Comment configurer Amazon RDS pour SQL Server dans l’activité Copy
Cet article explique comment utiliser l’activité Copy dans un pipeline de données pour copier des données depuis Amazon RDS pour SQL Server.
Configuration prise en charge
Pour la configuration de chaque onglet sous l’activité de copie, accédez respectivement aux sections suivantes.
Général
Reportez-vous aux instructions relatives aux paramètres Général pour configurer l’onglet Paramètres Général .
Source
Les propriétés suivantes sont prises en charge par Amazon RDS pour SQL Server sous l’onglet Source d’une activité Copy.
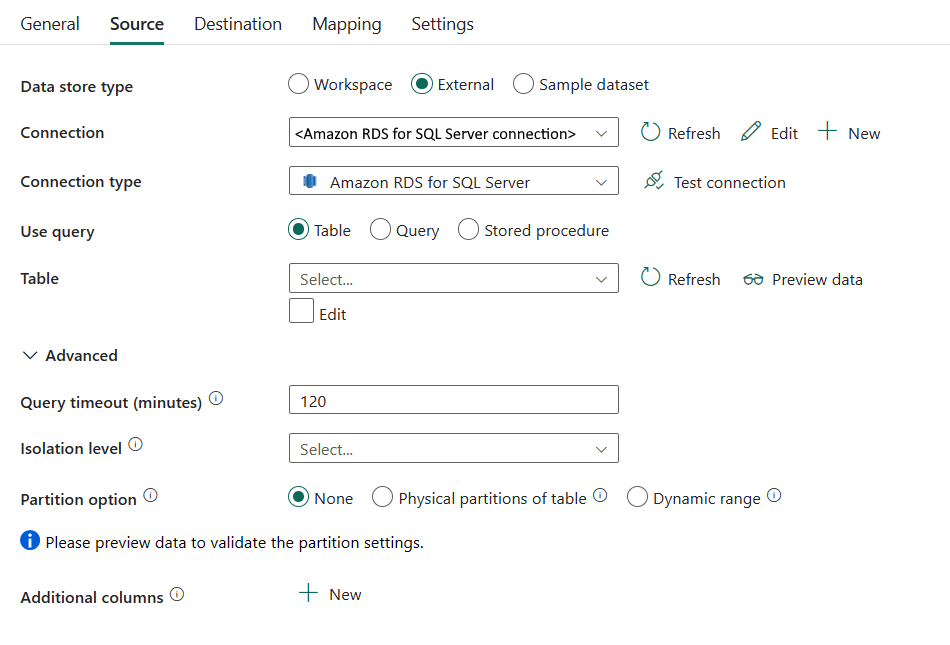
Les propriétés suivantes sont requises :
Type de magasin de données : sélectionnez Externe.
Connexion : sélectionnez une connexion Amazon RDS pour SQL Server dans la liste des connexions. Si la connexion n’existe pas, créez-en une en sélectionnant Nouveau.
Type de connexion : sélectionnez Amazon RDS pour SQL Server.
Utiliser la requête : spécifiez le mode de lecture des données. Vous pouvez choisir Table, Requête ou Procédure stockée. La liste suivante décrit la configuration de chaque paramètre :
Table : lit les données de la table spécifiée. Sélectionnez votre table source dans la liste déroulante, ou sélectionnez Modifier pour l’entrer manuellement.
Requête : spécifie la requête SQL personnalisée pour lire les données. par exemple
select * from MyTable. Vous pouvez également sélectionner l’icône de crayon à modifier dans l’éditeur de code.
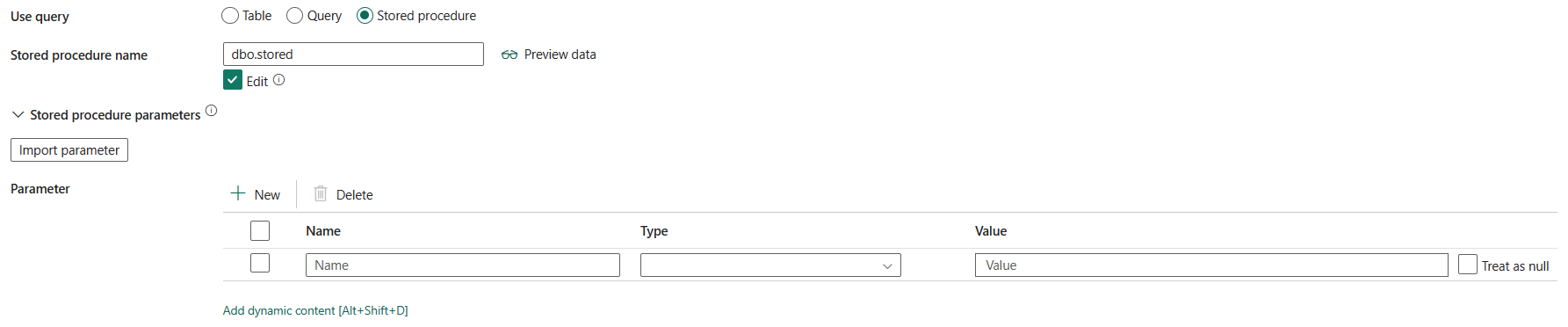
Procédure stockée : Nom de la procédure stockée qui lit les données de la table source. La dernière instruction SQL doit être une instruction SELECT dans la procédure stockée.
