Déboguer à l’aide du diagramme de travail physique (préversion) dans le portail Azure
Le diagramme de travail physique dans le portail Azure peut vous aider à visualiser les métriques clés de votre travail avec un nœud de diffusion en continu sous la forme d’un diagramme ou d’un tableau, par exemple : utilisation du processeur, utilisation de la mémoire, événements d’entrée, ID de partition et délai en filigrane. Il vous aide à identifier la cause d’un problème lorsque vous résolvez des problèmes.
Cet article montre comment utiliser le diagramme de travail physique pour analyser les performances d’un travail et identifier rapidement son goulot d’étranglement dans le portail Azure.
Important
Cette fonctionnalité est actuellement en PRÉVERSION. Pour connaître les conditions juridiques qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou plus généralement non encore en disponibilité générale, consultez l’Avenant aux conditions d’utilisation des préversions de Microsoft Azure.
Identifier le parallélisme d’un travail
Le travail avec parallélisation est le scénario évolutif dans Stream Analytics, qui peut offrir de meilleures performances. Si une tâche n’est pas en mode parallèle, il est fort probable qu’un goulot d’étranglement affecte ses performances. Il est important d’identifier si un travail est en mode parallèle ou non. Un diagramme de travail physique fournit un graphique visuel pour illustrer le parallélisme du travail. Dans un diagramme de travail physique, s’il existe une interaction de données entre différents nœuds de diffusion en continu, ce travail est un travail non parallèle nécessite plus d’attention. Par exemple, le diagramme de travail non parallèle ci-dessous :

Vous pouvez envisager de l’optimiser en travail parallèle (comme dans l’exemple ci-dessous) en réécrivant votre requête ou en mettant à jour des configurations d’entrée/sortie avec le simulateur de diagramme de travail dans l’extension Visual Studio Code ASA ou l’éditeur de requête dans le portail Azure. Pour en savoir plus, consultez Optimiser une requête à l’aide d’un simulateur de diagramme de travail (préversion).

Métriques clés pour identifier le goulot d’étranglement d’un travail parallèle
Le délai en filigrane et les événements d’entrée en backlog sont les principales métriques qui permettent de déterminer les performances de votre travail Stream Analytics. Si le délai en filigrane de votre travail augmente continuellement et si les événements d’entrée sont placés dans le backlog, cela signifie que votre travail n’arrive pas à suivre le rythme des événements d’entrée et à produire des sorties en temps opportun. Du point de vue des ressources de calcul, les ressources de processeur et de mémoire sont utilisées à haut niveau lorsque ce cas se produit.
Le diagramme de travail physique visualise ces métriques clés ensemble dans le diagramme pour vous fournir une image complète de celles-ci permettant d’identifier facilement le goulot d’étranglement.

Pour plus d’informations sur la définition des métriques, consultez la dimension de nom de nœud Azure Stream Analytics.
Identifier les événements d’entrée distribués de façon inégale (asymétrie des données)
Lorsque vous avez un travail en cours d’exécution en mode parallèle, mais observez un délai en filigrane important, utilisez cette méthode pour déterminer pourquoi.
Pour trouver la cause racine, vous ouvrez le diagramme de travail physique dans le portail Azure. Sous Surveillance, sélectionnez Diagramme de travail (préversion), puis basculez vers Diagramme physique.
À partir du diagramme physique, vous pouvez facilement déterminer si toutes les partitions ont un délai en filigrane important, ou si ce n’est le cas que de quelques-unes d’entre elles, en affichant la valeur du délai en filigrane dans chaque nœud ou en choisissant le paramètre de carte thermique de délai en filigrane afin de trier les nœuds de diffusion en continu (recommandé) :

Après avoir appliqué les paramètres de carte thermique que vous avez définis ci-dessus, vous obtenez les nœuds de diffusion en continu avec un délai en filigrane important dans l’angle supérieur gauche. Vous pouvez ensuite vérifier si les nœuds de diffusion en continu correspondants ont beaucoup plus d’événements d’entrée que d’autres. Pour cet exemple, streamingnode#0 et streamingnode#1 ont plus d’événements d’entrée.

