Tutoriel : Découvrir des relations dans le modèle sémantique, à l’aide du lien sémantique
Ce tutoriel montre comment interagir avec Power BI à partir d’un notebook Jupyter et détecter les relations entre les tables en utilisant la bibliothèque SemPy.
Dans ce tutoriel, vous allez apprendre à :
- Découvrir les relations dans un modèle sémantique (jeu de données Power BI) en utilisant la bibliothèque Python (SemPy) du lien sémantique.
- Utilisez des composants de SemPy qui prennent en charge l’intégration à Power BI et vous aident à automatiser l’analyse de la qualité des données. Ces composants sont les suivants :
- FabricDataFrame : structure de type pandas améliorée avec des informations sémantiques supplémentaires.
- Des fonctions permettant de tirer des modèles sémantiques d’un espace de travail Fabric dans votre notebook.
- Fonctions qui automatisent l’évaluation des hypothèses sur les dépendances fonctionnelles et identifient les violations des relations dans vos modèles sémantiques.
Prérequis
Souscrivez à un abonnement Microsoft Fabric . Inscrivez-vous à la version d’évaluation gratuite de Microsoft Fabric.
Connectez-vous à Microsoft Fabric.
Utilisez le sélecteur d’expérience en bas à gauche de votre page d’accueil pour basculer vers Fabric.
Sélectionnez Espaces de travail dans le volet de navigation gauche pour rechercher et sélectionner votre espace de travail. Cet espace de travail devient votre espace de travail actuel.
Téléchargez les modèles sémantiques Customer Profitability Sample.pbix et Customer Profitability Sample (auto).pbix à partir du dépôt GitHub fabric-samples et chargez-les dans votre espace de travail.
Suivre le notebook
Le notebook powerbi_measures_tutorial.ipynb accompagne ce tutoriel.
Pour ouvrir le bloc-notes associé pour ce didacticiel, suivez les instructions de Préparer votre système pour les didacticiels de science des données pour importer le bloc-notes dans votre espace de travail.
Si vous préférez copier et coller le code de cette page, vous pouvez créer un nouveau notebook.
Assurez-vous d’attacher un Lakehouse au notebook avant de commencer à exécuter du code.
Configurer le notebook
Dans cette section, vous configurez un environnement de notebook avec les modules et données nécessaires.
Installez
SemPyà partir de PyPI en utilisant la fonctionnalité d’installation inline%pipdans le notebook :%pip install semantic-linkEffectuez les importations nécessaires des modules SemPy que vous devez utiliser par la suite :
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsImportez pandas pour appliquer une option de configuration qui permet de mettre en forme la sortie :
import pandas as pd pd.set_option('display.max_colwidth', None)
Explorer des modèles sémantiques
Ce tutoriel utilise un exemple de modèle sémantique Customer Profitability Sample.pbix. Pour obtenir une description du modèle sémantique, consultez Customer Profitability Sample pour Power BI.
Utilisez la fonction
list_datasetsde SemPy pour explorer les modèles sémantiques dans votre espace de travail actuel :fabric.list_datasets()
Pour le reste de ce notebook, vous utilisez deux versions du modèle sémantique Customer Profitability Sample :
- Customer Profitability Sample : le modèle sémantique inclus dans les exemples Power BI avec des relations de table prédéfinies
- exemple de rentabilité des clients (auto): les mêmes données, mais les relations sont limitées à celles que Power BI détecterait automatiquement.
Extraire un exemple de modèle sémantique avec son modèle sémantique prédéfini
Chargez les relations prédéfinies et stockées dans le modèle sémantique de l'exemple de rentabilité client , en utilisant la fonction SemPy
list_relationships. Cette fonction répertorie dans le Modèle Objet Tabulaire :dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsVisualisez le DataFrame
relationshipsdans un graphe en utilisant la fonctionplot_relationship_metadatade SemPy :plot_relationship_metadata(relationships)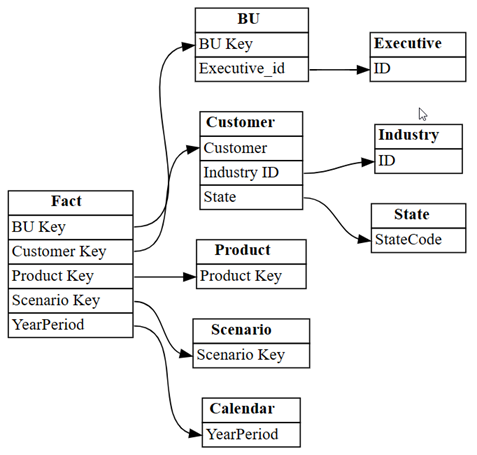

Ce graphe montre la « réalité du terrain » pour les relations entre les tables de ce modèle sémantique, car il reflète la façon dont elles ont été définies dans Power BI par un expert.
