Gérer les budgets, les coûts et les quotas pour Azure Machine Learning à l’échelle de l’organisation
Lorsque vous gérez les coûts de calcul liés à Azure Machine Learning, à l’échelle d’une organisation, avec un grand nombre de charges de travail, d’équipes et d’utilisateurs, vous avez de nombreux problèmes de gestion et d’optimisation à résoudre.
Cet article présente les meilleures pratiques pour optimiser les coûts, gérer les budgets et partager les quotas avec Azure Machine Learning. Il reflète l’expérience et les enseignements recueillis auprès d’équipes utilisant l’apprentissage automatique en interne chez Microsoft et en partenariat avec nos clients. Vous découvrirez comment effectuer les actions suivantes :
- Optimiser les ressources de calcul pour répondre aux exigences de charge de travail.
- Optimiser l’utilisation du budget d’une équipe.
- Planifier, gérer et partager des budgets, des coûts et des quotas à l’échelle d’une entreprise.
Optimiser les ressources de calcul pour répondre aux exigences de charge de travail
Lorsque vous démarrez un nouveau projet d’apprentissage automatique, il se peut que vous deviez effectuer un travail exploratoire pour obtenir une image précise des besoins en matière de calcul. Cette section fournit des recommandations sur la façon de déterminer le choix de la référence (SKU) de machine virtuelle appropriée pour l’apprentissage, l’inférence ou l’utilisation en tant que station de travail.
Déterminer la taille de calcul pour l’apprentissage
La configuration matérielle requise pour votre charge de travail d’apprentissage peut varier d’un projet à l’autre. Pour répondre à ces exigences, la solution de calcul Azure Machine Learning propose différents types de machines virtuelles :
- Usage général : ratio processeur/mémoire équilibré.
- À mémoire optimisée : ratio mémoire/processeur élevé.
- Optimisée pour le calcul : ratio processeur/mémoire élevé.
- Calcul haute performance : performances, scalabilité et rentabilité de premier plan pour diverses charges de travail de calcul haute performance réelles.
- Instances avec GPU : machines virtuelles spécialisées, conçues pour l’affichage de graphiques complexes et le montage vidéo, ainsi que pour la formation et l’inférence de modèles à l’aide du Deep Learning.
Vous ne connaissez peut-être pas encore vos besoins en matière de calcul. Dans ce scénario, nous vous recommandons de commencer avec l’une des options rentables par défaut suivantes. Ces options sont destinées aux tests légers et aux charges de travail d’apprentissage.
| Type | Taille de la machine virtuelle | Spécifications |
|---|---|---|
| Processeur | Standard_DS3_v2 | 4 cœurs, 14 gigaoctets (Go) de RAM, 28 Go de stockage |
| GPU | Standard_NC6 | 6 cœurs, 56 gigaoctets (Go) de RAM, 380 Go de stockage, GPU NVIDIA Tesla K80 |
Pour déterminer la taille de machine virtuelle optimale pour votre scénario, il se peut que vous deviez procéder par tâtonnement. Voici quelques aspects à prendre en compte.
- Si vous avez besoin d’une UC :
- Utilisez une machine virtuelle à mémoire optimisée si vous effectuez l’apprentissage sur des jeux de données volumineux.
- Utilisez une machine virtuelle optimisée pour le calcul si vous effectuez des inférences en temps réel ou d’autres tâches sensibles à la latence.
- Utilisez une machine virtuelle avec davantage de cœurs et de RAM pour accélérer les temps d’apprentissage.
- Si vous avez besoin d’un GPU, consultez les tailles de machines virtuelles optimisées pour GPU afin d’obtenir des informations sur la sélection d’une machine virtuelle.
- Si vous effectuez un apprentissage distribué, utilisez des tailles de machine virtuelle avec plusieurs GPU.
- Si vous effectuez un apprentissage distribué sur plusieurs nœuds, utilisez des GPU disposant de connexions NVLink.
Lorsque vous sélectionnez le type de machine virtuelle et la référence (SKU) correspondant le mieux à votre charge de travail, évaluez des références (SKU) de machine virtuelle comparables afin de trouver un compromis entre les performances de l’UC et du GPU, et la tarification. Du point de vue de la gestion des coûts, un travail peut s’exécuter correctement sur plusieurs références (SKU).
