RStudio sur Azure Databricks
Vous pouvez utiliser RStudio, un environnement de développement intégré (IDE) populaire pour R, permettant de vous connecter aux ressources de calcul Azure Databricks au sein des espaces de travail Azure Databricks. Utilisez RStudio Desktop pour vous connecter à un cluster Azure Databricks ou à un entrepôt SQL à partir de votre ordinateur de développement local. Vous pouvez également utiliser votre navigateur web pour vous connecter à votre espace de travail Azure Databricks, puis vous connecter à un cluster Azure Databricks sur lequel RStudio Server est installé, dans cet espace de travail.
Se connecter à l’aide de RStudio Desktop
Utilisez RStudio Desktop pour vous connecter à un cluster Azure Databricks ou à un entrepôt SQL distant à partir de votre ordinateur de développement local. Pour vous connecter dans ce scénario, utilisez une connexion ODBC et appeler des fonctions de package ODBC pour R, qui sont décrites dans cette section.
Notes
Vous ne pouvez pas utiliser de packages tels que SparkR ou sparklyr dans ce scénario RStudio Desktop, sauf si vous utilisez également Databricks Connect. Comme alternative à l'utilisation de RStudio Desktop, vous pouvez utiliser votre navigateur web pour vous connecter à votre espace de travail Azure Databricks, puis vous connecter à un cluster Azure Databricks sur lequel RStudio Server est installé dans cet espace de travail.
Pour configurer RStudio Desktop sur votre ordinateur de développement local :
- Téléchargez et installez R 3.3.0 ou une version ultérieure.
- Téléchargez et installez RStudio Desktop.
- Démarrez RStudio Desktop.
(Facultatif) Pour créer un projet RStudio :
- Démarrez RStudio Desktop.
- Cliquez sur Fichier > Nouveau projet.
- Sélectionnez Nouveau répertoire > Nouveau projet.
- Choisissez un nouveau répertoire pour le projet, puis cliquez sur Créer un projet.
Pour créer un script R :
- Une fois le projet ouvert, cliquez sur Fichier > Nouveau fichier > Script R.
- Cliquez sur Fichier > Enregistrer sous.
- Nommez le fichier, puis cliquez sur Enregistrer.
Pour vous connecter au cluster Azure Databricks ou à l’entrepôt SQL distant via ODBC pour R :
Obtenez le Nom d’hôte du serveur, le Port et les valeurs de Chemin d'accès HTTP pour votre cluster distant ou votre entrepôt SQL. Pour un cluster, ces valeurs se trouvent sous l’onglet JDBC/ODBC des Options avancées. Pour un entrepôt SQL, ces valeurs se trouvent sous l’onglet Détails de la connexion.
Obtenez un jeton d’accès personnel Azure Databricks.
Notes
En guise de bonne pratique de sécurité, quand vous vous authentifiez avec des outils, systèmes, scripts et applications automatisés, Databricks recommande d’utiliser des jetons d’accès personnels appartenant à des principaux de service et non des utilisateurs de l’espace de travail. Pour créer des jetons d’accès pour des principaux de service, consultez la section Gérer les jetons pour un principal de service.
Installez et configurez le pilote ODBC Databricks pour Windows, macOS ou Linux, en fonction du système d’exploitation de votre ordinateur local.
Configurez un nom de source de données ODBC (DSN) sur votre cluster ou votre entrepôt SQL distant pour Windows, macOS ou Linux, en fonction du système d’exploitation de votre ordinateur local.
