Gérer la mise à l'échelle horizontale d'un cluster (scale-out) dans Azure Data Explorer pour prendre en compte les fluctuations de la demande
Dimensionner un cluster de manière appropriée est essentiel pour les performances de l’Explorateur de données Azure. Une taille de cluster statique peut conduire à une sous-utilisation ou à une surutilisation, ce qui n’est idéal dans aucun cas. La demande de cluster n’étant pas prévisible de manière précise, la meilleure approche consiste à mettre à l’échelle un cluster, en ajoutant et en supprimant de la capacité et des ressources processeur en fonction des fluctuations de la demande.
Il existe deux workflows pour la mise à l’échelle d’un cluster Azure Data Explorer :
- Mise à l’échelle horizontale, également appelée scale-in et scale-out.
- Mise à l’échelle verticale, également appelée scale-up et scale-down. Cet article explique le workflow de mise à l’échelle horizontale.
Configurer la mise à l’échelle horizontale
La mise à l’échelle horizontale vous permet de mettre à l’échelle le nombre d’instances automatiquement en fonction de planifications et de règles prédéfinies. Pour spécifier les paramètres de mise à l’échelle automatique pour votre cluster :
Dans le portail Azure, accédez à votre ressource de cluster Azure Data Explorer. Sous Paramètres, sélectionnez Scale-out.
Dans la fenêtre Scale-out, sélectionnez la méthode de mise à l’échelle automatique de votre choix : Mise à l’échelle manuelle, Mise à l’échelle automatique optimisée ou Mise à l’échelle personnalisée.
Mise à l’échelle manuelle
Dans l’option de mise à l’échelle manuelle, le cluster a une capacité statique qui ne change pas automatiquement. Sélectionnez la capacité statique à l’aide de la barre nombre d’instances . La mise à l’échelle du cluster reste au paramètre sélectionné jusqu’à ce qu’elle soit modifiée.
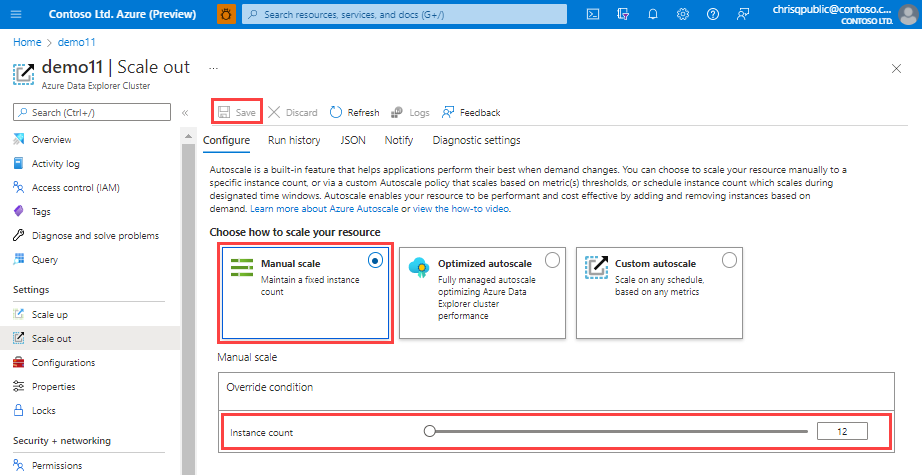
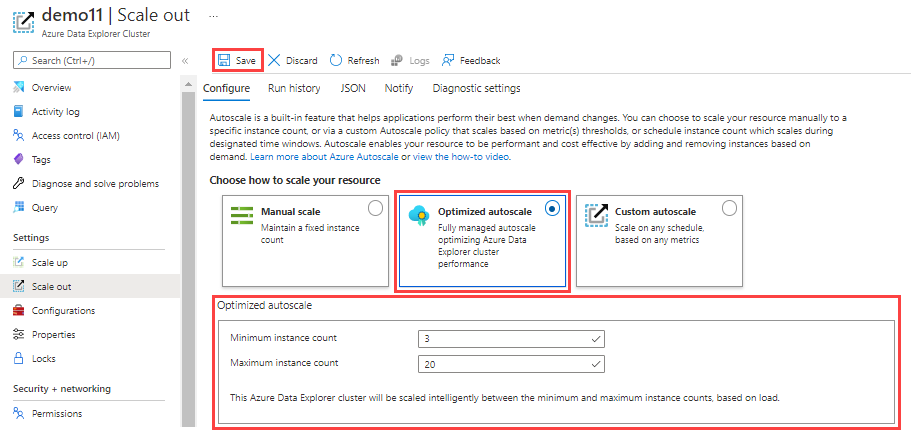
Mise à l’échelle automatique optimisée (option recommandée)
La mise à l’échelle automatique optimisée est le paramètre par défaut lors de la création du cluster et la méthode de mise à l’échelle recommandée. Cette méthode optimise les performances et les coûts du cluster, comme ceci :
- Si le cluster est sous-utilisé, un scale-in est effectué pour réduire les coûts sans affecter les performances requises.
- Si le cluster est surutilisé, un scale-out est effectué pour maintenir des performances optimales.