Certains GPU, tels ceux de la famille NC, en particulier les références (SKU) NC_Promo, offrent des capacités similaires à celles d’autres GPU, telles qu’une faible latence et l’aptitude à gérer plusieurs charges de travail de calcul en parallèle. Ils sont disponibles à des prix avantageux par rapport à d’autres GPU. Au final, une sélection attentive de références (SKU) de machine virtuelle adaptées à la charge de travail peut contribuer à réduire considérablement les coûts.
Un rappel concernant l’importance de l’utilisation est que l’exécution d’un plus grand nombre de GPU ne produit pas nécessairement des résultats plus rapides. Au lieu de cela, assurez-vous que les GPU sont pleinement utilisés. Par exemple, vérifiez soigneusement la nécessité de la technologie NVIDIA CUDA. Bien qu’elle soit parfois requise pour l’exécution d’un GPU haute performance, il se peut que votre travail n’en dépende pas.
Déterminer la taille de calcul pour l’inférence
Les exigences de calcul pour les scénarios d’inférence diffèrent des scénarios d’apprentissage. Les options disponibles varient selon que votre scénario nécessite une inférence hors connexion par lots ou requiert une inférence en ligne en temps réel.
Pour les scénarios d’inférence en temps réel, tenez compte des suggestions suivantes :
- Utilisez les fonctionnalités de profilage de votre modèle avec Azure Machine Learning pour déterminer la quantité de processeur et de mémoire que vous devez allouer au modèle lorsque vous le déployez en tant que service web.
- Si vous effectuez une inférence en temps réel mais n’avez pas besoin d’une haute disponibilité, opérez un déploiement vers Azure Container Instances (aucune sélection de référence SKU).
- Si vous effectuez une inférence en temps réel et avez besoin d’une haute disponibilité, opérez un déploiement vers Azure Kubernetes Service.
- Si vous utilisez des modèles Machine Learning traditionnels et recevez < 10 requêtes par seconde, commencez par une référence (SKU) de processeur. Les références SKU de la série F fonctionnent souvent bien.
- Si vous utilisez des modèles Deep Learning et recevez > 10 requêtes par seconde, essayez une référence (SKU) de GPU NVIDIA (NCasT4_v3 fonctionne souvent bien) avec Triton.
Pour les scénarios d’inférence par lots, tenez compte des suggestions suivantes :
- Lorsque vous utilisez des pipelines Azure Machine Learning pour effectuer une inférence par lots, suivez les conseils fournis dans Déterminer la taille de calcul pour l’apprentissage pour choisir votre taille de machine virtuelle initiale.
- Optimisez les coûts et les performances en effectuant une mise à l’échelle horizontale. L’une des principales méthodes d’optimisation des coûts et des performances consiste à paralléliser la charge de travail à l’aide d’une étape d’exécution parallèle dans Azure Machine Learning. Cette étape de pipeline vous permet d’utiliser un grand nombre de nœuds plus petits pour exécuter la tâche en parallèle, de façon à pouvoir effectuer une mise à l’échelle horizontale. La parallélisation entraîne cependant une surcharge. Une étape d’exécution parallèle peut être indiquée ou non selon la charge de travail et le degré de parallélisme qui peut être obtenu.
Déterminer la taille de l’instance de calcul
Pour un développement interactif, une instance de calcul d’Azure Machine Learning est recommandée. L’offre d’instance de calcul utilise un calcul sur nœud unique lié à un utilisateur unique, et peut être utilisée en tant que station de travail cloud.
Certaines organisations interdisent l’utilisation de données de production sur des stations de travail locales, imposent des restrictions à l’environnement de station de travail ou restreignent l’installation de packages et de dépendances dans leur environnement informatique. Vous pouvez utiliser une instance de calcul comme station de travail pour surmonter la limitation. Cette solution offre un environnement sécurisé avec accès aux données de production, et s’exécute sur des images fournies avec des packages et outils populaires préinstallés pour la science des données.
Quand l’instance de calcul s’exécute, l’utilisateur est facturé pour le calcul de la machine virtuelle, le service Standard Load Balancer (règles de trafic sortant incluses et données traitées), le disque du système d’exploitation (disque P10 géré par SSD Premium), un disque temporaire (dont le type dépend de la taille de machine virtuelle choisie) et une adresse IP publique. Afin de réduire les coûts, nous recommandons aux utilisateurs de tenir compte des recommandations suivantes :
- Démarrez et arrêtez l’instance de calcul quand elle n’est pas utilisée.
