Créer des solutions de continuité d'activité et de reprise d'activité avec Azure Data Explorer
Cet article explique en détail comment vous préparer à une panne régionale Azure en répliquant vos ressources Azure Data Explorer, la gestion et l’ingestion dans différentes régions Azure. Un exemple d’ingestion de données avec Azure Event Hubs est fourni. L’optimisation des coûts y est également abordée pour différentes configurations architecturales. Pour une analyse plus approfondie des considérations d’architecture et des solutions de reprise d’activité, consultez la vue d’ensemble relative à la continuité d’activité.
Se préparer à une panne régionale Azure pour protéger ses données
Azure Data Explorer ne prend pas en charge la protection automatique en cas de panne d’une région Azure entière. Cette interruption peut se produire lors d’une catastrophe naturelle, telle qu’un tremblement de terre. S’il vous faut une solution de récupération d’urgence, procédez comme suit afin de garantir la continuité d’activité. Au cours de ces étapes, vous allez répliquer vos clusters, la gestion et l’ingestion de données dans deux régions jumelées Azure.
- Créez un minimum de clusters indépendants dans deux régions jumelées Azure.
- Répliquez toutes les activités de gestion, telles que la création des tables ou la gestion des rôles d’utilisateur sur chaque cluster.
- Ingérez des données dans chaque cluster en parallèle.
Créer plusieurs clusters indépendants
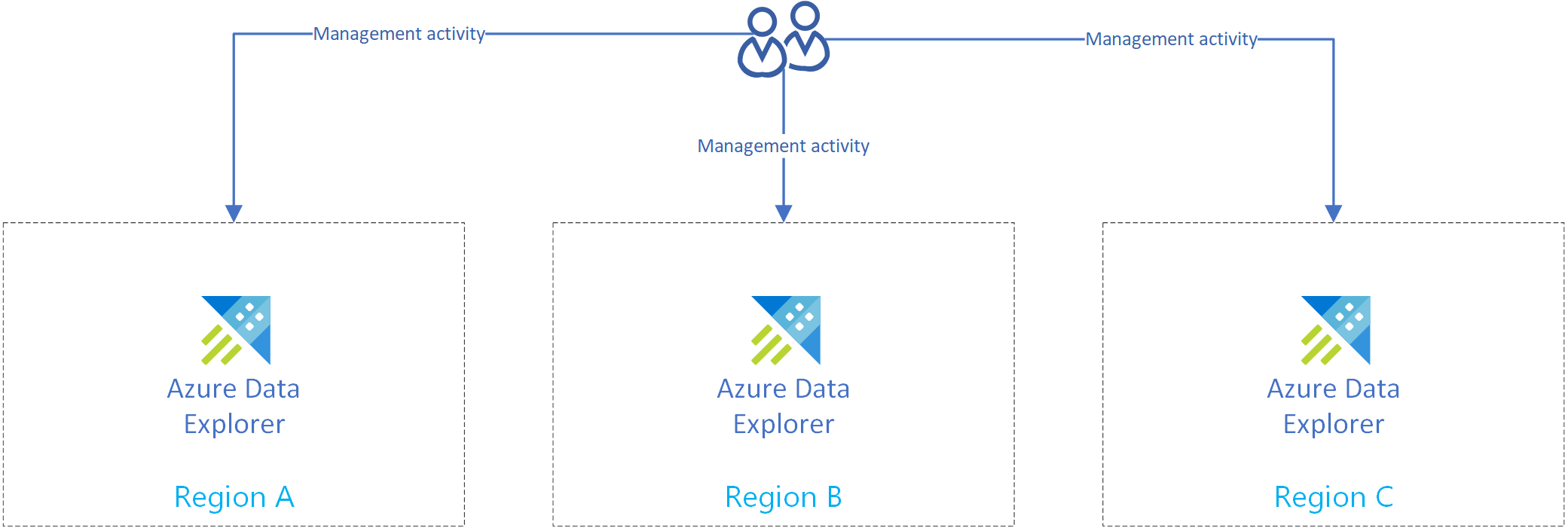
Créez plusieurs clusters Azure Data Explorer dans différentes régions. Veillez à ce qu’au moins deux de ces clusters soient créés dans des régions jumelées Azure.
