Indexer des données à partir de bibliothèques de documents SharePoint
Important
La prise en charge de l’indexeur SharePoint Online est en préversion publique. Il est proposé « tel quel », sous Conditions d’utilisation supplémentaires et n’est pris en charge que dans la mesure du possible. Les fonctionnalités d’évaluation ne sont pas recommandées pour les charges de travail de production et il n’est pas garanti qu’elles passent en disponibilité générale.
Veillez à consulter la section limitations connues avant de commencer.
Pour utiliser cette préversion, remplissez ce formulaire. Vous ne recevrez pas de notification d’approbation immédiatement après, car toute requête d’accès est automatiquement acceptée après avoir été soumise. Une fois l’accès activé, utilisez une préversion de l’API REST pour indexer votre contenu.
Cet article explique comment configurer un indexeur de recherche pour indexer les documents stockés dans les bibliothèques de documents SharePoint pour la recherche en texte intégral dans Azure AI Recherche. Les étapes de configuration sont les premières, suivies par les comportements et les scénarios
Fonctionnalités
Dans Azure AI Recherche, un indexeur est un analyseur qui extrait des données et métadonnées pouvant faire l’objet d’une recherche à partir d’une source de données. L’indexeur SharePoint Online se connecte à votre site SharePoint et indexe des documents d’une ou plusieurs bibliothèques de documents. L’indexeur offre les fonctionnalités suivantes :
- Indexez les fichiers et les métadonnées d’une ou de plusieurs bibliothèques de documents.
- Indexez de manière incrémentielle, en ne retenant que les fichiers et métadonnées nouveaux et modifiés.
- La détection des suppressions est intégrée. La suppression dans une bibliothèque de documents est détectée lors du prochain passage de l’indexeur et le document est supprimé de l’index.
- Par défaut, les images texte et normalisées sont extraites des documents qui sont indexés. Si vous le souhaitez, vous pouvez ajouter un ensemble de compétences pour un enrichissement par l’IA plus approfondi , comme l’OCR ou la traduction de texte.
Prérequis
Le service cloud SharePoint dans Microsoft 365
Des fichiers dans une bibliothèque de documents
Formats de document pris en charge
L’indexeur SharePoint Online peut extraire du texte à partir des formats de document suivants :
- CSV (consultez Indexation d’objets blob CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (consultez l’indexation d’objets JSON blobs)
- KML (XML pour les représentations géographiques)
- Formats Microsoft Office : DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (e-mails Outlook), XML (XML WORD 2003 et 2006)
- Formats de document ouverts : ODT, ODS, ODP
- Fichiers de texte brut (voir aussi l’indexation de texte brut)
- RTF
- XML
- ZIP
Limitations et considérations
Voici les limitations de cette fonctionnalité :
L’indexation de listes SharePoint n’est pas prise en charge.
L’indexation du contenu d’un site SharePoint .ASPX n’est pas prise en charge.
Les fichiers de notebook OneNote ne sont pas pris en charge.
Le point de terminaison privé n’est pas pris en charge.
Le changement de nom d’un dossier SharePoint ne déclenche pas d’indexation incrémentielle. Un dossier renommé est traité comme un nouveau contenu.
SharePoint prend en charge un modèle d’autorisation granulaire qui détermine l’accès par utilisateur au niveau du document. L’indexeur ne tire pas ces autorisations dans l’index et Recherche Azure AI ne prend pas en charge l’autorisation au niveau du document. Lorsqu’un document est indexé de SharePoint vers un service de recherche, le contenu est accessible à toute personne disposant d’un accès en lecture à l’index. Si vous avez besoin d’autorisations au niveau du document, envisagez d’utiliser des filtres de sécurité pour réduire les résultats et d’automatiser la copie des autorisations au niveau du fichier dans un champ de l’index.
L’indexation de fichiers chiffrés par l’utilisateur, de fichiers protégés par IRM (Information Rights Management), de fichiers ZIP avec mots de passe ou de contenu chiffré similaire n’est pas prise en charge. Pour que le contenu chiffré soit traité, l’utilisateur disposant des autorisations appropriées pour le fichier spécifique doit supprimer le chiffrement afin que l’élément puisse être indexé en conséquence lorsque l’indexeur exécute l’itération planifiée suivante.
L’indexation récursive de sous-sites à partir d’un site spécifique fourni n’est pas prise en charge.
L’indexeur SharePoint Online n’est pas pris en charge lorsque l’Accès conditionnel Microsoft Entra ID est activé.
Voici les considérations à prendre en compte lors de l’utilisation de cette fonctionnalité :
Si vous devez créer une application Copilot / RAG (génération augmentée de récupération) personnalisée pour discuter avec des données SharePoint, l’approche recommandée consiste à utiliser Microsoft Copilot Studio plutôt que cette fonctionnalité en préversion.
