Surveiller Azure Data Explorer
Azure Monitor collecte et agrège les métriques et les journaux d’activité de votre système pour surveiller la disponibilité, les performances et la résilience, et vous avertir des problèmes affectant votre système. Vous pouvez utiliser le portail Azure, PowerShell, Azure CLI, l’API REST ou les bibliothèques clientes pour configurer et afficher les données de surveillance.
Différentes métriques et journaux sont disponibles pour différents types de ressources. Cet article décrit les types de données de surveillance que vous pouvez collecter pour ce service et les moyens d’analyser ces données.
Collecter des données avec Azure Monitor
Ce tableau décrit comment collecter des données pour surveiller votre service et ce que vous pouvez faire avec les données une fois collectées :
| Données à collecter | Description | Comment collecter et acheminer les données | Où afficher les données | Données prises en charge |
|---|---|---|---|---|
| Données de métrique | Les métriques sont des valeurs numériques qui décrivent un aspect d’un système à un moment donné. Les métriques peuvent être agrégées à l’aide d’algorithmes, par rapport à d’autres métriques et analysées pour les tendances au fil du temps. | - Collecté automatiquement à intervalles réguliers. : vous pouvez router certaines métriques de plateforme vers un espace de travail Log Analytics pour interroger d’autres données. Vérifiez le paramètre d’exportation DS de chaque métrique pour voir si vous pouvez utiliser un paramètre de diagnostic pour acheminer les données de métriques. |
Explorateur de mesures | Métriques Azure Data Explorer prises en charge par Azure Monitor |
| Données du journal des ressources | Les journaux d’activité sont des événements système enregistrés avec un horodatage. Les journaux peuvent contenir différents types de données, qu'ils soient structurés ou en texte libre. Vous pouvez router les données du journal des ressources vers des espaces de travail Log Analytics pour la consultation et l’analyse. | Créez un paramètre de diagnostic pour collecter et acheminer les données du journal des ressources. | Log Analytics | Données de journal des ressources d'Azure Data Explorer prises en charge par Azure Monitor |
| Données du journal d’activité | Le journal d’activité Azure Monitor fournit des informations sur les événements au niveau de l’abonnement. Le journal d’activité inclut des informations comme lorsqu’une ressource est modifiée ou qu’une machine virtuelle est démarrée. | - Collecté automatiquement. - Créer un paramètre de diagnostic dans un espace de travail Log Analytics sans frais. |
Journal d'activité |
Pour obtenir la liste de toutes les données prises en charge par Azure Monitor, consultez :
- Métriques prises en charge par Azure Monitor
- Journaux de ressources pris en charge par Azure Monitor
Supervision intégrée pour Azure Data Explorer
Azure Data Explorer propose des métriques et des journaux d’activité pour surveiller le service.
Surveiller les performances, l’intégrité et l’utilisation d’Azure Data Explorer avec des métriques
Les métriques Azure Data Explorer fournissent des indicateurs clés relatifs à l’intégrité et aux performances des ressources du cluster Azure Data Explorer. Utilisez les métriques pour surveiller l’utilisation, l’intégrité et les performances du cluster Azure Data Explorer dans votre scénario spécifique en tant que métriques autonomes. Vous pouvez également utiliser des métriques comme base pour les tableaux de bord Azure et les alertes Azure opérationnels.
Pour utiliser des métriques pour surveiller vos ressources Azure Data Explorer dans le portail Azure :
- Connectez-vous au portail Azure .
- Dans le volet gauche de votre cluster Azure Data Explorer, recherchez les métriques .
- Sélectionnez Métriques pour ouvrir le volet Métriques et commencer l’analyse sur votre cluster.
Dans le volet Métriques, sélectionnez des métriques spécifiques à suivre, choisissez comment agréger vos données et créer des graphiques de métriques à afficher sur votre tableau de bord.
Les sélecteurs de ressource et de métrique Namespace sont prédéfinis pour votre cluster Azure Data Explorer. Les nombres de l’image suivante correspondent à la liste numérotée. Ils vous guident dans les différentes options de configuration et d’affichage de vos métriques.
