Performances et mise à l’échelle dans Fonctions durables (Azure Functions)
Pour optimiser les performances et l’évolutivité, il est important de comprendre les caractéristiques uniques de mise à l’échelle de Fonctions durables. Dans cet article, nous expliquons comment les workers sont mis à l’échelle en fonction de la charge et comment il est possible d’ajuster les différents paramètres.
Mise à l’échelle des workers
L’un des avantages fondamentaux du concept du hub de tâches est que le nombre de workers qui traitent les éléments de travail du hub de tâches peut être ajusté en permanence. En particulier, les applications peuvent ajouter plus de workers (effectuer un scale-out) si le travail doit être traité plus rapidement et peut supprimer des workers (effectuer un scale-in) s’il n’y a pas assez de travail pour maintenir les workers occupés. Il est même possible de mettre à l’échelle à zéro si le hub de tâches est complètement inactif. Lorsqu’il est mis à l’échelle à zéro, il n’y a pas du tout de workers ; seul le contrôleur de mise à l’échelle et le stockage doivent rester actifs.
Le schéma suivant illustre ce concept :
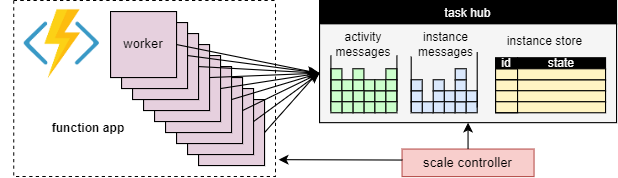
Mise à l’échelle automatique
Comme avec toutes les Azure Functions exécutées dans les plans Consommation et Élastique Premium, Durable Functions prend en charge la mise à l’échelle automatique par le biais du contrôleur de mise à l’échelle Azure Functions. Le contrôleur de mise à l’échelle surveille la durée pendant laquelle les messages et les tâches doivent attendre avant d’être traités. En fonction de ces latences, il peut décider d’ajouter ou de supprimer des workers.
Notes
À partir de Durable Functions 2.0, les applications de fonction peuvent être configurées de sorte qu’elles s’exécutent au sein des points de terminaison de service protégés par VNET dans le plan Élastique Premium. Dans cette configuration, Durable Functions déclenche des demandes de mise à l’échelle initiées au lieu du contrôleur de mise à l’échelle. Pour plus d’informations, consultez Surveillance de la mise à l’échelle du runtime.
Sur un plan Premium, la mise à l’échelle automatique peut aider à conserver le nombre de workers (et par conséquent le coût d’exploitation) à peu près proportionnel à la charge que l’application rencontre.
Utilisation de l’UC
Les fonctions d’orchestrateur exécutent leur logique plusieurs fois en raison de leur comportement de relecture. Il est par conséquent important que les threads de fonction d’orchestrateur n’effectuent pas de tâches nécessitant une utilisation intensive du processeur, n’effectuent pas d’opérations d’E/S ou se bloquent pour une raison quelconque. Tout travail susceptible de nécessiter un thread d’E/S, un blocage ou plusieurs threads doit être transféré vers les fonctions d’activité.
Les fonctions d’activité ont les mêmes comportements que les fonctions normales déclenchées par une file d’attente. Elles peuvent effectuer en toute sécurité des opérations d’E/S ou des opérations gourmandes en ressources de processeur et utiliser plusieurs threads. Étant donné que les déclencheurs d’activité sont sans état, ils peuvent librement effectuer un scale-out sur un nombre illimité de machines virtuelles.
Les fonctions d’entité sont également exécutées sur un thread unique et les opérations sont traitées une par une. Toutefois, les fonctions d’entité n’ont aucune restriction quant au type de code qui peut être exécuté.
Délais d’expiration des fonctions
Les fonctions d’activité, d’orchestrateur et d’entité sont soumises aux mêmes délais d’expiration de fonction que toutes les Azure Functions. En règle générale, Durable Functions traite les délais d’attente des fonctions de la même façon que les exceptions non gérées levées par le code de l’application.
Par exemple, si une activité expire, l’exécution de la fonction est enregistrée comme un échec, et l’orchestrateur est averti et gère le délai d’attente comme toute autre exception : de nouvelles tentatives ont lieu si elles sont spécifiées par l’appel, ou un gestionnaire d’exceptions peut être exécuté.
Traitement par lot des opérations d’entité
Pour améliorer les performances et réduire les coûts, un seul élément de travail peut exécuter un lot entier d’opérations d’entité. Sur les plans de consommation, chaque lot est ensuite facturé en tant qu’une seule exécution de fonction.