- Travaillez avec un échantillon de vos données sur une instance de calcul, et effectuez un scale-out afin d’exploiter les clusters de calcul pour pouvoir utiliser votre jeu de données au complet.
- Envoyez les travaux d’expérimentation en mode cible de calcul local sur l’instance de calcul en phase de développement ou de test, ou lorsque vous passez à une capacité de calcul partagée au moment d’envoyer des travaux à pleine échelle. Par exemple, avec de nombreuses époques, un jeu complet de données et une recherche d’hyperparamètre.
Si vous arrêtez l’instance de calcul, cela a pour effet d’arrêter la facturation des heures de calcul de machine virtuelle, du disque temporaire et du coût des données traitées par le service Standard Load Balancer. Notez que l’utilisateur continue de payer pour le disque du système d’exploitation et les règles de trafic sortant incluses du service Standard Load Balancer, même lorsque l’instance de calcul est arrêtée. Toutes les données enregistrées sur le disque du système d’exploitation sont conservées après arrêt et redémarrage.
Ajuster la taille de machine virtuelle choisie en surveillant l’utilisation du calcul
Vous pouvez consulter les informations sur l’usage et l’utilisation du calcul Azure Machine Learning via Azure Monitor. Vous pouvez voir des détails sur le déploiement et l’inscription du modèle, des détails de quota tels que les nœuds actifs et inactifs, des détails d’exécution tels que les exécutions annulées et terminées, ainsi que l’utilisation du calcul du GPU et du processeur.
En vous basant sur les insights extraits des détails de la surveillance, vous pouvez mieux planifier ou ajuster l’utilisation de vos ressources au sein de l’équipe. Par exemple, si vous remarquez un grand nombre de nœuds inactifs au cours de la semaine passée, vous pouvez travailler avec les propriétaires d’espace de travail correspondants pour mettre à jour la configuration du cluster de calcul afin d’éviter ce coût supplémentaire. Les avantages liés à l’analyse des modèles d’utilisation peuvent faciliter la prévision des coûts et l’amélioration du budget.
Vous pouvez accéder à ces métriques directement à partir du portail Azure. Accédez à votre espace de travail Azure Machine Learning, puis, dans la section surveillance du volet gauche, sélectionnez Métriques. Ensuite, vous pouvez sélectionner des détails sur ce que vous souhaitez voir, comme les métriques, l’agrégation et la période. Pour plus d’informations, consultez la page de documentation Superviser Azure Machine Learning.
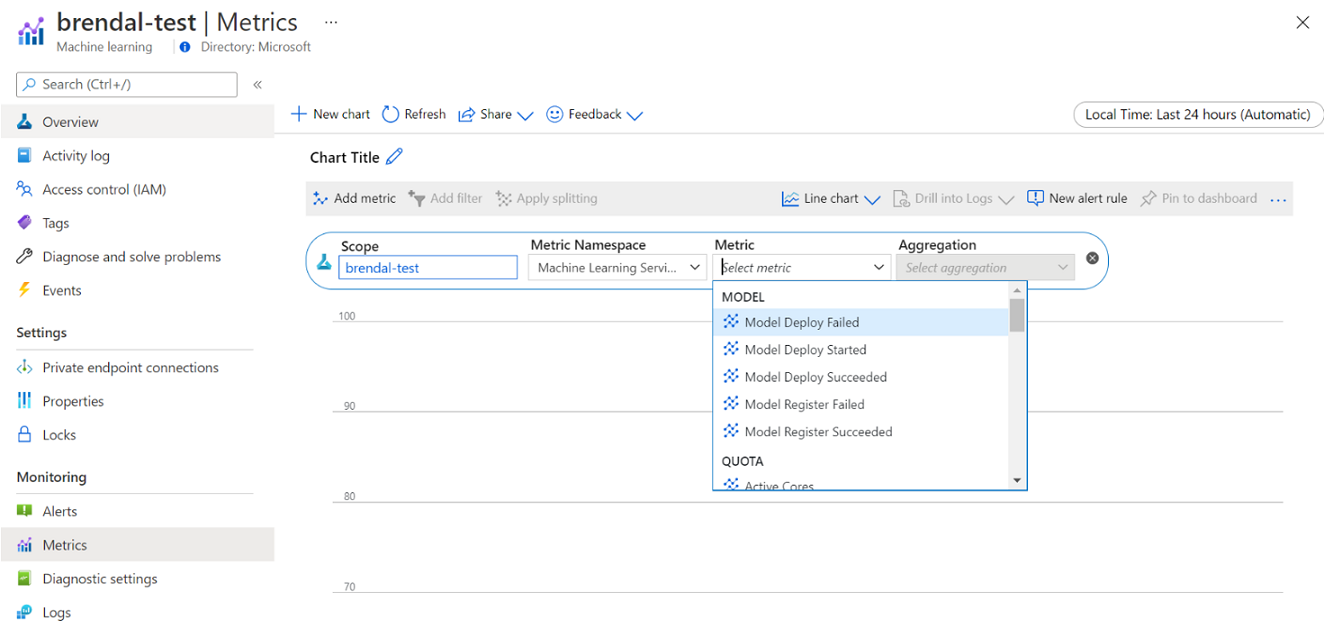
Basculer entre le calcul de cloud local, à nœud unique et à plusieurs nœuds pendant le développement
Les besoins de calcul et d’outillage varient tout au long du cycle de vie de l’apprentissage automatique. Pour répondre à ces besoins, la solution Azure Machine Learning peut s’interfacer avec un Kit de développement logiciel (SDK) et une interface CLI, à partir de pratiquement toute configuration de station de travail.
