Assistant Importation de données dans le portail Azure
Recherche Azure AI a deux Assistants Importation qui automatisent l’indexation et la création d’objets pour vous permettre de commencer à interroger immédiatement. Si vous débutez avec Recherche Azure AI, il s’agit de l’un des assistants les plus puissants à votre disposition. Avec un minimum d’effort, vous pouvez créer un pipeline d’indexation ou d’enrichissement qui exerce la plupart des fonctionnalités de Azure AI Search.
L’Assistant Importation de données prend en charge les workflows non-vectoriels. Vous pouvez extraire du texte et des chiffres à partir de documents bruts. Vous pouvez également configurer l’IA appliquée et les compétences intégrées qui déduisent la structure et génèrent du contenu pouvant faire l’objet d’une recherche de texte à partir de fichiers image et de données non structurées.
L’Assistant Importation et vectorisation de données ajoute la segmentation et la vectorisation. Vous devez spécifier un déploiement existant d’un modèle d’incorporation, mais l’Assistant établit la connexion, formule la requête et gère la réponse. Il génère du contenu vectoriel à partir de contenu textuel ou d’image.
Si vous utilisez l’Assistant pour les tests de preuve de concept, cet article explique les fonctionnements internes des Assistants afin de pouvoir les utiliser plus efficacement.
Cet article n’est pas un guide pas à pas. Pour obtenir de l’aide sur l’utilisation de l’Assistant avec des exemples de données, consultez :
- Démarrage rapide : Créer un index de recherche
- Démarrage rapide : créer une traduction de texte et un ensemble de compétences d’entité
- Démarrage rapide : créer un index vectoriel
- Démarrage rapide : recherche d’images (vecteurs)
Sources de données et scénarios pris en charge
Les Assistants prennent en charge la plupart des sources de données prises en charge par les indexeurs.
| Données | Assistant Importation de données | Assistant Importation et vectorisation des données |
|---|---|---|
| ADLS Gen2 | ✅ | ✅ |
| Stockage Blob Azure | ✅ | ✅ |
| Stockage Fichier Azure | ❌ | ❌ |
| Azure Table Storage | ✅ | ✅ |
| Azure SQL Database et SQL Managed Instance | ✅ | ✅ |
| Cosmos DB for NoSQL | ✅ | ✅ |
| Cosmos DB pour MongoDB | ✅ | ✅ |
| Cosmos DB for Apache Gremlin | ✅ | ✅ |
| MySQL | ❌ | ❌ |
| OneLake | ✅ | ✅ |
| SharePoint Online | ❌ | ❌ |
| SQL Server sur les machines virtuelles | ✅ | ✅ |
Exemples de données
Microsoft héberge des exemples de données qui vous permettent d’omettre une étape de configuration de la source de données sur un workflow de l’Assistant.
| Exemples de données | Assistant Importation de données | Assistant Importation et vectorisation des données |
|---|---|---|
| hôtels | ✅ | ❌ |
| immobilier | ✅ | ❌ |
Compétences
Cette section liste les compétences qui peuvent apparaître dans un ensemble de compétences généré par un Assistant. Les Assistants génèrent un ensemble de compétences et des mappages de champs de sortie en fonction des options que vous sélectionnez. Une fois l’ensemble de compétences créé, vous pouvez modifier sa définition JSON pour ajouter d’autres compétences.
Voici quelques points à garder à l’esprit sur les compétences de la liste suivante :
- Des options de reconnaissance optique de caractères (OCR) et d’analyse d’image sont disponibles pour les objets blob dans Stockage Azure et les fichiers dans OneLake, en supposant le mode d’analyse par défaut. Les images sont un type de contenu image (comme PNG ou JPG) ou une image incorporée dans un fichier d’application (comme PDF).
- Un modélisateur est ajouté si vous configurez une base de connaissances.
