Démarrage rapide : créer un ensemble de compétences dans le Portail Azure
Dans ce guide de démarrage rapide, vous découvrez comment un ensemble de compétences dans Recherche Azure AI permet d’ajouter la reconnaissance optique de caractères (OCR), l’analyse d’images, la détection de langue, la traduction de texte et la reconnaissance d’entités pour générer du texte pouvant être recherché dans un index de recherche.
Vous pouvez exécuter l’assistant Importation de données pour appliquer des compétences qui créent et transforment le contenu textuel lors de son indexation. L’entrée constitue vos données brutes, généralement des objets blob dans le stockage Azure. La sortie est un index pouvant faire l’objet d’une recherche contenant du texte, des légendes et des entités générés par l’IA. Le contenu généré est interrogeable dans le portail Azure au moyen de l’Explorateur de recherche.
Pour commencer, vous créez quelques ressources et chargez des exemples de fichiers avant d’exécuter l’assistant.
Prérequis
Compte Azure avec un abonnement actif. Créez un compte gratuitement.
Créez un service Recherche Azure AI ou recherchez un service existant. Vous pouvez utiliser un service gratuit pour ce guide de démarrage rapide.
Compte de stockage Azure avec Stockage Blob Azure.
Remarque
Ce démarrage rapide utilise les Azure AI services pour les transformations de l’IA. Parce que la charge de travail est si petite, les services Azure AI sont exploités en coulisses pour un traitement gratuit jusqu'à 20 transactions. Vous pouvez effectuer cet exercice sans avoir à créer une ressource multiservice Azure AI.
Configurer vos données
Dans les étapes suivantes, configurez un conteneur d’objets blob dans Stockage Azure pour stocker des fichiers de contenu hétérogènes.
Téléchargez les exemples de données consistant en un petit ensemble de fichiers de types différents.
Connectez-vous au portail Azure avec votre compte Azure.
Créez un compte de stockage Azure ou recherchez un compte existant.
Choisissez la même région que celle de la Recherche Azure AI pour éviter des frais de bande passante.
Choisissez le StorageV2 (usage général V2).
Dans le portail Azure, ouvrez votre page Stockage Azure et créez un conteneur. Vous pouvez utiliser le niveau d’accès par défaut.
Dans Conteneur, sélectionnez Charger pour charger les exemples de fichiers. Notez que vous disposez d’un vaste éventail de types de contenu, notamment des images et des fichiers d’application qui ne peuvent pas faire l’objet de recherches en texte intégral dans leurs formats natifs.
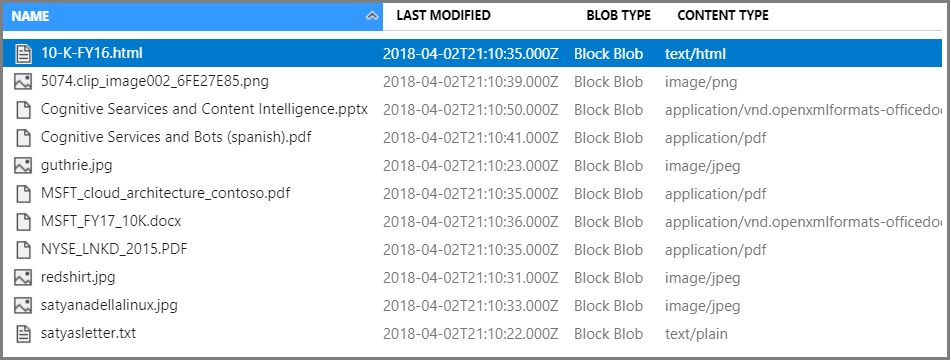
Vous êtes maintenant prêt à passer à l’Assistant Importation de données.
Exécuter l’Assistant Importation de données
Connectez-vous au portail Azure avec votre compte Azure.
Rechercher votre service de recherche. Dans la page Vue d’ensemble, sélectionnez Importer des données dans la barre de commandes pour créer du contenu pouvant être recherché en quatre étapes.
