Comprendre et ajuster les unités de streaming Stream Analytics
Comprendre l’unité de streaming et le nœud de streaming
Les unités de streaming représentent les ressources de calcul allouées pour exécuter un travail Stream Analytics. Plus le nombre d’unités de streaming est élevé, plus il y a de ressources d’UC et de mémoire allouées pour votre travail. Cette capacité vous permet de vous concentrer sur la logique de requête et résume la nécessité de gérer le matériel pour exécuter votre travail Stream Analytics en temps voulu.
Azure Stream Analytics prend en charge deux structures d’unités de streaming : SU V1 (déconseillé) et SU V2 (recommandé).
Le modèle SU V1 est l’offre d’origine d’Azure Stream Analytics (ASA) où chaque 6 unités de service correspond à un seul nœud de streaming pour un travail. Les tâches peuvent également s’exécuter avec 1 et 3 unités de diffusion en continu et elles correspondent à des nœuds de streaming fractionnaires. La mise à l’échelle se produit par incréments de 6 au-delà de 6 travaux SU, à 12, 18, 24 et au-delà en ajoutant d’autres nœuds de streaming qui fournissent des ressources de calcul distribuées.
Le modèle SU V2 (recommandé) est une structure simplifiée avec une meilleure tarification pour les mêmes ressources de calcul. Dans le modèle SU V2, 1 SU V2 correspond à un nœud de streaming pour votre travail. 2 SU V2 correspond à 2, 3 à 3, et ainsi de suite. Les travaux avec 1/3 et 2/3 SU V2 sont également disponibles avec un nœud de streaming, mais une fraction des ressources de calcul. Les travaux 1/3 SU et 2/3 SU V2 offrent une option économique pour les charges de travail nécessitant une plus petite mise à l’échelle.
La puissance de calcul sous-jacente pour les unités de streaming V1 et V2 est la suivante :
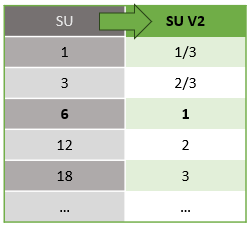
Pour plus d’informations sur la tarification su, consultez la page tarification d’Azure Stream Analytics.
Présentation des conversions d’unités de streaming et de l’emplacement de leur application
Il existe une conversion automatique d’unités de streaming qui se produit de la couche API REST vers l’interface utilisateur (portail Azure et Visual Studio Code). Vous remarquerez cette conversion dans le Journal d’activité, ainsi que les valeurs de l’unité de stockage qui s’affichent différemment des valeurs de l’interface utilisateur. Ce comportement est intentionnel et la raison est que les champs d’API REST sont limités aux valeurs entières et que les travaux ASA prennent en charge les nœuds fractionnaires (unités de diffusion en continu 1/3 SUV2 et 2/3 SUV2). L’interface utilisateur d’ASA affiche les valeurs de nœud 1/3, 2/3, 1, 2, 3, … etc. tandis que le serveur principal (journaux d’activité, couche API REST) affiche les mêmes valeurs multipliées par 10 que 3, 7, 10, 20, 30 respectivement.
| Standard | Standard V2 (IU) | Standard V2 (back-end, tels que les journaux, l’API Rest, etc.) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
Cela nous permet de transmettre la même granularité et d’éliminer la virgule décimale au niveau de la couche d’API pour les SKU V2. Cette conversion est automatique et n’a aucun impact sur les performances de votre travail.
Présentation de la consommation et de l’utilisation de la mémoire
Pour obtenir un traitement de streaming à faible latence, les travaux Azure Stream Analytics effectuent tout le traitement en mémoire. Quand la mémoire devient insuffisante, le travail de streaming échoue. Par conséquent, pour un travail de production, il est important de surveiller l’utilisation des ressources d’un travail de streaming et de vérifier qu’il existe suffisamment de ressources allouées afin d’assurer l’exécution des travaux 24 heures sur 24 et 7 jours sur 7.
La métrique de pourcentage d’utilisation des unités de streaming, comprise entre 0 % et 100 %, décrit la consommation de mémoire de votre charge de travail. Pour un travail de streaming avec un encombrement minimal, la métrique se situe généralement entre 10 et 20 %. Si le pourcentage d’utilisation des unités de streming est élevé (supérieur à 80 %) ou si les événements d’entrée sont mis en backlog (même avec un faible pourcentage d’utilisation des unités de streaming, car il n’affiche pas l’utilisation du processeur), il est probable que votre charge de travail nécessite davantage de ressources de calcul, ce qui vous oblige à augmenter le nombre d’unités de streaming. Il est préférable de conserver une métrique inférieure à 80 % pour prendre en compte les pics d’activité occasionnels. Pour réagir à l’augmentation des charges de travail et augmenter les unités de streaming, vous pouvez définir une alerte de 80 % sur la métrique d’utilisation de l’unité de stockage. En outre, vous pouvez utiliser des métriques de délai en filigrane et d’événements retardés pour voir si cela a un impact.