- Le fractionnement de texte et la fusion de texte sont ajoutés pour la segmentation des données si vous choisissez un modèle d’incorporation. Ils sont ajoutés pour d’autres compétences hors incorporation si la granularité du champ source est définie sur des pages ou des phrases.
| Compétences | Assistant Importation de données | Assistant Importation et vectorisation des données |
|---|---|---|
| Multimodal AI Vision | ❌ | ✅ |
| Incorporation Azure OpenAI | ❌ | ✅ |
| Azure Machine Learning (catalogue de modèles Azure AI Foundry) | ❌ | ✅ |
| Disposition des documents | ❌ | ✅ |
| Reconnaissance d’entités | ✅ | ❌ |
| Analyse d’image (s’applique aux blobs, à l’analyse par défaut, à l’indexation de fichiers entiers) | ✅ | ❌ |
| Extraction de mots clés | ✅ | ❌ |
| Détection de langue | ✅ | ❌ |
| Traduction du texte | ✅ | ❌ |
| Reconnaissance optique de caractères (s’applique aux blobs, à l’analyse par défaut, à l’indexation de fichiers entiers) | ✅ | ✅ |
| Détection PII | ✅ | ❌ |
| Analyse des sentiments | ✅ | ❌ |
| Modélisateur (s’applique à la base de connaissances) | ✅ | ❌ |
| Fractionnement de texte | ✅ | ✅ |
| Fusion de texte | ✅ | ✅ |
Base de connaissances
Vous pouvez générer une base de connaissances pour un stockage secondaire de contenu enrichi (généré par des compétences). Une base de connaissances peut être utile pour les workflows de récupération d’informations qui ne nécessitent pas un moteur de recherche.
| Base de connaissances | Assistant Importation de données | Assistant Importation et vectorisation des données |
|---|---|---|
| storage | ✅ | ❌ |
Ce que les Assistants créent
Les Assistants Importation créent les objets décrits dans le tableau suivant. Une fois les objets créés, vous pouvez lire leurs définitions JSON dans le portail Azure ou les appeler à partir du code.
Pour visualiser ces objets après l’exécution de l’Assistant :
Connectez-vous au portail Azure, puis trouvez votre service de recherche.
Sélectionnez Gestion de la recherche dans le menu pour rechercher des pages pour les index, les indexeurs, les sources de données et les ensembles de compétences.
| Object | Description |
|---|---|
| Indexeur | Objet de configuration spécifiant une source de données, un index cible, un ensemble de compétences facultatif, une planification facultative et des paramètres de configuration facultatifs pour la gestion des erreurs et l’encodage en base 64. |
| Source de données | Conserve les informations de connexion dans une source de données prise en charge sur Azure. Un objet de source de données est utilisé exclusivement avec les indexeurs. |
| Index | Structure de données physique utilisée pour la recherche en texte intégral et d’autres requêtes. |
| Ensemble de compétences | facultatif. Ensemble complet d’instructions destiné à manipuler, transformer et mettre en forme du contenu, notamment en analysant et extrayant des informations de fichiers image. Les ensembles de compétences sont également utilisés pour la vectorisation intégrée. À moins que le volume de travail ne tombe sous la limite de 20 transactions par indexeur par jour, l’ensemble de compétences doit inclure une référence à une ressource multiservices Azure AI qui fournit un enrichissement. Pour la vectorisation intégrée, vous pouvez utiliser Azure AI Vision ou un modèle d’intégration dans le catalogue de modèles Azure AI Foundry. |
| Base de connaissances | facultatif. Disponible seulement dans l’Assistant Importation de données. Enregistre la sortie d’ensembles de compétences enrichies dans des tables et des blobs dans Stockage Azure pour une analyse indépendante ou un traitement en aval dans des scénarios hors recherche. |
Avantages
Avant d’écrire du code, vous pouvez utiliser les Assistants à des fins de prototypage et de test de preuve de concept. Les Assistants se connectent à des sources de données externes, échantillonnent les données pour créer un index initial, puis importent les données en tant que documents JSON dans un index sur Recherche Azure AI.
Si vous évaluez des ensembles de compétences, l’Assistant les mappages de champs de sortie et ajoute des fonctions d’assistance pour créer des objets utilisables. Le fractionnement de texte est ajouté si vous spécifiez un mode d’analyse. La fusion de texte est ajoutée si vous avez choisi l’analyse des images afin que l’Assistant puisse réunir les descriptions de texte et le contenu de l’image. Les compétences de modélisateur sont ajoutées pour prendre en charge les projections valides si vous avez choisi l’option Base de connaissances. Toutes les tâches ci-dessus sont accompagnées d’une courbe d’apprentissage. Si vous débutez avec l’enrichissement, la possibilité de gérer ces étapes pour vous permet de mesurer la valeur d’une compétence sans devoir investir trop de temps et d’efforts.