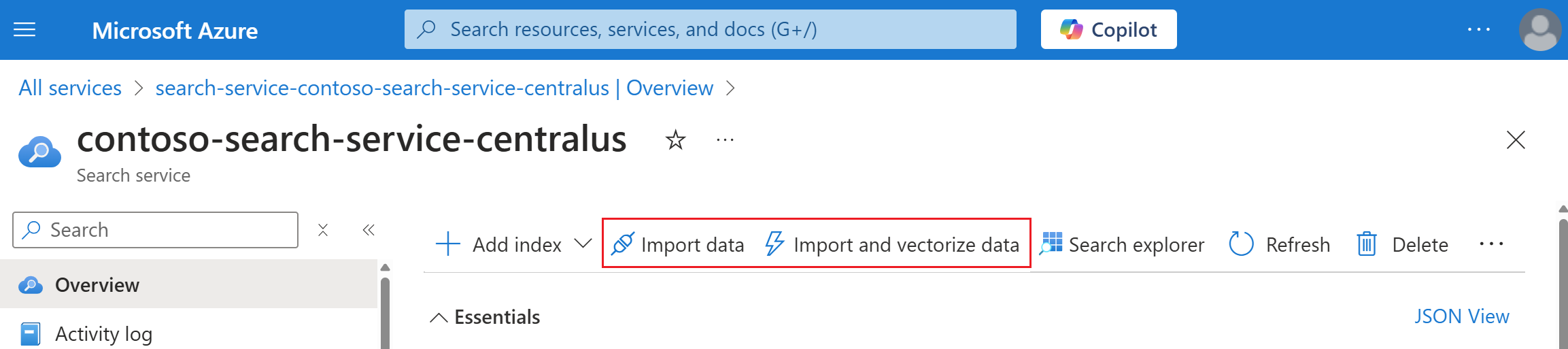
Étape 1 : Création d'une source de données
Dans Connexion à vos données, choisissez Stockage Blob Azure.
Choisissez une connexion existante au compte de stockage et sélectionnez le conteneur que vous avez créé. Donnez un nom à la source de données et utilisez les valeurs par défaut pour le reste.
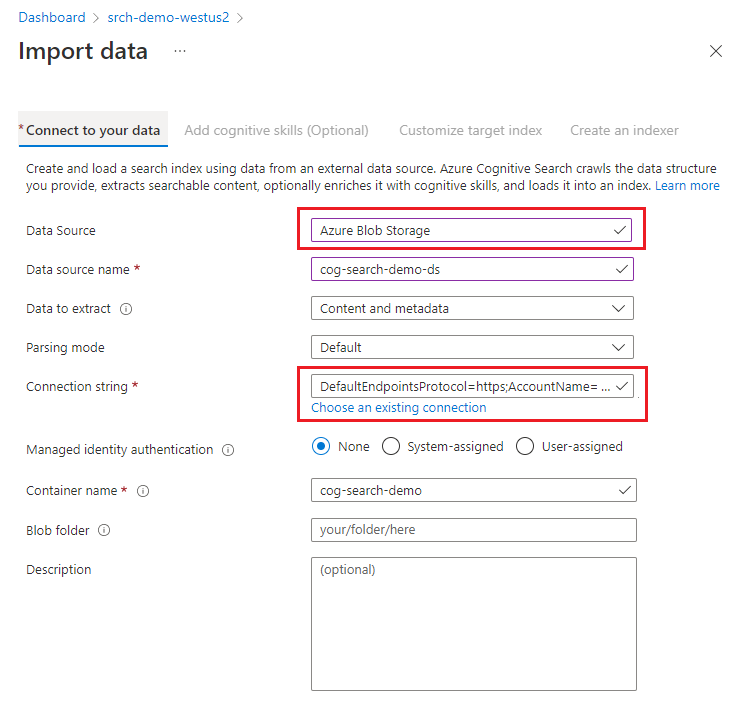
Passez à la page suivante.
