Créer et gérer des ressources de données
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Cet article explique comment créer et gérer des ressources de données dans Azure Machine Learning.
Les ressources de données peuvent vous aider quand vous avez besoin des éléments suivants :
- Contrôle de version : les ressources de données prennent en charge le contrôle de version des données.
- Reproductibilité : une fois que vous avez créé une version de ressource de données, elle est immuable. Elle ne peut pas être modifiée ni supprimée. Par conséquent, les pipelines ou les travaux d’apprentissage qui consomment la ressource de données peuvent être reproduits.
- Vérifiabilité : étant donné que la version de la ressource de données est immuable, vous pouvez suivre les versions de la ressource, qui a mis à jour une version et quand les mises à jour de version se sont produites.
- Traçabilité : pour une ressource de données spécifique, vous pouvez afficher les travaux ou pipelines qui consomment les données.
- Facilité d’utilisation : une ressource de données Azure Machine Learning ressemble aux signets de navigateur web (favoris). Au lieu de mémoriser des chemins de stockage longs (URI) qui référencent vos données fréquemment utilisées dans le Stockage Azure, vous pouvez créer une version de ressource de données, puis accéder à cette version de la ressource avec un nom convivial (par exemple :
azureml:<my_data_asset_name>:<version>).
Conseil
Pour accéder à vos données dans une session interactive (par exemple, un notebook) ou dans un travail, vous n’êtes pas obligé de créer d’abord une ressource de données. Vous pouvez utiliser des URI de magasin de données pour accéder aux données. Les URI de magasin de données offrent un moyen simple d’accéder aux données pour prendre en main Azure Machine Learning.
Prérequis
Pour créer et utiliser des ressources de données, vous avez besoin des éléments suivants :
Un abonnement Azure. Si vous n’en avez pas, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning.
Un espace de travail Azure Machine Learning. Créer des ressources d’espace de travail.
Créer des ressources de données
Lorsque vous créez votre ressource de données, vous devez définir le type de ressource de données. Azure Machine Learning prend en charge trois types de ressources de données :
| Type | API | Scénarios canoniques |
|---|---|---|
| File Référencer un seul fichier |
uri_file |
Lire un seul fichier dans le Stockage Azure (le fichier peut avoir n’importe quel format). |
| Folder Référencer un dossier |
uri_folder |
Lire un dossier de fichiers Parquet/CSV dans Pandas/Spark. Lire des données non structurées (images, texte, audio, etc.) situées dans un dossier. |
| Table Référencer une table de données |
mltable |
Vous avez un schéma complexe qui fait l’objet de modifications fréquentes ou vous avez besoin d’un sous-ensemble de données tabulaires de grande taille. AutoML avec des tables. Lire des données non structurées (images, texte, audio, etc.) qui sont réparties sur plusieurs emplacements de stockage. |
Remarque
Utilisez uniquement des nouvelles lignes incorporées dans des fichiers csv si vous inscrivez les données en tant que MLTable. De nouvelles lignes incorporées dans les fichiers csv peuvent entraîner des valeurs de champ mal alignées lorsque vous lisez les données. MLTable dispose du paramètre support_multi_line disponible dans la transformation read_delimited pour interpréter les sauts de ligne entre guillemets comme un enregistrement.
Lorsque vous consommez la ressource de données dans un travail Azure Machine Learning, vous pouvez monter ou télécharger la ressource sur le ou les nœuds de calcul. Pour plus d’informations, consultez Modes.
En outre, vous devez spécifier un paramètre de path qui pointe vers l’emplacement des données. Les chemins pris en charge comprennent :
| Emplacement | Exemples |
|---|---|
| Chemin sur votre ordinateur local | ./home/username/data/my_data |
| Chemin dans un magasin de données | azureml://datastores/<data_store_name>/paths/<path> |
| Chemin sur un serveur http(s) public | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Chemin dans Stockage Azure | (Blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Notes
Lorsque vous créez une ressource de données à partir d’un chemin local, elle est automatiquement chargée dans le magasin de données Azure Machine Learning par défaut dans le cloud.