Pour réduire les coûts et travailler de manière productive, nous vous recommandons de procéder comme suit :
- Clonez votre base de code d’expérimentation localement en utilisant Git, et envoyez des travaux au calcul cloud à l’aide du Kit de développement logiciel (SDK) Azure Machine Learning ou de l’interface CLI.
- Si votre jeu de données est volumineux, envisagez de gérer un échantillon de vos données sur votre station de travail locale, tout en conservant le jeu de données complet sur un stockage cloud.
- Paramétrez votre base de code d’expérimentation afin de pouvoir configurer vos travaux pour qu’ils s’exécutent avec un nombre variable d’époques ou sur des jeux de données de différentes tailles.
- Ne codez pas en dur le chemin d’accès au dossier de votre jeu de données. Vous pourrez ensuite facilement réutiliser la même base de code avec des jeux de données différents, et dans un contexte d’exécution locale et dans le cloud.
- Amorcez vos travaux d’expérimentation en mode cible de calcul local lors des phases de développement ou de test, ou lorsque vous basculez vers une capacité de cluster de calcul partagé au moment d’envoyer des tâches à pleine échelle.
- Si votre jeu de données est volumineux, utilisez un échantillon de données sur votre station de travail locale ou d’instance de calcul, tout en procédant à une mise à l’échelle vers le calcul cloud dans Azure Machine Learning afin travailler avec votre jeu de données au complet.
- Lorsque l’exécution de vos travaux prend beaucoup de temps, envisagez d’optimiser votre base de code pour un apprentissage distribué afin de permettre une montée en charge horizontale.
- Concevez vos charges de travail de formation distribuées pour l’élasticité des nœuds, afin de permettre une utilisation flexible du calcul sur nœud unique et sur plusieurs nœuds, et de faciliter l’utilisation du calcul pouvant être anticipé.
Combiner des types de calcul à l’aide de pipelines Azure Machine Learning
Lorsque vous orchestrez vos flux de travail d’apprentissage automatique, vous pouvez définir un pipeline comportant plusieurs étapes. Chaque étape du pipeline peut s’exécuter sur son propre type de calcul. Cela vous permet d’optimiser les performances et le coût pour répondre à des exigences de calcul variables durant le cycle de vie de l’apprentissage automatique.
Optimiser l’utilisation du budget d’une équipe
Si les décisions d’allocation budgétaire échappent souvent au contrôle d’une équipe individuelle, celle-ci est généralement habilitée à utiliser le budget alloué à sa guise. En trouvant un compromis judicieux entre la priorité des travaux, les performances et les coûts, une équipe peut obtenir une utilisation de cluster plus élevée, réduire le coût global et profiter d’un plus grand nombre d’heures de calcul avec le même budget. Cela peut entraîner une productivité accrue de l’équipe.
Optimiser les coûts de ressources de calcul partagées
La clé pour optimiser les coûts de ressources de calcul partagées consiste à s’assurer qu’elles sont utilisées à leur pleine capacité. Voici quelques conseils pour optimiser les coûts de vos ressources partagées :
- Lorsque vous utilisez des instances de calcul, ne les activez que lorsque vous avez du code à exécuter. Arrêtez-les lorsqu’elles ne sont pas utilisées.