L’illustration suivante montre les réplicas, trois clusters dans trois régions différentes.

Répliquer des activités de gestion
Répliquez les activités de gestion de manière à disposer de la même configuration de cluster dans chaque réplica.
Sur chaque réplica, créez les mêmes :
- Bases de données :vous pouvez utiliser le Portail Azure ou l’un de nos Kits de développement logiciel (SDK) pour créer une nouvelle base de données.
- Tables
- Mappages
- Stratégies
Gérez l’authentification et l’autorisation sur chaque réplica.
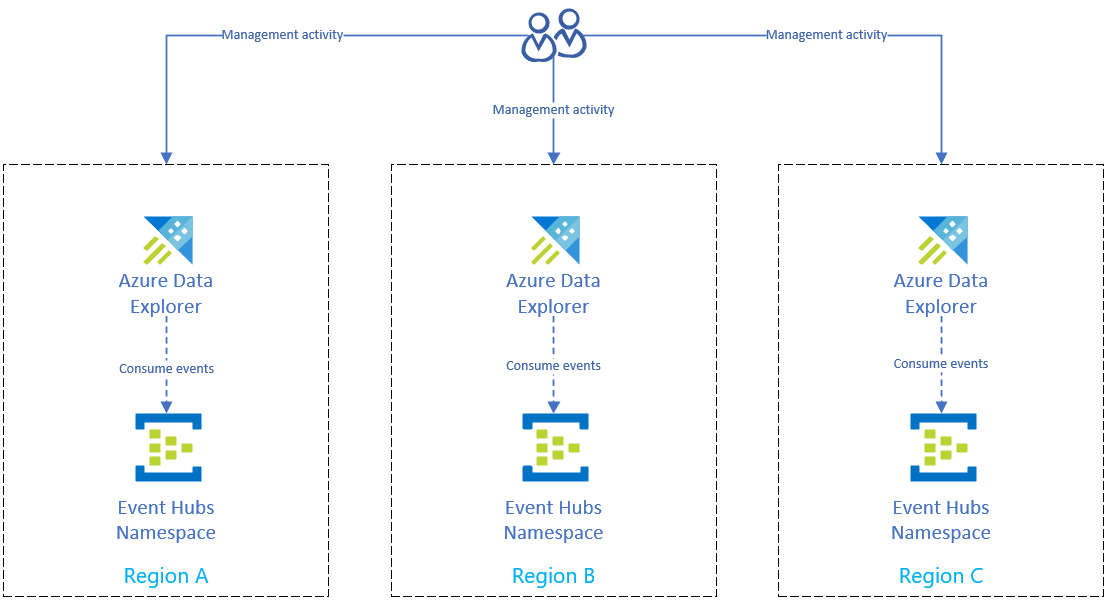
Solution de reprise d’activité utilisant l’ingestion de hub d’événements
Après vous être préparé à une panne régionale Azure pour protéger vos données, ces dernières, de même que la gestion sont distribuées dans plusieurs régions. En cas de panne dans une région, Azure Data Explorer est en mesure d’utiliser d’autres réplicas.
Configurer l’ingestion en utilisant un hub d’événements
Pour ingérer des données depuis Azure Event Hubs dans le cluster Azure Data Explorer de chaque région, répliquez d’abord votre configuration d’Azure Event Hubs dans chaque région. Configurez ensuite le réplica Azure Data Explorer de chaque région pour ingérer les données de ses Event Hubs correspondants.
Remarque
L’ingestion via Azure Event Hubs/IoT Hub/Stockage est robuste. Si un cluster n’est pas disponible pendant un certain temps, il rattrapera son retard ultérieurement et insérera les messages ou objets blob en attente. Ce processus s’appuie sur les points de contrôle.