Si vous obtenez le message Erreur de détection du schéma d’index à partir d’une source de données, l’indexeur qui alimente l’Assistant ne peut pas se connecter à votre source de données. La source de données dispose très probablement de protections de sécurité. Essayez les solutions suivantes, puis réexécutez l’Assistant.
| Fonctionnalité de sécurité | Solution |
|---|---|
| La ressource nécessite des rôles Azure, ou ses clés d’accès sont désactivées | Se connecter en tant que service approuvé ou se connecter avec une identité managée |
| La ressource se trouve derrière un pare-feu IP | Créer une règle de trafic entrant pour la recherche et pour le portail Azure |
| La ressource nécessite une connexion de point de terminaison privé | Se connecter par un point de terminaison privé |
Étape 2 : Ajouter des compétences cognitives
Ensuite, configurez l’enrichissement par IA pour appeler l’OCR, l’analyse des images et le traitement en langage naturel.
L’OCR et l’analyse d’image sont disponibles pour les objets blob dans Azure Blob Storage et Azure Data Lake Storage (ADLS) Gen2, ainsi que pour le contenu d’image dans OneLake. Les images peuvent être des fichiers autonomes ou des images intégrées dans un PDF ou d'autres fichiers.
Pour ce démarrage rapide, nous utilisons la ressource de services Azure AI gratuits. Les exemples de données se composent de 14 fichiers, donc l’attribution gratuite de 20 transactions sur Azure AI services est suffisante pour ce guide de démarrage rapide.
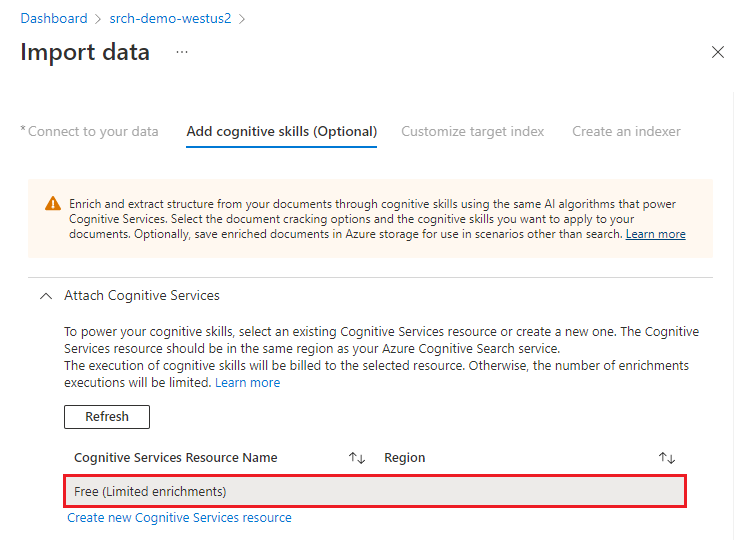
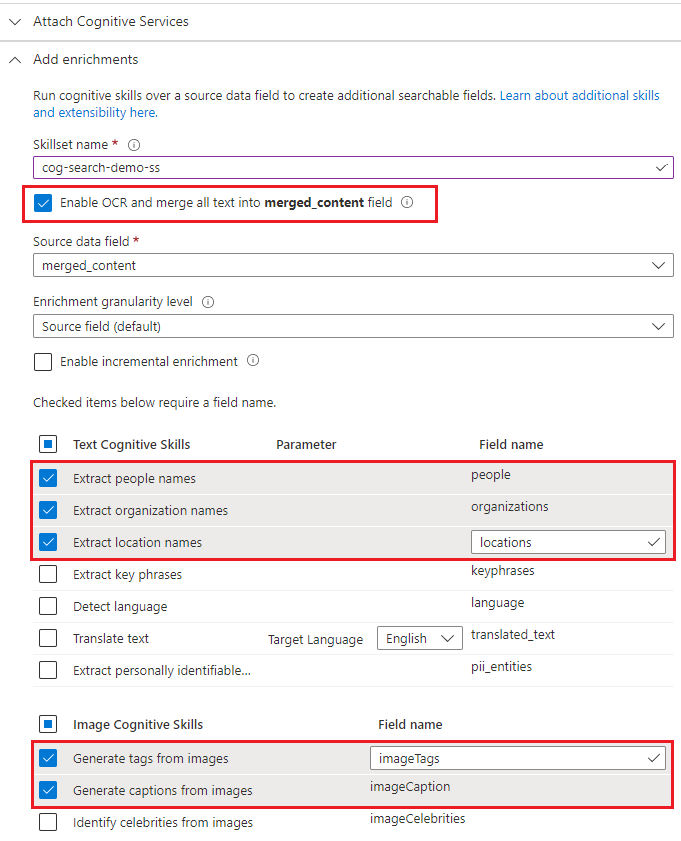
Développez Ajouter des enrichissements et effectuez six sélections.