L’échantillonnage est le processus par lequel un schéma d’index est déduit et présente quelques limitations. Lorsque la source de données est créée, l’Assistant choisit au hasard un échantillon de documents pour identifier les colonnes qui font partie de la source de données. Tous les fichiers ne sont pas lus, car l’opération pourrait durer des heures avec les sources de données très volumineuses. À partir d’une sélection de documents, les métadonnées sources, comme le nom ou le type de champ, sont utilisées pour créer une collection de champs dans un schéma d’index. Selon la complexité des données sources, vous devrez peut-être modifier le schéma initial dans un souci de précision, ou l’étendre à des fins d’exhaustivité. Vous pouvez faire en sorte que vos modifications soient incorporées dans la page de définition de l’index.
Globalement, les avantages de l’Assistant sont évidents : dans la mesure où les exigences sont respectées, vous pouvez créer un index interrogeable en quelques minutes. Certaines des complexités liées à l’indexation, comme la sérialisation des données sous forme de documents JSON, sont gérées par les Assistants.
Limites
Les Assistants Importation ont certaines limitations. Les contraintes sont les suivantes :
Les Assistants ne prennent pas en charge l’itération ni la réutilisation. Chaque exécution de l’Assistant donne lieu à la création d’une configuration d’index, d’ensemble de compétences et d’indexeur. Seules les sources de données peuvent être conservées et réutilisées dans l’Assistant. Pour modifier ou affiner d’autres objets, supprimez les objets et recommencez, ou utilisez les API REST ou le kit de développement logiciel (SDK) .NET pour modifier les structures.
Le contenu source doit résider dans une source de données prise en charge.
L’échantillonnage porte sur un sous-ensemble des données sources. Pour les sources de données volumineuses, l’Assistant peut ne pas déceler des champs. Vous serez peut-être amené à étendre le schéma ou à corriger les types de données déduits si l’échantillonnage est insuffisant.
L’enrichissement par IA, tel que présenté sur le portail Azure, se limite à un sous-ensemble de compétences intégrées.
Une base de connaissances, qui peut être créée par l’Assistant Importation, est limitée à quelques projections par défaut et utilise une convention d’affectation de noms par défaut. Si vous voulez personnaliser des noms ou des projections, vous devrez créer la base de connaissances via l’API REST ou les SDK.
Sécuriser les connexions
Les Assistants d’importation effectuent des connexions sortantes à l’aide du contrôleur de portail Azure et des points de terminaison publics. Vous ne pouvez pas utiliser les Assistants si les ressources Azure sont accessibles via une connexion privée ou via une liaison privée partagée.
Vous pouvez utiliser les Assistants sur des connexions publiques restreintes, mais toutes les fonctionnalités ne sont pas disponibles.
Sur un service de recherche, l’importation des exemples de données intégrés nécessite un point de terminaison public et aucune règle de pare-feu.
Les exemples de données sont hébergés par Microsoft sur des ressources Azure spécifiques. Le contrôleur de portail Azure se connecte à ces ressources via un point de terminaison public. Si vous placez votre service de recherche derrière un pare-feu, vous obtenez cette erreur lors de la tentative de récupération des exemples de données intégrés :
Import configuration failed, error creating Data Source, suivi de"An error has occured.".Sur les sources de données Azure prises en charge protégées par pare-feu, vous pouvez récupérer des données si vous disposez des règles de pare-feu appropriées.
La ressource Azure doit admettre les requêtes réseau à partir de l’adresse IP de l’appareil utilisé sur la connexion. Vous devez également répertorier Recherche Azure AI en tant que service approuvé sur la configuration réseau de la ressource. Par exemple, dans Stockage Azure, vous pouvez répertorier
Microsoft.Search/searchServicesen tant que service approuvé.Lors des connexions à un compte multiservice Azure AI que vous fournissez, ou lors des connexions aux modèles d’intégration déployés dans le portail Azure AI Foundry ou Azure OpenAI, l’accès Internet public doit être activé, sauf si votre service de recherche répond aux exigences de date de création, de niveau et de région pour les connexions privées. Pour plus d’informations sur ces exigences, voir Créer des connexions sortantes via une liaison privée partagée.