Configurer des unités de streaming (SU) Stream Analytics
Connectez-vous au Portail Azure.
Dans la liste des ressources, recherchez le travail Stream Analytics que vous souhaitez mettre à l’échelle, puis ouvrez-le.
Dans la page du travail, sous le titre Configurer, sélectionnez Mettre à l’échelle. Le nombre par défaut d’unités SU est 1 lors de la création d’un travail.
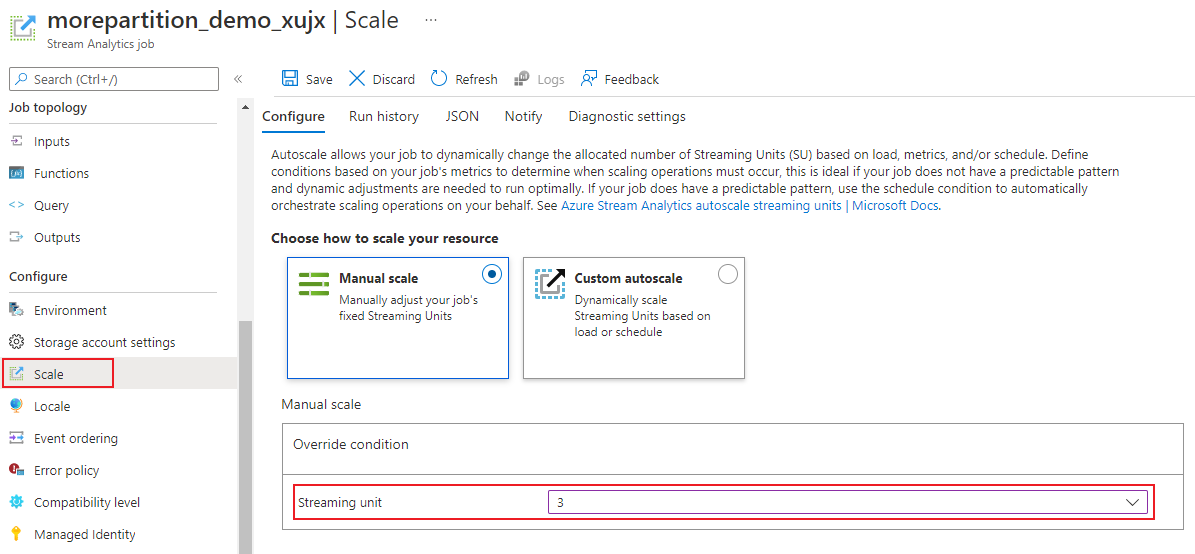
Choisissez l’option SU dans la liste déroulante pour définir les unités de stockage du travail. Notez que vous êtes limité à des paramètres d’unité SU spécifiques.
Vous pouvez modifier le nombre d’unités SU affectées à votre travail pendant qu’il est en cours d’exécution. Vous pouvez être limité à choisir parmi un ensemble de valeurs SU lorsque le travail est en cours d’exécution si votre travail utilise une sortie non partitionnée ou a une requête à plusieurs étapes avec des valeurs PARTITION BY différentes.
Surveillance des performances du travail
À l’aide du Portail Azure, vous pouvez suivre les métriques de performance d’un travail. Pour en savoir plus sur la définition des métriques, consultez Métriques de travail Azure Stream Analytics. Pour en savoir plus sur la surveillance des métriques dans le Portail, consultez Surveiller le travail Stream Analytics avec le Portail Azure.