Créer une ressource de données : type Fichier
Une ressource de données de type Fichier (uri_file) pointe vers un fichier unique sur le stockage (par exemple, un fichier CSV). Vous pouvez créer une ressource de données de type fichier à l’aide de :
Créez un fichier YAML et copiez-collez l’extrait de code suivant. Veillez à mettre à jour les espaces réservés <> avec
- le nom de votre ressource de données
- la version
- description
- le chemin d’accès à un fichier unique sur un emplacement pris en charge
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Ensuite, exécutez la commande suivante dans l’interface CLI. Veillez à mettre à jour l’espace réservé <filename> avec le nom de fichier YAML.
az ml data create -f <filename>.yml


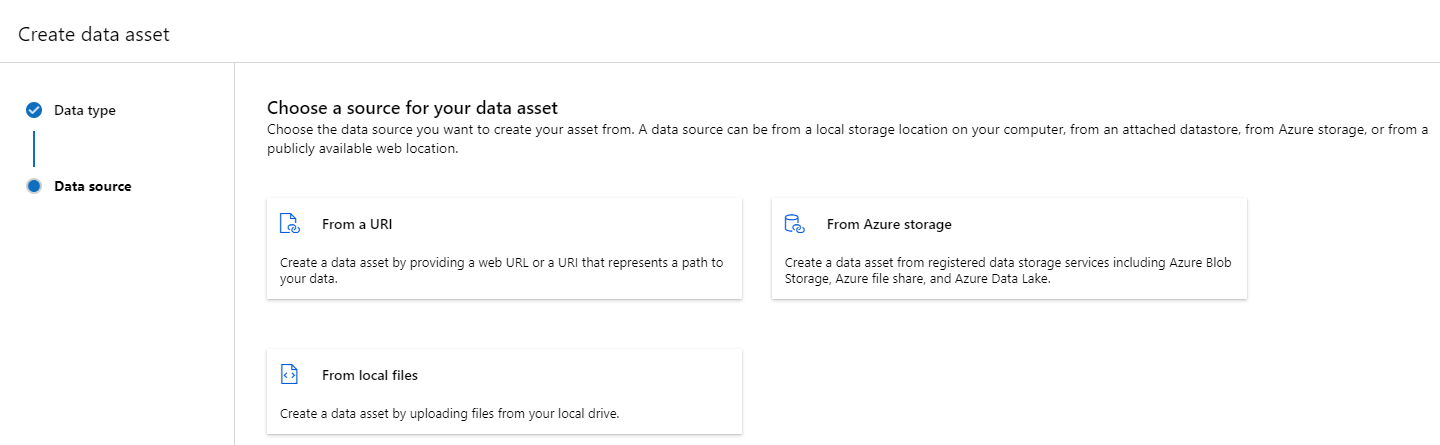
Créer une ressource de données : type Dossier
Une ressource de données de type Dossier (uri_folder) pointe vers un dossier dans une ressource de stockage (par exemple, un dossier contenant plusieurs sous-dossiers d’images). Vous pouvez créer une ressource de données de type dossier à l’aide de :
Copiez-collez le code suivant dans un nouveau fichier YAML. Veillez à mettre à jour les espaces réservés <> avec
- Le nom de votre ressource de données
- la version
- Description
- le chemin d’accès à un dossier sur un emplacement pris en charge
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Ensuite, exécutez la commande suivante dans l’interface CLI. Veillez à mettre à jour l’espace réservé <filename> avec le nom de fichier YAML.
az ml data create -f <filename>.yml

Créer une ressource de données : type Table
Les tables Azure Machine Learning (MLTable) disposent de fonctionnalités enrichies, décrites plus en détail dans Utilisation des tables dans Azure Machine Learning. Au lieu de répéter cette documentation ici, lisez cet exemple qui décrit la création d’une ressource de données de type Table, avec des données Titanic situées sur un compte Stockage Blob Azure disponible publiquement.
Tout d’abord, créez un répertoire nommé Data et créez un fichier appelé MLTable :
mkdir data
touch MLTable
Ensuite, copiez et collez le YAML suivant dans le fichier MLTable que vous avez créé à l'étape précédente :
Attention
Ne renommez pas le fichier MLTableMLTable.yaml ou MLTable.yml. Azure Machine Learning attend un fichier MLTable.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Exécutez la commande suivante dans l’interface CLI. Veillez à mettre à jour les espaces réservés <> avec le nom et la version de la ressource de données.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Important
Le path doit être un dossier qui contient un fichier MLTable valide.