À partir de la console RStudio (Afficher > Déplacer le focus sur la console), installez les packages ODBC et DBI à partir de CRAN :
require(devtools) install_version( package = "odbc", repos = "http://cran.us.r-project.org" ) install_version( package = "DBI", repos = "http://cran.us.r-project.org" )De retour dans votre script R (Afficher > Déplacer le focus sur la source), chargez les packages
odbcetDBIinstallés :library(odbc) library(DBI)Appelez la version ODBC de la fonction dbConnect dans le package
DBI, en spécifiant le piloteodbcdans le packageodbc, ainsi que le DSN ODBC que vous avez créé, par exemple, un DSN ODBC deDatabricks.conn = dbConnect( drv = odbc(), dsn = "Databricks" )Appelez une opération via le DSN ODBC, par exemple une instruction
SELECTvia la fonction dbGetQuery dans le packageDBI, en spécifiant le nom de la variable de connexion et l’instructionSELECTelle-même, par exemple à partir d’une table nomméediamondsdans un schéma (base de données) nommédefault:print(dbGetQuery(conn, "SELECT * FROM default.diamonds LIMIT 2"))
Le script R complet est le suivant :
library(odbc)
library(DBI)
conn = dbConnect(
drv = odbc(),
dsn = "Databricks"
)
print(dbGetQuery(conn, "SELECT * FROM default.diamonds LIMIT 2"))
Pour exécuter le script, en mode source, cliquez sur Source. Les résultats du script R précédent sont les suivants :
_c0 carat cut color clarity depth table price x y z
1 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
Se connecter à un RStudio Server hébergé par Databricks
Important
Le serveur RStudio hébergé par Databricks est déprécié et n’est disponible que sur databricks Runtime versions 15.4 et antérieures. Pour plus d’informations, consultez Dépréciation de RStudio Server hébergé.
Utilisez votre navigateur Web pour vous connecter à votre espace de travail Azure Databricks, puis vous connecter à une capacité de calcul Azure Databricks sur laquelle RStudio Server est installé dans cet espace de travail.
Pour plus d’informations, consultez Se connecter à un RStudio Server hébergé par Databricks
Architecture d'intégration RStudio
Lorsque vous utilisez RStudio Server sur Azure Databricks, le démon RStudio Server s’exécute sur le nœud de pilote d’un cluster Azure Databricks. L’interface utilisateur web RStudio est transmise par proxy via webapp Azure Databricks, ce qui signifie que vous n’avez pas besoin d’apporter de modifications à la configuration réseau de votre cluster. Ce diagramme illustre l’architecture du composant d’intégration RStudio.
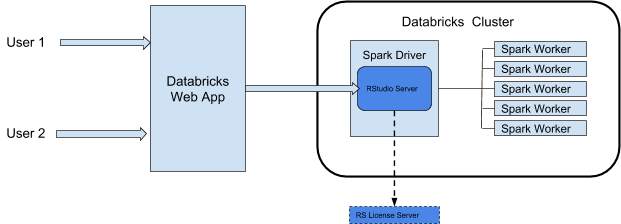
Avertissement
Azure Databricks transmet le service web RStudio à partir du port 8787 sur le pilote Spark du cluster. Ce proxy web est destiné à être utilisé uniquement avec RStudio. Si vous lancez d’autres services web sur le port 8787, vous pouvez exposer vos utilisateurs à de potentielles failles de sécurité. Ni Databricks ni Microsoft ne sont responsables des problèmes résultant de l’installation de logiciels non pris en charge sur un cluster.
Spécifications
Le cluster doit être un cluster polyvalent.
Vous devez avoir l’autorisation PEUT ATTACHER À pour ce cluster. L’administrateur de cluster peut vous accorder cette autorisation. Voir Autorisations de calcul.
Le cluster ne doit pas avoir le contrôle d’accès à la table, l’arrêt automatique ou le relais des informations d’identification activé.
Le cluster ne doit pas utiliser le partagémode d’accès.
Le cluster ne doit pas avoir la configuration Spark
spark.databricks.pyspark.enableProcessIsolationdéfinie surtrue.Vous devez disposer d’une licence Pro flottante RStudio Server pour utiliser l’édition Pro.
Notes
Bien que le cluster puisse utiliser un mode d’accès prenant en charge Unity Catalog, vous ne pouvez pas utiliser RStudio Server à partir de ce cluster pour accéder aux données dans Unity Catalog.
Prise en main : RStudio Server OS Edition
La version Open Source de RStudio Server est préinstallée sur les clusters Azure Databricks qui utilisent Databricks Runtime for Machine Learning (Databricks Runtime ML).
Pour ouvrir RStudio Server OS Edition sur un cluster, suivez les étapes suivantes :
Ouvrir page de détails du cluster.