Si vous avez besoin d’une solution d’indexation de contenu SharePoint dans un environnement de production, envisagez de créer un connecteur personnalisé avec des webhooks SharePoint en appelant l’API Microsoft Graph pour exporter les données vers un conteneur d’objets blob Azure, puis utilisez l’indexeur d’objets blob Azure pour l’indexation incrémentielle.
- Si votre configuration SharePoint permet aux processus Microsoft 365 de mettre à jour les métadonnées du système de fichiers SharePoint, sachez que ces mises à jour peuvent déclencher l’indexeur SharePoint Online, ce qui entraîne l’ingestion de documents plusieurs fois. Étant donné que l’indexeur SharePoint Online est un connecteur tiers à Azure, l’indexeur ne peut pas lire la configuration ni varier son comportement. Elle répond aux modifications apportées au contenu nouveau et modifié, quelle que soit la façon dont ces mises à jour sont apportées. Pour cette raison, veillez à tester votre configuration et à comprendre le nombre de documents à traiter avant d’utiliser l’indexeur et tout enrichissement par l’IA.
Configurer l’indexeur SharePoint Online
Pour configurer l’indexeur SharePoint Online, utilisez le Portail Azure et une API REST en préversion. Vous pouvez utiliser la version 2020-06-30-preview ou ultérieure. Nous vous recommandons l’API dans la préversion la plus récente.
Cette section présente les étapes à suivre. Vous pouvez également regarder la vidéo suivante.
Étape 1 (facultatif) : activer l’identité managée affectée par le système
Activez une identité managée affectée par le système pour détecter automatiquement le locataire dans lequel le service de recherche est approvisionné.
Effectuez cette étape si le site SharePoint se trouve dans le même locataire que le service de recherche. Ignorez cette étape si le site SharePoint se trouve dans un autre locataire. L’identité n’est pas utilisée pour l’indexation, juste la détection du locataire. Vous pouvez également ignorer cette étape si vous souhaitez placer l’ID de locataire dans la chaîne de connexion.
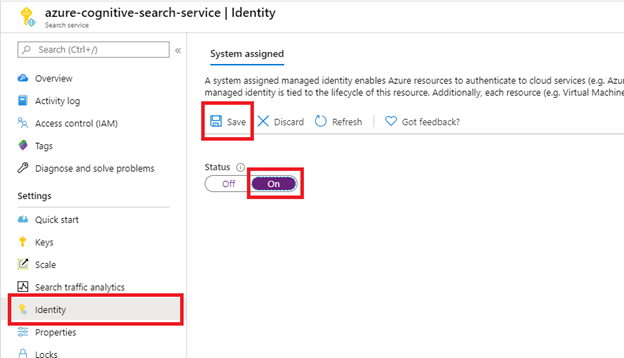
Après avoir sélectionné Enregistrer, vous obtenez un ID d’objet qui a été attribué à votre service de recherche.
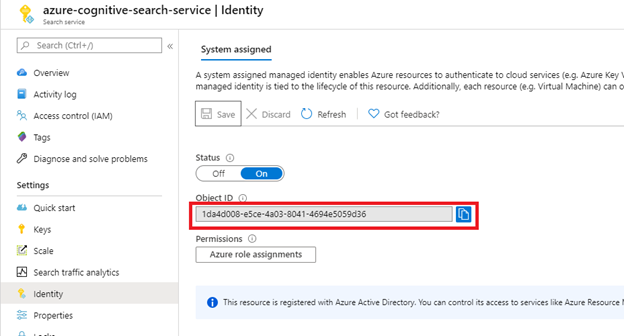
Étape 2 : Déterminer les autorisations requises par l’indexeur
L’indexeur SharePoint Online prend en charge à la fois les autorisations déléguées et d’application. Choisissez les autorisations que vous souhaitez utiliser en fonction de votre scénario.
Nous recommandons les autorisations basées sur l’application. Consultez les limitations pour les problèmes connus liés aux permissions déléguées.
Permissions d’application (recommandé), où l’indexeur fonctionne sous l’identité du locataire SharePoint avec un accès à tous les sites et fichiers. L’indexeur nécessite une clé secrète client. L’indexeur devra également obtenir l’approbation de l’administrateur du locataire avant de pouvoir indexer tout contenu.
Permissions déléguées, où l’indexeur fonctionne sous l’identité de l’utilisateur ou de l’application envoyant la requête. L’accès aux données est limité aux sites et aux fichiers auxquels l’appelant a accès. Pour prendre en charge les autorisations déléguées, l’indexeur a besoin d’une invite de code d’appareil pour se connecter au nom de l’utilisateur. Les permissions déléguées par l’utilisateur appliquent l’expiration des jetons toutes les 75 minutes, conformément aux bibliothèques de sécurité les plus récentes utilisées pour implémenter ce type d’authentification. Ce n’est pas un comportement qui peut être ajusté. Un jeton expiré nécessite l’indexation manuelle à l’aide d’Exécuter l’indexeur (préversion). Pour cette raison, il est préférable d’utiliser des autorisations basées sur l’application.