Création de ressources de données à partir des sorties du travail
Vous pouvez créer une ressource de données à partir d’un travail Azure Machine Learning. Pour ce faire, définissez le paramètre name dans la sortie. Dans cet exemple, vous envoyez un travail qui copie les données d’un magasin public d’objets blob vers votre magasin de données Azure Machine Learning par défaut et crée une ressource de données appelée job_output_titanic_asset.
Créez un fichier YAML de spécification de travail (<file-name>.yml) :
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Ensuite, envoyez le travail à l’aide de l’interface CLI :
az ml job create --file <file-name>.yml
Gérer les ressources de données
Créer une ressource de données
Important
Par conception, la suppression de ressources de données n’est pas prise en charge.
Si Azure Machine Learning autorisait la suppression de ressources de données, cela aurait les effets négatifs suivants :
- Les travaux de production qui consomment des ressources de données qui ont été supprimées ultérieurement échouent.
- Il deviendrait plus difficile de reproduire une expérience ML.
- La traçabilité des travaux serait rompue, car il deviendrait impossible d’afficher la version de la ressource de données supprimée.
- Vous ne serez pas en mesure de suivre et auditer correctement, car il pourrait manquer des versions.
Par conséquent, l’immuabilité des ressources de données offre un niveau de protection lorsque vous travaillez en équipe pour créer des charges de travail de production.
Pour une ressource de données créée par erreur, par exemple, avec un nom, un type ou un chemin d’accès incorrects, Azure Machine Learning offre des solutions pour gérer la situation sans les conséquences négatives de la suppression :
| Je souhaite supprimer cette ressource de données parce que... | Solution |
|---|---|
| Le nom est incorrect | Archivez la ressource de données |
| L’équipe n’utilise plus la ressource de données | Archivez la ressource de données |
| Elle encombre la liste des ressources de données | Archivez la ressource de données |