Comme illustré dans le diagramme ci-dessous, vos sources de données produisent des événements dans les hubs d’événements de toutes les régions, et chaque réplica Azure Data Explorer consomme les événements. Les composants de visualisation des données tels que Power BI, Grafana ou les applications web alimentées par les kits de développement logiciel (SDK) peuvent interroger l’un des réplicas.
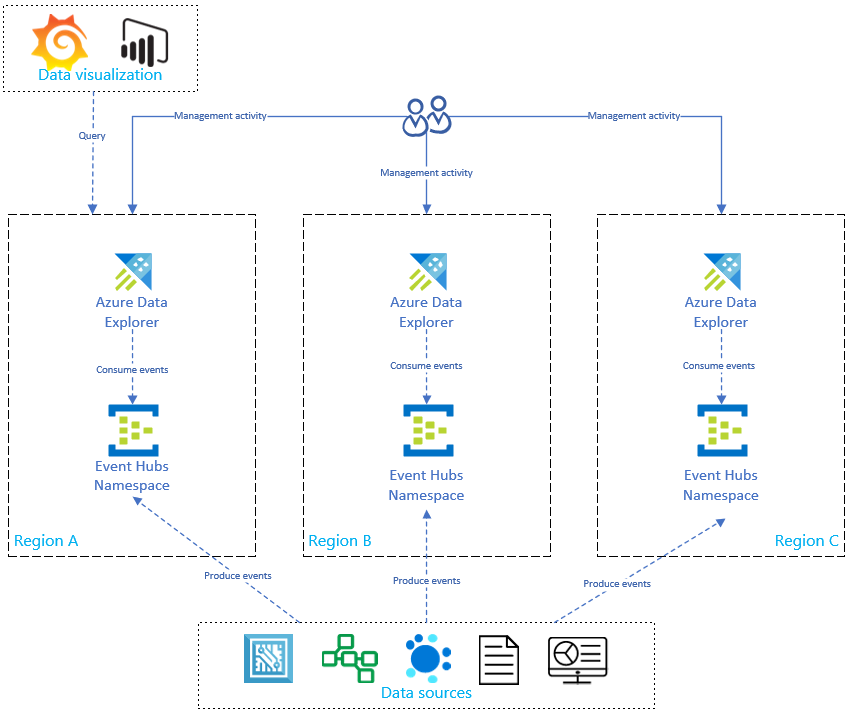
Optimiser les coûts
Vous êtes maintenant prêt à optimiser vos réplicas à l’aide des méthodes suivantes :
- Créer une configuration de récupération des données à la demande
- Démarrer et arrêter les réplicas
- Implémenter un service d’application hautement disponible
- Optimiser les coûts dans une configuration active-active
Créer une configuration de la récupération des données à la demande
La réplication et la mise à jour de la configuration Azure Data Explorer augmentent de manière linéaire le coût en fonction du nombre de réplicas. À des fins d’optimisation des coûts, vous pouvez implémenter une variante architecturale pour équilibrer le temps, le basculement et le coût. Dans une configuration de récupération des données à la demande, l’optimisation des coûts a été implémentée en introduisant des réplicas Azure Data Explorer passifs. Ces réplicas ne sont activés qu’en cas d’incident dans la région primaire (région A, par exemple). Les réplicas des régions B et C n’ont pas à être actifs 24 heures sur 24, 7 jours sur 7, ce qui réduit considérablement les coûts. Dans la plupart des cas cependant, les performances de ces réplicas ne sont pas aussi bonnes que celles du cluster principal. Pour plus d’informations, consultez Configuration de la récupération des données à la demande.
Dans l’illustration ci-dessous, un seul cluster ingère des données provenant du hub d’événements. Le cluster principal de la région A se charge de l’exportation continue de toutes les données vers un compte de stockage. Les réplicas secondaires accèdent aux données à l’aide de tables externes.