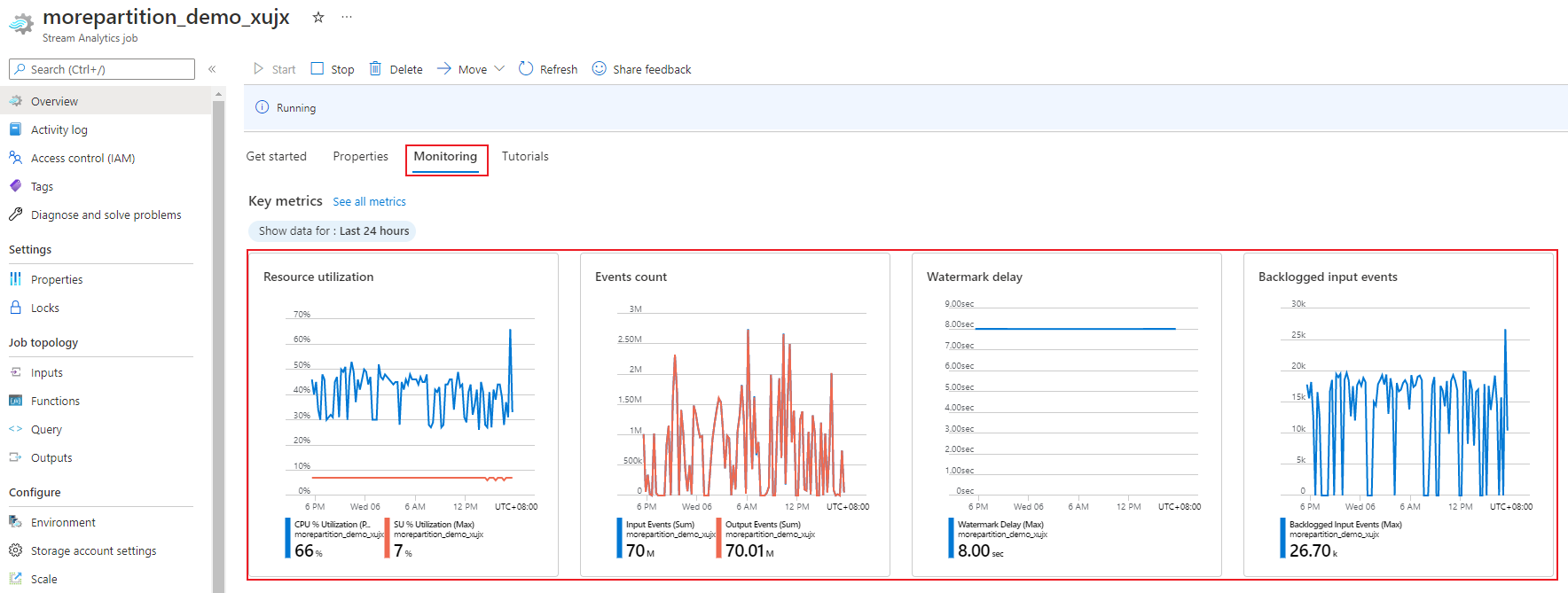
Calculez le débit prévu pour la charge de travail. Si le débit est plus faible que prévu, paramétrez la partition d’entrée ainsi que la requête, puis ajoutez des unités SU à votre travail.
Combien d’unités de streaming sont requises pour un travail ?
Le choix du nombre d’unités de streaming requises pour un travail particulier dépend de la configuration de la partition pour les entrées et de la requête définie pour le travail. La page Mise à l’échelle vous permet de définir le nombre adapté d’unités de streaming. Il est recommandé d’allouer plus d’unités de streaming que nécessaire. Le moteur de traitement Stream Analytics est configuré pour une latence et un débit supérieurs, en allouant une capacité de mémoire supplémentaire.
En règle générale, la meilleure pratique consiste à démarrer avec 1 unité de streaming V2 pour les requêtes qui n’utilisent pas PARTITION BY. Déterminez ensuite la configuration idéale en utilisant une méthode d’essai et d’erreur où vous modifiez le nombre d’unités de streaming, une fois que vous avez transmis le volume représentatif de données et examiné la métrique % d’utilisation de SU. Le nombre maximal d’unités de streaming qui peut être utilisé par un travail Stream Analytics varie selon le nombre d’étapes de la requête définie pour le travail et le nombre de partitions pour chaque étape. Pour obtenir plus d’informations sur les limites à respecter, cliquez ici.
Pour plus d’informations sur le choix du nombre adapté d’unités de streaming, consultez cette page : Mettre à l’échelle des travaux Azure Stream Analytics pour augmenter le débit.
Notes
Le choix du nombre d’unités SU requises pour un travail particulier dépend de la configuration de la partition pour les entrées et de la requête définie pour le travail. Vous pouvez sélectionner votre quota en unités SU pour un travail. Pour plus d’informations sur le quota d’abonnement Azure Stream Analytics, consultez Limites de Stream Analytics. Pour augmenter ce quota d’unités SU pour vos abonnements, contactez le Support Microsoft. Les valeurs valides pour les unités de streaming par travail sont 1/3, 2/3, 1, 2, 3, etc.