Vous pouvez vérifier plus en détail le nombre de partitions allouées aux nœuds de diffusion en continu individuellement afin de déterminer si plus d’événements d’entrée sont occasionnés par davantage de partitions allouées ou une partition spécifique ayant davantage d’événements d’entrée. Pour cet exemple, tous les nœuds de diffusion en continu ont deux partitions. Cela signifie que streamingnode#0 et streamingnode#1 ont une partition spécifique contenant plus d’événements d’entrée que d’autres partitions.
Pour localiser la partition qui a plus d’événements d’entrée que d’autres partitions dans streamingnode#0 et streamingnode#1, procédez comme suit :
- Dans la section Graphique, sélectionnez Ajouter un graphique
- Ajouter des Événements d’entrée dans une métrique, et l’ID de partition dans un séparateur.
- Sélectionnez Appliquer pour afficher le graphique d’événements d’entrée.
- Sélectionnez streamingnode#0 et streamingnode#1 dans le diagramme.
Vous verrez le graphique ci-dessous avec la métrique des événements d’entrée filtrée par partitions dans les deux nœuds de diffusion en continu.

Quelles autres actions pouvez-vous entreprendre ?
Comme le montre l’exemple, les partitions (0 et 1) ont plus de données d’entrée que d’autres partitions. C’est ce que nous appelons une asymétrie des données. Les nœuds de diffusion en continu qui traitent des partitions présentant une asymétrie des données doivent consommer plus de ressources de processeur et de mémoire que d’autres. Ce déséquilibre entraîne un ralentissement des performances et augmente le délai en filigrane. Vous pouvez vérifier l’utilisation du processeur et de la mémoire dans les deux nœuds de diffusion en continu ainsi que dans le diagramme physique. Pour atténuer ce problème, vous devez répartir vos données d’entrée de manière plus uniforme.
Identifier la cause d’une surcharge de processeur ou de mémoire
Quand un travail parallèle présente un délai en filigrane croissant sans la situation d’asymétrie des données mentionnée précédemment, cela peut être dû à la présence d’une quantité importante de données sur tous les nœuds de diffusion en continu, qui altère les performances. Vous pouvez voir que le travail présente cette caractéristique à l’aide du diagramme physique.
Ouvrez le diagramme de travail physique, accédez à votre travail sur le portail Azure sous Surveillance, sélectionnez Diagramme de travail (préversion) et basculez vers Diagramme physique. Vous verrez le diagramme physique chargé comme ci-dessous.
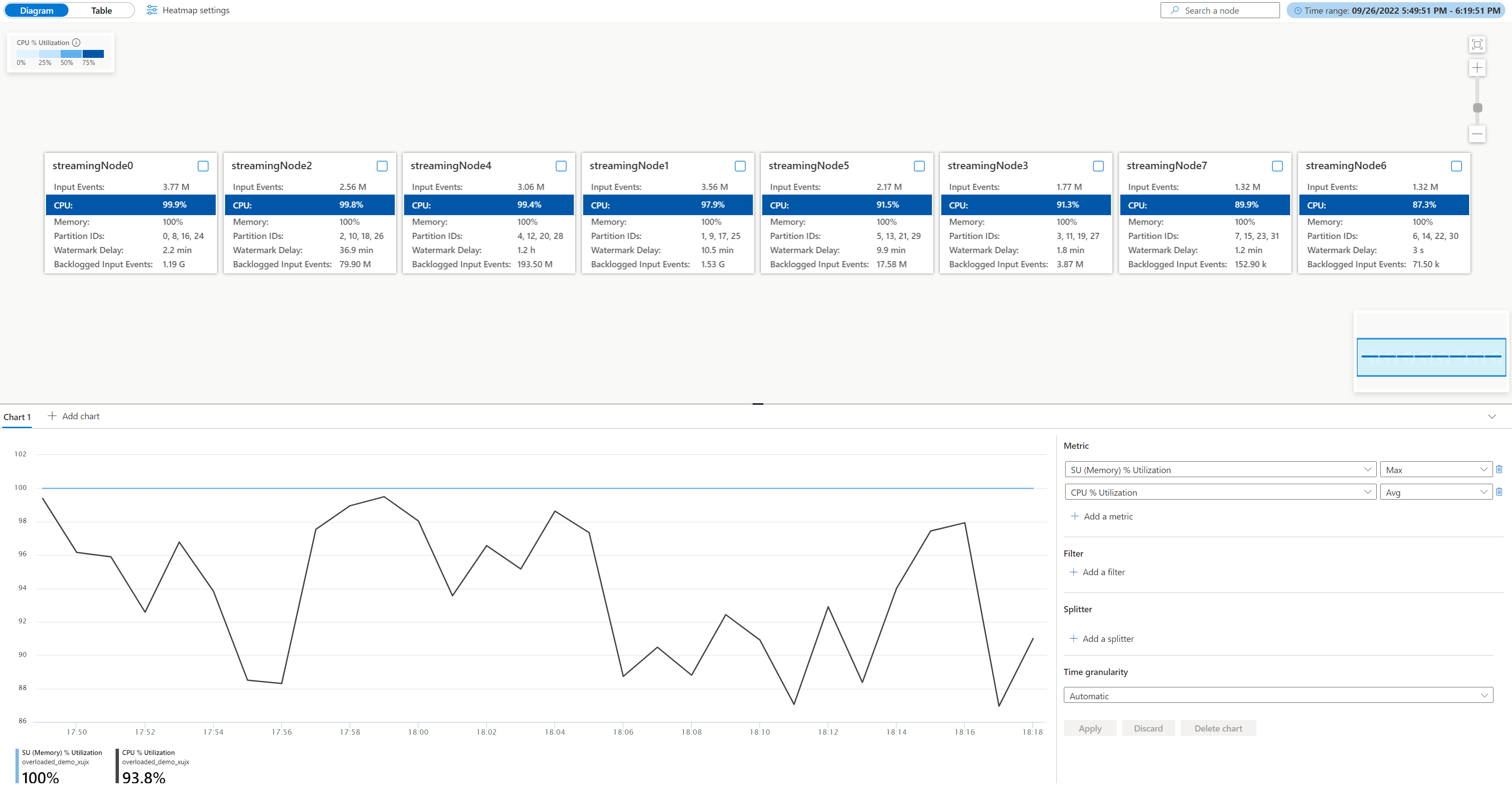
Vérifiez l’utilisation du processeur et de la mémoire dans chaque nœud de diffusion en continu pour déterminer si l’utilisation est trop élevée dans tous les nœuds de diffusion en continu. Si l’utilisation du processeur et de l’unité de diffusion en continu est très élevée (plus de 80 pour cent) dans tous les nœuds de diffusion en continu, vous pouvez conclure que ce travail a une grande quantité de données traitées dans chaque nœud de diffusion en continu.
Dans le cas ci-dessus, l’utilisation du processeur est d’environ 90 % et l’utilisation de la mémoire est déjà de 100 %. Il montre que chaque nœud de diffusion en continu manque de ressources pour traiter les données.