- Lorsque vous utilisez des clusters de calcul, définissez le nombre minimal de nœuds sur 0, et le nombre maximal sur ce que vous évaluez en fonction de vos contraintes budgétaires. Utilisez la Calculatrice de prix Azure pour calculer le coût d’utilisation complète d’un nœud de machine virtuelle de la référence (SKU) de machine virtuelle de votre choix. La mise à l’échelle automatique effectue un scale-down de tous les nœuds de calcul lorsque personne ne les utilise. Elle effectue un scale-up uniquement jusqu’au nombre de nœuds que vous budgétisez. Vous pouvez configurer la mise à l’échelle automatique pour effectuer un scale-down de tous les nœuds de calcul.
- Surveillez l’utilisation de vos ressources, telles que le processeur et le GPU, lors de l’apprentissage de modèles. Si les ressources ne sont pas entièrement utilisées, modifiez votre code pour mieux les exploiter, ou effectuez un scale-down vers des tailles de machine virtuelle plus petites ou plus économiques.
- Déterminez si vous pouvez créer des ressources de calcul partagées pour votre équipe afin d’éviter les inefficacités de calcul occasionnées par les opérations de mise à l’échelle du cluster.
- Optimisez les stratégies de délai d’attente de mise à l’échelle automatique de cluster de calcul en fonction des métriques d’utilisation.
- Utilisez des quotas d’espace de travail pour contrôler la quantité de ressources de calcul auxquelles les espaces de travail individuels ont accès.
Introduire une priorité de planification en créant des clusters pour plusieurs références (SKU) de machine virtuelle
En cas de contrainte de quota et de budget, une équipe doit trouver un compromis entre l’exécution des travaux en temps opportun et le coût, afin de s’assurer que les travaux importants s’exécutent à temps et que le budget soit utilisé le mieux possible.
Pour optimiser l’utilisation du calcul, il est recommandé aux équipes de créer des clusters de différentes tailles avec des machines virtuelles basse priorité et dédiées . Les calculs basse priorité utilisant une capacité excédentaire dans Azure, il bénéficient de tarifs réduits. En revanche, ces machines peuvent être préemptées à chaque fois qu’une demande de priorité supérieure leur est adressée.
En utilisant les clusters de taille et de priorité variables, vous pouvez introduire une notion de priorité de planification. Par exemple, lorsque des travaux expérimentaux et de production rivalisent pour le même quota de GPU NC, le travail de production peut prendre le pas sur l’exécution du travail expérimental. Dans ce cas, exécutez le travail de production sur le cluster de calcul dédié et le travail expérimental sur le cluster de calcul basse priorité. Lorsque le quota s’épuise, le travail expérimental est suspendu en faveur du travail de production.
Outre la priorité des machines virtuelles, envisagez d’exécuter des travaux sur différents types de machines virtuelles. Il peut arriver que l’exécution prenne plus de temps sur une instance de machine virtuelle équipée d’un GPU P40 que sur une instance équipée d’un GPU V100. Toutefois, étant donné que des instances de machine virtuelle V100 peuvent être occupées ou voir leur quota entièrement utilisé, il se peut que le temps d’exécution sur le GPU P40 soit plus court en raison du débit de travail. Vous pouvez également envisager d’exécuter des travaux de priorité inférieure sur des instances de machine virtuelle moins performantes et plus économiques dans une perspective de gestion des coûts.
Mettre fin prématurément à l’exécution d’un travail quand l’apprentissage ne converge pas
Lorsque vous expérimentez pour améliorer un modèle par rapport à sa ligne de base, vous pouvez être amené à conduire différentes expérimentations avec des configurations légèrement différentes. Pour une exécution, vous pouvez modifier les jeux de données en entrée. Pour une autre, vous pouvez modifier un hyperparamètre. Les modifications ne sont pas forcément toutes aussi efficaces les uns que les autres. Vous détectez rapidement qu’un changement n’a pas eu l’effet escompté sur la qualité d’apprentissage de votre modèle. Pour détecter si un apprentissage ne converge pas, surveillez le progrès de l’apprentissage en cours d’exécution. Par exemple, en enregistrant les métriques de performances après chaque période d’apprentissage. Envisagez de mettre fin prématurément au travail afin de libérer des ressources et du budget pour un autre essai.
