Opérations de Machine Learning
Les opérations de Machine Learning (également appelées MLOps) consistent à appliquer des principes DevOps aux applications basées sur l’IA. Pour implémenter des opérations de Machine Learning dans une organisation, des compétences, des processus et des technologies spécifiques doivent être mis en place. L’objectif est de fournir des solutions de Machine Learning robustes, évolutives, fiables et automatisées.
Dans cet article, découvrez comment planifier des ressources pour prendre en charge les opérations de Machine Learning au niveau de l’organisation. Passez en revue les meilleures pratiques et recommandations basées sur l’utilisation d’Azure Machine Learning pour adopter des opérations de Machine Learning dans l’entreprise.
Qu’est-ce que les opérations de Machine Learning ?
Les algorithmes et frameworks modernes de Machine Learning facilitent de plus en plus le développement de modèles capables d’effectuer des prédictions précises. Les opérations de Machine Learning sont un moyen structuré d’incorporer le Machine Learning dans le développement d’applications dans l’entreprise.
Dans un exemple de scénario, vous avez créé un modèle Machine Learning qui dépasse toutes vos attentes au niveau de la justesse, et qui impressionne les commanditaires liés à votre entreprise. Il est temps à présent de déployer le modèle en production, mais cela ne s’avère peut-être pas aussi simple que prévu. L’organisation devra probablement avoir mis en place des personnes, des processus et des technologies avant de pouvoir utiliser votre modèle Machine Learning en production.
Avec le temps, vous ou un collègue pouvez développer un nouveau modèle plus performant que l’ancien. Le remplacement d’un modèle Machine Learning utilisé en production présente certaines préoccupations importantes pour l’organisation :
- Vous souhaiterez implémenter le nouveau modèle sans perturber les opérations métier qui s’appuient sur le modèle déployé.
- À des fins réglementaires, vous devrez peut-être expliquer les prédictions du modèle ou recréer le modèle si des prédictions inhabituelles ou biaisées résultent de données dans le nouveau modèle.
- Les données que vous utilisez dans votre formation et modèle Machine Learning peuvent changer au fil du temps. Avec les modifications apportées aux données, vous devrez peut-être réentraîner régulièrement le modèle pour maintenir sa précision de prédiction. Une personne ou un rôle doit être chargé de nourrir les données, de surveiller les performances du modèle, de réentraîner le modèle et de corriger le modèle en cas d’échec.
Supposons que vous ayez une application qui traite les prédictions d’un modèle via API REST. Même un cas d’usage simple comme celui-ci peut entraîner des problèmes en production. L’implémentation d’une stratégie d’opérations de Machine Learning peut vous aider à résoudre les problèmes de déploiement et à prendre en charge les opérations métier qui s’appuient sur des applications basées sur l’IA.
Certaines opérations de Machine Learning s’intègrent bien dans le framework DevOps général. Les exemples incluent la configuration des tests unitaires et des tests d’intégration et le suivi des modifications à l’aide du contrôle de version. D’autres tâches sont plus uniques aux opérations de Machine Learning et peuvent inclure :
- Permettre l’expérimentation et la comparaison en continu par rapport à un modèle de référence.
- Superviser les données entrantes pour détecter une éventuelle dérive de données.
- Déclenchez le réentraînement du modèle et configurez une restauration pour la récupération d’urgence.
- Créer des pipelines de données réutilisables pour la formation et le scoring.
L’objectif des opérations de Machine Learning est de combler l’écart entre le développement et la production, et d’offrir plus rapidement de la valeur ajoutée aux clients. Pour atteindre cet objectif, vous devez repenser les processus traditionnels de développement et de production.
Toutes les organisations n’ont pas les mêmes impératifs concernant l’approche des opérations de Machine Learning. L’architecture des opérations de Machine Learning d’une grande entreprise multinationale ne sera probablement pas la même infrastructure que celle d’une petite start-up. Les organisations commencent généralement modestement et se développent au fur et à mesure que leur maturité, leur catalogue de modèles et leur expérience évoluent.
Le modèle de maturité des opérations de Machine Learning peut vous aider à voir où votre organisation se situe sur l’échelle de maturité des opérations de Machine Learning et vous aider à planifier la croissance future.