| Le chemin d’accès est incorrect | Créez une nouvelle version de la ressource de données (même nom) avec le chemin d’accès correct. Pour plus d’informations, consultez Créer des ressources de données. |
| Elle a un type incorrect | Actuellement, Azure Machine Learning n’autorise pas la création d’une nouvelle version avec un type différent de la version initiale. (1) Archivez la ressource de données (2) Créez une ressource de données sous un autre nom avec le type correct. |
Archiver une ressource de données
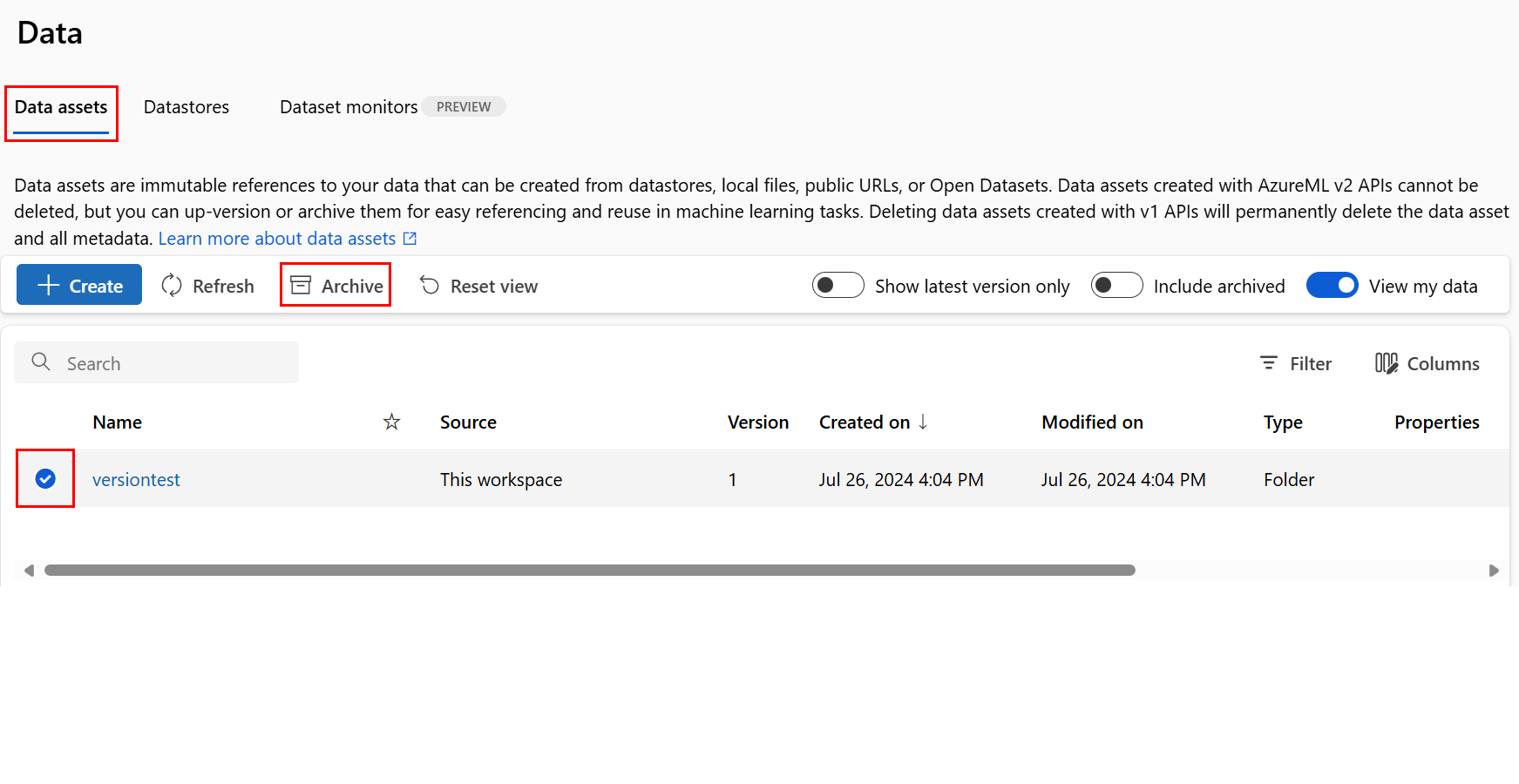
L’archivage d’une ressource de données la masque par défaut à partir des requêtes de liste (par exemple, dans l’interface CLI az ml data list) et de la liste des ressources de données dans l’interface utilisateur de Studio. Vous pouvez continuer à référencer et utiliser une ressource de données archivée dans vos flux de travail. Vous pouvez archiver les éléments suivants :
- Toutes les versions de la ressource de données sous un nom donné
or
- Une version spécifique de la ressource de données
Archiver toutes les versions d’une ressource de données
Pour archiver toutes les versions de la ressource de données sous un nom donné, utilisez :
Exécutez la commande suivante. Veillez à mettre à jour les espaces réservés <> avec vos informations.
az ml data archive --name <NAME OF DATA ASSET>
Archiver une version spécifique de la ressource de données
Pour archiver une version de ressource de données spécifique, utilisez :
Exécutez la commande suivante. Veillez à mettre à jour les espaces réservés <> avec le nom et la version de votre ressource de données.
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
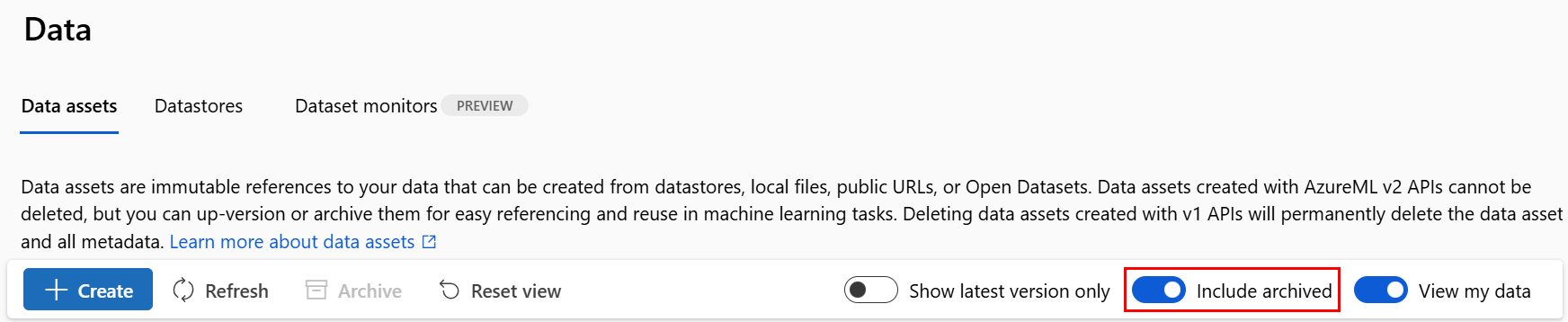
Restaurer une ressource de données archivée
Vous pouvez restaurer une ressource de données archivée. Si toutes les versions de la ressource de données sont archivées, vous ne pouvez pas restaurer des versions individuelles de la ressource de données. Vous devez restaurer toutes les versions.