Activez l’OCR pour ajouter des compétences d’analyse d’images à la page de l’Assistant.
Choisissez des compétences de reconnaissance d’entité (personnes, organisations, emplacements) et d’analyse d’image (étiquettes, légendes).
Passez à la page suivante.
Étape 3 : Configurer l’index
Un index contient votre contenu pouvant faire l’objet de recherches. L’Assistant d’Importation de données peut généralement créer le schéma en échantillonnant la source de données. Au cours de cette étape, examinez le schéma généré, puis modifiez éventuellement les paramètres.
Pour ce guide de démarrage rapide, l’Assistant effectue un travail de qualité en termes de définition de valeurs par défaut raisonnables :
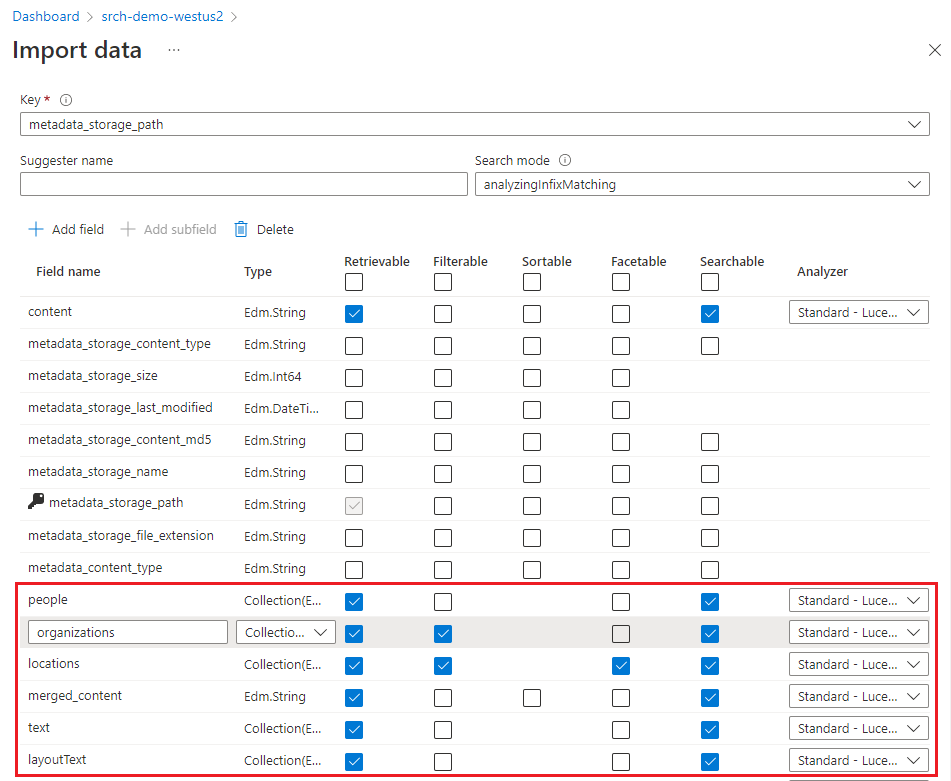
Les champs par défaut sont fonction des propriétés de métadonnées des objets blob existants, ainsi que sur les nouveaux champs destinés de la sortie d’enrichissement (par exemple,
people,organizations,locations). Les types de données sont déduits à partir des métadonnées et des échantillonnages de données.La clé de document par défaut est metadata_storage_path (ce champ est sélectionné, car il contient des valeurs uniques).