Les connexions à Azure AI multiservice sont destinées à la facturation. La facturation intervient lorsque les appels API dépassent le nombre de transactions gratuites (20 par cycle d'indexation) pour les compétences intégrées appelées par l'assistant d'importation de données ou la vectorisation intégrée dans l'assistant d'importation et de vectorisation de données.
Si Azure AI Search ne peut pas se connecter :
Dans l’Assistant Importation et vectorisation de données, l’erreur est
"Access denied due to Virtual Network/Firewall rules."Dans l’Assistant Importation de données, il n’y a aucune erreur, mais l’ensemble de compétences ne sera pas créé.
Si les paramètres de pare-feu empêchent les flux de travail de votre Assistant de réussir, envisagez plutôt d’utiliser des approches de script ou de programmation.
Workflow
L’Assistant est organisé en quatre étapes principales :
Il se connecte à une source de données Azure prise en charge.
Il crée un schéma d’index, déduit par l’échantillonnage des données sources.
En option, elle ajoute des compétences pour extraire ou générer du contenu et une structure. Les entrées pour la création d’une base de connaissances sont collectées à cette étape.
Exécutez l’Assistant pour créer des objets, éventuellement vectoriser des données, charger des données dans un index, définir une planification et d’autres options de configuration.
Le flux de travail est un pipeline. Il s’agit donc d’une façon unique. Vous ne pouvez pas utiliser l’Assistant pour modifier les objets créés, mais vous pouvez utiliser d’autres outils de portail, tels que l’index ou le concepteur d’indexeurs ou les éditeurs JSON, pour les mises à jour autorisées.
Démarrage des Assistants
Voici comment démarrer les Assistants.
Dans le portail Azure, ouvrez la page du service de recherche à partir du tableau de bord, ou recherchez votre service dans la liste.
Dans la page Vue d’ensemble du service en haut, sélectionnez Importer des données ou Importer et vectoriser des données.
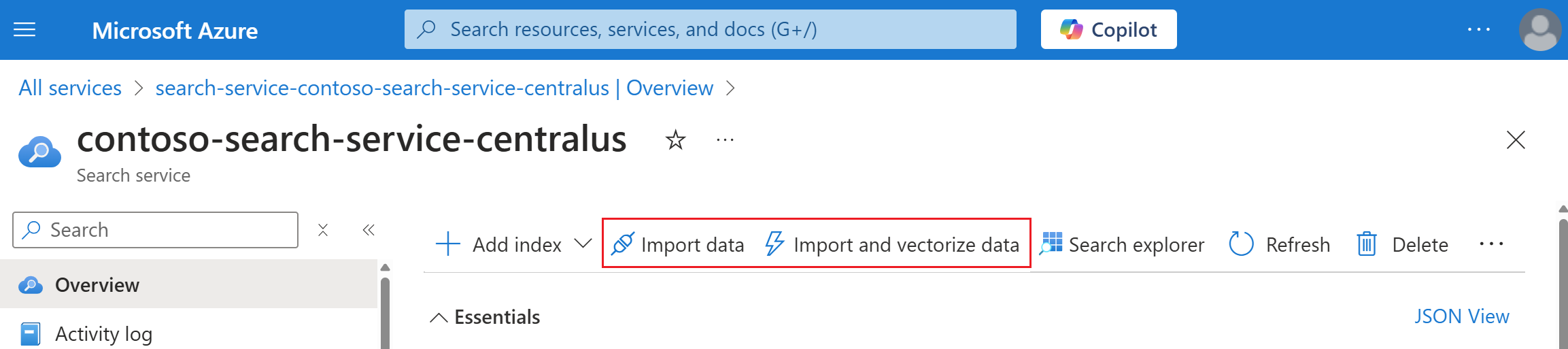
Les Assistants s’ouvrent entièrement dans la fenêtre du navigateur, ce qui vous permet d’avoir plus de place pour travailler.