Planifier, gérer et partager des budgets, des coûts et des quotas
À mesure qu’une organisation augmente son nombre de cas d’usage et d’équipes d’apprentissage automatique, elle a besoin d’une maturité opérationnelle accrue de la part des services informatiques et financiers, ainsi que d’une coordination entre les différentes équipes d’apprentissage automatique pour garantir l’efficacité des opérations. Une gestion de la capacité et des quotas à l’échelle de l’entreprise devient importante pour faire face à la rareté des ressources informatiques et aux frais de gestion.
Cette section décrit les meilleures pratiques en matière de planification, de gestion et de partage des budgets, des coûts et des quotas à l’échelle de l’entreprise. Elle est basée sur les enseignements tirés de la gestion de nombreuses ressources d’apprentissage par GPU pour l’apprentissage automatique en interne chez Microsoft.
Compréhension des dépenses en ressources avec Azure Machine Learning
L’un des plus grands défis auquel peut se heurter un administrateur pour la planification des besoins de calcul est de partir de zéro, sans aucune information historique pouvant servir d’estimation de base. D’un point de vue pratique, la plupart des projets commencent par un petit budget.
Pour comprendre à quoi le budget est dépensé, il est essentiel de comprendre d’où viennent les coûts liés à Azure Machine Learning :
- Azure Machine Learning ne facture que l’infrastructure de calcul utilisée et n’ajoute aucun surcoût aux coûts de calcul.
- Lors de la création d’un espace de travail Azure Machine Learning, quelques autres ressources sont également créées pour activer Azure Machine Learning, à savoir, Azure Key Vault, Application Insights, Stockage Azure et Azure Container Registry. Ces ressources sont utilisées dans Azure Machine Learning et vous payez elles.
- Des sont coûts associés au calcul managé, par exemple, pour les clusters d’apprentissage, les instances de calcul et les points de terminaison d’inférence gérés. Avec ces ressources de calcul managé, il faut prendre en compte les coûts d’infrastructure suivants : machines virtuelles, réseau virtuel, équilibreur de charge, bande passante et stockage.
Suivre les habitudes de dépense et générer de meilleurs rapports grâce à l’étiquetage
Les administrateurs veulent souvent suivre les coûts sur différentes ressources dans Azure Machine Learning. L’étiquetage est une solution naturelle à ce problème et s’aligne sur l’approche générale utilisée par Azure et de nombreux autres fournisseurs de services cloud. Grâce à la prise en charge des étiquettes, vous pouvez désormais voir la répartition des coûts au niveau du calcul et accéder à une vue plus détaillée pour améliorer le monitoring des coûts, les rapports et la transparence.
La catégorisation vous permet de placer des indicateurs personnalisés sur vos espaces de travail et calculs (à partir de modèles Azure Resource Manager et d’Azure Machine Learning studio) pour filtrer davantage ces ressources dans Microsoft Cost Management selon ces étiquettes et observer les habitudes de dépense. Cette fonctionnalité est idéale dans les scénarios de rétrofacturation interne. En outre, les balises peuvent être utiles pour capturer des métadonnées ou des détails associés au calcul, tels qu’un projet, une équipe ou un certain code de facturation. La catégorisation est donc très utile pour mesurer le montant des dépenses consacrées aux différentes ressources et, par conséquent, pour mieux comprendre les coûts et les schémas de dépenses au sein des équipes ou des projets.
Par ailleurs, des balises injectées par le système sont placées sur les ressources de calcul. Vous pouvez ainsi filtrer la page Analyse des coûts sur la balise « Type de calcul » pour afficher la répartition par ressource de calcul de vos dépenses totales et identifier la catégorie de ressources de calcul à l’origine de la majorité de vos coûts. Cette information se révèle particulièrement utile pour gagner en visibilité sur les modèles de coûts d’apprentissage et d’inférence.