Restaurer toutes les versions d’une ressource de données
Pour restaurer toutes les versions de la ressource de données sous un nom donné, utilisez :
Exécutez la commande suivante. Veillez à mettre à jour les espaces réservés <> avec le nom de votre ressource de données.
az ml data restore --name <NAME OF DATA ASSET>
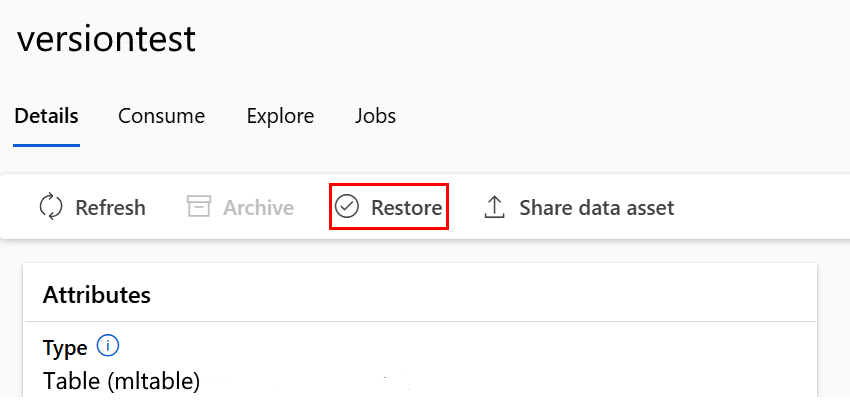
Restaurer une version spécifique de la ressource de données
Important
Si toutes les versions de la ressource de données ont été archivées, vous ne pouvez pas restaurer des versions individuelles de la ressource de données. Vous devez restaurer toutes les versions.
Pour archiver une version spécifique de la ressource de données, utilisez :
Exécutez la commande suivante. Veillez à mettre à jour les espaces réservés <> avec le nom et la version de votre ressource de données.
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Lignage des données
La traçabilité des données est comprise au sens large comme le cycle de vie qui couvre l’origine des données et leur parcours au fil du temps dans le stockage. Différents types de scénarios de recherche descendante l’utilisent, par exemple
- Dépannage
- Traçage des causes racines dans les pipelines ML
- Débogage
Les scénarios d’analyse de la qualité des données, de conformité et hypothétiques utilisent également la traçabilité. La traçabilité est représentée visuellement pour montrer les données migrant de la source vers la destination, et couvre les transformations de données. Étant donné la complexité de la plupart des environnements de données d’entreprise, ces vues peuvent devenir difficiles à comprendre sans effectuer de consolidation ou de masquage des points de données périphériques.