Facteurs qui augmentent l’utilisation du % SU
Les éléments de requête temporelle (orientée sur le temps) sont l’ensemble des opérateurs fournis par Stream Analytics. Stream Analytics gère l’état de ces opérations en interne au nom de l’utilisateur, grâce à la gestion de la consommation de mémoire, les points de contrôle pour la résilience et la récupération de l’état au cours des mises à niveau du service. Même si Stream Analytics gère totalement les états, il existe de nombreuses recommandations de meilleure pratique que les utilisateurs doivent prendre en compte.
Une tâche avec une logique de requête complexe peut avoir une utilisation élevée d’unités de streaming, même si elle ne reçoit pas continuellement des événements d’entrée. Cela peut se produire après un pic soudain des événements d’entrée et de sortie. Le travail peut continuer à maintenir l’état en mémoire si la requête est complexe.
Le pourcentage d'utilisation des unités de streaming peut soudainement et brièvement passer à 0 avant de revenir aux niveaux prévus. Ceci est dû à des erreurs transitoires ou à des mises à niveau lancées par le système. Augmenter le nombre d’unités de streaming d’un travail ne diminue pas forcément le pourcentage d’utilisation des unités de streaming si votre requête n’est pas entièrement parallèle.
Lorsque vous comparez l’utilisation sur une période donnée, utilisez les métriques de taux d’événements. Les métriques InputEvents et OutputEvents montrent le nombre d’événements qui ont été lus et traités. Des métriques indiquent également le nombre d’événements d’erreur, tels que les erreurs de désérialisation. Lorsque le nombre d’événements par unité de temps augmente, le pourcentage de SU augmente dans la plupart des cas.
Logique de requête avec état dans les éléments temporels
L’une des caractéristiques propres à un travail Azure Stream Analytics consiste à effectuer un traitement avec état, comme des agrégations fenêtrées, jointures temporelles et fonctions d’analyse temporelle. Chacun de ces opérateurs conserve des informations d’état. La taille maximale de la fenêtre pour ces éléments de requête est de sept jours.
Le concept de fenêtre temporelle apparaît dans plusieurs éléments de requête Stream Analytics :
Agrégats fenêtrés : GROUP BY fenêtres de Bascule, Récurrente et Glissante
Jointures temporelles : JOIN à la fonction DATEDIFF
Fonctions analytiques temporelles : ISFIRST, LAST et LAG avec LIMIT DURATION
Les facteurs suivants influencent la mémoire utilisée (qui fait partie de la métrique des unités de streaming) par les travaux Stream Analytics :
Agrégations fenêtrées
La mémoire consommée (taille de l’état) pour un agrégat fenêtré n’est pas toujours directement proportionnelle à la taille de la fenêtre. Au lieu de cela, la mémoire consommée est proportionnelle à la cardinalité des données ou le nombre de groupes dans chaque fenêtre de temps.
Par exemple, dans la requête suivante, le nombre associé à clusterid est la cardinalité de la requête.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
Afin d’atténuer les problèmes provoqués par une cardinalité élevée dans la requête précédente, vous pouvez envoyer des événements à Event Hubs avec un partitionnement par clusterid, et effectuer un scale-out de la requête en autorisant le système à traiter chaque partition d’entrée séparément à l’aide de PARTITION BY, comme indiqué dans l’exemple suivant :
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
Une fois que la requête est partitionnée, elle est répartie sur plusieurs nœuds. Par conséquent, le nombre de clusterid arrivant dans chaque nœud est réduit, ce qui réduit d’autant la cardinalité du groupe par opérateur.
Les partitions Event Hubs doivent être partitionnées par la clé de regroupement pour éviter une étape de réduction. Pour plus d'informations, consultez la Vue d'ensemble des Concentrateurs d’événements.
Jointures temporelles
La mémoire consommée (taille de l’état) d’une jointure temporelle est proportionnelle au nombre d’événements dans la marge de manœuvre temporelle de la jointure, qui est la vitesse d’entrée des événements multipliée par la taille de la marge de manœuvre. En d’autres termes, la mémoire consommée par les jointures est proportionnelle à l’intervalle de temps DateDiff multipliée par le taux d’événements moyen.
Le nombre d’événements sans correspondance de la jointure affecte la consommation de mémoire pour la requête. La requête suivante vise à identifier l’exposition publicitaire qui génère des clics :
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
Dans cet exemple, il est possible qu’un grand nombre de publicités s’affichent et que quelques personnes cliquent dessus ; cette configuration est requise pour conserver l’ensemble des événements dans la fenêtre de temps. La consommation de mémoire est proportionnelle à la taille de la fenêtre et au taux d’événements.