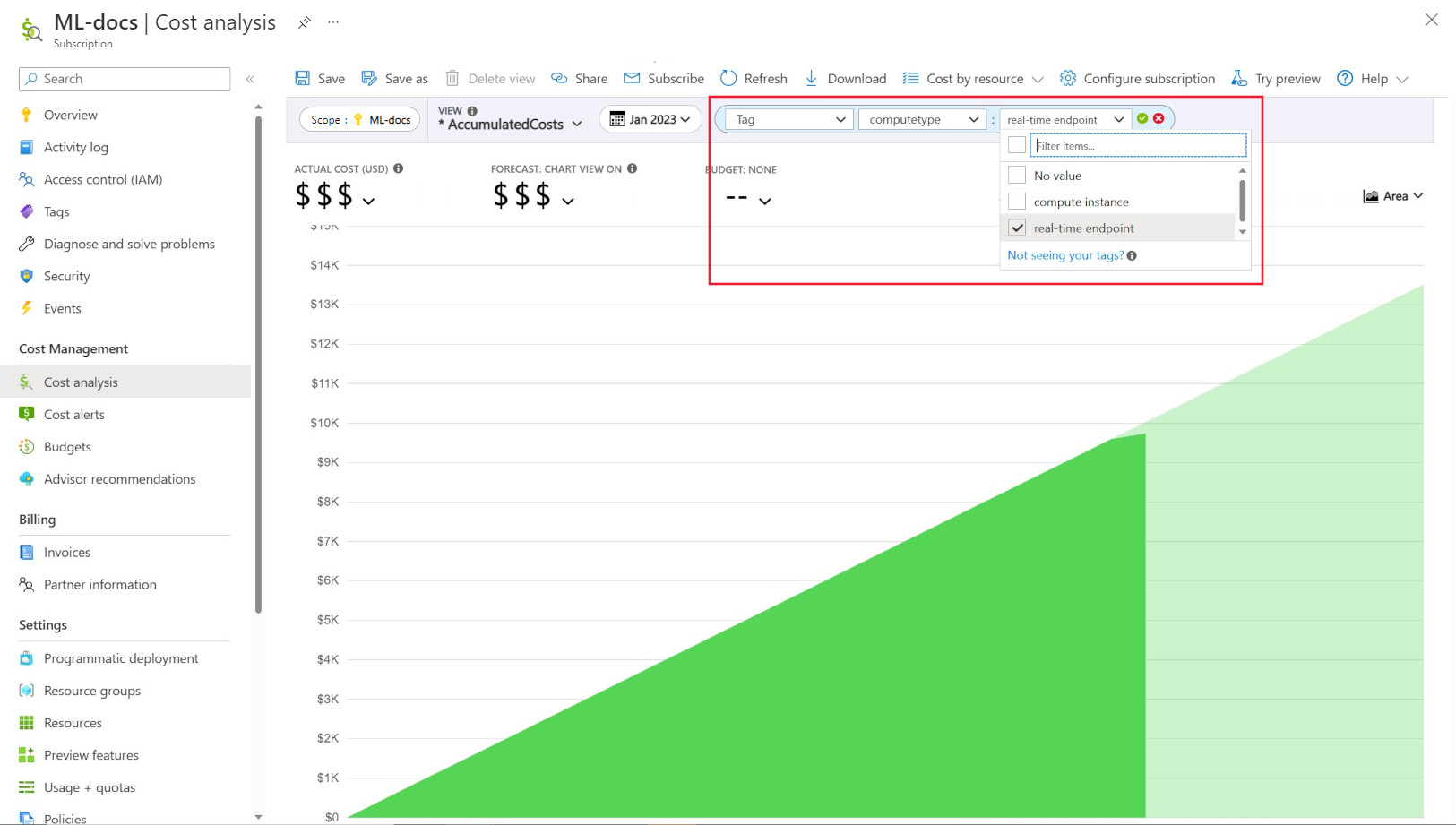
Régir et restreindre l’utilisation du calcul par stratégie
Lorsque vous gérez un environnement Azure avec de nombreuses charges de travail, il peut être difficile de garder une vue d’ensemble des dépenses en ressources. Azure Policy peut vous aider à contrôler et à régir les dépenses en ressources, en restreignant les modèles d’utilisation particuliers dans l’environnement Azure.
Dans le cas d’Azure Machine Learning, nous recommandons de mettre en place des stratégies pour n’autoriser que l’utilisation de références (SKU) de machines virtuelles spécifiques. Des stratégies peuvent aider à prévenir et à contrôler la sélection l’usage de machines virtuelles coûteuses. Elles permettent également d’imposer l’utilisation de références (SKU) de machines virtuelles basse priorité.
Allouer et gérer les quotas en fonction des priorités
Azure vous permet de fixer des limites à l’allocation de quota sur un abonnement et un niveau d’espace de travail Azure Machine Learning. Restreindre les personnes autorisées à gérer les quotas grâce au contrôle d’accès en fonction du rôle (RBAC) Azure peut vous aider à veiller à l’utilisation des ressources et à la prévisibilité des coûts.
La disponibilité des quotas de GPU peut être rare dans vos abonnements. Pour garantir une utilisation élevée des quotas dans les charges de travail, nous vous recommandons de vérifier si les quotas sont utilisés et attribués de manière optimale dans les charges de travail.