Démarrez le cluster, puis cliquez sur l’onglet Apps :
Dans l’onglet Applications, cliquez sur le bouton Configurer RStudio. Cela génère un mot de passe à usage unique pour vous. Cliquez sur le lien Afficher pour l’afficher et copiez le mot de passe.
Cliquez sur le lien Ouvrir RStudio pour ouvrir l’interface utilisateur dans un nouvel onglet. Entrez votre nom d’utilisateur et votre mot de passe dans le formulaire de connexion, puis connectez-vous.
À partir de l’interface utilisateur RStudio, vous pouvez importer le package
SparkRet configurer une sessionSparkRpour lancer des travaux Spark sur votre cluster.library(SparkR) sparkR.session() # Query the first two rows of a table named "diamonds" in a # schema (database) named "default" and display the query result. df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2") showDF(df)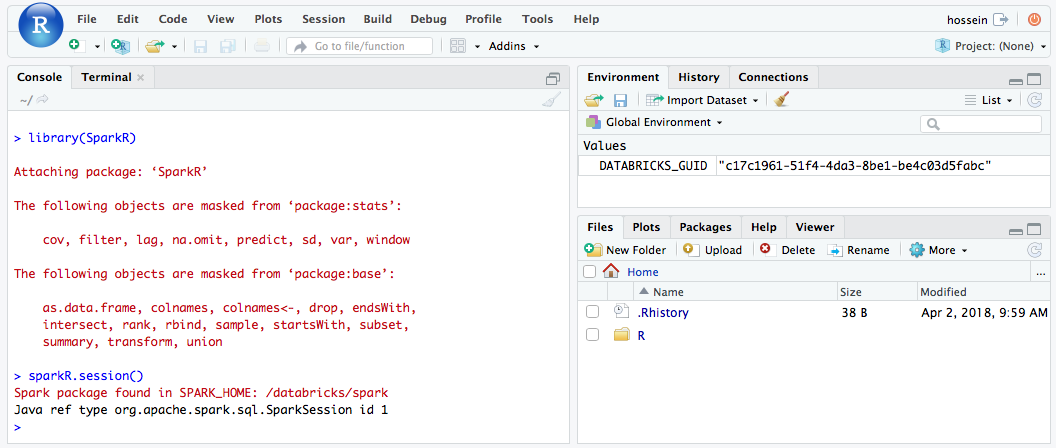
Vous pouvez également attacher le package sparklyr et configurer une connexion Spark.
library(sparklyr) sc <- spark_connect(method = "databricks") # Query a table named "diamonds" and display the first two rows. df <- spark_read_table(sc = sc, name = "diamonds") print(x = df, n = 2)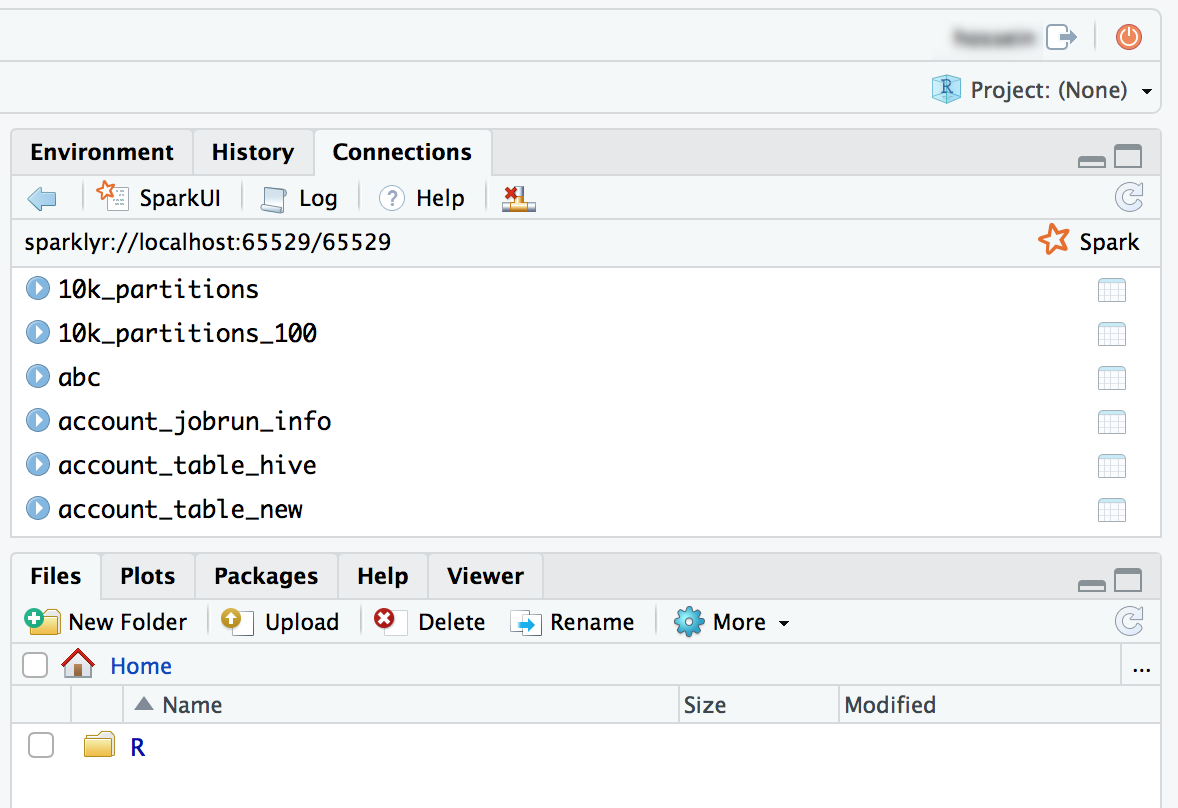
Prise en main : RStudio Workbench
Cette section vous montre comment configurer et commencer à utiliser RStudio Workbench (anciennement RStudio Server Pro) sur un cluster Azure Databricks. En fonction de votre licence, RStudio Workbench peut inclure RStudio Server Pro.
Configurer le serveur de licences RStudio
Pour utiliser RStudio Workbench sur Azure Databricks, vous devez convertir votre licence Pro en licence flottante. Pour obtenir de l'aide, contactez help@rstudio.com. Lorsque votre licence est convertie, vous devez configurer un serveur de licences pour RStudio Workbench.
Pour configurer un serveur de licences :