Vérifiez le nombre de partitions allouées à chaque nœud de diffusion en continu afin de pouvoir décider si vous avez besoin de nœuds de diffusion en continu supplémentaires pour équilibrer les partitions afin de réduire la charge des nœuds de diffusion en continu existants.
Dans ce cas, chaque nœud de diffusion en continu a quatre partitions allouées, ce qui semble excessif pour un nœud de diffusion en continu.


Quelles autres actions pouvez-vous entreprendre ?
Envisagez de réduire le nombre de partitions pour chaque nœud de diffusion en continu afin de réduire les données d’entrée. Vous pourriez doubler les unités de diffusion en continu allouées à chaque nœud de diffusion en continu pour passer à deux partitions par nœud en augmentant le nombre de nœuds de diffusion en continu de 8 à 16. Vous pouvez également quadrupler les unités de streaming pour que chaque nœud de streaming gère les données d’une partition.
Pour en savoir plus sur la relation entre le nœud de diffusion en continu et l’unité de diffusion en continu, consultez Comprendre l’unité de diffusion en continu et le nœud de diffusion en continu.
Que dois-je faire si le délai en filigrane continue d’augmenter quand un seul nœud de streaming gère les données d’une seule partition ? Repartitionnez votre entrée avec davantage de partitions pour réduire la quantité de données dans chaque partition. Pour plus de détails, consultez Utiliser le repartitionnement pour optimiser des travaux Azure Stream Analytics.
Étapes suivantes
- Présentation de Stream Analytics
- Diagramme de travail Stream Analytics (préversion) dans le portail Azure
- Métriques des travaux Azure Stream Analytics
- Mise à l’échelle des travaux Stream Analytics
- Informations de référence sur le langage de requête Stream Analytics
- Analyser les performances des travaux Stream Analytics à l’aide de métriques et de dimensions