Nom de la procédure stockée : sélectionnez la procédure stockée ou spécifiez le nom de la procédure stockée manuellement lorsque vous sélectionnez Modifier pour lire les données de la table source.
Paramètres de procédure stockée : spécifiez des valeurs pour les paramètres de procédure stockée. Les valeurs autorisées sont des paires de noms ou de valeurs. Les noms et la casse des paramètres doivent correspondre aux noms et à la casse des paramètres de procédure stockée. Vous pouvez sélectionner Importer des paramètres pour obtenir vos paramètres de procédure stockée.
Sous Avancé, vous pouvez spécifier les champs suivants :
Délai d’expiration de la requête (minutes) : spécifiez le délai d’expiration pour l’exécution de la commande de requête, la valeur par défaut étant de 120 minutes. Si un paramètre est défini pour cette propriété, les valeurs autorisées sont un intervalle de temps, par exemple « 02:00:00 » (120 minutes).
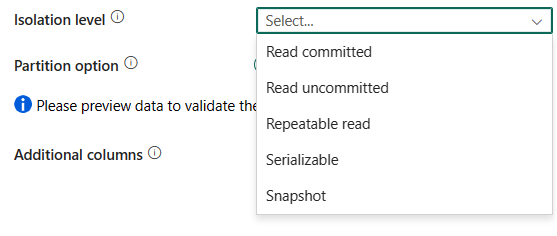
Niveau d’isolation : Spécifie le comportement de verrouillage des transactions pour la source SQL. Les valeurs autorisées sont les suivantes : Lecture validée, Lecture non validée, Lecture renouvelable, Sérialisable et Instantané. S’il n’est pas spécifié, le niveau d’isolation par défaut de la base de données est utilisé. Pour plus d’informations, reportez-vous à IsolationLevel Enum.
Option de partition : spécifiez les options de partitionnement des données utilisées pour charger des données à partir d’Amazon RDS pour SQL Server. Les valeurs autorisées sont : Aucune (valeur par défaut), Partitions physiques de la table et Plage dynamique. Lorsqu’une option de partition est activée (autrement dit, pas Aucun), le degré de parallélisme pour charger simultanément les données à partir d’Amazon RDS pour SQL Server est contrôlé par le Degré de parallélisme de copie sous l’onglet des paramètres de l’activité Copy.
Aucun : choisissez ce paramètre pour ne pas utiliser de partition.
Partitions physiques de table : lors de l’utilisation d’une partition physique, la colonne de partition et le mécanisme sont automatiquement déterminés en fonction de votre définition de table physique.
Plage dynamique : lors de l’utilisation d’une requête avec le parallèle activé, le paramètre de partition de plage(
?DfDynamicRangePartitionCondition) est nécessaire. Exemple de requête :SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Nom de la colonne de partition : Indiquez le nom de la colonne source de type entier ou date/heure (
int,smallint,bigint,date,smalldatetime,datetime,datetime2, oudatetimeoffset) qui est utilisée par le partitionnement de plage pour la copie parallèle. S’il n’est pas spécifié, l’index ou la clé primaire de la table seront automatiquement détectés et utilisés en tant que colonne de partition.Si vous utilisez une requête pour récupérer des données sources, utilisez
?DfDynamicRangePartitionConditiondans la clause WHERE. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la base de données SQL.Limite supérieure de la partition : Valeur maximale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête seront partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la base de données SQL.
Limite inférieure de la partition : Valeur minimum de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête seront partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la base de données SQL.
Colonnes supplémentaires : ajoutez des colonnes de données supplémentaires au chemin d’accès relatif ou à la valeur statique des fichiers sources du magasin. L'expression est prise en charge pour ce dernier.