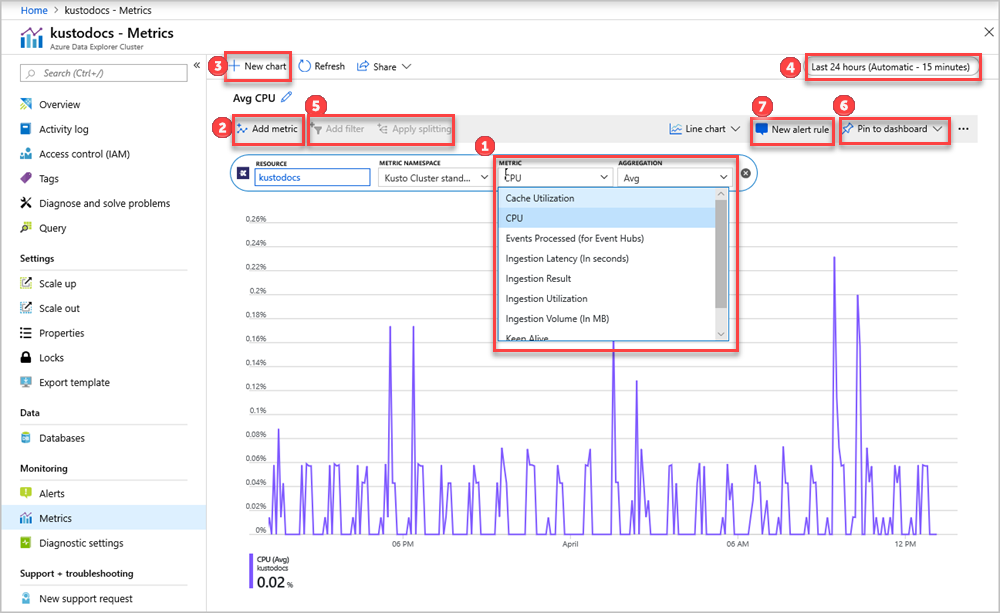
- Pour créer un graphique de métriques, sélectionnez le nom de la Métrique et l’agrégation pertinente par métrique. Pour plus d’informations sur les différentes métriques, consultez Métriques Azure Data Explorer prises en charge.
- Sélectionnez Ajouter une métrique pour afficher le tracé de plusieurs métriques sur le même graphique.
- Sélectionnez + Nouveau graphique pour afficher plusieurs graphiques en une seule vue.
- Utilisez le sélecteur d’heure pour modifier l’intervalle de temps (valeur par défaut : 24 heures passées).
- Utilisez Ajouter un filtre et Appliquer la division pour les métriques qui ont des dimensions.
- Sélectionnez Épingler au tableau de bord pour ajouter la configuration de votre graphique aux tableaux de bord afin de pouvoir le visualiser à nouveau.
- Définissez nouvelle règle d’alerte pour visualiser vos métriques à l’aide des critères définis. La nouvelle règle d’alerte inclut votre ressource cible, la métrique, le fractionnement et les dimensions de filtre de votre graphique. Modifiez ces paramètres dans le volet de création de règle d’alerte .
Surveiller l’ingestion, les commandes, les requêtes et les tables d’Azure Data Explorer à l’aide des journaux de diagnostic
Azure Data Explorer est un service d’analytique des données rapide et entièrement managé pour une analyse en temps réel sur de grands volumes de données en continu à partir d’applications, de sites web, d’appareils IoT, etc. Les journaux de diagnostic d'Azure Monitor fournissent des données sur le fonctionnement des ressources Azure. Azure Data Explorer utilise les journaux de diagnostic pour obtenir des insights sur l’ingestion, les commandes, les requêtes et les tables. Vous pouvez exporter les journaux des opérations vers stockage Azure, event hub ou Log Analytics pour surveiller l’ingestion, les commandes et l’état des requêtes. Les journaux d’activité du stockage Azure et d’Azure Event Hubs peuvent être routés vers une table de votre cluster Azure Data Explorer pour une analyse plus approfondie.
Important
Les données du journal de diagnostic peuvent contenir des données sensibles. Limitez les autorisations de la destination des journaux en fonction de vos besoins de supervision.