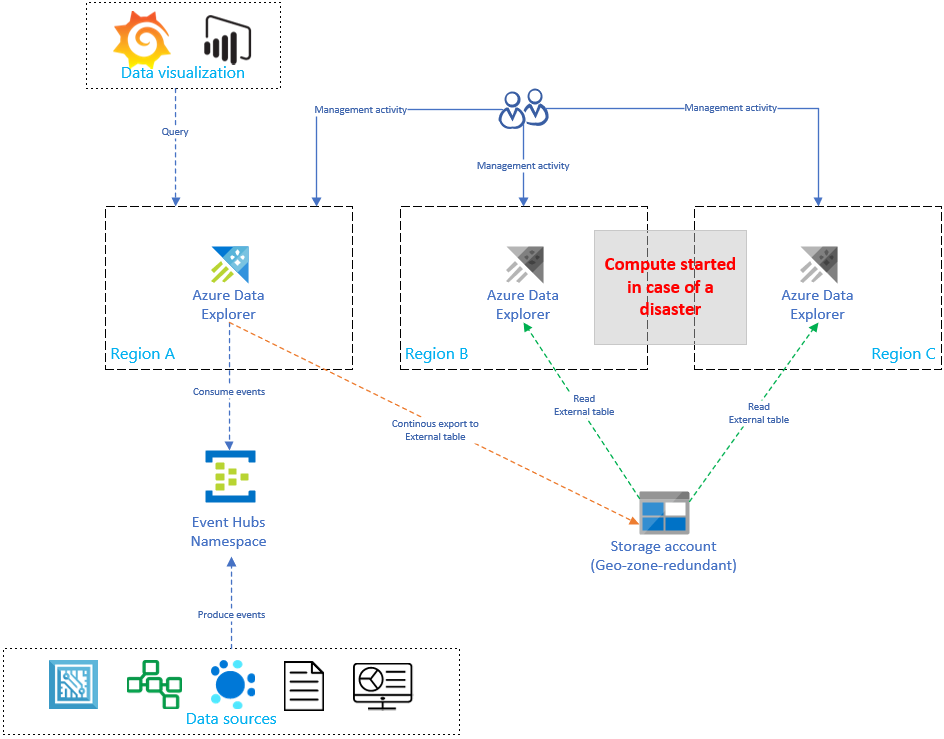
Démarrer et arrêter les réplicas
Vous pouvez démarrer et arrêter les réplicas secondaires à l’aide d’une des méthodes suivantes :
Connecteur Azure Data Explorer vers Power Automate (Préversion)
Bouton Arrêter sous l’onglet Vue d’ensemble dans le portail Azure. Pour plus d’informations, consultez Arrêter et redémarrer le cluster.
Azure CLI :
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>"
Implémenter un service d’application hautement disponible
Créer le client BCDR Azure App Service
Cette section explique comment créer une instance Azure App Service prenant en charge une connexion à un cluster Azure Data Explorer principal et plusieurs clusters secondaires. L’image suivante illustre la configuration d’Azure App Service.