Par défaut, la taille de lot maximale est de 50 pour les plans de consommation ou de 5 000 pour tous les autres plans. La taille de lot maximale peut également être configurée dans le fichier host.json. Si la taille de lot maximale est 1, le traitement par lot est de fait désactivé.
Notes
Si l’exécution des opérations d’entité individuelles prend beaucoup de temps, il peut être avantageux de limiter la taille de lot maximale pour réduire le risque d’expiration de délai de fonction, en particulier sur les plans de consommation.
Mise en cache d’instance
En règle générale, pour traiter un élément de travail d’orchestration, un worker doit à la fois
- récupérer l’historique d’orchestration ;
- relire le code d’orchestrateur à l’aide de l’historique.
Si le même worker traite plusieurs éléments de travail pour la même orchestration, le fournisseur de stockage peut optimiser ce processus en mettant en cache l’historique dans la mémoire du worker, ce qui élimine la première étape. En outre, il peut mettre en cache l’orchestrateur d’exécution, qui élimine la deuxième étape, la relecture de l’historique, aussi.
L’effet classique de la mise en cache est une entrée/sortie réduite par rapport au service de stockage sous-jacent, et un débit et une latence globaux améliorés. En revanche, la mise en cache augmente la consommation de mémoire sur le worker.
La mise en cache d’instance est actuellement prise en charge par le fournisseur de Stockage Azure et par le fournisseur de stockage Netherite. La table ci-dessous fournit une comparaison.
| Fournisseur Stockage Azure | Fournisseur de stockage Netherite | Fournisseur de stockage MSSQL | |
|---|---|---|---|
| Mise en cache d’instance | Pris en charge (worker in-process .NET uniquement) |
Pris en charge | Non pris en charge |
| Paramètre par défaut | Désactivé | activé | n/a |
| Mécanisme | Sessions étendues | Cache d’instance | n/a |
| Documentation | Voir Sessions étendues | Voir Cache d’instance | n/a |
Conseil
La mise en cache peut réduire la fréquence de relecture des historiques, mais elle ne peut pas éliminer complètement la relecture. Lors du développement d’orchestrateurs, nous vous recommandons vivement de les tester sur une configuration qui désactive la mise en cache. Le comportement de relecture forcée par défaut peut être utile pour détecter les violations des contraintes du code de la fonction d’orchestrateur lors du développement.
Comparaison des mécanismes de mise en cache
Les fournisseurs utilisent différents mécanismes pour implémenter la mise en cache et offrent différents paramètres pour configurer le comportement de mise en cache.
-
Les sessions étendues, telles qu’utilisées par le fournisseur de Stockage Azure, conservent les orchestrateurs d’exécution intermédiaire en mémoire jusqu’à ce qu’ils soient inactifs pendant un certain temps. Les paramètres permettant de contrôler ce mécanisme sont
extendedSessionsEnabledetextendedSessionIdleTimeoutInSeconds. Pour plus d’informations, consultez la section Sessions étendues de la documentation du fournisseur de Stockage Azure.
Notes
Les sessions étendues sont prises en charge uniquement dans le worker in-process .NET.
- Le cache d’instance, tel qu’utilisé par le fournisseur de stockage Netherite, conserve l’état de toutes les instances, y compris leurs historiques, dans la mémoire du worker, tout en conservant le suivi de la mémoire totale utilisée. Si la taille du cache dépasse la limite configurée par
InstanceCacheSizeMB, les données d’instance les moins récemment utilisées sont supprimées. SiCacheOrchestrationCursorsest défini sur true, le cache stocke également les orchestrateurs d’exécution intermédiaire ainsi que l’état de l’instance. Pour plus d’informations, consultez la section Cache d’instance de la documentation du fournisseur de stockage Netherite.
Notes
Les caches d’instance fonctionnent pour tous les kits de développement logiciel (SDK) de langage, mais l’option CacheOrchestrationCursors est disponible uniquement pour le worker in-process .NET.
Limitations de la concurrence
Une seule instance de travail peut exécuter plusieurs éléments de travail simultanément. Cela permet d’augmenter le parallélisme et d’utiliser plus efficacement les workers. Toutefois, si un worker tente de traiter trop d’éléments de travail en même temps, il peut épuiser ses ressources disponibles, telles que la charge du processeur, le nombre de connexions réseau ou la mémoire disponible.
