Opetusohjelma, osa 3: Koneoppimismallin harjoittaminen ja rekisteröiminen
Tässä opetusohjelmassa opit kouluttamaan useita koneoppimismalleja ja valitsemaan parhaan, jotta voit ennustaa, ketkä pankkiasiakkaat todennäköisesti lähtevät.
Tässä opetusohjelmassa:
- Harjoita Random Forest- ja LightGBM-malleja.
- Microsoft Fabricin alkuperäisen MLflow-kehyksen integroinnin avulla voit kirjata lokiin koulutetut koneoppimismallit, käytetyt hyperaparameterit ja arviointimittarit.
- Rekisteröi harjoitettu koneoppimismalli.
- Arvioi koulutettujen koneoppimismallien suorituksia vahvistustietojoukossa.
MLflow on avoimen lähdekoodin ympäristö, jonka avulla voit hallita koneoppimisen elinkaarta esimerkiksi seurannan, mallien ja mallirekisterin avulla. MLflow on integroitu suoraan Fabric Data Science -kokemukseen.
Edellytykset
Hanki Microsoft Fabric -tilaus. Voit myös rekisteröityä ilmaiseen Microsoft Fabric -kokeiluversioon.
Vaihda Fabriciin aloitussivun vasemmassa alakulmassa olevan käyttökokemuksen vaihtajan avulla.

Tämä on opetusohjelmasarjan osa 3/5. Suorita tämä opetusohjelma suorittamalla ensin:
- Osa 1: Tietojen käyttö Microsoft Fabric -lakehousessa Apache Sparkin avulla.
- Osa 2: Tutustu ja visualisoi tietoja Microsoft Fabric -muistikirjojen avulla, niin saat lisätietoja tiedoista.
Seuraa mukana muistikirjassa
3-train-evaluate.ipynb on muistikirja, joka on tämän opetusohjelman mukana.
Jos haluat avata tämän opetusohjelman liitteenä olevan muistikirjan, noudata ohjeita kohdassa Valmistele järjestelmäsi datatiedeopetusohjelmia varten muistikirjan tuomiseksi työtilaasi.
Jos haluat kopioida ja liittää koodin tältä sivulta, voit luoda uuden muistikirjan.
Muista liittää lakehouse muistikirjaan ennen kuin aloitat koodin suorittamisen.
Tärkeä
Liitä sama lakehouse, jota käytit osassa 1 ja osassa 2.
Mukautettujen kirjastojen asentaminen
Tähän muistikirjaan asennat epätasapainoisen oppimisen (tuotu nimellä imblearn) käyttämällä %pip install. Epätasapainoinen oppiminen on synteettisen vähemmistön ylimyyntitekniikan (SMOTE) kirjasto, jota käytetään käsitellessä epätasapainoisia tietojoukkoja. PySpark-ydin käynnistetään uudelleen :n jälkeen %pip install, joten sinun on asennettava kirjasto ennen kuin suoritat muita soluja.
Saat smote-käyttöoikeuden käyttämällä -kirjastoa imblearn . Asenna se nyt käyttämällä rivinsisäisiä asennusominaisuuksia (esimerkiksi , %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
Tärkeä
Suorita tämä asennus aina, kun käynnistät muistikirjan uudelleen.
Kun asennat kirjaston muistikirjaan, se on käytettävissä vain muistikirjaistunnon ajan, ei työtilassa. Jos käynnistät muistikirjan uudelleen, sinun on asennettava kirjasto uudelleen.
Jos sinulla on kirjasto, jota käytät usein ja haluat tuoda sen kaikkien työtilasi muistikirjojen saataville, voit käyttää Tähän tarkoitukseen Fabric-ympäristöä . Voit luoda ympäristön, asentaa siihen kirjaston , jonka jälkeen työtilan järjestelmänvalvoja voi liittää ympäristön työtilaan oletusympäristönä. Lisätietoja ympäristön määrittämisestä työtilan oletusasetukseksi on kohdassa Järjestelmänvalvoja määrittää työtilan oletuskirjastot.