Étape 3 : créer une inscription d’application Microsoft Entra
L’indexeur SharePoint Online utilise cette application Microsoft Entra pour l’authentification.
Connectez-vous au portail Azure.
Recherchez Microsoft Entra ID ou accédez-y, puis sélectionnez Inscriptions d’applications.
Sélectionnez + Nouvelle inscription :
- Attribuez un nom à votre application.
- Sélectionnez Client unique.
- Ignorez l’étape de désignation de l’URI. Aucun URI de redirection n’est nécessaire.
- Sélectionnez Inscrire.
Sur la gauche, sélectionnez Autorisations d’API, puis Ajouter une autorisation, et enfin Microsoft Graph.
Si l’indexeur utilise des autorisations d’API d’application, sélectionnez Permissions d’application et ajoutez ce qui suit :
- Application – Files.Read.All
- Application – Sites.Read.All

Quand vous utilisez des autorisations d’application, l’indexeur accède au site SharePoint dans un contexte de service. Ainsi, lorsque vous exécutez l’indexeur, il a accès à tout le contenu du locataire SharePoint, ce qui nécessite l’approbation de l’administrateur du locataire. Une clé secrète client est également requise pour l’authentification. La configuration de la clé secrète client est décrite plus loin dans cet article.
Si l’indexeur utilise des autorisations d’API déléguées, sélectionnez Permissions déléguées et ajoutez ce qui suit :
- Delegated - Files.Read.All
- Delegated - Sites.Read.All
- Delegated - User.Read
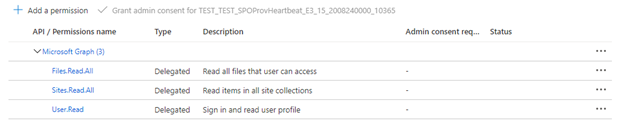
Les permissions déléguées permettent au client de recherche de se connecter à SharePoint sous l’identité de sécurité de l’utilisateur actuel.
Octroyez le consentement administrateur.