Opérations de Machine Learning vs. DevOps
Les opérations de Machine Learning sont différentes de DevOps dans plusieurs domaines clés. Les opérations de Machine Learning présentent ces caractéristiques :
- L’exploration précède le développement et les opérations.
- Le cycle de vie de la science des données nécessite une méthode de travail adaptative.
- Des limites relatives à la qualité des données et à la progression de la limite de disponibilité.
- Un effort opérationnel plus important est nécessaire par rapport à DevOps.
- Les équipes de travail nécessitent des spécialistes et des experts du domaine.
Pour obtenir un résumé, passez en revue les sept principes des opérations de Machine Learning.
L’exploration précède le développement et les opérations
Les projets de science des données sont différents des projets de développement d’applications ou d’Engineering données. Un projet de science des données peut réussir à atteindre le stade de production, mais souvent, plus d’étapes sont impliquées que dans un déploiement traditionnel. Après une analyse initiale, il peut sembler évident que le résultat opérationnel ne sera pas atteint avec les jeux de données disponibles. Une phase d’exploration plus détaillée est généralement la première étape d’un projet de science des données.
L’objectif de la phase d’exploration est de définir et d’affiner le problème. Pendant cette phase, les scientifiques des données exécutent une analyse exploratoire des données. Ils utilisent des statistiques et des visualisations pour confirmer ou infirmer les hypothèses. Les parties prenantes doivent comprendre que le projet peut ne pas s’étendre au-delà de cette phase. Il est également important de rendre cette phase aussi fluide que possible pour accélérer le délai d’exécution. Sauf si le problème à résoudre inclut un élément de sécurité, évitez de restreindre la phase exploratoire avec les processus et les procédures. Les scientifiques des données doivent pouvoir travailler avec les outils et les données qu’ils préfèrent. Des données réelles sont nécessaires pour ce travail d’exploration.
Le projet peut passer aux étapes d’expérimentation et de développement lorsque les parties prenantes sont confiantes que le projet de science des données est réalisable et peut fournir une valeur métier réelle. À ce stade, les pratiques de développement prennent de plus en plus d’importance. Il est recommandé de capturer les métriques de toutes les expériences effectuées durant cette phase. Il est également important d’incorporer le contrôle de code source pour pouvoir comparer les modèles et avoir accès aux différentes versions du code.
Les activités de développement incluent la refactorisation, le test et l’automatisation du code d’exploration dans des pipelines d’expérimentation reproductibles. L’organisation doit créer des applications et des pipelines pour servir les modèles. La refactorisation du code en composants et bibliothèques modulaires permet d’augmenter les capacités de réutilisation et de test ainsi que le niveau de performance.
Enfin, les pipelines d’inférence d’application ou de lot qui servent les modèles sont déployés dans des environnements intermédiaires ou de production. En plus de surveiller la fiabilité et les performances de l’infrastructure comme pour une application standard, dans un déploiement de modèles Machine Learning, vous devez surveiller en permanence la qualité des données, le profil de données et le modèle pour la dégradation ou la dérive. Les modèles Machine Learning nécessitent également un réentraînement au fil du temps pour rester pertinents dans un environnement en constante évolution.
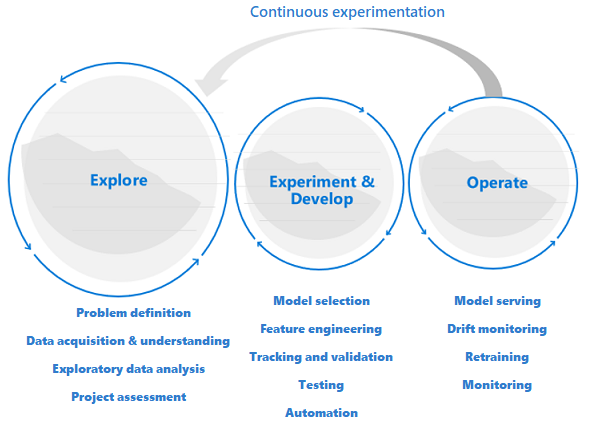
Le cycle de vie de la science des données nécessite une méthode de travail adaptative
Étant donné que la nature et la qualité des données sont incertaines initialement, vous risquez de ne pas atteindre vos objectifs métier si vous appliquez un processus DevOps classique à un projet de science des données. L’exploration et l’expérimentation sont des activités et des besoins récurrents tout au long du processus de Machine Learning. Les équipes de Microsoft utilisent un cycle de vie de projet et un processus de travail qui reflète la nature des activités spécifiques à la science des données. Le processus TDSP (Team Data Science Process) et le processus DSLP (Data Science Lifecycle Process) sont des exemples d’implémentations de référence.