Si vous avez sélectionné Importer des données, vous pouvez sélectionner l’option Exemples pour indexer un jeu de données hébergé par Microsoft dans une source de données prise en charge.
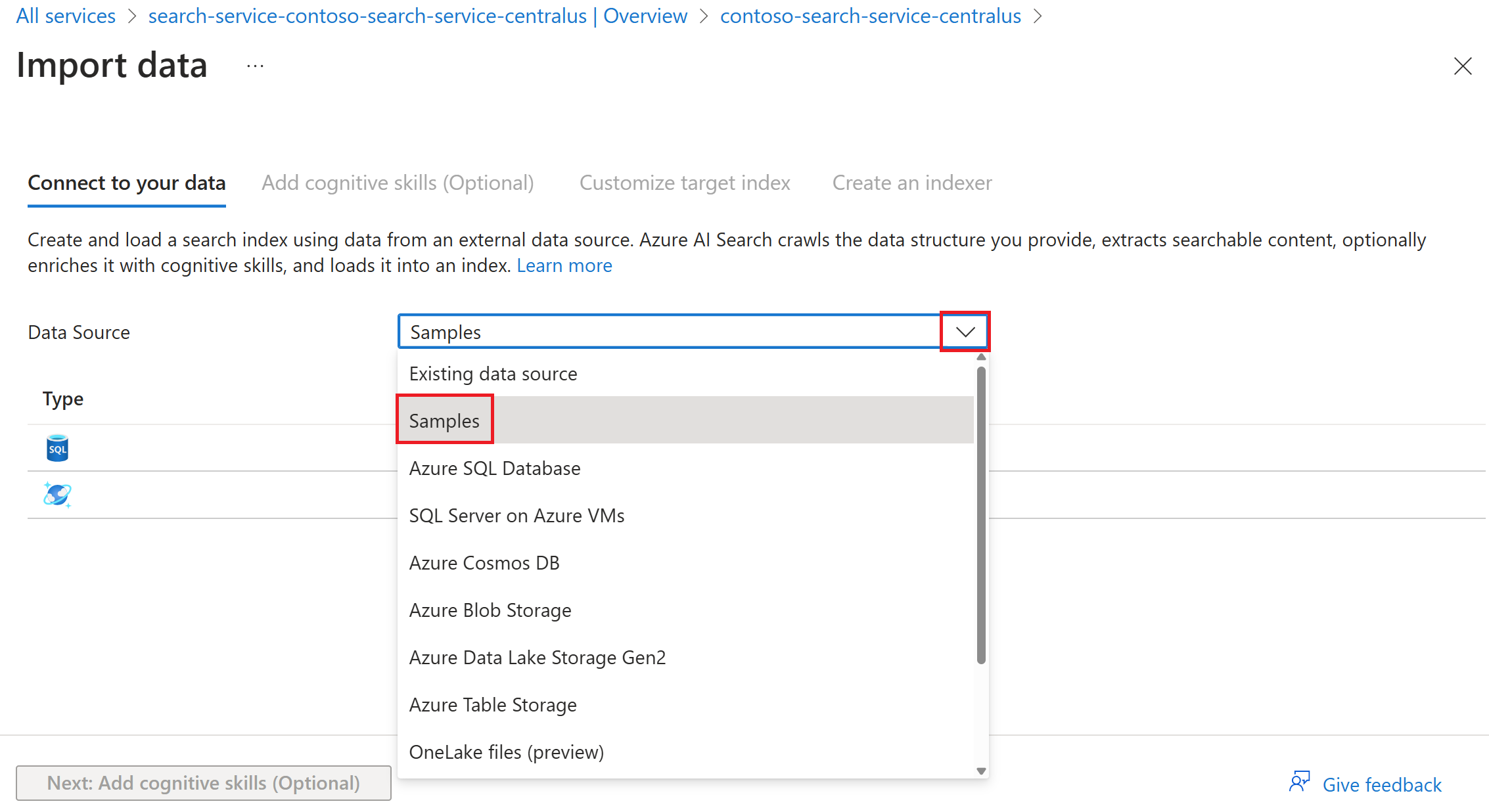
Suivez les étapes restantes de l’Assistant pour créer l’index et l’indexeur.