Le consentement administrateur du locataire est nécessaire pour utiliser des autorisations d’API d’application. Certains locataires sont verrouillés de telle sorte que le consentement administrateur du locataire est également requis pour les autorisations d’API déléguées. Si l’une de ces conditions s’applique, vous devrez demander à l’administrateur du locataire son consentement pour cette application Microsoft Entra avant de créer l’indexeur.
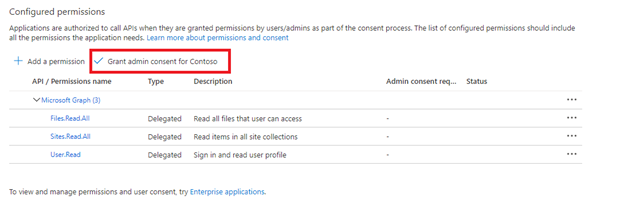
Sélectionnez l’onglet Authentification.
Définissez Autoriser les flux de clients publics sur Oui, puis sélectionnez Enregistrer.
Sélectionnez + Ajouter une plateforme, puis Applications de bureau et mobiles. Sélectionnez
https://login.microsoftonline.com/common/oauth2/nativeclient, puis Configurer.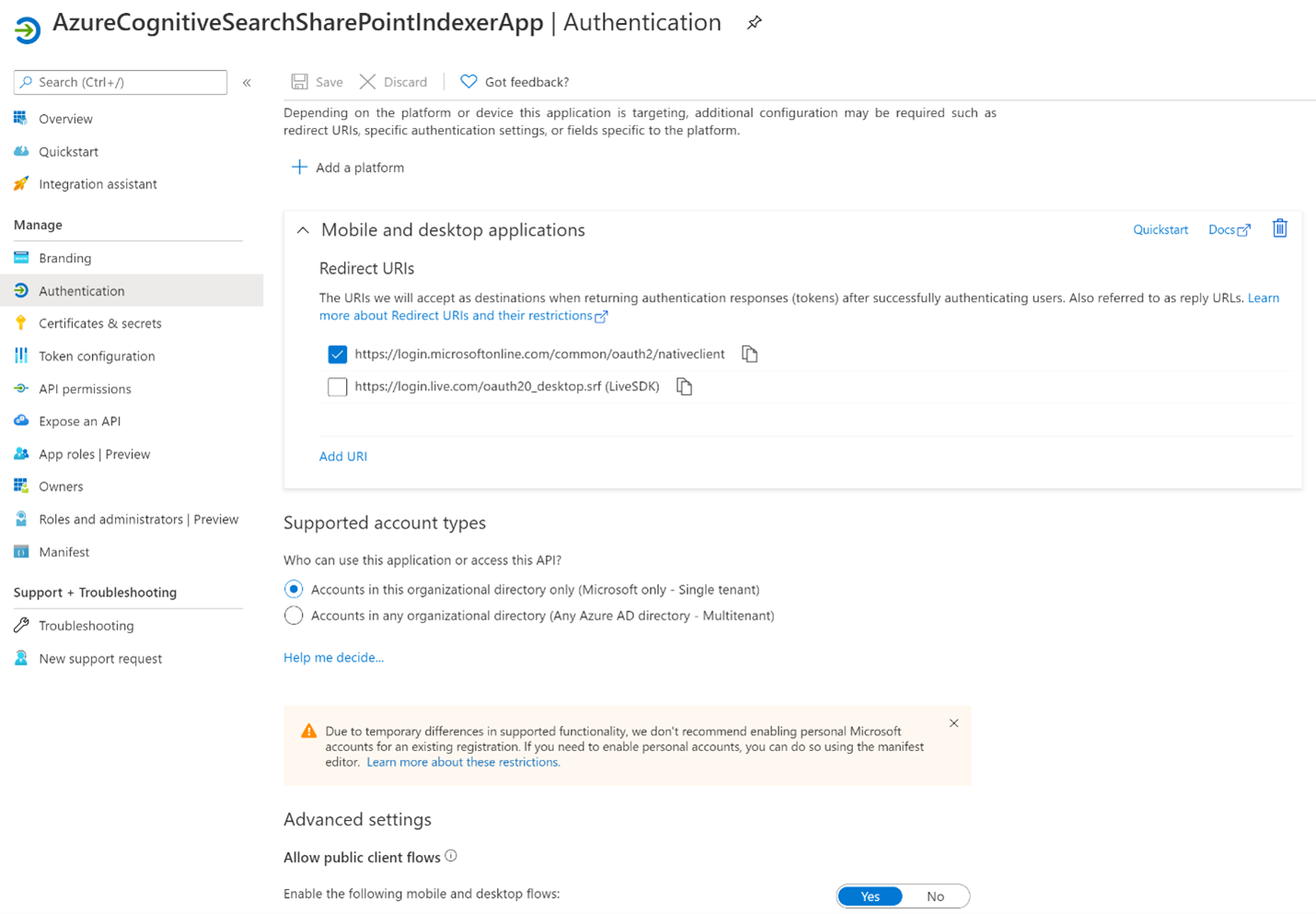
(Autorisations d’API d’application uniquement) Pour s’authentifier auprès de l’application Microsoft Entra à l’aide des permissions d’application, l’indexeur nécessite une clé secrète client.
Sélectionnez Certificats et secrets dans le menu de gauche, puis Clés secrètes client, puis Nouvelle clé secrète client.

Dans le menu qui s’affiche, entrez une description de la nouvelle clé secrète client. Ajustez la date d’expiration le cas échéant. Si le secret expire, il doit être recréé et l’indexeur doit être mis à jour avec le nouveau secret.
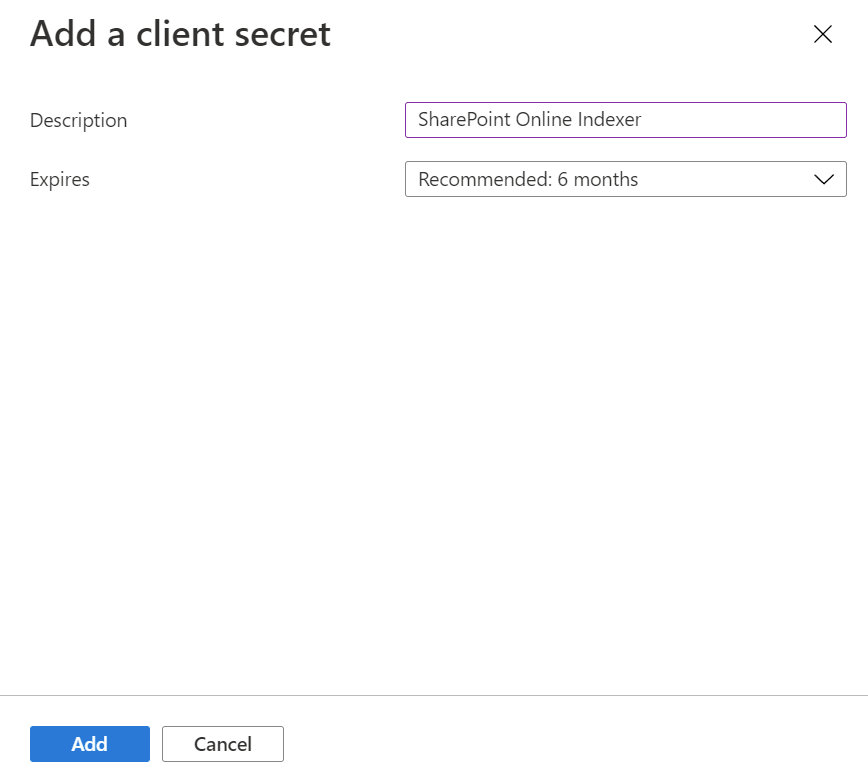
La nouvelle clé secrète client apparaît dans la liste des secrets. Dès que vous quittez la page, le secret n’est plus visible. Copiez-le donc à l’aide du bouton de copie et enregistrez-le dans un endroit sûr.