Pour vous assurer qu’un worker individuel ne survalide pas, il peut être nécessaire de limiter la concurrence par instance. En limitant le nombre de fonctions qui s’exécutent simultanément sur chaque worker, nous pouvons éviter d’épuiser les limites de ressources sur ce worker.
Notes
Les limitations de concurrence s’appliquent uniquement localement pour limiter les éléments en cours de traitement par worker. Ainsi, ces limitations ne limitent pas le débit total du système.
Conseil
Dans certains cas, la limitation de la concurrence par worker peut réellement augmenter le débit total du système. Cela peut se produire lorsque chaque worker prend moins de travail, ce qui entraîne le contrôleur de mise à l’échelle à ajouter davantage de workers aux files d’attente, ce qui augmente ensuite le débit total.
Configuration des limitations
Les limites de concurrence des fonctions d’activité, d’orchestrateur et d’entité peuvent être configurées dans le fichier host.json. Les paramètres pertinents sont durableTask/maxConcurrentActivityFunctions pour les fonctions d’activité et durableTask/maxConcurrentOrchestratorFunctions pour les fonctions d’orchestrateur et d’entité. Ces paramètres contrôlent le nombre maximal de fonctions d’orchestrateur, d’entité ou d’activité qui sont chargés en mémoire par un seul worker.
Notes
Les orchestrations et les entités sont chargées dans la mémoire uniquement lorsqu’elles traitent activement des événements ou des opérations, ou si la mise en cache est activée. Après avoir exécuté leur logique et attendu (par exemple pour une instruction await (C#) ou yield (JavaScript, Python) dans le code de la fonction d’orchestrateur), elles peuvent être déchargées de la mémoire. Les orchestrations et les entités qui sont déchargées de la mémoire ne sont pas comptabilisées dans la limitation maxConcurrentOrchestratorFunctions. Même si des millions d’orchestrations ou d’entités sont dans l’état « En cours d’exécution », elles n’entrent en compte que dans le calcul de la limite lorsqu’elles sont chargées dans la mémoire active. Une orchestration qui planifie une fonction d’activité de la même manière ne compte pas dans le calcul de la limite si l’orchestration attend la fin de l’exécution de l’activité.
Functions 2.0
{
"extensions": {
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
}
Functions 1.x
{
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
Considérations relatives au Language Runtime
Le runtime du langage que vous sélectionnez peut imposer des restrictions d’accès concurrentiel strictes sur vos fonctions. Par exemple, les applications Durable Functions écrites en Python ou PowerShell peuvent uniquement prendre en charge l’exécution d’une seule fonction à la fois sur une seule machine virtuelle. Cela peut entraîner des problèmes de performances significatifs si elles ne sont pas soigneusement prises en compte. Par exemple, si un orchestrateur s’étend sur 10 activités mais que le runtime du langage limite l’accès concurrentiel à une seule fonction, alors 9 des 10 fonctions d’activité sont bloquées en attendant une chance de s’exécuter. En outre, ces 9 activités bloquées ne peuvent pas être équilibrées en mémoire pour les autres threads, car le runtime Durable Functions les aura déjà chargées en mémoire. Cela devient particulièrement problématique si les fonctions d’activité sont de longue durée.
Si le runtime de langage que vous utilisez impose une restriction sur l’accès concurrentiel, vous devez mettre à jour les paramètres de concurrence Durable Functions pour qu’ils correspondent aux paramètres de concurrence du runtime de votre langage. Cela permet de s’assurer que le runtime Durable Functions n’essaie pas d’exécuter simultanément plus de fonctions que ce qui est autorisé par le runtime de langage, ce qui permet d’équilibrer la charge de toutes les activités en attente sur d’autres machines virtuelles. Par exemple, si vous avez une application Python qui restreint la concurrence à 4 fonctions (peut-être qu’elle est seulement configurée avec 4 threads sur un seul processus de worker du langage ou 1 thread sur 4 processus de worker du langage), vous devez configurer à la fois maxConcurrentOrchestratorFunctions et maxConcurrentActivityFunctions sur 4.
Pour plus d’informations et pour obtenir des recommandations sur les performances de Python, consultez Améliorer les performances de débit des applications Python dans Azure Functions. Les techniques mentionnées dans cette documentation de référence pour les développeurs Python peuvent avoir un impact important sur les performances et l’évolutivité de Durable Functions.
Nombre de partitions
Certains fournisseurs de stockage utilisent un mécanisme de partitionnement et autorisent la spécification d’un paramètre partitionCount.