Vous pouvez aussi lancer l’Importation des données à partir d’autres services Azure, dont Azure Cosmos DB, Azure SQL Database, SQL Managed Instance et le Stockage Blob Azure. Recherchez Ajouter Azure AI Search dans le volet de navigation de gauche de la page de présentation du service.
Configuration de la source de données dans l’Assistant
L’Assistant se connecte à une source de données externe prise en charge en utilisant la logique interne fournie par les indexeurs Recherche Azure AI, qui sont capables d’échantillonner la source, lire les métadonnées, décrypter les documents pour en lire le contenu et la structure, et sérialiser le contenu sous forme de JSON pour une importation ultérieure dans Recherche Azure AI.
Vous pouvez coller une connexion à une source de données prise en charge dans un autre abonnement ou région, mais le sélecteur Choisir une connexion existante est limité à l’abonnement actif.
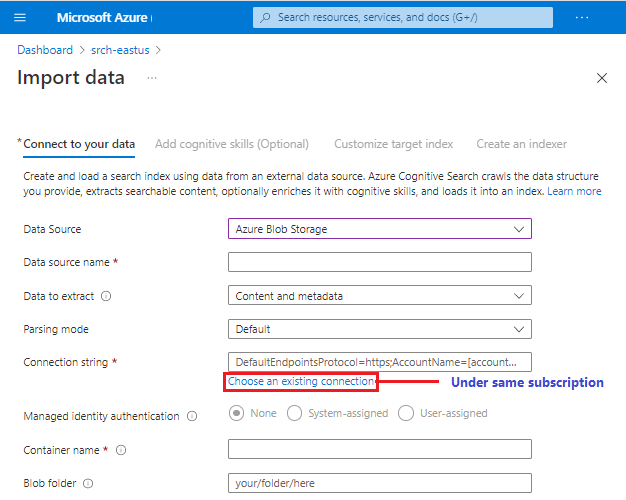
Il n’est pas garanti que toutes les sources de données en préversion soient disponibles dans l’Assistant. Étant donné que chaque source de données est susceptible d’introduire d’autres modifications en aval, une source de données en préversion sera uniquement ajoutée à la liste des sources de données si elle prend entièrement en charge toutes les expériences de l’Assistant, telles que la définition des compétences et l’inférence du schéma d’index.
Vous ne pouvez importer des données qu’à partir d’une seule table, d’une vue de base de données ou d’une structure de données équivalente, mais la structure peut inclure des sous-structures hiérarchiques ou imbriquées. Pour plus d’informations, consultez How to model complex types (Modélisation des types complexes).
Configuration de l’ensemble de compétences dans l’Assistant
La configuration de l’ensemble de compétences se produit après la définition de la source de données, car le type de source de données informe sur la disponibilité de certaines compétences intégrées. En particulier, si vous indexez des fichiers à partir de Stockage Blob, le mode d’analyse choisi pour ces fichiers détermine si l’analyse des sentiments est disponible.
L’Assistant ajoute les compétences que vous choisissez. Il ajoute également d’autres compétences nécessaires pour un résultat fructueux. Par exemple, si vous spécifiez une base de connaissances, l’Assistant ajoute une compétence Modélisateur pour prendre en charge les projections (ou les structures de données physiques).
Les ensembles de compétences sont facultatifs et un bouton se trouve au bas de la page pour ignorer si vous ne souhaitez pas utiliser l’enrichissement par IA.
Configuration du schéma d’index dans l’Assistant
Les Assistants échantillonnent votre source de données pour détecter les champs et le type de champ. En fonction de la source de données, il peut également proposer des champs pour l’indexation des métadonnées.
Étant donné que l’échantillonnage est un exercice imprécis, passez l’index en revue pour tenir compte des points suivants :
La liste des champs est-elle exacte ? Si votre source de données contient des champs qui n’ont pas été sélectionnés dans l’échantillonnage, vous pouvez ajouter manuellement tous les nouveaux champs que l’échantillonnage a manqués, et supprimer ceux qui n’ajoutent pas de valeur à une expérience de recherche ou qui ne seront pas utilisés dans une expression de filtre ou un profil de scoring.