Les attributs par défaut sont Récupérable et PossibilitéRecherche. PossibilitéRecherche permet la recherche en texte intégral dans un champ. Récupérable signifie que les valeurs des champs peuvent être retournées dans les résultats. L’Assistant suppose que vous souhaitez ces champs récupérables et interrogeables, car vous les avez créés par l’intermédiaire de compétences. Sélectionnez Filtrable si vous souhaitez utiliser des champs dans une expression de filtre.
Marquer un champ comme étant Récupérable ne signifie pas que le champ doit être présent dans les résultats de recherche. Vous pouvez contrôler la composition des résultats de recherche à l’aide du paramètre de requête sélectionner pour spécifier les champs à inclure.
Passez à la page suivante.
Étape 4 : Configurer l’indexeur
L’indexeur mène le processus d’indexation. Il spécifie le nom de la source de données, un index cible et la fréquence d’exécution. L’assistant Importation de données crée plusieurs objets, dont un indexeur que vous pouvez réinitialiser et exécuter à plusieurs reprises.
Dans la page Indexeur, acceptez le nom par défaut et sélectionnez Une fois.
Sélectionnez Envoyer pour créer et exécuter simultanément l’indexeur.
Superviser l’état
Sélectionnez Indexeurs dans le volet de navigation de gauche pour surveiller l’état, puis sélectionnez l’indexeur. L’indexation en fonction des compétences prend plus de temps que l’indexation textuelle, notamment l’OCR et l’analyse d’image.
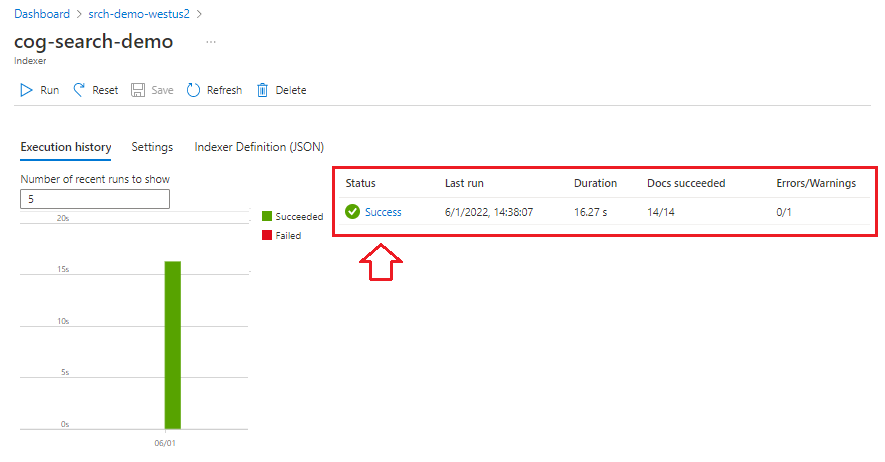
Pour afficher les détails sur l’état de l’exécution, sélectionnez Réussite (ou Échec) pour afficher les détails de l’exécution.
Dans cette démonstration, il y a quelques avertissements : « Impossible d’exécuter la compétence parce qu’une ou plusieurs entrées de compétence ne sont pas valides » Cela vous indique qu’un fichier PNG dans la source de données ne fournit aucune entrée de texte à la reconnaissance d’entités. Cet avertissement apparaît, car la compétence OCR en amont n’a pas reconnu de texte dans l’image, et ne pouvait donc pas fournir d’entrée de texte à la compétence de reconnaissance d’entité en aval.
Les avertissements sont courants dans l’exécution de l’ensemble de compétences. Au fur et à mesure que vous vous familiarisez à la manière dont les compétences sont itérées sur vos données, vous allez commencer à remarquer des modèles et à apprendre quels avertissements vous pouvez ignorer.