- Lancez une petite instance sur le réseau de votre fournisseur de Cloud ; le démon du serveur de licences est très léger.
- Téléchargez et installez la version correspondante de RStudio License Server sur votre instance, puis démarrez le service. Pour obtenir des instructions détaillées, consultez le Guide d’administration de RStudio Workbench.
- Assurez-vous que le port du serveur de licences est ouvert pour les instances Azure Databricks.
Installer RStudio Workbench
Pour installer RStudio Workbench sur un cluster Azure Databricks, vous devez créer un script init pour installer le package binaire Rstudio Workbench et le configurer de façon à utiliser votre serveur de licences pour le bail de la licence.
Notes
Si vous envisagez d’installer RStudio Workbench sur une version de Databricks Runtime qui comprend déjà le package de l’édition Open Source de RStudio Server, vous devez d’abord désinstaller ce package pour que l’installation aboutisse.
Le fichier .sh suivant est un exemple que vous pouvez stocker comme script d’initialisation dans un emplacement tel que dans votre répertoire d’accueil comme fichier d’espace de travail, dans un volume Unity Catalog ou dans un stockage d’objets. Pour plus d’informations, consultez Scripts init à étendue au réseau en cluster. Le script effectue également des configurations d’authentification supplémentaires qui uniformisent l’intégration avec Azure Databricks.
Avertissement
Les scripts init associés aux clusters de l’étendue sur DBFS sont en fin de vie. Le stockage de scripts d’initialisation dans DBFS existe dans certains espaces de travail pour prendre en charge des charges de travail héritées et n’est pas recommandé. Tous les scripts init stockés dans DBFS doivent être migrés. Pour obtenir les instructions de migration, consultez Migrer des scripts init depuis DBFS.