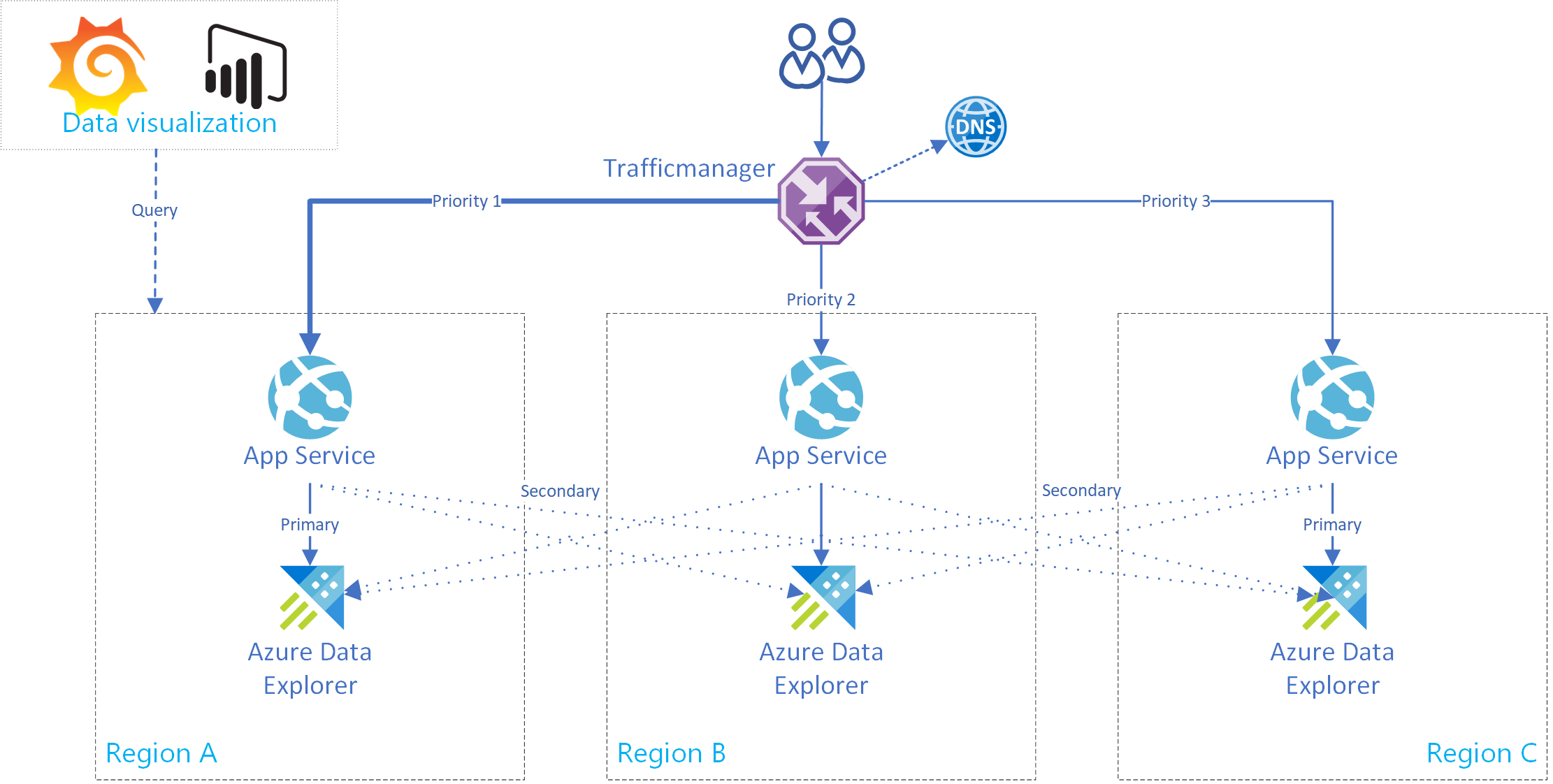
Conseil
Le fait de disposer de plusieurs connexions entre les réplicas du même service offre une disponibilité accrue. Cette configuration n’est pas seulement utile dans les cas de pannes régionales.
Utilisez ce code réutilisable pour une instance App Service. La classe AdxBcdrClient a été créée pour implémenter un client à plusieurs clusters. Dans un premier temps, chaque requête exécutée à l’aide de ce client est envoyée au cluster principal. En cas d’échec, la requête est envoyée aux réplicas secondaires.
Utilisez des métriques d’insights d’application personnalisées pour mesurer les performances et demander une distribution vers les clusters principaux et secondaires.
Tester le client BCDR Azure App Service
Nous avons exécuté un test à l’aide de plusieurs réplicas Azure Data Explorer. Après une panne simulée de clusters principaux et secondaires, vous pouvez voir que le client BCDR App Service se comporte comme prévu.