Requête dans l’Explorateur de recherche
Après la création d’un index, utilisez le Navigateur de recherche pour retourner des résultats.
Sur la gauche, sélectionnez Index, puis sélectionnez l’index. Le Navigateur de recherche se trouve dans le premier onglet.
Entrez une chaîne de recherche pour interroger l’index, telle que
satya nadella. La barre de recherche accepte les mots clés, les expressions entre guillemets et les opérateurs :"Satya Nadella" +"Bill Gates" +"Steve Ballmer"
Les résultats sont retournés au format JSON détaillé, qui peut être difficile à lire, en particulier dans des documents volumineux. Voici quelques conseils pour effectuer des recherches dans cet outil :
Basculez vers la vue JSON pour spécifier les paramètres de résultats de la forme.
Ajoutez
selectpour limiter les champs dans les résultats.Ajoutez
countpour afficher le nombre de résultats.Utilisez CTRL-F pour rechercher des termes ou des propriétés spécifiques dans les résultats au format JSON.
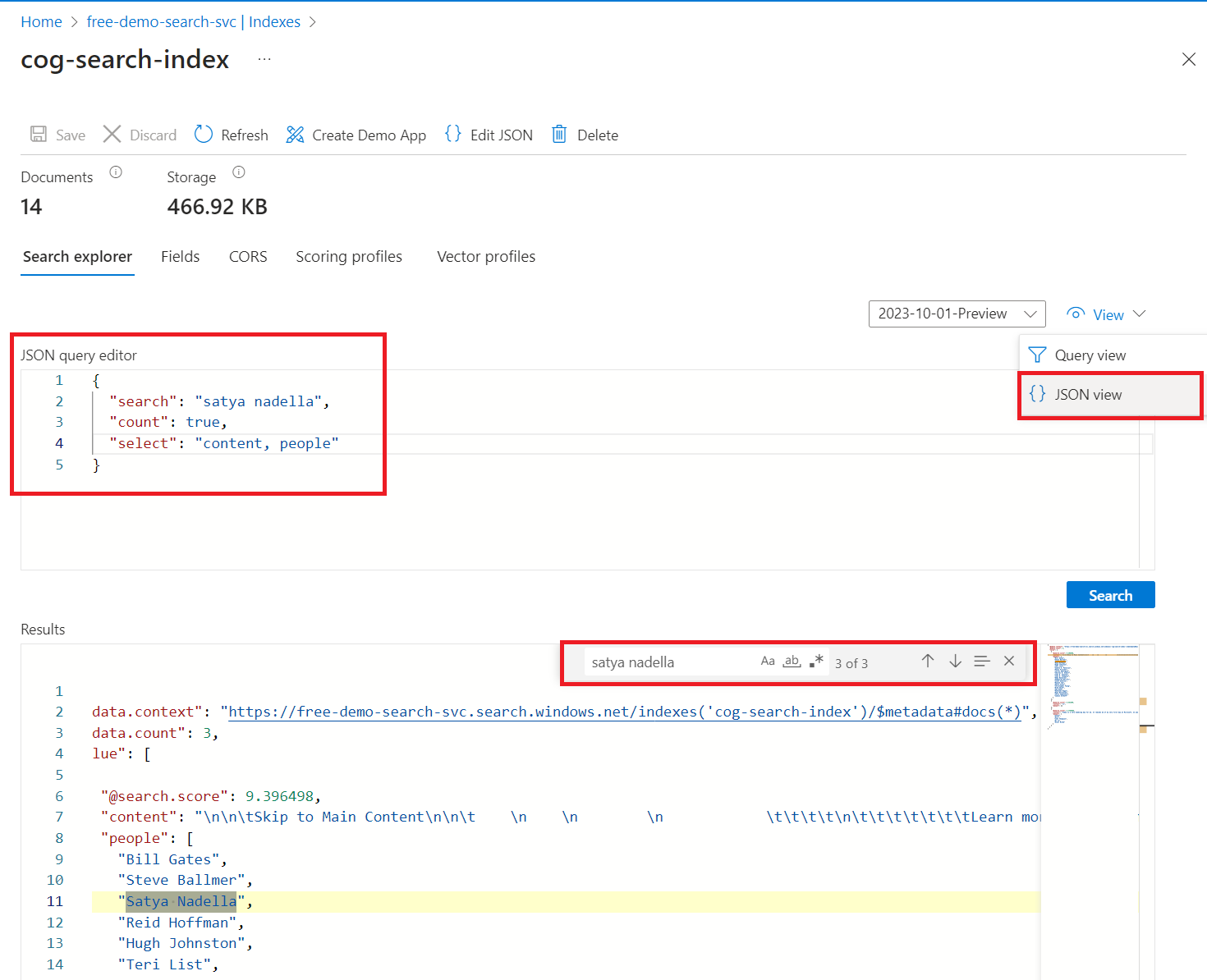
Voici un JSON que vous pouvez coller dans la vue :
{
"search": "\"Satya Nadella\" +\"Bill Gates\" +\"Steve Ballmer\"",
"count": true,
"select": "content, people"
}
Conseil
Les chaînes de requête respectent la casse. Ainsi, si vous recevez un message « champ inconnu », consultez l’onglet Champs ou Définition d’index (JSON) pour vérifier le nom et la casse.
Éléments importants à retenir
Vous avez maintenant créé votre premier ensemble de compétences et appris les étapes de base de l’indexation basée en fonction des compétences.
Parmi les concepts clés que vous avez compris (nous l’espérons), figure la dépendance. Un ensemble de compétences est lié à un indexeur. Les indexeurs sont spécifiques à Azure et à la source. Bien que ce guide de démarrage rapide utilise le Stockage Blob Azure, d’autres sources de données Azure sont possibles. Pour plus d’informations, consultez Indexeurs dans Recherche Azure AI.
Un autre concept important est que les compétences servent sur les types de contenu et que, lors de l’utilisation de contenu hétérogène, certaines entrées sont ignorées. En outre, les fichiers ou les champs volumineux peuvent dépasser les limites d’indexeur de votre niveau de service. Il est normal de voir des avertissements quand ces événements se produisent.
