sparklyr
Azure Databricks prend en charge sparklyr dans les notebooks, les travaux et RStudio Desktop. Cet article décrit comment utiliser sparklyr, avec des exemples de scripts que vous pouvez exécuter. Pour plus d’informations, consultez Interface R vers Apache Spark.
Spécifications
Azure Databricks distribue la dernière version stable de sparklyr avec chaque version de Databricks Runtime. Vous pouvez utiliser sparklyr dans les notebooks R d’Azure Databricks ou dans RStudio Server hébergé sur Azure Databricks en important la version installée de sparklyr.
Dans RStudio Desktop, Databricks Connect vous permet de connecter sparklyr depuis votre ordinateur local aux clusters Azure Databricks et d’exécuter du code Apache Spark. Voir Utiliser sparklyr et RStudio Desktop avec Databricks Connect.
Connecter sparklyr aux clusters Azure Databricks
Pour établir une connexion sparklyr, vous pouvez utiliser "databricks" comme méthode de connexion dans spark_connect().
Aucun paramètre supplémentaire à spark_connect() n’est nécessaire, ni l’appel de spark_install(), car Spark est déjà installé sur un cluster Azure Databricks.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
Barres de progression et interface utilisateur Spark avec sparklyr
Si vous attribuez l’objet de connexion sparklyr à une variable nommée sc comme dans l’exemple ci-dessus, vous verrez des barres de progression Spark dans le notebook après chaque commande qui déclenche des travaux Spark.
En outre, vous pouvez cliquer sur le lien à côté de la barre de progression pour afficher l’interface utilisateur Spark associée au travail Spark donné.
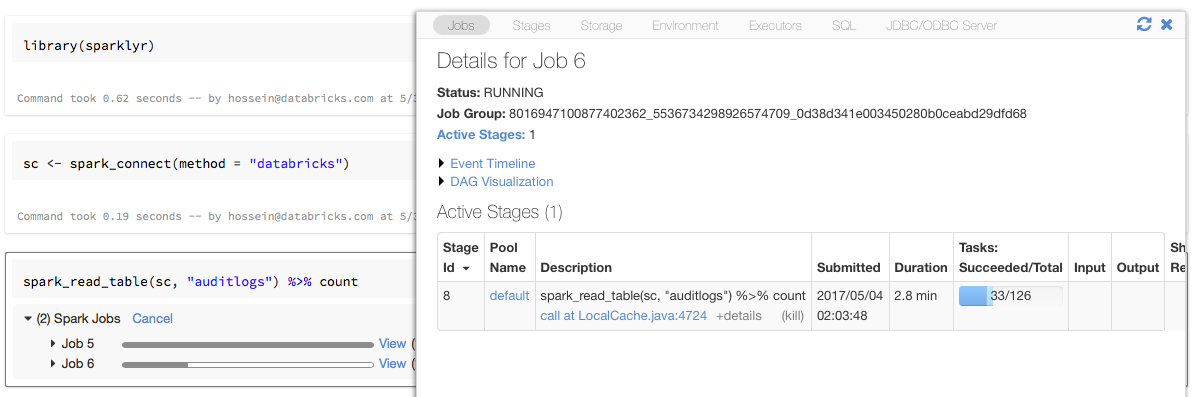
Utiliser sparklyr
Une fois que vous avez installé sparklyr et établi la connexion, toutes les autres API sparklyr fonctionnent normalement. Pour obtenir des exemples, consultez l’exemple de notebook.
sparklyr est généralement utilisé avec d’autres packages tidyverse tels que dplyr. La plupart de ces packages sont préinstallés sur Databricks pour votre commodité. Vous pouvez simplement les importer et commencer à utiliser l’API.
Utiliser sparklyr et SparkR ensemble
SparkR et sparklyr peuvent être utilisés ensemble dans un même notebook ou travail. Vous pouvez importer SparkR en même temps que sparklyr et utiliser ses fonctionnalités. Dans les notebooks d’Azure Databricks, la connexion SparkR est préconfigurée.
Certaines des fonctions de SparkR masquent un certain nombre de fonctions de dplyr :
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
Si vous importez SparkR après avoir importé dplyr, vous pouvez faire référence aux fonctions de dplyr en utilisant les noms complets, par exemple, dplyr::arrange().
De même, si vous importez dplyr après SparkR, les fonctions de SparkR sont masquées par dplyr.
Vous pouvez également détacher de manière sélective l’un des deux packages lorsque vous n’en avez pas besoin.
detach("package:dplyr")
Consultez aussi Comparaison de SparkR et sparklyr.
Utiliser sparklyr dans les travaux spark-submit
Vous pouvez exécuter des scripts qui utilisent sparklyr sur Azure Databricks en tant que travaux spark-submit, avec quelques modifications mineures du code. Certaines des instructions ci-dessus ne s’appliquent pas à l’utilisation de sparklyr dans des travaux spark-submit sur Azure Databricks. En particulier, vous devez fournir l’URL du maître Spark à spark_connect. Par exemple :
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Fonctionnalités non prises en charge
Azure Databricks ne prend pas en charge les méthodes sparklyr telles que spark_web() et spark_log() qui nécessitent un navigateur local. Toutefois, comme l’interface utilisateur Spark est intégrée à Azure Databricks, vous pouvez facilement inspecter les travaux et les journaux Spark.
Consultez Pilote de calcul et journaux du Worker.
Exemple de notebook Démonstration de Sparklyr
Notebook sparklyr
Pour obtenir d’autres exemples, consultez Travailler avec des DataFrames et des tables dans R.