#!/bin/bash
set -euxo pipefail
if [[ $DB_IS_DRIVER = "TRUE" ]]; then
sudo apt-get update
sudo dpkg --purge rstudio-server # in case open source version is installed.
sudo apt-get install -y gdebi-core alien
## Installing RStudio Workbench
cd /tmp
# You can find new releases at https://rstudio.com/products/rstudio/download-commercial/debian-ubuntu/.
wget https://download2.rstudio.org/server/bionic/amd64/rstudio-workbench-2022.02.1-461.pro1-amd64.deb -O rstudio-workbench.deb
sudo gdebi -n rstudio-workbench.deb
## Configuring authentication
sudo echo 'auth-proxy=1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-user-header-rewrite=^(.*)$ $1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-sign-in-url=<domain>/login.html' >> /etc/rstudio/rserver.conf
sudo echo 'admin-enabled=1' >> /etc/rstudio/rserver.conf
sudo echo 'export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin' >> /etc/rstudio/rsession-profile
# Enabling floating license
sudo echo 'server-license-type=remote' >> /etc/rstudio/rserver.conf
# Session configurations
sudo echo 'session-rprofile-on-resume-default=1' >> /etc/rstudio/rsession.conf
sudo echo 'allow-terminal-websockets=0' >> /etc/rstudio/rsession.conf
sudo rstudio-server license-manager license-server <license-server-url>
sudo rstudio-server restart || true
fi
- Remplacez
<domain>par votre URL Azure Databricks et<license-server-url>par l’URL de votre serveur de licence flottante. - Stockez ce fichier