Étape 4 : Créer une source de données
À partir de cette section, utilisez l’API REST en préversion pour les étapes restantes. Nous vous recommandons l’API dans la préversion la plus récente.
Une source de données spécifie les données à indexer, les informations d’identification et les stratégies pour identifier efficacement les modifications apportées aux données (comme les lignes nouvelles, modifiées ou supprimées). Une source de données peut être utilisée par plusieurs indexeurs dans le même service de recherche.
Pour l’indexation SharePoint, la source de données doit avoir les propriétés requises suivantes :
- name est le nom unique de la source de données au sein de votre service de recherche.
- Le type doit être « sharepoint ». Cette valeur respecte la casse.
- credentials fournit le point de terminaison SharePoint et l’ID d’application (client) Microsoft Entra.
https://microsoft.sharepoint.com/teams/MySharePointSiteest un exemple de point de terminaison SharePoint. Vous pouvez récupérer le point de terminaison en accédant à la page d’accueil de votre site SharePoint et en copiant l’URL à partir du navigateur. - container spécifie la bibliothèque de documents à indexer. Les propriétés contrôlent quels documents sont indexés.
Pour créer une source de données, appelez Créer une source de données (préversion).
POST https://[service name].search.windows.net/datasources?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-datasource",
"type" : "sharepoint",
"credentials" : { "connectionString" : "[connection-string]" },
"container" : { "name" : "defaultSiteLibrary", "query" : null }
}
Format de la chaîne de connexion
Le format de la chaîne de connexion change selon que l’indexeur utilise des autorisations d’API déléguées ou des autorisations d’API d’application.
Format de la chaîne de connexion pour les autorisations d’API déléguées
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];TenantId=[SharePoint site tenant id]Format de la chaîne de connexion pour les autorisations d’API d’application
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];ApplicationSecret=[Azure AD App client secret];TenantId=[SharePoint site tenant id]
Remarque
Si le site SharePoint se trouve dans le même locataire que le service de recherche et si l’identité managée affectée par le système est activée, il n’est pas nécessaire d’inclure TenantId dans la chaîne de connexion. Si le site SharePoint se trouve dans un locataire différent de celui du service de recherche, TenantId doit être inclus.
Étape 5 : Créer un index
L’index spécifie les champs d’un document, les attributs et d’autres constructions qui façonnent l’expérience de recherche.
Pour créer un index, appelez Créer un index (préversion) :
POST https://[service name].search.windows.net/indexes?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}
Important
Seul metadata_spo_site_library_item_id peut être utilisé en tant que champ clé dans un index rempli par l’indexeur SharePoint Online. Si un champ clé n’existe pas dans la source de données, metadata_spo_site_library_item_id est automatiquement mappé au champ clé.
Étape 6 : Créer un indexeur
Un indexeur connecte une source de données à un index de recherche cible et fournit une planification afin d’automatiser l’actualisation des données. Une fois l’index et la source de données créés, vous pouvez créer l’indexeur.
Si vous utilisez des autorisations déléguées, vous êtes invité au cours de cette étape à vous connecter avec les informations d’identification de l’organisation ayant accès au site SharePoint. Si possible, nous vous recommandons de créer un compte d’utilisateur d’organisation et de donner à ce nouvel utilisateur les autorisations exactes que vous souhaitez attribuer à l’indexeur.
La création de l’indexeur s’effectue en quelques étapes :
Envoyez une requête Créer un indexeur (préversion) :
POST https://[service name].search.windows.net/indexers?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key] { "name" : "sharepoint-indexer", "dataSourceName" : "sharepoint-datasource", "targetIndexName" : "sharepoint-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpg", "dataToExtract": "contentAndMetadata" } }, "schedule" : { }, "fieldMappings" : [ { "sourceFieldName" : "metadata_spo_site_library_item_id", "targetFieldName" : "id", "mappingFunction" : { "name" : "base64Encode" } } ] }Si vous utilisez des autorisations d’application, vous devez attendre que l’exécution initiale soit terminée avant de commencer à interroger votre index. Les instructions suivantes fournies dans cette étape concernent spécifiquement les autorisations déléguées et ne s’appliquent pas aux autorisations d’application.
Lorsque vous créez l’indexeur pour la première fois, la requête Créer un indexeur (préversion) attend que vous terminiez l’étape suivante. Vous devez appeler Obtenir l’état de l’indexeur pour obtenir le lien et entrer votre nouveau code d’appareil.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Si vous n’exécutez pas la commande Obtenir l’état de l’indexeur dans un délai de 10 minutes, le code expire et vous devez recréer la source de données.