Jos haluat lisätietoja aiemmin luotujen työtilakirjastojen ja Spark-ominaisuuksien siirtämisestä ympäristöön, lue ohjeartikkeli Työtilakirjastojen ja Spark-ominaisuuksien siirtäminen oletusympäristöön.
Lataa tiedot
Ennen koneoppimismallin harjoittamista sinun on ladattava delta-taulukko Lakehousesta, jotta voit lukea edellisessä muistikirjassa luomasi puhdistetut tiedot.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Luo kokeiluja mallin seuraamista ja kirjaamista varten MLflow'n avulla
Tässä osiossa näytetään, miten luodaan kokeilu, määritetään koneoppimismallin ja harjoitusparametrit sekä pisteytysmittarit, harjoitetaan koneoppimismalleja, kirjataan ne ja tallennetaan harjoitetut mallit myöhempää käyttöä varten.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment" # MLflow experiment name
MLflow-automaattianalyysipalveluiden ominaisuuksien laajentaminen, automaattinen lokerointi toimii siten, että se tallentaa automaattisesti syöteparametrien arvot ja koneoppimismallin tulostemittarit harjoittamisen aikana. Nämä tiedot kirjataan sitten työtilaan, jossa niitä voidaan käyttää ja visualisoida käyttämällä MLflow-ohjelmointirajapintoja tai vastaavaa työtilan kokeilua.
Kaikki niiden nimillä tehdyt kokeilut kirjataan, ja voit seurata niiden parametreja ja suorituskykymittareita. Saat lisätietoja automaattianalyysipalveluista ohjeartikkelista Automaattinen lokiloggaus Microsoft Fabricissa.
Määritä kokeilu- ja automaattianalyysimääritykset
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Tuo scikit-learn ja LightGBM
Kun tiedot ovat paikoillaan, voit nyt määrittää koneoppimismalleja. Käytät tässä muistikirjassa Random Forest- ja LightGBM-malleja. Mallien käyttäminen scikit-learn ja lightgbm käyttöönotto muutamalla koodirivillä.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Koulutus-, vahvistus- ja testitietojoukkojen valmisteleminen
Käytä funktiota train_test_split kohteesta scikit-learn tietojen jakamiseen koulutus-, vahvistus- ja testijoukkoihin.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Testitietojen tallentaminen delta-taulukkoon
Tallenna testitiedot delta-taulukkoon käytettäväksi seuraavassa muistikirjassa.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Sovella SMOTE:a koulutustietoihin uusien näytteiden syntetisoimiseksi vähemmistöluokalle
Osassa 2 tietojen tarkastelu osoitti, että 10 000 arvopisteesta, jotka vastaavat 10 000 asiakasta, vain 2 037 asiakasta (noin 20 %) on lähtenyt pankista. Tämä osoittaa, että tietojoukko on epätasapainoinen. Epätasapainoisen luokituksen ongelma on se, että vähemmistöluokasta on liian vähän esimerkkejä, jotta malli oppisi tehokkaasti päätösrajan. SMOTE on yleisin tapa syntetisoida uusia näytteitä vähemmistöluokalle. Saat lisätietoja SMOTE: sta täältä ja täältä.
Vihje
Ota huomioon, että SMOTE:a tulee soveltaa vain koulutustietojoukkoon. Testitietojoukko on jätettävä alkuperäiseen epätasapainoisen jakautumisensa, jotta saadaan kelvollinen arvio siitä, miten koneoppimismalli suoriutuu alkuperäisistä tiedoista, mikä edustaa tuotantotilannetta.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Vihje
Voit turvallisesti ohittaa MLflow-varoitussanoman, joka tulee näkyviin, kun suoritat tämän solun.
Jos näet ModuleNotFoundError-sanoman , et päässyt suorittaa muistikirjassa ensimmäistä solua, joka asentaa kirjaston imblearn . Tämä kirjasto on asennettava aina, kun käynnistät muistikirjan uudelleen. Suorita kaikki solut uudelleen tämän muistikirjan ensimmäisestä solusta alkaen.