Remarque
Dans le portail Azure, les données brutes des métriques pour les pages Metrics et Insights sont stockées dans Azure Monitor. Les requêtes sur ces pages interrogent directement les données de métriques brutes pour fournir les résultats les plus précis. Lorsque vous utilisez la fonctionnalité des paramètres de diagnostic, vous pouvez migrer les données de métriques brutes vers l’espace de travail Log Analytics. Pendant la migration, certaines précisions de données peuvent être perdues en raison de l’arrondi ; par conséquent, les résultats des requêtes peuvent varier légèrement des données d’origine. La marge d’erreur est inférieure à un pourcentage.
Les journaux de diagnostic peuvent être utilisés pour configurer la collecte des données de journal suivantes :
- Ingestion
- Commandes et Requêtes
- Tables
- Journal
Remarque
- Les journaux d’ingestion sont pris en charge pour l’ingestion en file d’attente vers l’URI d’ingestion de données à l’aide des bibliothèques client Kusto et des connecteurs de données.
- Les journaux d’ingestion ne sont pas pris en charge pour l’ingestion en continu, l’ingestion directe à l’URI du cluster, l’ingestion à partir d’une requête ou de
.set-or-appendcommandes.
Remarque
L’échec des journaux d’ingestion est signalé uniquement pour l’état final d’une opération d’ingestion, contrairement à la métrique Résultat de l’ingestion, qui est émise pour les échecs temporaires retentés en interne.
- Opérations d’ingestion réussies: Ces fichiers journaux contiennent des informations sur les opérations d’ingestion achevées avec succès.
- Opérations d’ingestion ayant échoué: Ces journaux contiennent des informations détaillées sur les opérations d’ingestion échouées, y compris les détails des erreurs.
- Opérations de traitement par lot de l’ingestion : ces journaux contiennent des statistiques détaillées sur les lots prêts pour l’ingestion (durée, taille du lot, nombre d’objets blob et types de traitement par lot).
Vous pouvez choisir d’envoyer les données de journal à un espace de travail Log Analytics, à un compte de stockage ou à un hub d’événements.
Les journaux de diagnostic sont désactivés par défaut. Pour activer les journaux de diagnostic pour votre cluster, procédez comme suit :
Dans le portail Azure , sélectionnez la ressource de cluster que vous souhaitez surveiller.
Sous Supervision, sélectionnez Paramètres de diagnostic.
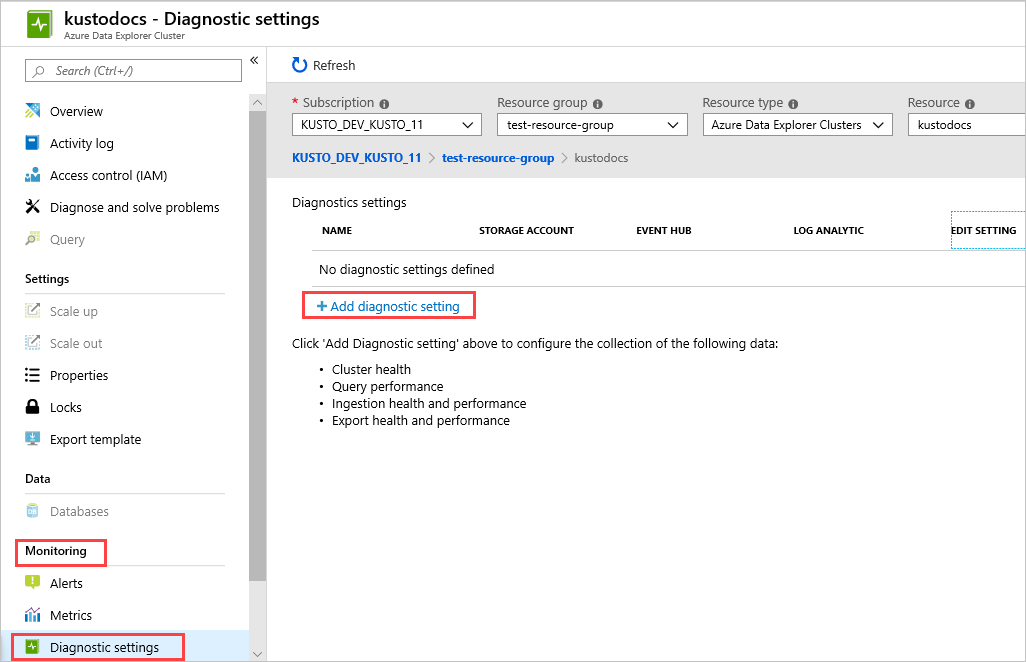
Sélectionnez Ajouter un paramètre de diagnostic.