Copiez le code de connexion de l’appareil à partir de la réponse d’Obtenir l’état de l’indexeur. La connexion de l’appareil se trouve dans l’« errorMessage ».
{ "lastResult": { "status": "transientFailure", "errorMessage": "To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code <CODE> to authenticate." } }Indiquez le code inclus dans le message d’erreur.
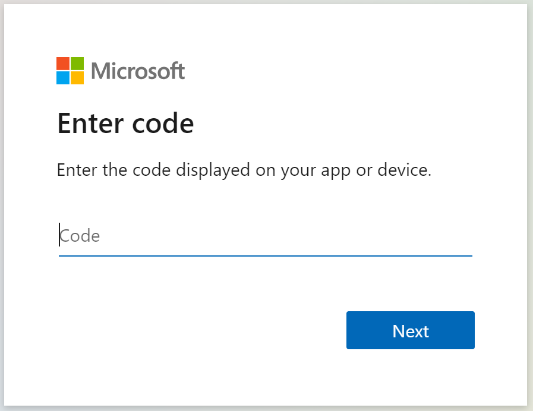
L’indexeur SharePoint Online accède au contenu SharePoint en tant qu’utilisateur connecté. L’utilisateur connecté est celui qui se connecte au cours de cette étape. Ainsi, si vous vous connectez avec un compte d’utilisateur qui n’a pas accès à un document à indexer de la bibliothèque de documents, l’indexeur n’y a pas accès non plus.
Si possible, nous vous recommandons de créer un compte d’utilisateur et de donner à ce nouvel utilisateur les autorisations exactes que vous souhaitez attribuer à l’indexeur.
Approuvez les autorisations demandées.
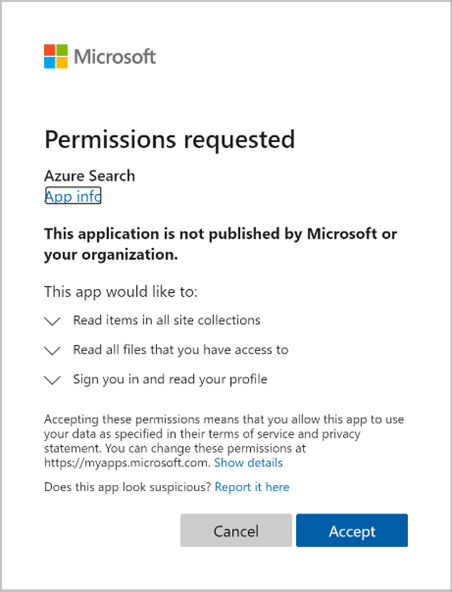
La requête initiale Créer un indexeur (préversion) est exécutée si toutes les autorisations fournies ci-dessus sont correctes et respectent le délai de 10 minutes.
Remarque
Si l’application Microsoft Entra nécessite l’approbation de l’administrateur et qu’elle n’a pas été approuvée avant la connexion, l’écran suivant peut s’afficher. L’approbation de l’administrateur est requise pour continuer.
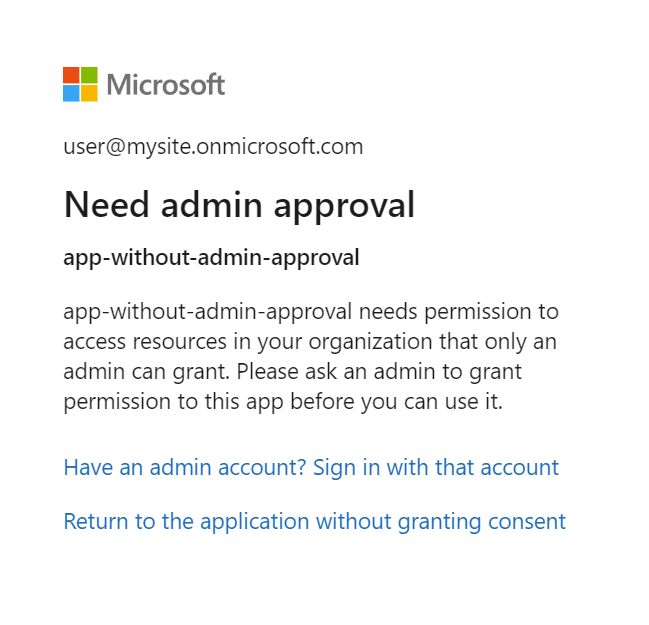
Étape 7 : Vérifier l’état de l’indexeur
Une fois l’indexeur créé, vous pouvez appeler Get Indexer Status :
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
Mise à jour de la source de données
Si l’objet source de données ne fait l’objet d’aucune mise à jour, l’indexeur s’exécute selon une planification sans aucune intervention de l’utilisateur.