Chez Microsoft, nous déterminons périodiquement si les quotas de GPU sont utilisés et répartis entre les équipes d’apprentissage automatique de manière optimale en évaluant les besoins en capacité par rapport aux priorités.
Engager la capacité à l’avance
Si vous avez une bonne estimation du volume de calcul qui sera utilisé au cours de l’année prochaine ou des années suivantes, vous pouvez acheter des instances de machines virtuelles réservées Azure à prix réduit. Il existe des conditions d’achat d’une durée de 1 an ou de 3 ans. Étant donné que les instances de machines virtuelles réservées Azure font l’objet d’une remise, il est possible de réaliser des économies conséquentes par rapport aux tarifs de paiement à l’utilisation.
Azure Machine Learning prend en charge les instances de calcul réservées. Les remises sont automatiquement appliquées au calcul managé par Azure Machine Learning.
Gérer la conservation des données
Chaque fois qu’un pipeline d’apprentissage automatique est exécuté, des jeux de données intermédiaires peuvent être générés à chaque étape du pipeline pour la mise en cache et la réutilisation des données. La croissance des données en sortie de ces pipelines d’apprentissage automatique peut devenir problématique pour une organisation qui effectue de nombreuses expérimentations d’apprentissage automatique.
Les scientifiques des données ne passent généralement pas leur temps à nettoyer les jeux de données intermédiaires qui sont générés. Au fil du temps, les données générées s’accumulent. Le service Stockage Azure permet d’améliorer la gestion du cycle de vie des données. La gestion du cycle de vie par le service Stockage Blob Azure vous permet de configurer des stratégies générales pour déplacer des données inutilisées vers des niveaux de stockage froid afin de réduire les coûts.
Considérations relatives à l’optimisation des coûts d’infrastructure
Mise en réseau
Le coût de la mise en réseau Azure provient de la bande passante sortante du centre de données Azure. Toutes les données entrantes dans un centre de données Azure sont gratuites. La clé pour réduire le coût du réseau est de déployer autant que possible toutes vos ressources dans la même région de centre de données. Si vous pouvez déployer l’espace de travail et le calcul d’Azure Machine Learning dans la région où se trouvent vos données, vous pouvez bénéficier d’un coût moindre et de performances supérieures.
Vous souhaitez peut-être avoir une connexion privée entre votre réseau local et votre réseau Azure afin de disposer d’un environnement cloud hybride. ExpressRoute vous permet de le faire mais, compte tenu du coût élevé du service, il est peut-être plus rentable de renoncer à une configuration de cloud hybride et de transférer toutes les ressources vers le cloud Azure.
Azure Container Registry
Pour Azure Container Registry, les facteurs déterminants pour l’optimisation du coûts sont les suivants :
- Débit requis pour les téléchargements d’images Docker à partir du registre de conteneurs vers Azure Machine Learning
- Configuration requise pour les fonctionnalités de sécurité d’entreprise, telles qu’Azure Private Link
Pour les scénarios de production nécessitant un débit élevé ou une sécurité d’entreprise, la référence (SKU) Premium d’Azure Container Registry est recommandé.
Pour les scénarios de dev/test où le débit et la sécurité sont moins critiques, nous recommandons la référence (SKU) Standard ou Premium.
La référence (SKU) De base d’Azure Container Registry n’est pas recommandée pour Azure Machine Learning. Elle n’est pas recommandée en raison de son faible débit et de la faible capacité de stockage incluse, qui peut être rapidement dépassée par la taille relativement importante des images Docker (plus de 1 o) d’Azure Machine Learning.
Considérer la disponibilité du type de calcul lors du choix des régions Azure
Lorsque vous choisissez une région pour votre calcul, gardez à l’esprit la disponibilité du quota de calcul. Les régions populaires et de grande taille, telles que USA Est, USA Ouest et Europe Ouest, ont tendance à offrir des valeurs de quotas par défaut plus élevées et une plus grande disponibilité pour la plupart des CPU et GPU, par rapport à d’autres régions où des restrictions de capacité plus strictes sont en place.
En savoir plus
Étapes suivantes
Pour en savoir plus sur l’organisation et la configuration des environnements Azure Machine Learning, consultez Organiser et configurer des environnements Azure Machine Learning.
Pour en savoir plus sur les meilleures pratiques en matière de DevOps avec Azure Machine Learning, consultez le guide du DevOps avec Machine Learning.