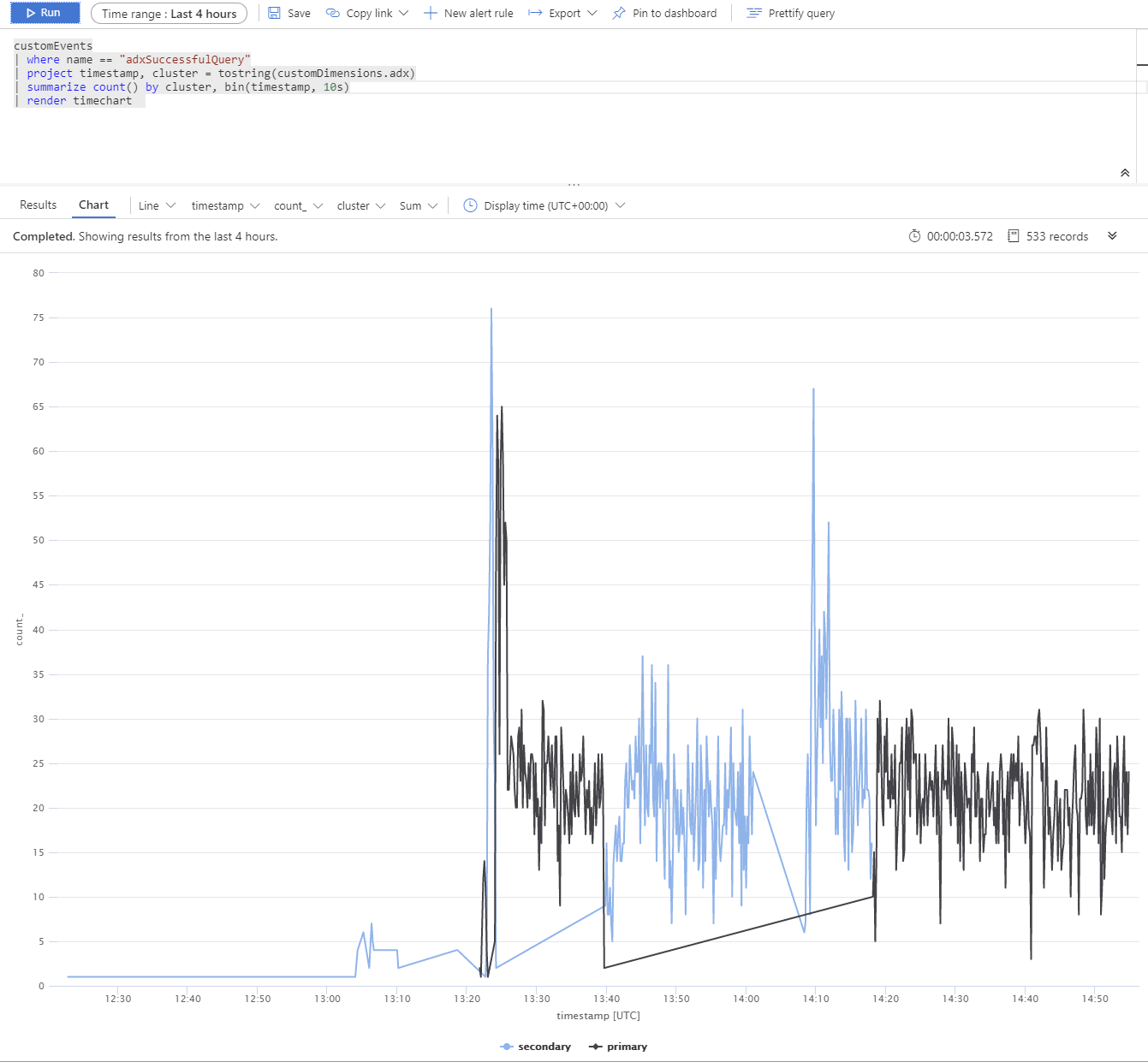
Les clusters Azure Data Explorer sont répartis dans les régions Europe Ouest (2xD14v2 primaire), Asie Sud-Est et USA Est (2xD11v2).