Toutefois, si vous modifiez l’objet de source de données alors que le code de l’appareil a expiré, vous devez vous connecter à nouveau pour que l’indexeur puisse s’exécuter. Par exemple, si vous modifiez la requête de la source de données, reconnectez-vous avec https://microsoft.com/devicelogin et obtenez le nouveau code de l’appareil.
Voici les étapes de mise à jour d’une source de données, en supposant qu’un code d’appareil a expiré :
Appelez Exécuter l’indexeur (préversion) pour démarrer manuellement l’exécution de l’indexeur.
POST https://[service name].search.windows.net/indexers/sharepoint-indexer/run?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Vérifiez l’état de l’indexeur.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Si vous recevez une erreur vous demandant de vous rendre sur
https://microsoft.com/devicelogin, ouvrez la page et copiez le nouveau code.Collez le code dans la boîte de dialogue.
Réexécutez manuellement l’indexeur et vérifiez l’état de l’indexeur. Cette fois, l’exécution de l’indexeur doit démarrer correctement.
Indexation des métadonnées de document
Si vous indexez des métadonnées de document ("dataToExtract": "contentAndMetadata"), les métadonnées suivantes sont disponibles pour l’index.
| Identificateur | Type | Description |
|---|---|---|
| metadata_spo_site_library_item_id | Edm.String | Clé combinant l’ID de site, l’ID de bibliothèque et l’ID d’élément, identifiant de façon unique un élément dans une bibliothèque de documents pour un site. |
| metadata_spo_site_id | Edm.String | ID du site SharePoint. |
| metadata_spo_library_id | Edm.String | ID de la bibliothèque de documents. |
| metadata_spo_item_id | Edm.String | ID de l’élément (document) de la bibliothèque. |
| metadata_spo_item_last_modified | Edm.DateTimeOffset | Date/heure (UTC) de la dernière modification de l’élément. |
| metadata_spo_item_name | Edm.String | Nom de l'élément. |
| metadata_spo_item_size | Edm.Int64 | Taille (en octets) de l’élément. |
| metadata_spo_item_content_type | Edm.String | Type de contenu de l’élément. |
| metadata_spo_item_extension | Edm.String | Extension de l’élément. |
| metadata_spo_item_weburi | Edm.String | URI de l’élément. |
| metadata_spo_item_path | Edm.String | Combinaison du chemin parent et du nom de l’élément. |
L’indexeur SharePoint Online prend également en charge les métadonnées spécifiques à chaque type de document. Pour plus d’informations, consultez Propriétés des métadonnées de contenu utilisées dans Azure AI Recherche.
Remarque
Pour indexer des métadonnées personnalisées, « additionalColumns » doit être spécifié dans le paramètre de requête de la source de données.
Inclure ou exclure par type de fichier
Vous pouvez contrôler les fichiers qui sont indexés en définissant des critères d’inclusion et d’exclusion dans la section « parameters » de la définition de l’indexeur.
Incluez des extensions de fichiers spécifiques en définissant "indexedFileNameExtensions" sur une liste d’extensions de fichier séparées par des virgules (avec un point au début). Excluez des extensions de fichiers spécifiques en définissant "excludedFileNameExtensions" sur les extensions qui doivent être ignorées. Si la même extension figure dans les deux listes, elle est exclue de l’indexation.
PUT /indexers/[indexer name]?api-version=2024-05-01-preview
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Contrôle des documents indexés
Un seul indexeur SharePoint Online peut indexer du contenu à partir d’une ou plusieurs bibliothèques de documents. Utilisez le paramètre « container » de la définition de la source de données pour indiquer les sites et les bibliothèques de documents à indexer.
La section « container » de la source de données a deux propriétés pour cette tâche :« name » et « query ».
Nom
La propriété « name » est obligatoire et doit avoir l’une des trois valeurs suivantes :
| Valeur | Description |
|---|---|
| defaultSiteLibrary | Indexe tout le contenu de la bibliothèque de documents par défaut d’un site. |
| allSiteLibraries | Indexe tout le contenu de toutes les bibliothèques de documents d’un site. Les bibliothèques de documents d’un sous-site ne sont pas comprises dans l’étendue. Si vous avez besoin de contenu provenant de sous-sites, choisissez « useQuery » et spécifiez « includeLibrariesInSite ». |
| useQuery | Seul le contenu défini dans la propriété « query » est indexé. |
Requête
Le paramètre « query » de la source de données est constitué de paires mot clé/valeur. Les mots clés qui peuvent être utilisés sont indiqués ci-après. Les valeurs sont des URL de site ou de bibliothèque de documents.