Mallin harjoittaminen
- Harjoita mallia käyttämällä Random Forestia maksimisyvyyteen 4 ja 4 ominaisuudella
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Harjoita mallia käyttämällä Random Forestia, jonka suurin syvyys on 8 ja 6 ominaisuutta
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Mallin harjoittaminen LightGBM:n avulla
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Kokeilee artefaktia mallin suorituskyvyn seurantaa varten
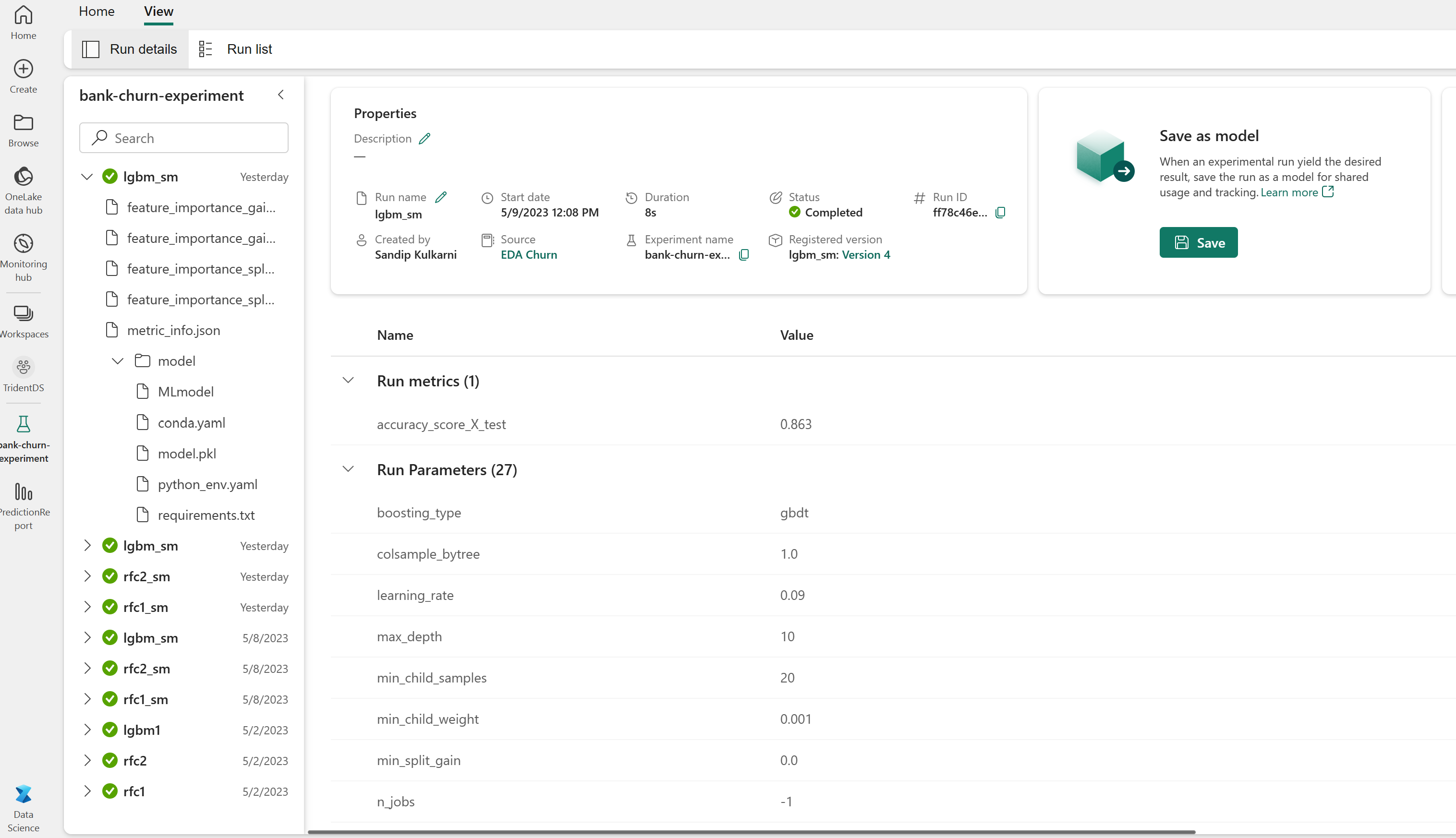
Kokeilusuoritukset tallennetaan automaattisesti kokeiluarteefaktiin, joka löytyy työtilasta. Ne nimetään kokeilun määrittämisessä käytetyn nimen perusteella. Kaikki koulutetut koneoppimismallit, niiden suoritukset, suorituskykymittarit ja malliparametrit kirjataan.