Des limites relatives à la qualité des données et à la progression de la limite de disponibilité
Pour qu’une équipe de Machine Learning puisse développer efficacement des applications basées sur le Machine Learning, l’accès aux données de production est souhaitable dans tous les environnements de travail pertinents. Si l’accès aux données de production n’est pas possible pour des impératifs de conformité ou des contraintes techniques, implémentez le contrôle d’accès en fonction du rôle (Azure RBAC) avec Azure Machine Learning, l’accès juste-à-temps ou les pipelines de déplacement des données pour créer des réplicas de données de production et améliorer la productivité des utilisateurs.
Le machine learning nécessite un effort opérationnel plus important
Contrairement aux logiciels traditionnels, les performances d’une solution de Machine Learning sont constamment à risque, car la solution dépend de la qualité des données. Pour maintenir une solution qualitative en production, il est essentiel de surveiller et de réévaluer en continu les données et la qualité du modèle. En règle générale, un modèle de production nécessite un réentraînement, un redéploiement et un réglage en temps opportun. Ces tâches s’ajoutent aux impératifs quotidiens de sécurité, de supervision de l’infrastructure et de conformité, et nécessitent une expertise particulière.
Les équipes de Machine Learning ont besoin de spécialistes et d’experts techniques du domaine
Bien que les projets de science des données partagent certains rôles avec les projets informatiques classiques, la réussite d’un effort de machine learning dépend fortement de la présence essentielle de spécialistes des technologies du machine learning et d’experts techniques du domaine. Un spécialiste de la technologie dispose de l’expérience nécessaire pour effectuer des expérimentations de machine learning de bout en bout. Un expert du domaine peut aider le spécialiste en analysant et en synthétisant des données ou en sélectionnant des données à utiliser.
Les rôles techniques courants spécifiques aux projets de science des données sont les suivants : expert du domaine, ingénieur données, scientifique des données, ingénieur IA, validateur de modèle et ingénieur Machine Learning. Pour en savoir plus sur les rôles et les tâches au sein d’une équipe classique de science des données, consultez TDSP (Team Data Science Process).
Les sept principes des opérations de Machine Learning
Lorsque vous considérez l’adoption des opérations de Machine Learning dans votre organisation, envisagez d’appliquer les principes fondamentaux suivants :
Utiliser le contrôle de version pour les sorties de code, de données et d’expérimentation. Contrairement au développement traditionnel de logiciels, les données ont une influence directe sur la qualité des modèles Machine Learning. Vous devez adapter la version de votre codebase d’expérimentation, ainsi qu’effectuer également un versioning de vos jeux de données pour avoir la certitude de pouvoir reproduire les expériences ou les résultats d’inférence. La gestion de versions des sorties d’expérimentation, par exemple les modèles, permet de réduire les efforts et le coût de calcul des opérations de leur récréation.
Utiliser plusieurs environnements. Pour séparer le développement et les tests du travail de production, répliquez votre infrastructure dans au moins deux environnements. Le contrôle d’accès pour les utilisateurs peut être différent pour chaque environnement.
Gérez votre infrastructure et vos configurations en tant que code. Quand vous créez et mettez à jour des composants d’infrastructure dans vos environnements de travail, utilisez l’infrastructure en tant que code pour éviter que des incohérences ne se développent entre vos environnements. Gérez les spécifications liées aux travaux d’expérimentation de machine learning sous forme de code. Ainsi, vous pouvez facilement réexécuter et réutiliser une version de votre expérimentation dans plusieurs environnements.
Suivre et gérer les expériences de Machine Learning. Suivez les indicateurs de performances clés et d’autres artefacts pour vos expériences de Machine Learning. La conservation d’un historique des performances des travaux vous permet une analyse quantitative de la réussite des expérimentations et améliore la collaboration et l’agilité au niveau de l’équipe.
Tester le code, valider l’intégrité des données et assurer la qualité du modèle. Testez votre codebase d’expérimentation pour vérifier l’exactitude des fonctions de préparation des données et des fonctions d’extraction de caractéristiques, l’intégrité des données ainsi que les performances de modèle.