Dans la fenêtre Paramètres de diagnostic :
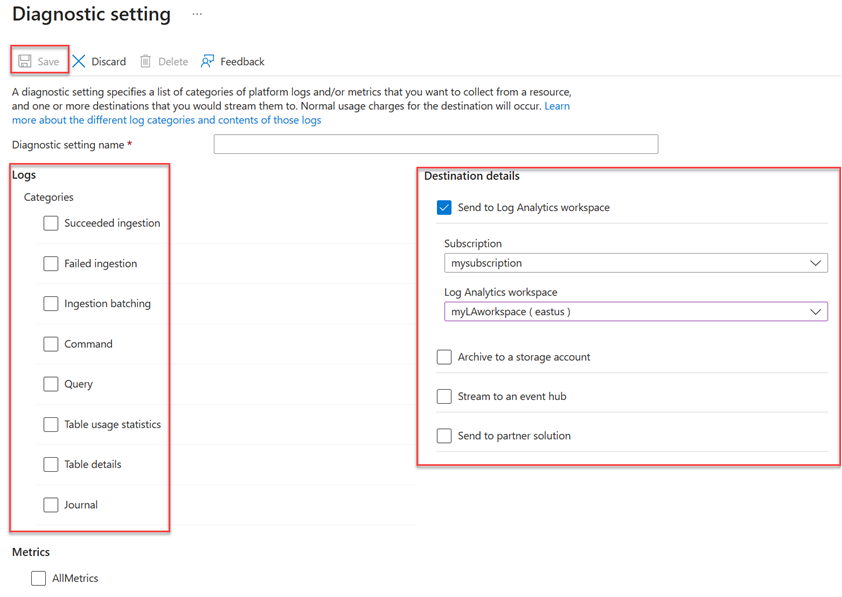
- Entrez un nom dans Nom du paramètre de diagnostic.
- Sélectionnez une ou plusieurs cibles de destination : un espace de travail Log Analytics, un compte de stockage ou un hub d’événements.
- Sélectionnez les journaux à collecter : ingestion réussie, échec de l’ingestion, traitement par lot d’ingestion, Commande, requête, statistiques d’utilisation des tables, Détails de table, ou journal.
- Sélectionnez les métriques à collecter (facultatif).
- Sélectionnez Enregistrer pour enregistrer les nouveaux paramètres et métriques des journaux de diagnostic.
Une fois les paramètres prêts, les journaux commencent à apparaître dans les cibles de destination configurées : un compte de stockage, un hub d’événements ou un espace de travail Log Analytics.
Remarque
Si vous envoyez des journaux à un espace de travail Log Analytics, les journaux SucceededIngestion, FailedIngestion, IngestionBatching, Command, Query, TableUsageStatistics, TableDetailset Journal sont stockés dans les tables Log Analytics nommées : SucceededIngestion, FailedIngestion, ADXIngestionBatching, ADXCommand, ADXQuery, ADXTableUsageStatistics, ADXTableDetailset ADXJournal respectivement.
Utiliser les outils Azure Monitor pour analyser les données
Ces outils Azure Monitor sont disponibles dans le portail Azure pour vous aider à analyser les données de surveillance :
Certains services Azure ont un tableau de bord de supervision intégré dans le portail Azure. Ces tableaux de bord sont appelés insights, et vous pouvez les trouver dans la section Insights d’Azure Monitor dans le portail Azure.
Metrics Explorer vous permet d’afficher et d’analyser les métriques pour les ressources Azure. Pour plus d’informations, consultez Analyser les métriques avec l’Explorateur de métriques Azure Monitor.