Voit tarkastella kokeitasi:
Valitse vasemmassa paneelissa työtilasi.
Suodata oikeassa yläkulmassa näyttämään vain kokeiluja, jotta löydät helpommin etsimäsi kokeilun.
Etsi ja valitse kokeilun nimi, tässä tapauksessa bank-churn-experiment. Jos et näe kokeiluja työtilassasi, päivitä selaimesi.


Arvioi koulutettujen mallien suorituksia vahvistustietojoukossa
Kun olet suorittanut koneoppimismallin harjoittamisen, voit arvioida koulutettujen mallien suorituskykyä kahdella tavalla.
Avaa tallennettu kokeilu työtilasta, lataa koneoppimismallit ja arvioi sitten ladattujen mallien suorituskyky vahvistustietojoukossa.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMArvioi suoraan koulutettujen koneoppimismallien suorituskykyä vahvistustietojoukossa.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Suosistasi riippuen kumpi tahansa tapa on sopiva, ja sen pitäisi tarjota identtisiä suorituksia. Tässä muistikirjassa valitset ensimmäisen lähestymistavan, jotta voit paremmin esitellä Microsoft Fabricin MLflow-automaattianalyysiominaisuuksia.
Näytä true/false-positiiviset/negatiiviset käyttämällä sekaannusmatriisia
Seuraavaksi luot komentosarjan hämmennysmatriisin piirtämiseksi, jotta voit arvioida luokituksen tarkkuuden vahvistustietojoukon avulla. Sekaannusmatriisi voidaan piirtää myös SynapseML-työkaluilla, mikä näkyy tässä olevassa Petosten havaitsemismalli -esimerkissä.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Virhematriisi Random Forest Classifierille, jonka enimmäissyvyys on 4 ja 4 ominaisuutta
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
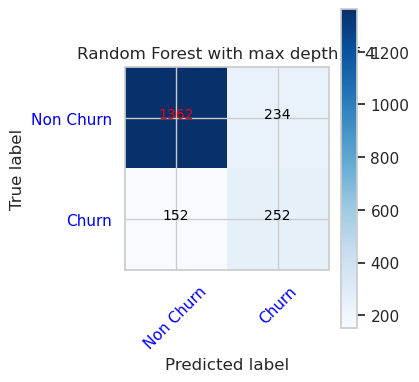
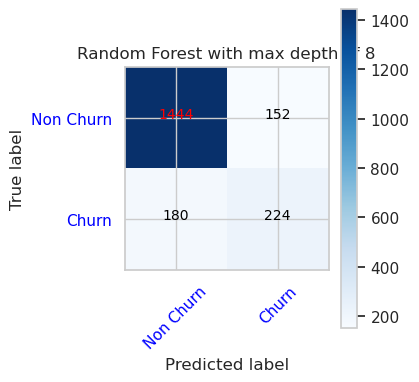
- Virhematriisi Random Forest Classifierille, jonka enimmäissyvyys on 8 ja 6 ominaisuutta
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
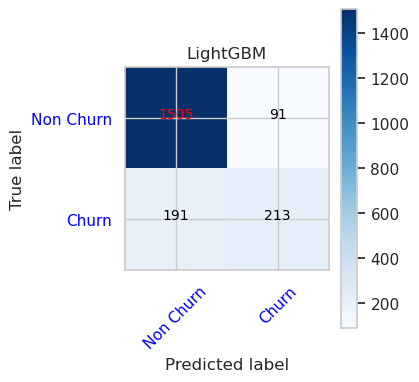
- LightGBM:n sekaannusmatriisi
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()