Le type de données convient-il pour les données entrantes ? Azure AI Search prend en charge les types de données EDM (Entity Data Model). Pour les données Azure SQL, il existe un tableau de mappages qui présente les valeurs équivalentes. Pour plus d’informations, consultez Mappages et transformations de champs.
Avez-vous un champ qui peut faire office de clé ? Ce champ doit être Edm.string et doit identifier un document de manière unique. Dans le cas des données relationnelles, elles peuvent être mappées à une clé primaire. Pour les objets blob, il peut s’agir de
metadata-storage-path. Si des valeurs de champ comportent des espaces ou des tirets, vous devez définir l’option Clé d’encodage en base-64 dans l’étape Créer un indexeur, sous Options avancées, pour supprimer le vérification de la validation pour ces caractères.Définissez des attributs pour déterminer comment ce champ est utilisé dans un index.
Prenez votre temps dans cette étape, car les attributs déterminent l’expression physique des champs dans l’index. Si, par la suite, vous souhaitez modifier des attributs, même par programmation, vous devrez presque toujours supprimer et regénérer l’index. Les attributs de base comme Pouvant faire l’objet d’une recherche et Récupérable ont un impact négligeable sur le stockage. L’activation de filtres et l’utilisation de suggesteurs augmentent les besoins de stockage.
Possibilité de recherche permet une recherche en texte intégral. Chaque champ utilisé dans les requêtes de forme libre ou dans les expressions de requête doit avoir cet attribut. Les index inversés sont créés pour chaque champ que vous marquez comme Possibilité de recherche.
Récupérable retourne le champ dans les résultats de la recherche. Chaque champ qui fournit du contenu aux résultats de recherche doit avoir cet attribut. La définition de ce champ n’a pas d’incidence notable sur la taille de l’index.
Filtrable permet de référencer le champ dans les expressions de filtre. Chaque champ utilisé dans une expression $filter doit avoir cet attribut. Les expressions de filtre sont des correspondances exactes. Les chaînes de texte demeurant intactes, un stockage supplémentaire est nécessaire pour recevoir le contenu textuel.
À choix multiples active le champ pour la navigation par facettes. Seuls les champs également marqués comme Filtrables peuvent être marqués comme À choix multiples.
Triable permet d’utiliser le champ dans un tri. Chaque champ utilisé dans une expression $Orderby doit avoir cet attribut.
Avez-vous besoin d’une analyse lexicale ? Pour les champs Edm.string de type Searchable, vous pouvez définir un analyseur si vous voulez des fonctions d’indexation et d’interrogation qui offrent une prise en charge linguistique améliorée.
La valeur par défaut est Standard Lucene, mais vous pouvez choisir Microsoft Anglais si vous souhaitez utiliser l’analyseur de Microsoft pour le traitement lexical avancé, tel que la résolution des formes verbales et nominales irrégulières. Seuls des analyseurs linguistiques peuvent être spécifiés sur le portail Azure. Si vous utilisez un analyseur personnalisé ou un analyseur non linguistique comme par mot clé, modèle, etc., vous devez le créer par programmation. Pour plus d’informations sur les analyseurs, consultez Ajouter des analyseurs linguistiques.
Avez-vous besoin de fonctionnalités TypeAhead matérialisées par la saisie semi-automatique ou les suggestions de résultats ? Cochez la case Suggesteur pour activer les suggestions de requête TypeAhead et la saisie semi-automatique sur les champs sélectionnés. Les suggesteurs s’ajoutent au nombre de termes tokenisés de votre index et occupent donc davantage d’espace de stockage.
Configuration de l’indexeur dans l’Assistant
La dernière page de l’Assistant collecte les entrées utilisateur pour la configuration de l’indexeur. Vous pouvez spécifier un calendrier et définir d’autres options qui varient selon le type de source de données.
En interne, l’Assistant configure également les définitions suivantes, qui ne sont pas visibles dans l’indexeur tant qu’il n’a pas été créé :
- mappages de champs entre la source de données et l’index
- mappages de champs de sortie entre la sortie de compétence et un index
Essayer les Assistants
La meilleure façon de comprendre les avantages et les limitations de l’Assistant est de le parcourir pas à pas. Voici quelques guides de démarrage rapide basés sur l’Assistant.