Log Analytics vous permet d’interroger et d’analyser les données de journalisation à l’aide du langage de requête Kusto (KQL) . Pour plus d’informations, voir Bien démarrer avec les requêtes de journal dans Azure Monitor.
Le portail Azure dispose d’une interface utilisateur pour l’affichage et les recherches de base du journal d’activité . Pour effectuer une analyse plus approfondie, routez les données vers les journaux Azure Monitor et exécutez des requêtes plus complexes dans Log Analytics.
Application Insights surveille la disponibilité, les performances et l’utilisation de vos applications web, afin de pouvoir identifier et diagnostiquer les erreurs sans attendre qu’un utilisateur les signale.
Application Insights inclut des points de connexion à différents outils de développement et s’intègre à Visual Studio pour prendre en charge vos processus DevOps. Pour plus d’informations, consultez Supervision des applications pour App Service.
Les outils qui permettent une visualisation plus complexe sont les suivants :
- Tableaux de bord qui vous permettent de combiner différents types de données dans un seul volet du portail Azure.
- Les workbooks, des rapports personnalisables que vous pouvez créer dans le portail Azure. Les workbooks peuvent inclure du texte, des métriques et des requêtes de journal.
- Grafana, outil de plateforme ouverte qui excelle dans les tableaux de bord opérationnels. Vous pouvez utiliser Grafana pour créer des tableaux de bord qui incluent des données provenant de plusieurs sources autres qu’Azure Monitor.
- Power BI, un service d’analytique métier qui fournit des visualisations interactives sur différentes sources de données. Vous pouvez configurer Power BI pour importer automatiquement des données de journal à partir d’Azure Monitor pour tirer parti de ces visualisations.
Exporter des données Azure Monitor
Vous pouvez exporter des données hors d’Azure Monitor dans d’autres outils à l’aide de :
Métriques : Utiliser l’API REST pour les métriques pour extraire les données de métriques de la base de données de métriques Azure Monitor. Pour plus d’informations, consultez Informations de référence sur l’API REST Azure Monitor.
Journaux : utilisez l’API REST ou les bibliothèques de client associées.
L’exportation de données de l’espace de travail Log Analytics.
Pour bien démarrer avec l’API REST Azure Monitor, consultez le guide de l’API REST Azure Monitor.
Utiliser des requêtes Kusto pour analyser les données de journal
Vous pouvez analyser les données du journal Azure Monitor à l’aide du langage de requête Kusto (KQL). Pour plus d’informations, consultez Requêtes de journal dans Azure Monitor.
Utiliser des alertes Azure Monitor pour vous avertir des problèmes
alertes Azure Monitor vous permettent d’identifier et de résoudre les problèmes dans votre système, et de vous avertir de manière proactive lorsque des conditions spécifiques sont trouvées dans vos données de surveillance avant que vos clients ne les remarquent. Vous pouvez alerter sur n’importe quelle source de données de métrique ou de journal dans la plateforme de données Azure Monitor. Il existe différents types d’alertes Azure Monitor en fonction des services que vous surveillez et des données de surveillance que vous collectez. Consultez Choisir le bon type de règle d’alerte.
Pour obtenir des exemples d’alertes courantes pour les ressources Azure, consultez Exemples de requêtes d’alerte de journal.
Implémentation d’alertes à grande échelle
Pour certains services, vous pouvez surveiller à grande échelle en appliquant la même règle d’alerte de métrique à plusieurs ressources du même type qui existent dans la même région Azure. Azure Monitor Baseline Alerts (AMBA) fournit une méthode semi-automatisée pour l'implémentation à grande échelle d'alertes de métriques de plateforme importantes, de tableaux de bord et de recommandations.
Obtenir des recommandations personnalisées à l’aide d’Azure Advisor
Pour certains services, si des conditions critiques ou des modifications imminentes se produisent pendant les opérations de ressources, une alerte s’affiche sur le service page Vue d’ensemble dans le portail. Vous pouvez trouver plus d’informations et des correctifs recommandés pour l’alerte dans les recommandations de l’Advisor , sous Surveillance dans le menu de gauche. Pendant les opérations normales, aucune recommandation de conseiller ne s’affiche.
Pour plus d’informations sur Azure Advisor, consultez vue d’ensemble d’Azure Advisor.