Intégration et livraison continues du Machine Learning. Utilisez l’intégration continue (CI) pour automatiser les tests pour votre équipe. Incluez l’entraînement de modèle dans le cadre de pipelines d’entraînement continus. Incluez le test A/B dans votre version pour vous assurer que seul un modèle de qualité est utilisé en production.
Supervisez les services, les modèles et les données. Quand vous mettez à disposition des modèles dans un environnement d’opérations de Machine Learning, il est essentiel de superviser les services pour garantir la disponibilité et la conformité de leur infrastructure ainsi que la qualité des modèles. Configurer la supervision pour identifier une éventuelle dérive de données et de modèle et pour déterminer si un réentraînement est nécessaire. Envisagez de configurer des déclencheurs pour le réentraînement automatique.
Meilleures pratiques d’Azure Machine Learning
Azure Machine Learning propose des services de gestion des ressources, d’orchestration et d’automatisation pour vous aider à gérer le cycle de vie des workflows d’entraînement et de déploiement de vos modèles Machine Learning. Passez en revue les meilleures pratiques et recommandations pour appliquer des opérations de Machine Learning dans les domaines de ressources des personnes, des processus et de la technologie, tous pris en charge par Azure Machine Learning.
Personnes
Travaillez en équipes de projet pour utiliser au mieux les connaissances relatives aux spécialistes et aux domaines de votre organisation. Configurez les espaces de travail Azure Machine Learningpour chaque projet pour répondre aux impératifs de séparation des cas d’usage.
Définissez un ensemble de responsabilités et de tâches en tant que rôle afin que n’importe quel membre de l’équipe d’un projet d’opérations de Machine Learning puisse être affecté et remplir plusieurs rôles. Utilisez des rôles personnalisés dans Azure afin de définir un ensemble d’opérations RBAC Azure précises pour Azure Machine Learning, qui peuvent être effectuées par chaque rôle.
Standardisez un cycle de vie de projet et une méthodologie agile. Le processus TDSP (Team Data Science Process) fournit une implémentation du cycle de vie de référence.
Les équipes équilibrées peuvent exécuter toutes les phases d’opérations de Machine Learning, notamment l’exploration, le développement et les opérations.
Process
Standardisez un modèle de code pour la réutilisation du code et accélérez la durée de bon fonctionnement d’un nouveau projet ou quand un nouveau membre de l’équipe rejoint le projet. Utilisez des pipelines Azure Machine Learning, des scripts de soumission de travaux et des pipelines CI/CD comme base pour les nouveaux modèles.
Utilisez la gestion de versions. Les travaux envoyés à partir d’un dossier Git effectuent un suivi automatique des métadonnées du dépôt. Le travail présent dans Azure Machine Learning est utilisé à des fins de reproductibilité.
Utilisez le contrôle de version pour les entrées et sorties d’expérience pour la reproductibilité. Utilisez les jeux de données Azure Machine Learning ainsi que les fonctionnalités de gestion des modèles et de gestion de l’environnement pour faciliter la gestion des versions.
Créez un historique des exécutions pour les expérimentations à des fins de comparaison, de planification et de collaboration. Utilisez un framework de suivi des expérimentations, par exemple MLflow, pour collecter de métriques.
Mesurez et contrôlez en permanence la qualité du travail de votre équipe via l’intégration continue dans le codebase d’expérimentation complet.
Terminez l’entraînement tôt dans le processus lorsqu’un modèle ne converge pas. Utilisez un framework de suivi des expérimentations et l’historique des exécutions dans Azure Machine Learning pour superviser l’exécution des travaux.
Définissez une stratégie de gestion des expérimentations et des modèles. Envisagez d’utiliser un nom comme champion pour faire référence au modèle de référence actuel. Un modèle challenger est un modèle candidat qui peut surpasser le modèle champion en production. Appliquez des étiquettes dans Azure Machine Learning pour marquer les expérimentations et les modèles. Dans un scénario comme les prévisions de ventes, plusieurs mois sont parfois nécessaires pour déterminer si les prédictions du modèle sont exactes.
Élevez l’intégration continue pour l’entraînement continu en incluant l’entraînement de modèle dans la build. Par exemple, démarrez l’entraînement du modèle sur le jeu de données complet à chaque demande de tirage (pull request).