Notez les points suivants :
- Si l’option Requête est spécifiée pour la source, l’activité Copy exécute cette requête sur la source SQL Server pour obtenir les données. Vous pouvez également indiquer une procédure stockée en spécifiant Nom de la procédure stockée et Paramètres de procédure stockée si la procédure stockée accepte des paramètres.
- Lorsque vous utilisez une procédure stockée dans la source pour récupérer des données, sachez que si votre procédure stockée est conçue pour renvoyer un schéma différent quand une valeur de paramètre différente est entrée, vous risquez d’échouer ou d’obtenir un résultat inattendu lors de l’importation d’un schéma à partir de l’interface utilisateur ou lors de la copie de données dans la base de données SQL avec création de table automatique.
Mappage
Pour la configuration de l’onglet Mappage, accédez à Configurer vos mappages sous l’onglet Mappage.
Paramètres
Pour la configuration de l’onglet Paramètres, accédez à Configurer vos autres paramètres sous l’onglet Paramètres.
Copier en parallèle à partir de la base de données SQL
Le connecteur Amazon RDS for SQL Server dans l'activité de copie fournit un partitionnement des données intégré pour copier les données en parallèle. Vous trouverez des options de partitionnement de données dans l’onglet Source de l’activité de copie.
Lorsque vous activez la copie partitionnée, l'activité de copie exécute des requêtes parallèles contre votre source Amazon RDS for SQL Server pour charger les données par partitions. Le degré de parallélisme est contrôlé par le Degré de parallélisme de copie sous l’onglet des paramètres de l’activité Copy. Par exemple, si vous définissez Degré de parallélisme de copie sur quatre, le service génère et exécute simultanément quatre requêtes en fonction de l’option et des paramètres de votre partition spécifiée, et chaque requête récupère une partie des données depuis votre instance Amazon RDS pour SQL Server.
Nous vous suggérons d'activer la copie parallèle avec le partitionnement des données, en particulier lorsque vous chargez une grande quantité de données depuis votre Amazon RDS for SQL Server. Voici quelques suggestions de configurations pour différents scénarios. Lors de la copie de données dans un magasin de données basé sur un fichier, il est recommandé d’écrire les données dans un dossier sous la forme de plusieurs fichiers (spécifiez uniquement le nom du dossier). Les performances seront meilleures qu’avec l’écriture de données dans un seul fichier.
| Scénario | Paramètres suggérés |
|---|---|
| Chargement complet à partir d’une table volumineuse, avec des partitions physiques. | Option de partition : Partitions physiques de la table. Pendant l’exécution, le service détecte automatiquement les partitions physiques et copie les données par partition. Pour vérifier si votre table possède, ou non, une partition physique, vous pouvez vous reporter à cette requête. |
| Chargement complet d’une table volumineuse, sans partitions physiques, avec une colonne d’entiers ou DateHeure pour le partitionnement des données. | Options de partition : Partition dynamique par spécification de plages de valeurs. Colonne de partition (facultatif) : Spécifiez la colonne utilisée pour partitionner les données. Si la valeur n’est pas spécifiée, la colonne de la clé primaire est utilisée. Limite supérieure de partition et limite inférieure de partition (facultatif) : Spécifiez si vous souhaitez déterminer le stride de la partition. Cela ne permet pas de filtrer les lignes de la table ; toutes les lignes de la table sont partitionnées et copiées. S’il n’est pas spécifié, l’activité Copy détecte automatiquement les valeurs et peut prendre beaucoup de temps en fonction des valeurs MIN et MAX. Il est recommandé de fournir une limite supérieure et une limite inférieure. Par exemple, si les valeurs de la colonne de partition « ID » sont comprises entre 1 et 100, et que vous définissez la limite inférieure à 20 et la limite supérieure à 80, avec la copie parallèle à 4, le service récupère des données en fonction de 4 partitions, (ID des plages <=20, [21, 50], [51, 80] et >=81, respectivement). |
| Chargement d’une grande quantité de données à l’aide d’une requête personnalisée, sans partitions physiques, et avec une colonne d’entiers ou de date/DateHeure pour le partitionnement des données. | Options de partition : Partition dynamique par spécification de plages de valeurs. Requête: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Colonne de partition : Spécifiez la colonne utilisée pour partitionner les données. Limite supérieure de partition et limite inférieure de partition (facultatif) : Spécifiez si vous souhaitez déterminer le stride de la partition. Cela ne permet pas de filtrer les lignes de la table ; toutes les lignes du résultat de la requête sont partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. Par exemple, si les valeurs de la colonne de partition « ID » sont comprises entre 1 et 100, et que vous définissez la limite inférieure à 20 et la limite supérieure à 80, avec la copie parallèle à 4, le service récupère des données en fonction de 4 partitions (ID des plages <=20, [21, 50], [51, 80] et >=81, respectivement). Voici d’autres exemples de requêtes pour différents scénarios : • Interroger l’ensemble de la table : SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Interroger une table avec une sélection de colonnes et des filtres de la clause WHERE supplémentaires : SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Effectuer une requête avec des sous-requêtes : SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Effectuer une requête avec une partition dans une sous-requête : SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Meilleures pratiques pour charger des données avec l’option de partition :
- Choisissez une colonne distinctive comme colonne de partition (p. ex. : clé primaire ou clé unique) pour éviter l’asymétrie des données.