Pour configurer la mise à l’échelle automatique optimisée :
Sélectionnez Mise à l’échelle automatique optimisée.
Spécifiez un nombre minimum et maximum d’instances. La mise à l’échelle automatique du cluster est comprise entre ces valeurs en fonction de la charge.
Sélectionnez Enregistrer.
La mise à l’échelle automatique optimisée commence. Vous pouvez voir ses actions dans le journal d’activité du cluster dans Azure.
Logique de la mise à l’échelle automatique optimisée
La mise à l’échelle automatique optimisée est gérée par une logique prédictive ou réactive. Une logique prédictive suit le modèle d’utilisation du cluster. Quand il identifie le caractère saisonnier avec un degré de confiance élevé, il gère la mise à l’échelle du cluster. Sinon, une logique réactive qui suit l’utilisation réelle du cluster est utilisée pour prendre des décisions sur les opérations de mise à l’échelle du cluster en fonction du niveau actuel d’utilisation des ressources.
Les principales métriques pour les flux prédictifs et réactifs sont les suivantes :
- UC
- Facteur d’utilisation du cache
- Utilisation de l’ingestion
Les logiques prédictives et réactives sont liées aux limites de taille du cluster ainsi qu’au nombre minimum et maximum d’instances, conformément aux valeurs définies dans la configuration de la mise à l’échelle automatique optimisée. Il n’est pas souhaitable d’effectuer fréquemment des opérations de scale-out et de scale-in sur le cluster en raison de l’impact sur les ressources du cluster et du temps nécessaire pour ajouter ou supprimer des instances, ainsi que pour rééquilibrer le cache chaud sur tous les nœuds.
Mise à l’échelle automatique prédictive
La logique prédictive prévoit l’utilisation du cluster pour le jour suivant en fonction de son modèle d’utilisation au cours des dernières semaines. La prévision est utilisée pour créer une planification d’opérations de scale-in ou de scale-out afin d’ajuster la taille du cluster à l’avance. Cela permet de terminer la mise à l’échelle du cluster et le rééquilibrage des données à temps pour gérer les changements de charge. Cette logique est particulièrement efficace pour les modèles saisonniers, notamment les pics d’utilisation quotidiens ou hebdomadaires.
Toutefois, dans les scénarios où un seul pic d’utilisation dépasse les prévisions, la mise à l’échelle automatique optimisée revient à la logique réactive. Quand cela se produit, les opérations de scale-in ou de scale-out sont effectuées ad hoc en fonction du dernier niveau d’utilisation des ressources.
Mise à l’échelle automatique réactive
Scale-out
Quand le cluster s’approche d’un état de surutilisation, une opération de scale out est effectuée pour maintenir des performances optimales. Une opération de scale out est effectuée si au moins l’une des conditions suivantes se produit :
- L’utilisation du cache est élevée pendant plus d’une heure
- L’utilisation du processeur est élevée pendant plus d’une heure
- L’utilisation de l’ingestion est élevée pendant plus d’une heure
Scale-in
Quand le cluster est sous-utilisé, une opération de scale in est effectuée pour réduire les coûts tout en maintenant des performances optimales. Plusieurs métriques sont utilisées pour vérifier qu’il est possible d’effectuer un scale-in du cluster en toute sécurité.
Pour vérifier que les ressources ne sont pas surchargées, les métriques suivantes sont évaluées avant d’effectuer le scale in :
- L’utilisation du cache n’est pas élevée
- L’UC est inférieur à la moyenne
- L’utilisation de l’ingestion est inférieure à la moyenne
- Si l’ingestion en streaming est utilisée, son utilisation n’est pas élevée
- La métrique Keep Alive est supérieure à une valeur minimale définie, traitée correctement et dans les temps, ce qui indique que le cluster est réactif
- Il n’y a pas de limitation de requêtes
- Le nombre de requêtes ayant échoué est inférieur à la valeur minimale définie
Notes
La logique de scale in nécessite une évaluation d’une journée avant l’implémentation du scale in optimisé. Cette évaluation a lieu toutes les heures. Si vous souhaitez effectuer un changement immédiat, utilisez la mise à l’échelle manuelle.
Mise à l’échelle automatique personnalisée
Bien que la mise à l’échelle automatique optimisée soit l’option de mise à l’échelle recommandée, la mise à l’échelle automatique personnalisée Azure est également prise en charge. Utiliser la méthode de mise à l’échelle automatique personnalisée vous permet de mettre à l’échelle votre cluster dynamiquement en fonction de métriques que vous spécifiez. Pour configurer la mise à l’échelle automatique personnalisée, effectuez les étapes suivantes.