Réduisez le délai d’obtention d’informations sur la qualité du pipeline de machine learning en exécutant une build automatisée sur un échantillon. Utilisez les paramètres de pipeline Azure Machine Learning pour paramétriser les jeux de données d’entrée.
Utilisez le déploiement continu (CD) pour les modèles Machine Learning afin d’automatiser le déploiement et le test des services de scoring en temps réel dans vos environnements Azure.
Dans certains secteurs réglementés, il se peut que vous deviez effectuer des étapes de validation de modèle pour permettre l’utilisation d’un modèle Machine Learning dans un environnement de production. L’automatisation des étapes de validation peut accélérer le délai de livraison. Quand les étapes de vérification ou de validation manuelles constituent toujours un goulot d’étranglement, demandez-vous si vous pouvez certifier le pipeline de validation de modèle automatisée. Utilisez des étiquettes de ressources dans Azure Machine Learning pour indiquer la conformité des ressources et les candidats à la vérification ou les déclencheurs de déploiement.
N’effectuez pas de réentraînement en production, puis procédez au remplacement direct du modèle de production sans tests d’intégration. Même si les exigences fonctionnelles et de performances du modèle peuvent sembler bonnes, entre autres problèmes potentiels, un modèle réentraîné peut avoir une empreinte environnementale plus importante et interrompre l’environnement serveur.
Quand l’accès aux données de production est disponible uniquement en production, utilisez le contrôle d’accès RBAC Azure et les rôles personnalisés pour octroyer à un certain nombre de spécialistes du machine learning l’accès en lecture. Certains rôles peuvent avoir besoin de lire les données pour l’exploration des données associées. Vous pouvez également faire une copie des données disponible dans les environnements hors production.
Établissez des conventions de nommage et des étiquettes pour les expérimentations Azure Machine Learning afin de différencier le réentraînement des pipelines de machine learning de référence des travaux expérimentaux.
Technology
Si vous soumettez actuellement des travaux via l’IU (interface utilisateur) d’Azure Machine Learning studio ou l’interface CLI, au lieu de les soumettre via le SDK, utilisez l’interface CLI ou les tâches Azure DevOps pour le machine learning afin de configurer les étapes du pipeline d’automatisation. Ce processus peut réduire l’empreinte du code en réutilisant les mêmes soumissions de travaux directement à partir des pipelines d’automatisation.
Utilisez la programmation basée sur les événements. Par exemple, déclenchez un pipeline de test de modèle hors connexion à l’aide d’Azure Functions après l’enregistrement d’un nouveau modèle. Ou envoyez une notification à un alias d’e-mail désigné quand un pipeline critique ne s’exécute pas. Azure Machine Learning crée des événements dans Azure Event Grid. Plusieurs rôles peuvent s’abonner pour être avertis d’un événement.
Quand vous employez Azure DevOps dans le cadre de l’automatisation, utilisez les tâches Azure DevOps pour le machine learning afin de vous servir des modèles Machine Learning en tant que déclencheurs de pipeline.
Quand vous développez des packages Python pour votre application de machine learning, vous pouvez les héberger dans un dépôt Azure DevOps sous forme d’artefacts et les publier en tant que flux. Grâce à cette approche vous pouvez intégrer le workflow DevOps pour créer des packages avec votre espace de travail Azure Machine Learning.
Vous pouvez utiliser un environnement de préproduction pour tester l’intégration du système aux pipelines de machine learning avec des composants d’application amont ou aval.
Créer des tests unitaires et d’intégration pour vos points de terminaison d’inférence afin d’améliorer le débogage et d’accélérer le déploiement.
Pour déclencher le réentraînement, utilisez les moniteurs de jeux de données et les workflows pilotés par les événements. Souscrivez aux événements de dérive de données et automatisez le déclencheur de pipelines de Machine Learning pour le réentraînement.
Fabrique d’intelligence artificielle pour les opérations d’apprentissage automatique de l’organisation
Une équipe de science des données peut décider de gérer en interne plusieurs cas d’usage du machine learning. L’adoption des opérations de Machine Learning permet à une organisation de configurer des équipes de projet pour une meilleure qualité, fiabilité et facilité de maintenance des solutions. Grâce aux équipes équilibrées, aux processus pris en charge et à l’automatisation de la technologie, une équipe qui adopte des opérations de Machine Learning peut évoluer et se concentrer sur le développement de nouveaux cas d’usage.