Lors de l’utilisation du partitionnement, les workers ne sont pas directement en concurrence pour des éléments de travail individuels. Au lieu de cela, les éléments de travail sont d’abord regroupés dans des partitions partitionCount. Ces partitions sont ensuite affectées aux workers. Cette approche partitionnée de la distribution de charge peut contribuer à réduire le nombre total d’accès au stockage requis. En outre, cela peut activer la mise en cache d’instance et améliorer la localité, car il crée une affinité : tous les éléments de travail pour la même instance sont traités par le même worker.
Notes
Le partitionnement limite le scale-out, car la plupart des workers partitionCount peuvent traiter des éléments de travail à partir d’une file d’attente partitionnée.
Le tableau suivant montre, pour chaque fournisseur de stockage, quelles files d’attente sont partitionnées, ainsi que la plage autorisée et les valeurs par défaut du paramètre partitionCount.
| Fournisseur Stockage Azure | Fournisseur de stockage Netherite | Fournisseur de stockage MSSQL | |
|---|---|---|---|
| Messages d’instance | Partitionné | Partitionné | Non partitionné |
| Messages d’activité | Non partitionné | Partitionné | Non partitionné |
Par défaut partitionCount |
4 | 12 | n/a |
Maximum partitionCount |
16 | 32 | n/a |
| Documentation | Voir Scale-out de l’orchestrateur | Voir Considérations sur le nombre de partitions | n/a |
Avertissement
Le nombre de partitions ne peut plus être modifié une fois qu’un hub de tâches a été créé. Ainsi, il est conseillé de le définir sur une valeur suffisamment importante pour répondre aux exigences futures de mise à l’échelle pour l’instance du hub de tâches.
Configuration du nombre de partitions
Le paramètre partitionCount peut être spécifié dans le fichier host.json. L’exemple suivant d’extrait de code host.json définit la propriété durableTask/storageProvider/partitionCount (ou durableTask/partitionCountdans Durable Functions 1.x) sur 3.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Considérations relatives à la réduction des latences d’appel
Dans des conditions normales, les demandes d’appel (à des activités, des orchestrateurs, des entités, etc.) nécessitent un traitement plutôt rapide. Toutefois, il n’existe aucune garantie sur la latence maximale des demandes d’appel, car elle dépend de facteurs tels que : le type de comportement de mise à l'échelle de votre plan App Service, de vos paramètres de concurrence et de la taille de backlog de votre application. De ce fait, nous vous recommandons de vous engager dans un test de contrainte pour mesure et optimiser les latences de fin de votre application.
Cibles de performance
Lors de la planification de l’utilisation de Fonctions durables pour une application de production, il est important de tenir compte très rapidement des exigences de performances dans le processus de planification. Certain scénario d'usage de base sont décrits ci-dessous :
- Exécution d’activité séquentielle : ce scénario décrit une fonction d’orchestrateur qui exécute une série de fonctions d’activité, l’une après l’autre. Il ressemble beaucoup à l’exemple de chaînage de fonctions.
- Exécution d’activité parallèle : ce scénario décrit une fonction d’orchestrateur qui exécute de nombreuses fonctions d’activité en parallèle à l’aide du modèle fan-out/fan-in.
- Traitement de la réponse en parallèle : ce scénario constitue la seconde moitié du modèle fan-out/fan-in. Il se concentre sur les performances du scénario fan-in. Contrairement au scénario fan-out, le scénario fan-in est réalisé par une instance de fonction d’orchestrateur unique et peut donc uniquement s’exécuter sur une seule machine virtuelle.
- Traitement des événements externes : ce scénario représente une instance unique de la fonction d’orchestrateur, qui attend les événements externes, un par un.
- Traitement des opérations d’entité : ce scénario teste la rapidité avec laquelle une seuleentité Compteur peut traiter un flux constant d’opérations.
Nous fournissons des numéros de débit pour ces scénarios dans la documentation respective des fournisseurs de stockage. En particulier :
- pour le fournisseur de Stockage Azure, consultez Objectifs de performances.
- pour le fournisseur de stockage Netherite, consultez Scénarios de base.
- pour le fournisseur de stockage MSSQL, consultez Points de référence de débit d’orchestration.
Conseil
Contrairement aux opérations fan-out, les opérations fan-in sont limitées à une seule machine virtuelle. Si votre application utilise le modèle fan-out/fan-in et si vous vous préoccupez des performances de scénario fan-in, pensez à sous-diviser le scénario fan-out de fonction d’activité sur plusieurs sous-orchestrations.