Pour corriger ce comportement, envoyez des événements à Event Hubs avec un partitionnement par clés de jointure (ID dans ce cas) et effectuez un scale-out de la requête en autorisant le système à traiter chaque partition d’entrée séparément à l’aide de PARTITION BY comme indiqué :
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
Une fois que la requête est partitionnée, elle est répartie sur plusieurs nœuds. Par conséquent, le nombre d’événements arrivant dans chaque nœud est réduit, ce qui réduit d’autant la taille de l’état dans la fenêtre de jointure.
Fonctions analytiques temporelles
La mémoire consommée (taille de l’état) d’une fonction analytique temporelle est proportionnelle au taux d’événements multiplié par la durée. La mémoire consommée par les fonctions analytiques n’est pas proportionnelle à la taille de la fenêtre, mais plutôt le nombre de partitions dans chaque fenêtre de temps.
La solution est similaire à celle de la jointure temporelle. Vous pouvez augmenter la taille des instances de la requête à l’aide de PARTITION BY.
Mémoire tampon d’événements en désordre
L’utilisateur peut configurer la taille de la mémoire tampon d’événements en désordre dans le volet de configuration Ordre des événements. La mémoire tampon est utilisée pour contenir des entrées pendant la durée d’affichage de la fenêtre et les réorganiser. La taille de la mémoire tampon est proportionnelle à la vitesse d’entrée des événements multipliée par la taille de la fenêtre d’événements en désordre. La taille de fenêtre par défaut est égale à 0.
Pour corriger le dépassement de capacité de la mémoire tampon, augmenter la taille des instances de la requête à l’aide de PARTITION BY. Une fois que la requête est partitionnée, elle est répartie sur plusieurs nœuds. Par conséquent, le nombre d’événements arrivant dans chaque nœud est réduit, ce qui réduit d’autant le nombre d’événements dans chaque mémoire tampon de réorganisation.
Nombre de partitions d’entrée
Chaque partition d’entrée d’une entrée de travail a une mémoire tampon. Plus le nombre de partitions d’entrée est élevé, plus le travail consomme de ressources. Pour chaque unité de streaming, Azure Stream Analytics peut traiter environ 7 Mo/s d’entrée. Par conséquent, vous pouvez optimiser en faisant correspondre le nombre d’unités de streaming Stream Analytics avec le nombre de partitions dans votre Event Hub.
En règle générale, un travail configuré avec 1/3 d’unité de streaming est suffisante pour un Event Hub avec deux partitions (qui est la valeur minimale du Event Hub). Si l’Event Hub a davantage de partitions, votre travail Stream Analytics consomme davantage de ressources, mais n’utilise pas nécessairement le débit supplémentaire fourni par le Concentrateur d’événements.
Pour un travail avec 1 unité de streaming V2, vous devrez peut-être demander 4 ou 8 partitions du Event Hub. Toutefois, évitez de trop nombreuses partitions inutiles car cela provoque l’utilisation excessive des ressources. Par exemple, un Event Hub avec 16 partitions ou plus dans un travail Stream Analytics qui possède 1 unité de streaming.
Données de référence
Les données de référence dans ASA sont chargées en mémoire pour la recherche rapide. Avec l’implémentation actuelle, chaque opération de jointure avec les données de référence conserve une copie des données de référence en mémoire, même si vous effectuez la jointure plusieurs fois avec les mêmes données de référence. Pour les requêtes avec PARTITION BY, comme chaque partition possède une copie des données de référence, les partitions sont entièrement découplées. Avec l’effet multiplicateur, l’utilisation de la mémoire peut être rapidement très élevée si vous effectuez la jointure avec les données de référence plusieurs fois avec plusieurs partitions.
Utilisation de fonctions UDF
Quand vous ajoutez une fonction UDF, Azure Stream Analytics charge le runtime JavaScript en mémoire, qui affecte le pourcentage des unités de streaming.
Étapes suivantes
- Créer des requêtes parallélisables dans Azure Stream Analytics
- Mettre à l’échelle des travaux Azure Stream Analytics pour augmenter le débit
- Métriques des travaux Azure Stream Analytics
- Dimensions des métriques des travaux Azure Stream Analytics
- Surveiller le travail Stream Analytics avec le Portail Azure
- Analyser les performances des travaux Stream Analytics avec des dimensions de métriques
- Comprendre et ajuster les unités de diffusion en continu