Au fur et à mesure que le nombre de cas d’usage augmente dans une organisation, la charge de gestion liée à la prise en charge des cas d’usage augmente de manière linéaire, voire exponentielle. Le défi pour l’organisation devient la façon d’accélérer le temps de commercialisation, de soutenir l’évaluation plus rapide de la faisabilité des cas d’usage, de mettre en œuvre la répétabilité et de mieux utiliser les ressources disponibles et les ensembles de compétences sur un éventail de projets. Pour de nombreuses organisations, le développement d’une fabrique d’IA est la solution.
Une fabrique d’IA est un système de processus métier reproductibles et d’artefacts standardisés qui facilitent le développement et le déploiement d’un grand ensemble de cas d’usage de Machine Learning. Une fabrique d’IA optimise la configuration de l’équipe, les pratiques recommandées, la stratégie des opérations de Machine Learning, les modèles architecturaux et les modèles réutilisables adaptés aux besoins de l’entreprise.
Une fabrique d’IA réussie repose sur des processus répétables et de ressources réutilisables qui peuvent aider une organisation à passer efficacement des dizaines de cas d’usage à des milliers de cas d’usage.
La figure suivante récapitule les éléments clés d’une fabrique d’IA :

Standardiser les modèles architecturaux reproductibles
La répétabilité est une caractéristique clé d’une fabrique d’IA. Les équipes de science des données peuvent accélérer le développement de projets et améliorer la cohérence entre les projets en développant quelques modèles architecturaux reproductibles qui couvrent la plupart des cas d’usage du machine learning pour leur organisation. Quand ces modèles sont en place, la plupart des projets peuvent les utiliser et tirer parti des avantages suivants :
- Phase de conception accélérée
- Approbations accélérées pour les équipes informatiques et de sécurité quand elles réutilisent les outils dans d’autres projets
- Développement accéléré grâce à une infrastructure réutilisable sous forme de modèles de code et de modèles de projet
Les modèles architecturaux peuvent inclure, mais sans s’y limiter, les sujets suivants :
- Services préférés pour chaque phase du projet
- Connectivité des données et gouvernance
- Stratégie d’opérations de Machine Learning adaptée aux impératifs du secteur, de l’entreprise ou de la classification des données
- Modèles de champion et de challenger de gestion des expériences
Faciliter la collaboration et le partage entre les équipes
Les dépôts de code partagés et les utilitaires peuvent accélérer le développement de solutions de machine learning. Les référentiels de code peuvent être développés de manière modulaire au cours du projet afin d’être suffisamment génériques pour pouvoir être utilisés dans d’autres projets. Ils peuvent être mis à disposition dans un dépôt centralisé accessible à toutes les équipes de science des données.
Partage et réutilisation de la propriété intellectuelle
Pour optimiser la réutilisation du code, vous devez passer en revue la propriété intellectuelle suivante au début d’un projet :
- Code interne conçu pour réutiliser dans l’organisation. Les exemples incluent des packages et des modules.
- Jeux de données créés dans d’autres projets de machine learning, ou disponibles dans l’écosystème Azure.
- Projets de science des données existants ayant une architecture et des problèmes métier similaires.
- Référentiels GitHub ou open source qui peuvent accélérer le projet.
Toute rétrospective de projet doit inclure un élément d’action pour déterminer si les éléments du projet peuvent être partagés et généralisés pour une réutilisation plus large. La liste des ressources que l’organisation peut partager et réutiliser s’étend au fil du temps.
Afin de faciliter le partage et la découverte, de nombreuses entreprises ont introduit des dépôts partagés pour organiser les extraits de code et les artefacts de machine learning. Les artefacts dans Azure Machine Learning, notamment les jeux de données, les modèles, les environnements et les pipelines, peuvent être définis sous forme de code, ce qui vous permet de les partager efficacement entre les projets et les espaces de travail.
Modèles de projet
Pour accélérer le processus de migration des solutions existantes et optimiser la réutilisation du code, de nombreuses organisations normalisent sur un modèle de projet pour lancer de nouveaux projets. Les exemples de modèles de projet recommandés pour une utilisation avec Azure Machine Learning sont les exemples Azure Machine Learning, le processus DSLP (Data Science Lifecycle Process) et le processus TDSP (Team Data Science Process).