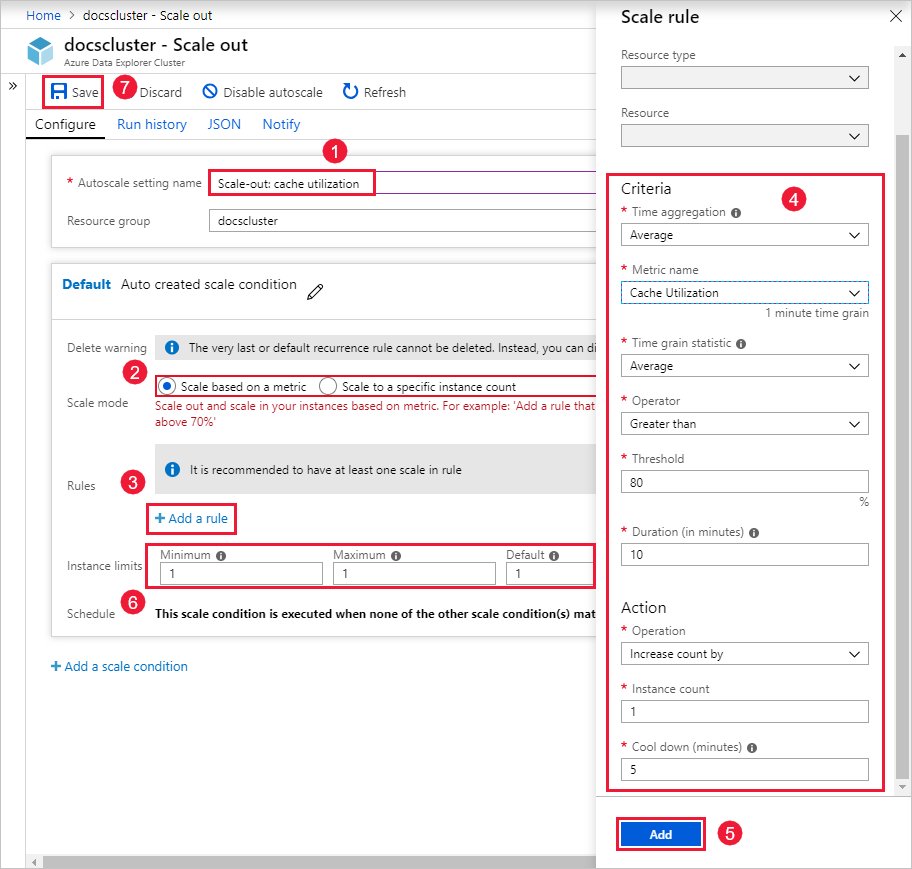
Dans la zone Nom du paramètre de mise à l’échelle automatique, indiquez un nom, par exemple Scale-out : utilisation de cache.
Pour Mode de mise à l’échelle, sélectionnez Mettre à l’échelle selon une mesure. Ce mode fournit une mise à l’échelle dynamique. Vous pouvez également sélectionner Mettre à l’échelle à un nombre d’instances spécifique.
Sélectionnez + Ajouter une règle.
Dans la section Règle de mise à l’échelle à droite, entrez des valeurs pour chaque paramètre.
Critères
Paramètre Description et valeur Agrégation du temps Sélectionnez un critère d’agrégation, comme Moyenne. Nom de la métrique Sélectionnez la métrique sur laquelle vous voulez baser l’opération de mise à l’échelle, comme Utilisation du cache. Statistiques de fragment de temps Choisissez entre Moyenne, Minimum, Maximum et Somme. Opérateur Choisissez l’option appropriée, par exemple Supérieur ou égal à. Seuil Choisissez une valeur appropriée. Par exemple, pour l’utilisation du cache, 80 pour cent est un bon point de départ. Durée (en minutes) Choisissez une durée appropriée pendant laquelle le système effectue des recherches lors du calcul de métriques. Commencez avec la valeur par défaut, 10 minutes. Action
Paramètre Description et valeur opération Choisissez l’option appropriée pour effectuer un scale-in ou un scale-out. Nombre d’instances Choisissez le nombre de nœuds ou d’instances que vous voulez ajouter ou supprimer quand une condition de métrique est remplie. Refroidissement (minutes) Choisissez un intervalle de temps d’attente approprié entre les opérations de mise à l’échelle. Commencez avec la valeur par défaut, cinq minutes. Sélectionnez Ajouter.
Dans la section Limites d’instance à gauche, entrez des valeurs pour chaque paramètre.
Paramètre Description et valeur Minimum Nombre d’instances en dessous duquel la mise à l’échelle de votre cluster ne se met pas en œuvre, quelle que soit l’utilisation. Maximum Nombre d’instances au-dessus duquel la mise à l’échelle de votre cluster ne se met pas en œuvre, quelle que soit l’utilisation. Par défaut Nombre d’instances par défaut. Ce paramètre est utilisé s’il existe des problèmes de lecture des métriques de ressource. Sélectionnez Enregistrer.
Vous venez de configurer une mise à l'échelle horizontale pour votre cluster Azure Data Explorer. Ajoutez une autre règle pour une mise à l’échelle verticale. Si vous avez besoin d’aide pour résoudre des problèmes de mise à l’échelle de clusters, ouvrez une demande de support dans le portail Azure.
Contenu connexe
- Superviser les performances, l’intégrité et l’utilisation d’Azure Data Explorer avec des métriques
- Gérer la mise à l’échelle verticale du cluster pour dimensionner ce dernier de manière appropriée.