Dans un pipeline Azure Machine Learning, les ressources de données indiquent l’origine des données et la façon dont elles ont été traitées, par exemple :
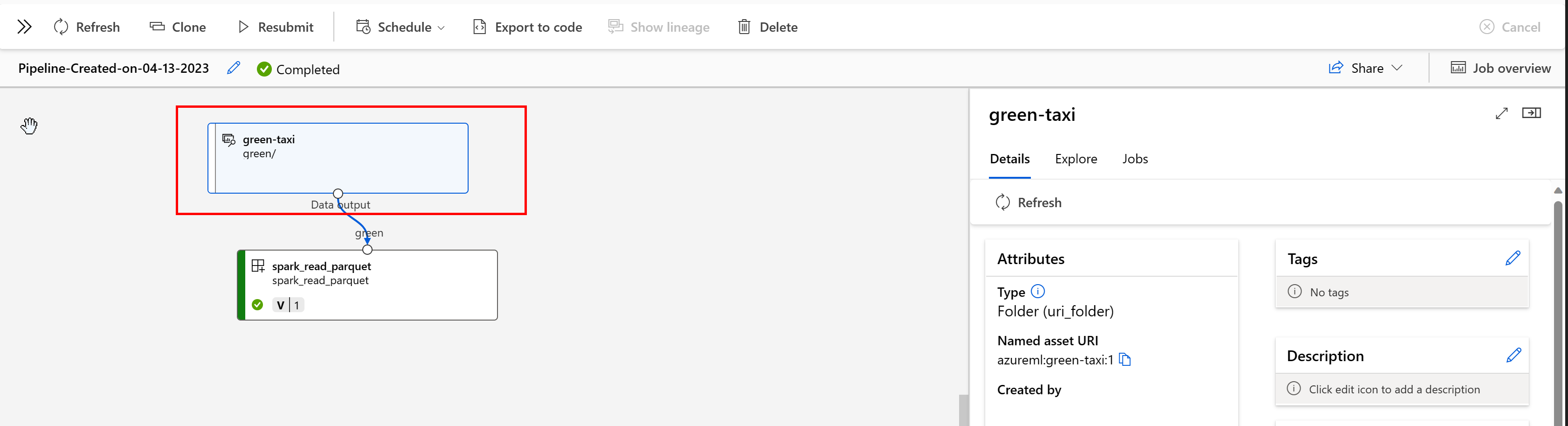
Vous pouvez afficher les travaux qui consomment la ressource de données dans l’interface utilisateur de Studio. Tout d’abord, sélectionnez Données dans le menu de gauche, puis sélectionnez le nom de la ressource de données. Notez les travaux qui consomment la ressource de données :
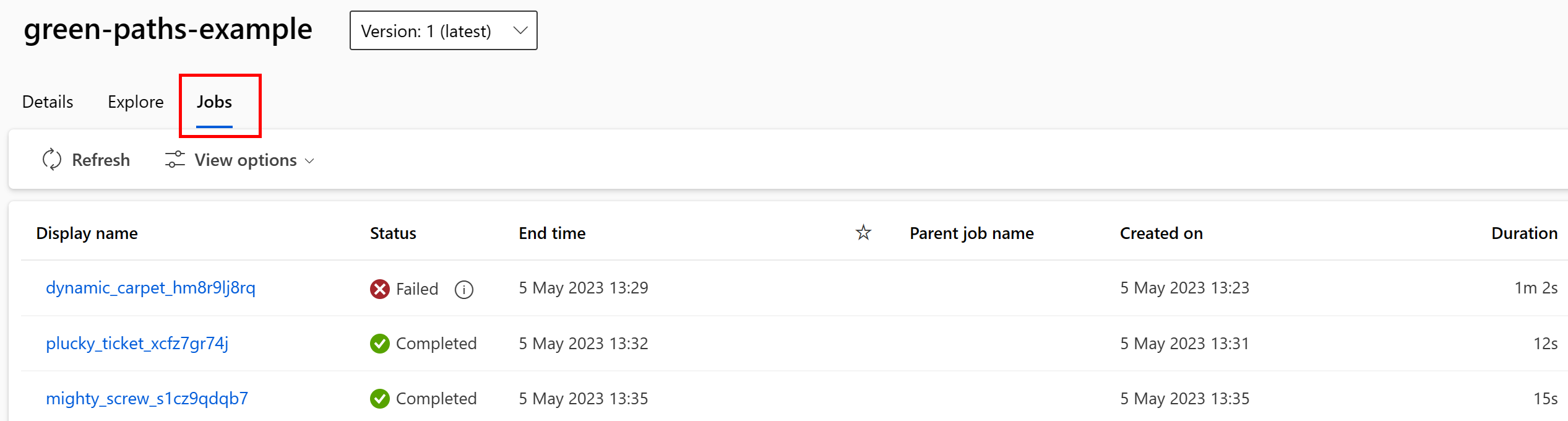
La vue Tâches dans les ressources de données facilite la recherche des défaillances des travaux, ainsi que l’analyse des causes racines dans vos pipelines ML et le débogage.
