérer les données sources, intégrez ?AdfRangePartitionUpbound dans la clause WHERE. |
< limite supérieure de votre partition > | Non | partitionUpperBound |
| Limite inférieure de partition | Valeur minimale de la colonne de partition à partir de laquelle copier les données. Si vous utilisez une requête pour récupérer les données sources, insérez ?AdfRangePartitionLowbound dans la clause WHERE. |
< limite inférieure de votre partition > | Non | partitionLowerBound |
| Colonnes supplémentaires | Ajoutez des colonnes de données supplémentaires pour stocker le chemin d’accès relatif ou la valeur statique des fichiers sources. L'expression est prise en charge pour ce dernier. | •Nom •Valeur |
Non | additionalColumns : • nom •valeur |
Informations de destination
| Nom | Description | Valeur | Obligatoire | Propriété de script JSON |
|---|---|---|---|---|
| Connection | Votre connexion au magasin de données de destination. | < votre connexion Azure Database pour PostgreSQL > | Oui | connection |
| type de connexion | Type de connexion de destination. | Base de données Azure pour PostgreSQL | Oui | / |
| Table | Votre table de données de destination pour écrire des données. | < nom de votre table de destination > | Oui | typeProperties (sous typeProperties ->sink) :- schéma - table |
| Méthode d’écriture | Méthode utilisée pour écrire des données dans Azure Database pour PostgreSQL. | • Commande de copie (valeur par défaut) • Bulk insert |
Non | writeMethod : • CopyCommand • BulkInsert |
| Script de pré-copie | Requête SQL pour l’activité de copie à exécuter avant d’écrire des données dans Azure Database pour PostgreSQL dans chaque exécution. Vous pouvez utiliser cette propriété pour nettoyer les données préchargées. | < votre script de pré-copie> | Non | preCopyScript |
| Délai d’expiration du lot d’écriture | Temps d’attente pour que l’opération d’insertion de lot soit terminée avant d’expirer. | durée (la valeur par défaut est 00:30:00 - 30 minutes) |
Non | writeBatchTimeout |
| Écrire la taille du lot | Nombre de lignes chargées dans Azure Database pour PostgreSQL par lot. | entier (la valeur par défaut est 1 000 000) |
Non | writeBatchSize |