.shcomme script d’initialisation dans un emplacement tel que dans votre répertoire d’accueil comme fichier d’espace de travail, dans un volume Unity Catalog ou dans un stockage d’objets. Pour plus d’informations, consultez Scripts init à étendue au réseau en cluster. - Avant de lancer un cluster, ajoutez ce fichier
.shcomme script d’initialisation à partir de l’emplacement associé. Pour obtenir des instructions, consultez les scripts d’init dans l’étendue du cluster. - Lancez le cluster.
Utiliser RStudio Server Pro
Ouvrir page de détails du cluster.
Démarrez le cluster et cliquez sur l'onglet "Applications" :
Dans l’onglet Applications, cliquez sur le bouton Configurer RStudio.
Vous n’avez pas besoin du mot de passe à usage unique. cliquez sur le lien Ouvrir l’interface utilisateur RStudio pour ouvrir une session RStudio Pro authentifiée.
À partir de l’interface utilisateur RStudio, vous pouvez attacher le package
SparkRet configurer une sessionSparkRpour lancer des travaux Spark sur votre cluster.library(SparkR) sparkR.session() # Query the first two rows of a table named "diamonds" in a # schema (database) named "default" and display the query result. df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2") showDF(df)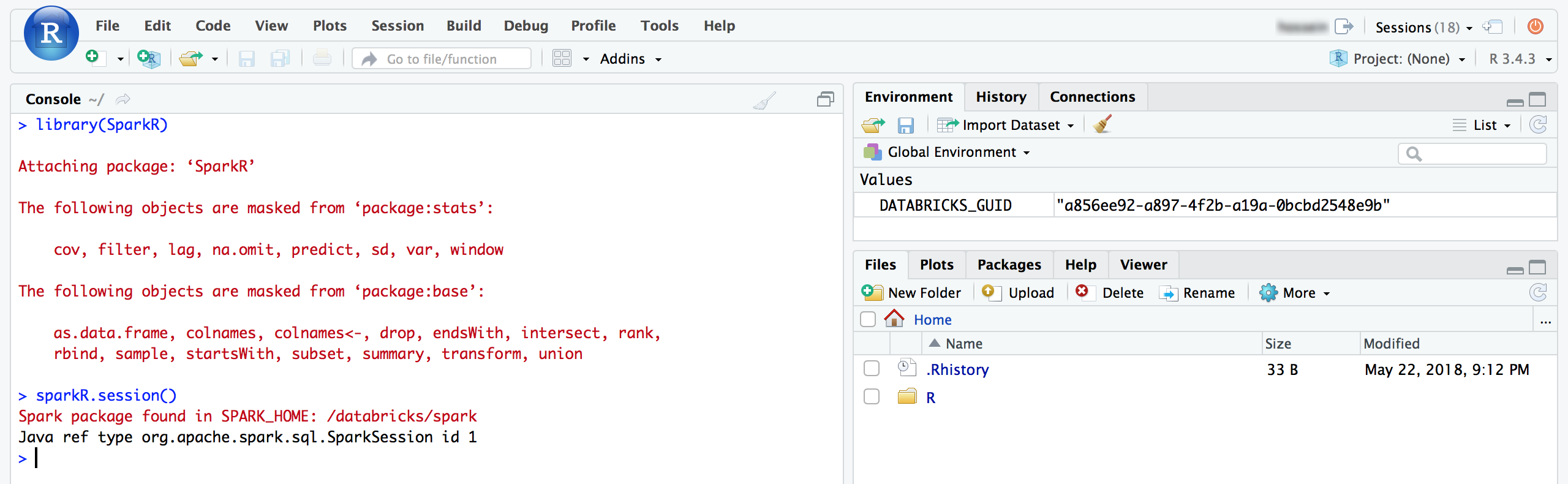
Vous pouvez également attacher le package sparklyr et configurer une connexion Spark.
library(sparklyr) sc <- spark_connect(method = "databricks") # Query a table named "diamonds" and display the first two rows. df <- spark_read_table(sc = sc, name = "diamonds") print(x = df, n = 2)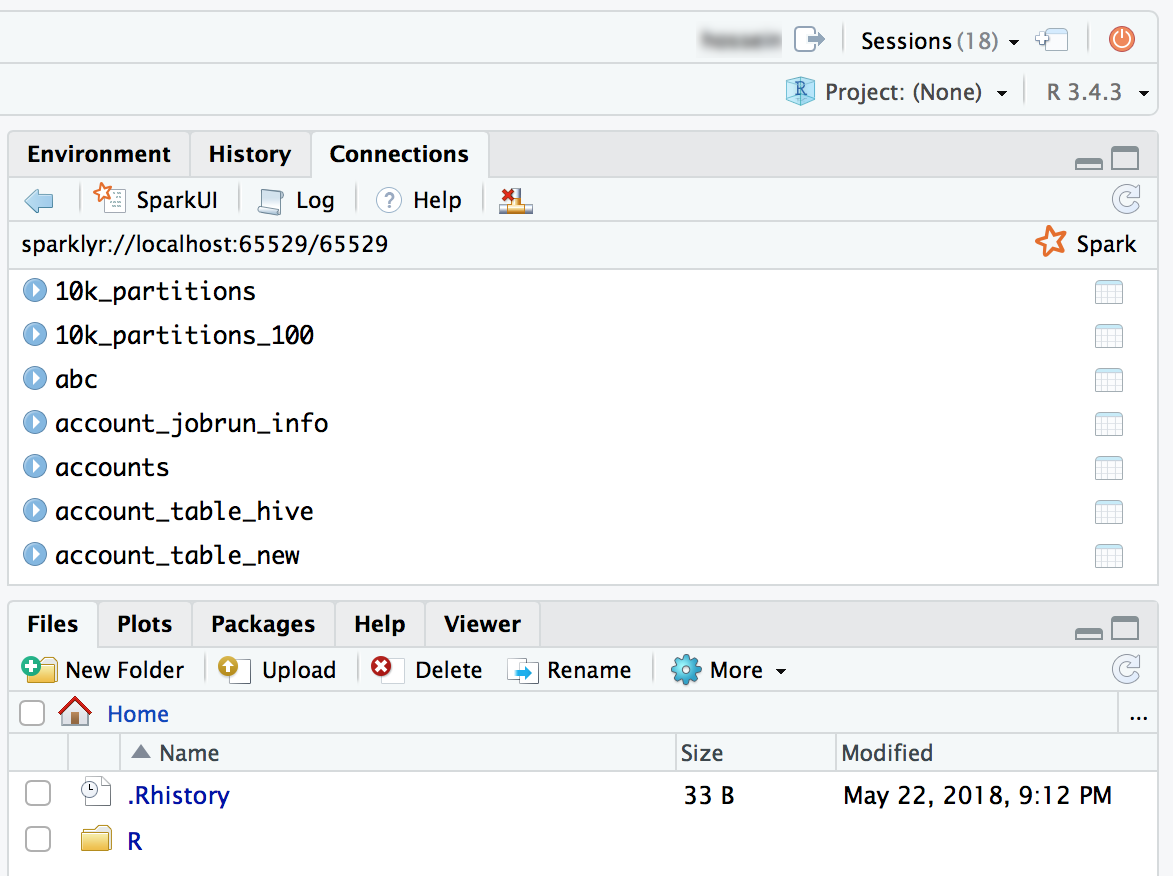
RStudio Server FAQ
Quelle est la différence entre l’édition Open Source de RStudio Server et RStudio Workbench ?