- Si la table possède une partition intégrée, utilisez l’option de partition Partitions physiques de la table pour obtenir de meilleures performances.
Exemple de requête pour vérifier une partition physique
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Si la table a une partition physique, vous voyez « HasPartition » avec la valeur « yes » (oui) comme suit.

Résumé du tableau
Consultez le tableau suivant pour obtenir le résumé et plus d’informations sur l’activité Copy d’Amazon RDS pour SQL Server.
Informations sur la source
| Nom | Description | Valeur | Obligatoire | Propriété de script JSON |
|---|---|---|---|---|
| Type de banque de données | Votre type de magasin de données. | Externe | Oui | / |
| Connection | Votre connexion au magasin de données source. | < votre connexion > | Oui | connection |
| Type de connexion | Votre type de connexion. Sélectionnez Amazon RDS pour SQL Server. | Amazon RDS pour SQL Server | Oui | / |
| Utiliser la requête | La requête SQL personnalisée pour lire les données. | Table • Requête • Procédure stockée |
Oui | / |
| Table | Votre table de données source. | < nom de votre table de destination> | Non | schéma table |
| Requête | La requête SQL personnalisée pour lire les données. | < votre requête > | Non | sqlReaderQuery |
| Nom de la procédure stockée | Cette propriété est le nom de la procédure stockée qui lit les données dans la table source. La dernière instruction SQL doit être une instruction SELECT dans la procédure stockée. | < nom de la procédure stockée > | Non | sqlReaderStoredProcedureName |
| Paramètre de procédure stockée | Ces paramètres concernent la procédure stockée. Les valeurs autorisées sont des paires de noms ou de valeurs. Les noms et la casse des paramètres doivent correspondre aux noms et à la casse des paramètres de procédure stockée. | < paires nom ou valeur > | Non | storedProcedureParameters |
| Délai d'expiration de la requête | Délai d’expiration pour l’exécution de la commande de requête. | intervalle de temps (la valeur par défaut est de 120 minutes) |
Non | queryTimeout |
| Niveau d’isolation | Spécifie le comportement de verrouillage des transactions pour la source SQL. | • Lecture validée • Lecture invalidée • Lecture renouvelable • Serializable • Instantané |
Non | isolationLevel : • ReadCommitted • ReadUncommitted • RepeatableRead • Serializable • Instantané |
| Option de partition | Les options de partitionnement des données utilisées pour charger les données depuis Amazon RDS pour SQL Server. | • Aucun (valeur par défaut) • Partitions physiques de la table • Plage dynamique |
Non | partitionOption : • Aucun (valeur par défaut) • PhysicalPartitionsOfTable • DynamicRange |
| Nom de la colonne de partition | Nom de la colonne source en type entier ou date/datetime (int, smallint, bigint, date, smalldatetime, datetime, datetime2 ou datetimeoffset) utilisé par le partitionnement par plages de valeurs pour la copie en parallèle. S’il n’est pas spécifié, l’index ou la clé primaire de la table seront automatiquement détectés et utilisés en tant que colonne de partition. Si vous utilisez une requête pour récupérer des données sources, utilisez ?DfDynamicRangePartitionCondition dans la clause WHERE. |
< noms de colonne de votre partition > | Non | partitionColumnName |
| Limite supérieure de partition | Valeur maximale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête seront partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. | < limite supérieure de votre partition > | Non | partitionUpperBound |
| Limite inférieure de partition | Valeur minimale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête seront partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. | < limite inférieure de votre partition > | Non | partitionLowerBound |
| Colonnes supplémentaires | Ajouter les colonnes de données supplémentaires pour stocker le chemin d’accès relatif ou la valeur statique des fichiers sources. L’expression est prise en charge pour ce dernier. | • Nom • Valeur |
Non | additionalColumns : • nom • valeur |