Étiquetage des ressources de données
Les ressources de données prennent en charge la catégorisation, qui consiste en des métadonnées supplémentaires appliquées à la ressource de données sous la forme d’une paire clé-valeur. L’étiquetage des données offre de nombreux avantages :
- Description de la qualité des données. Par exemple, si votre organisation utilise une architecture Lakehouse en médaillon, vous pouvez baliser les actifs avec
medallion:bronze(brut),medallion:silver(validé) etmedallion:gold(enrichi). - Recherche et filtrage efficaces des données pour faciliter leur découverte.
- Identification des données personnelles sensibles pour gérer et régir correctement l’accès aux données. Par exemple :
sensitivity:PII/sensitivity:nonPII. - Détermination de l’approbation ou non des données par un audit IA responsable (RAI). Par exemple :
RAI_audit:approved/RAI_audit:todo.
Vous pouvez ajouter des balises aux ressources de données dans le cadre de leur flux de création, ou vous pouvez ajouter des balises à des ressources de données existantes. Cette section présente les deux :
Ajouter des balises dans le cadre du flux de création de ressource de données
Créez un fichier YAML et copiez-collez le code suivant dans ce fichier YAML. Veillez à mettre à jour les espaces réservés <> avec
- le nom de votre ressource de données
- la version
- description
- les balises (paires clé-valeur)
- le chemin d’accès à un fichier unique sur un emplacement pris en charge
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Exécutez la commande suivante dans l’interface CLI. Veillez à mettre à jour l’espace réservé <filename> avec le nom de fichier YAML.
az ml data create -f <filename>.yml
Ajouter des étiquettes à une ressource de données existante
Exécutez la commande suivante dans Azure CLI. Veillez à mettre à jour les espaces réservés <> avec
- Le nom de votre ressource de données
- La version
- La paire clé-valeur pour la balise
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Meilleures pratiques relatives aux versions
En règle générale, vos processus ETL organisent votre structure de dossiers dans le stockage Azure en fonction du temps, par exemple :
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
La combinaison de dossiers structurés temps/version et de tables Azure Machine Learning (MLTable) vous permet de construire des jeux de données avec version. Un exemple hypothétique montre comment obtenir des données avec version avec des tables Azure Machine Learning. Supposons que vous ayez un processus qui charge des images d’un appareil photo vers Stockage Blob Azure toutes les semaines, dans la structure suivante :
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Remarque
Bien que nous montrons comment versionner des données d’image (jpeg), la même approche fonctionne pour n’importe quel type de fichier (par exemple, Parquet, CSV).
Avec les tables Azure Machine Learning (mltable), construisez une table de chemins qui inclut les données jusqu’à la fin de la première semaine en 2023. Ensuite, créez une ressource de données :
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
À la fin de la semaine suivante, votre ETL a mis à jour les données pour en inclure davantage :
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
La première version (20230108) continue de monter/télécharger des fichiers uniquement à partir de year=2022/week=52 et year=2023/week=1, car les chemins sont déclarés dans le fichier MLTable. Cela garantit la reproductibilité de vos expériences. Pour créer une nouvelle version de la ressource de données qui inclut year=2023/week2, utilisez :
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Vous disposez maintenant de deux versions des données, où le nom de la version correspond à la date à laquelle les images ont été chargées dans le stockage :
- 20230108 : Les images jusqu’au 8 janvier 2023.
- 20230115 : Les images jusqu’au 15 janvier 2023.
Dans les deux cas, MLTable construit une table de chemins qui incluent uniquement les images jusqu’à ces dates.
Dans un travail Azure Machine Learning, vous pouvez monter ou télécharger ces chemins d’accès dans la MLTable avec versions sur votre cible de calcul à l’aide des modes eval_download ou eval_mount :
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Notes
Les modes eval_mount et eval_download sont propres à MLTable. Dans ce cas, la fonctionnalité de runtime des données AzureML évalue le fichier MLTable et monte les chemins d’accès sur la cible de calcul.