RStudio Workbench prend en charge un large éventail de fonctionnalités d’entreprise qui ne sont pas disponibles dans l’édition Open Source. Vous pouvez consulter une comparaison des fonctionnalités sur le site web de RStudio.
En outre, l’édition Open Source de RStudio Server est distribué dans le cadre de la licence publique générale GNU Affero (AGPL), tandis que la version Pro est fournie avec une licence commerciale pour les organisations qui ne sont pas en mesure d’utiliser le logiciel AGPL.
Pour finir, RStudio Workbench est fourni avec le support professionnel et d’entreprise de RStudio, PBC, tandis que l’édition Open Source de RStudio Server est fourni sans support.
Puis-je utiliser ma licence RStudio Workbench / RStudio Server Pro sur Azure Databricks ?
Oui, si vous disposez déjà d’une licence Pro Enterprise pour RStudio Server, vous pouvez utiliser cette licence sur Azure Databricks. Consultez Bien démarrer : RStudio Workbench pour découvrir comment installer RStudio Workbench sur Azure Databricks.
Où s’exécute RStudio Server ? Dois-je gérer des services/serveurs supplémentaires ?
Comme vous pouvez le voir sur le diagramme dans l'architecture d’intégration RStudio, le démon RStudio Server s’exécute sur le nœud du pilote (maître) de votre cluster Azure Databricks. Avec l’édition Open Source de RStudio Server, vous n’avez pas besoin d’exécuter d’autres serveurs/services. Toutefois, pour RStudio Workbench, vous devez gérer une instance distincte qui exécute RStudio License Server.
Puis-je utiliser RStudio Server sur un cluster standard ?
Notes
Cet article décrit l’interface utilisateur des clusters héritée. Si vous souhaitez obtenir plus d’informations sur la nouvelle interface utilisateur des clusters (en préversion), notamment les modifications de terminologie pour les modes d’accès au cluster, consultez Informations de référence sur la configuration de calcul. Pour une comparaison des nouveaux types de cluster hérités, consultez Modifications apportées à l’interface utilisateur des clusters et aux modes d’accès au cluster.
Oui, vous pouvez.
Puis-je utiliser RStudio Server sur un cluster avec arrêt automatique ?
Non, vous ne pouvez pas utiliser RStudio quand l’arrêt automatique est activé. L’arrêt automatique peut purger les scripts et données utilisateur non enregistrés dans une session RStudio. Pour protéger les utilisateurs contre ce scénario de perte de données involontaire, RStudio est désactivé par défaut sur ces clusters.
Pour les clients qui requièrent le nettoyage des ressources de cluster lorsqu’elles ne sont pas utilisées, Databricks recommande d’utiliser des API de cluster pour nettoyer les clusters RStudio en fonction d’une planification.
Comment conserver mon travail sur RStudio ?
Nous vous recommandons vivement de conserver votre travail à l’aide d’un système de gestion de version depuis RStudio. RStudio prend en charge de nombreux systèmes de gestion de version et vous permet d’enregistrer et de gérer vos projets. Si vous ne faites pas persister votre code par l'une des méthodes suivantes, vous risquez de perdre votre travail si un administrateur d’espace de travail redémarre ou met fin au cluster.