Gestion des données centralisée
Le processus d’accès aux données à des fins d’exploration ou de production peut prendre du temps. De nombreuses entreprises centralisent la gestion de leurs données pour rapprocher les producteurs et les consommateurs de données pour faciliter l’accès aux données à des fins d’expérimentation du machine learning.
Utilitaires partagés
Votre organisation peut utiliser des tableaux de bord centralisés à l’échelle de l’entreprise pour consolider les informations de journalisation et de surveillance. Les tableaux de bord peuvent inclure la journalisation des erreurs, la disponibilité du service et la télémétrie et la surveillance des performances du modèle.
Utilisez les métriques Azure Monitor pour construire un tableau de bord pour Azure Machine Learning et les services associés comme le Stockage Azure. Un tableau de bord vous aide à suivre la progression de l’expérimentation, l’intégrité de l’infrastructure de calcul et l’utilisation du quota GPU.
Une équipe d’ingénierie spécialisée en machine learning
De nombreuses organisations ont implémenté le rôle de l’ingénieur Machine Learning. Un ingénieur Machine Learning se spécialise dans la création et l’exécution de pipelines Machine Learning robustes, la surveillance de dérive et le réentraînement des flux de travail et des tableaux de bord de supervision. L’ingénieur a la responsabilité globale de l’industrialisation de la solution Machine Learning, du développement à la production. L’ingénieur travaille en étroite collaboration avec l’Engineering données, les architectes ainsi que les équipes sécurité et opérations pour garantir la mise en place de tous les contrôles nécessaires.
La science des données nécessite une expertise approfondie du domaine, alors que l’ingénierie du machine learning est plutôt une approche plus technique. La différence rend l’ingénieur Machine Learning plus flexible, afin qu’il puisse travailler sur différents projets et avec différents services d’entreprise. Une équipe d’ingénierie spécialisée dans le machine learning peut tirer parti de manière efficace des pratiques de science des données à grande échelle en implémentant la répétabilité et la réutilisation des workflows d’automatisation dans divers cas d’usage et services métier.
Activation et documentation
Il est important de fournir des conseils d’aide clairs sur le processus de fabrique d’IA aux équipes et aux utilisateurs (nouveaux ou existants). Les conseils permettent de garantir la cohérence et de réduire l’effort requis par l’équipe d’ingénierie du Machine Learning lorsqu’il industrialise un projet. Concevez du contenu spécifiquement pour les différents rôles de votre organisation.
Chacun ayant un style d’apprentissage unique, un mélange des types d’aides suivants peut accélérer l’adoption du framework de fabrique d’IA :
- Un hub central qui a des liens vers tous les artefacts. Par exemple, ce hub peut être un canal sur Microsoft Teams ou un site Microsoft SharePoint.
- Plan de formation et d’activation conçu pour chaque rôle.
- Une présentation récapitulative de haut-niveau de l’approche et une vidéo d’accompagnement.
- Un document détaillé ou guide opérationnel.
- Vidéos pratiques.
- Évaluations de l’état de préparation.
Série de vidéo sur les opérations de Machine Learning dans Azure
Une série vidéo sur les opérations de Machine Learning dans Azure vous montre comment établir des opérations de Machine Learning pour votre solution Machine Learning, du développement initial à la production.
Éthique
L’éthique joue un rôle déterminant dans la conception d’une solution d’IA. En l’absence d’implémentation de principes éthiques, les modèles entraînés peuvent présenter le même biais que les données à partir desquels ils ont été entraînés. Le résultat peut être que le projet est arrêté. Plus important encore, la réputation de l’organisation peut être à risque.
Pour garantir l’implémentation dans les projets des principes éthiques clés que l’entreprise défend, l’entreprise doit fournir une liste de ces principes et les moyens de les valider d’un point de vue technique durant la phase de test. Utilisez les fonctionnalités de Machine Learning dans Azure Machine Learning pour comprendre ce qui est responsable du Machine Learning et comment la créer dans vos opérations de Machine Learning.
Étapes suivantes
Apprenez-en davantage sur l’organisation et la configuration des environnements Azure Machine Learning ou regardez une série vidéo pratique sur les opérations de Machine Learning dans Azure.
En savoir plus sur la gestion des budgets, des quotas et des coûts au niveau de l’organisation à l’aide d’Azure Machine Learning :