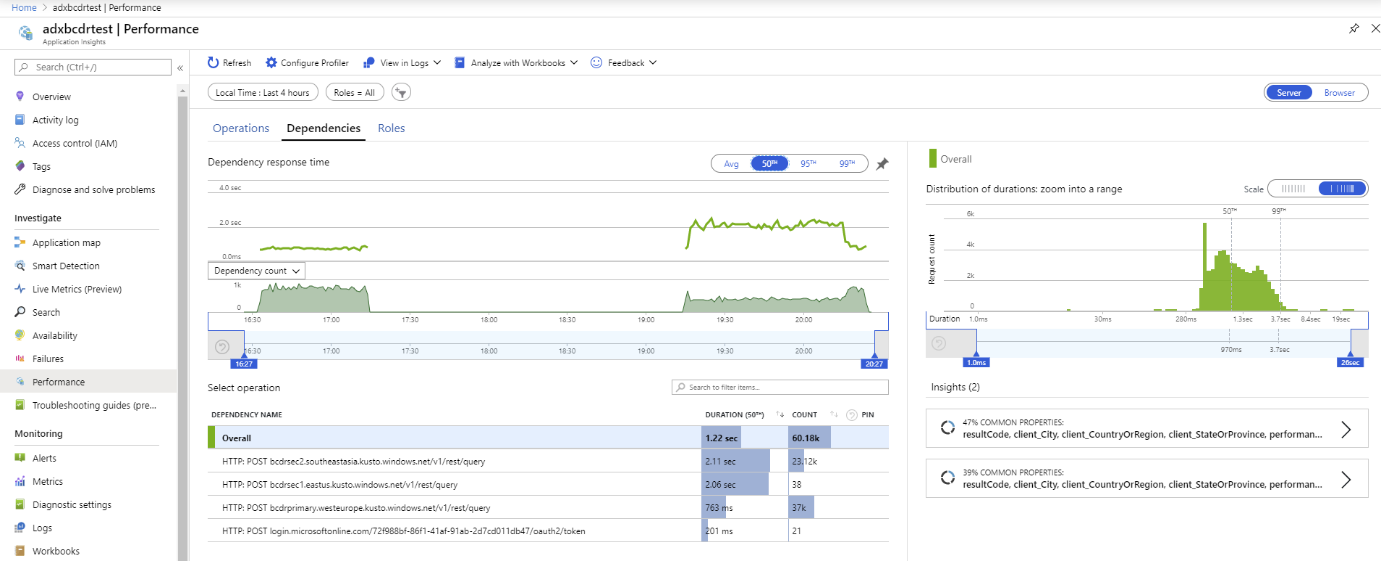
Remarque
Les temps de réponse plus lents sont dus à des références SKU et des requêtes mondiales.
Effectuer un routage dynamique ou statique
Utilisez les méthodes de routage Azure Traffic Manager à des fins de routage dynamique ou statique des requêtes. L’équilibreur de charge de trafic DNS Azure Traffic Manager vous permet de répartir le trafic App Service. Ce trafic est optimisé pour les services des régions Azure du monde entier, tout en offrant une disponibilité et une réactivité élevées
Vous pouvez également utiliser le routage basé sur Azure Front Door. Pour découvrir une comparaison de ces deux méthodes, consultez Équilibrage de charge avec la suite de livraison d’application Azure.
Optimiser les coûts dans une configuration active-active
L’utilisation d’une configuration active-active à des fins de récupération d’urgence augmente le coût de façon linéaire. Le coût comprend les nœuds, le stockage, le balisage et la hausse du coût de mise en réseau pour la bande passante.
Utiliser la mise à l’échelle automatique optimisée pour optimiser les coûts
Utilisez la fonctionnalité de mise à l’échelle automatique optimisée pour configurer la mise à l’échelle horizontale des clusters secondaires. Ils doivent être dimensionnés de manière à gérer la charge d’ingestion. Lorsque le cluster principal n’est pas accessible, les clusters secondaires reçoivent plus de trafic et sont mis à l’échelle en fonction de la configuration.
Dans cet exemple, l’utilisation de la mise à l’échelle automatique optimisée a permis d’économiser environ 50 % du coût par rapport à la même échelle horizontale et verticale sur tous les réplicas.