Une méthode consiste à enregistrer vos fichiers (code ou données) sur Qu’est-ce que DBFS ?. Par exemple, si vous enregistrez un fichier sous /dbfs/, les fichiers ne seront pas supprimés lorsque votre cluster sera arrêté ou redémarré.
Une autre méthode consiste à enregistrer le notebook R dans votre système de fichiers local en l’exportant sous Rmarkdown, puis à importer le fichier dans l’instance RStudio. Le blog Partage de notebooks R à l’aide de RMarkdown décrit les étapes plus en détails.
Comment démarrer une session SparkR ?
SparkR est contenu dans Databricks Runtime, mais vous devez le charger dans RStudio. Exécutez le code suivant dans RStudio pour initialiser une session SparkR.
library(SparkR)
sparkR.session()
En cas d’erreur lors de l’importation du package SparkR, exécutez .libPaths() et vérifiez que /home/ubuntu/databricks/spark/R/lib est inclus dans le résultat.
S’il n’est pas inclus, vérifiez le contenu de /usr/lib/R/etc/Rprofile.site. Répertoriez /home/ubuntu/databricks/spark/R/lib/SparkR sur le pilote pour vérifier que le package SparkR est installé.
Comment démarrer une session sparklyr ?
Le package sparklyr doit être installé sur le cluster. Utilisez une des méthodes suivantes pour installer le package sparklyr :
- En tant que bibliothèque Azure Databricks
- Commande
install.packages() - Interface utilisateur de gestion des packages RStudio
library(sparklyr)
sc <- spark_connect(method = “databricks”)
Comment RStudio s’intègre-t-il avec les notebooks R Azure Databricks ?
Vous pouvez déplacer votre travail entre les notebooks et RStudio à l’aide de la gestion de version.
Qu’est-ce que le répertoire de travail ?
Quand vous démarrez un projet dans RStudio, vous choisissez un répertoire de travail. Par défaut, il s’agit du répertoire de base sur le conteneur du pilote (master) où RStudio Server est en cours d’exécution. Vous pouvez modifier ce répertoire si vous le souhaitez.
Puis-je lancer Shiny Apps à partir de RStudio qui s’exécute sur Azure Databricks ?
Oui, vous pouvez développer et afficher des applications Shiny dans RStudio Server sur Databricks.
Je ne peux pas utiliser terminal ou git dans RStudio sur Azure Databricks. Comment puis-je résoudre ce problème ?
Assurez-vous que vous avez désactivé Websocket. Dans l’édition Open Source de RStudio Server, vous pouvez le faire à partir de l’interface utilisateur.
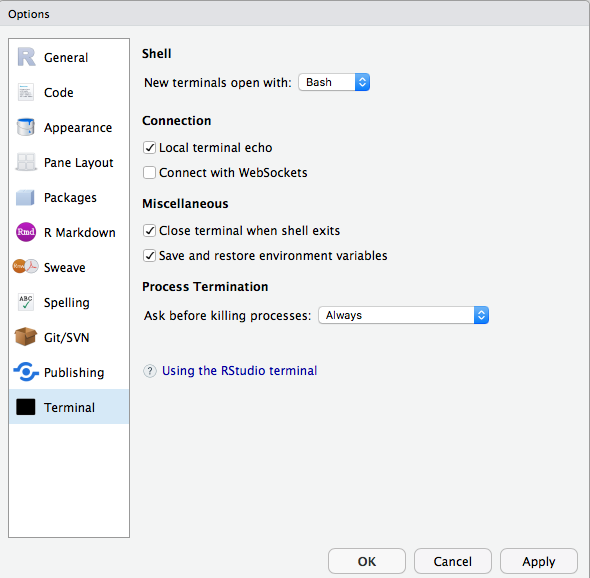
Dans RStudio Server Pro, vous pouvez ajouter allow-terminal-websockets=0 à /etc/rstudio/rsession.conf pour désactiver Websocket pour tous les utilisateurs.
Je ne vois pas l’onglet Applications dans les détails du cluster.
Cette fonctionnalité n’est pas disponible pour tous les clients. Elle nécessite le Plan Premium.