La sortie est acheminée vers un index de recherche. Il existe un mappage entre les paires nom-valeur créées durant l’indexation et les champs individuels de votre index. En interne, l’Assistant configure une arborescence d’enrichissement et définit un ensemble de compétences, en établissant l’ordre des opérations et le flux général. Ces étapes sont masquées dans l’assistant, mais ces concepts deviennent importants lorsque vous démarrez l’écriture de code.
Enfin, vous avez appris que vous pouvez vérifier le contenu en interrogeant l’index. Au final, Recherche Azure AI fournit un index dans lequel il est possible d’effectuer une recherche et que vous pouvez interroger à l’aide de la syntaxe de requête simple ou entièrement étendue. Un index contenant des champs enrichis ressemble à n’importe quel autre index. Vous pouvez intégrer des analyseurs personnalisés ou standard, des profils de scoring, des synonymes, une navigation par facettes, une recherche géographique ou toute autre fonctionnalité de Recherche Azure AI.
Nettoyer les ressources
Lorsque vous travaillez dans votre propre abonnement, il est recommandé, à la fin de chaque projet, de déterminer si vous avez toujours besoin des ressources que vous avez créées. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources individuellement, ou supprimer le groupe de ressources pour supprimer l’ensemble des ressources.
Vous pouvez rechercher et gérer les ressources dans le portail à l’aide des liens Toutes les ressources ou Groupes de ressources situés dans le volet de navigation de gauche.
Si vous avez utilisé un service gratuit, n’oubliez pas que vous êtes limité à trois index, indexeurs et sources de données. Vous pouvez supprimer des éléments un par un sur le portail Azure pour ne pas dépasser la limite.
Étape suivante
Vous pouvez créer des ensembles de compétences à l’aide du portail Azure, du kit SDK .NET ou de l’API REST. Pour approfondir vos connaissances, essayez l’API REST à l’aide d’un client REST et d’autres exemples de données.