Complémenter la découverte des relations
Si vous avez commencé avec les relations détectées automatiquement par Power BI, vous avez un ensemble plus petit.
Visualisez les relations détectées automatiquement par Power BI dans le modèle sémantique :
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)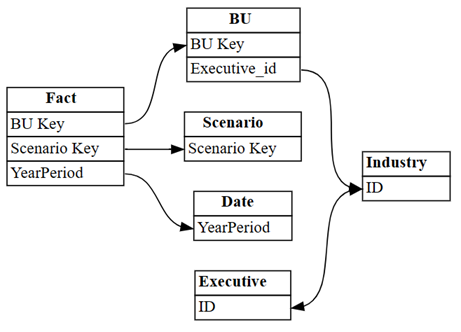
La détection automatique de Power BI a manqué de nombreuses relations. Par ailleurs, deux des relations détectées automatiquement sont sémantiquement incorrectes :
Executive[ID]->Industry[ID]BU[Executive_id]->Industry[ID]
Imprimez les relations dans une table :
autodetectedLes relations incorrectes dans la table
Industrys’affichent dans des lignes avec l’index 3 et 4. Utilisez ces informations pour supprimer ces lignes.Ignorez les relations identifiées de manière incorrecte.
autodetected.drop(index=[3,4], inplace=True) autodetectedVous avez maintenant des relations correctes, mais incomplètes.
Visualisez ces relations incomplètes avec
plot_relationship_metadata:plot_relationship_metadata(autodetected)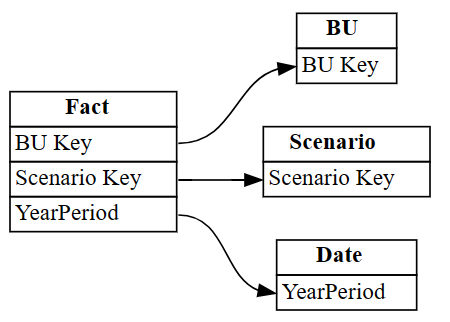
Chargez toutes les tables du modèle sémantique en utilisant les fonctions
list_tablesetread_tablede SemPy :tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Passez en revue le résultat du journal pour obtenir des informations sur le fonctionnement de cette fonction, et trouvez des relations entre les tables à l’aide de
find_relationships.suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Visualisez les relations nouvellement découvertes :
plot_relationship_metadata(suggested_relationships_all)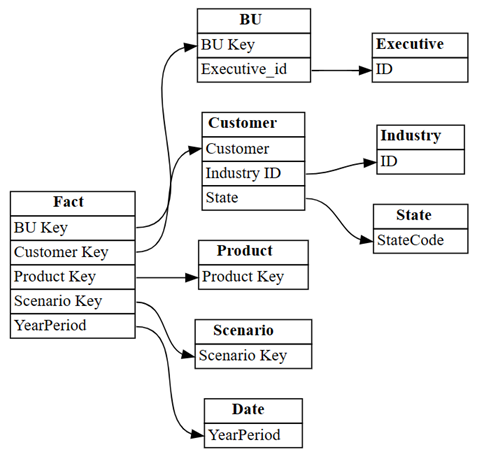
SemPy a pu détecter toutes les relations.
Utilisez le paramètre
excludepour limiter la recherche aux relations supplémentaires qui n’ont pas été identifiées précédemment :additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Valider les relations
Tout d’abord, chargez les données à partir de l’exemple de rentabilité client du modèle sémantique :
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Vérifiez si les valeurs de clé primaire et étrangère se chevauchent, en utilisant la fonction
list_relationship_violations. Fournissez la sortie de la fonctionlist_relationshipscomme entrée pourlist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))Les violations de relation fournissent des insights intéressants. Par exemple, une valeur sur sept dans
Fact[Product Key]n’est pas présente dansProduct[Product Key], et cette clé manquante est50.
L’analyse exploratoire des données est un processus passionnant, tout comme le nettoyage des données. Il y a toujours quelque chose que les données cachent, selon la façon dont vous les examinez, de ce que vous voulez demander, etc. Le lien sémantique vous offre de nouveaux outils que vous pouvez utiliser pour tirer le meilleur parti de vos données.
Contenu connexe
Découvrez d’autres tutoriels pour le lien sémantique / SemPy :
- Tutoriel : Nettoyer les données avec des dépendances fonctionnelles
- Tutoriel : Analyser les dépendances fonctionnelles dans un modèle sémantique d’échantillon
- Tutoriel : Extraire et calculer des mesures Power BI à partir d’un notebook Jupyter
- Tutoriel : Découvrir les relations dans l’ensemble de données Synthea à l’aide du lien sémantique
- Tutoriel : Valider des données à l’aide de SemPy et Great Expectations (GX)