Remarque
Pour obtenir la valeur d’un mot clé particulier, nous vous recommandons d’accéder à la bibliothèque de documents que vous essayez d’inclure/d’exclure et de copier l’URI à partir du navigateur. Il s’agit du moyen le plus simple d’obtenir la valeur à utiliser avec un mot clé dans la requête.
| Mot clé | Description de la valeur et exemples |
|---|---|
| null | Si la valeur est Null ou vide, indexe la bibliothèque de documents par défaut ou toutes les bibliothèques de documents selon le nom du conteneur. Exemple : "container" : { "name" : "defaultSiteLibrary", "query" : null } |
| includeLibrariesInSite | Indexe le contenu de toutes les bibliothèques du site spécifié dans la chaîne de connexion. La valeur doit être l’URI du site web ou du sous-site. Exemple 1 : "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/mysite" } Exemple 2 (inclure quelques sous-sites uniquement) : "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite1;includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite2" } |
| includeLibrary | Indexe tout le contenu de cette bibliothèque. La valeur est le chemin complet de la bibliothèque, que vous pouvez copier à partir de votre navigateur : Exemple 1 (chemin complet) : "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary" } Exemple 2 (URI copié à partir de votre navigateur) : "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| excludeLibrary | N’indexe pas le contenu de cette bibliothèque. La valeur est le chemin complet de la bibliothèque, que vous pouvez copier à partir de votre navigateur : Exemple 1 (chemin complet) : "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mysite.sharepoint.com/subsite1; excludeLibrary=https://mysite.sharepoint.com/subsite1/MyDocumentLibrary" } Exemple 2 (URI copié à partir de votre navigateur) : "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/teams/mysite; excludeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| additionalColumns | Indexe les colonnes de la bibliothèque de documents. La valeur est une liste de noms de colonnes séparés par des virgules que vous souhaitez indexer. Utilisez une double barre oblique inverse pour échapper des points-virgules et des virgules dans les noms de colonne : Exemple 1 (additionalColumns=MyCustomColumn,MyCustomColumn2) : "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary;additionalColumns=MyCustomColumn,MyCustomColumn2" } Exemple 2 (caractère d’échappement utilisant une double barre oblique inverse) : "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx;additionalColumns=MyCustomColumnWith\\,,MyCustomColumnWith\\;" } |
Gestion des erreurs
Par défaut, l’indexeur SharePoint Online s’arrête dès qu’il rencontre un document avec un type de contenu non pris en charge (par exemple, une image). Vous pouvez utiliser le paramètre excludedFileNameExtensions pour ignorer certains types de contenu. Toutefois, vous devrez peut-être indexer des documents sans connaître à l’avance tous les types de contenu possibles. Pour poursuivre l’indexation quand un type de contenu non pris en charge est détecté, définissez le paramètre de configuration failOnUnsupportedContentType sur false :
PUT https://[service name].search.windows.net/indexers/[indexer name]?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
... other parts of indexer definition
"parameters" : { "configuration" : { "failOnUnsupportedContentType" : false } }
}
Pour certains documents, Azure AI Recherche ne parvient pas à déterminer le type de contenu ou à traiter un document avec un autre type de contenu pris en charge. Pour ignorer ce mode d’échec, définissez le paramètre de configuration failOnUnprocessableDocument sur false :
"parameters" : { "configuration" : { "failOnUnprocessableDocument" : false } }
Azure AI Recherche limite la taille des documents indexés. Ces limites sont documentées dans Limites de service dans Azure AI Recherche. Par défaut, les documents surdimensionnés sont traités comme des erreurs. Toutefois, vous pouvez toujours indexer des métadonnées de stockage de documents surdimensionnés en définissant le paramètre de configuration indexStorageMetadataOnlyForOversizedDocuments sur true :
"parameters" : { "configuration" : { "indexStorageMetadataOnlyForOversizedDocuments" : true } }
Vous pouvez également poursuivre l’indexation si des erreurs se produisent à tout moment du traitement, que ce soit durant l’analyse de documents ou l’ajout de documents à un index. Pour ignorer un nombre spécifique d’erreurs, définissez les paramètres de configuration maxFailedItems et maxFailedItemsPerBatch sur les valeurs souhaitées. Par exemple :
{
... other parts of indexer definition
"parameters" : { "maxFailedItems" : 10, "maxFailedItemsPerBatch" : 10 }
}
Si le chiffrement est activé pour un fichier sur le site SharePoint, un message d’erreur similaire au suivant peut être rencontré :
Code: resourceModified Message: The resource has changed since the caller last read it; usually an eTag mismatch Inner error: Code: irmEncryptFailedToFindProtector
Le message d’erreur inclut également l’ID de site SharePoint, l’ID de lecteur et l’ID d’élément de lecteur dans le modèle suivant : <sharepoint site id> :: <drive id> :: <drive item id>. Ces informations peuvent être utilisées pour identifier l’élément qui échoue du côté de SharePoint. L’utilisateur peut ensuite supprimer le chiffrement de l’élément pour résoudre le problème.