Opetusohjelma, osa 2: Tietojen tutkiminen ja visualisointi Microsoft Fabric -muistikirjojen avulla
Tässä opetusohjelmassa opit suorittamaan valmistelevan tietoanalyysin (EDA), jotta voit tutkia ja tutkia tietoja samalla, kun teet yhteenvedon niiden tärkeimmistä ominaisuuksista tietojen visualisointitekniikoiden avulla.
seabornKäytät Python-tietojen visualisointikirjastoa, joka tarjoaa korkean tason käyttöliittymän visualisointien luomiseen tietokehyksissä ja matriiseissa. Lisätietoja kohteesta seabornseaborn : Tilastollinen tietojen visualisointi.
Käytät myös muistikirjapohjaista Data Wrangler -työkalua, joka tarjoaa mukaansatempaavan kokemuksen tutkivien tietojen analysoimiseen ja puhdistamiseen.
Tämän opetusohjelman tärkeimmät vaiheet ovat:
- Lue lakehousessa olevasta delta-taulukosta tallennetut tiedot.
- Muunna Spark DataFrame Pandas DataFrameksi, jota python-visualisointikirjastot tukevat.
- Käytä Data Wrangler -funktiota tietojen ensimmäisen puhdistamisen ja muunnoksen suorittamiseen.
- Suorita valmistelevia tietoanalyyseja :n avulla
seaborn.
Edellytykset
Hanki Microsoft Fabric -tilaus. Voit myös rekisteröityä ilmaiseen Microsoft Fabric -kokeiluversioon.
Siirry Synapse Data Science -käyttökokemukseen aloitussivun vasemmassa reunassa olevan käyttökokemuksen vaihtajan avulla.

Tämä on opetusohjelmasarjan osa 2/5. Suorita tämä opetusohjelma suorittamalla ensin:
Seuraa mukana muistikirjassa
2-explore-cleanse-data.ipynb on muistikirja, joka seuraa tätä opetusohjelmaa.
Jos haluat avata tämän opetusohjelman liitteenä olevan muistikirjan, tuo muistikirja työtilaasi noudattamalla ohjeita kohdassa Järjestelmän valmisteleminen datatieteen opetusohjelmia varten.
Jos haluat kopioida ja liittää koodin tältä sivulta, voit luoda uuden muistikirjan.
Muista liittää lakehouse muistikirjaan ennen kuin aloitat koodin suorittamisen.
Tärkeä
Liitä sama lakehouse, jota käytit osassa 1.
Raakadata Lakehousesta
Lue raakadataa Lakehousen Tiedostot-osiosta . Latasit nämä tiedot edelliseen muistikirjaan. Varmista, että olet kiinnittänyt saman lakehousen, jota käytit osassa 1 tähän muistikirjaan, ennen kuin suoritat tämän koodin.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Pandas DataFrame -kehyksen luominen tietojoukosta
Muunna spark DataFrame pandas DataFrame -kehykseksi käsittelyn ja visualisoinnin helpottamiseksi.
df = df.toPandas()
Raakatietojen näyttäminen
Tutustu raakatietoihin :n avulla display: tee joitakin perustilastoja ja näytä kaavionäkymiä. Huomaa, että sinun on ensin tuotava tarvittavat kirjastot, kuten Numpy, Pnadas, Seabornja Matplotlib tietojen analysointia ja visualisointia varten.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Tietojen ensimmäisen puhdistuksen suorittaminen Data Wrangler -funktion avulla
Jos haluat tutkia ja muuntaa mitä tahansa muistikirjasi pandoja Tietokehykset, käynnistä Data Wrangler suoraan muistikirjasta.
Muistiinpano
Data Wrangleria ei voi avata, kun muistikirjan ydin on varattu. Solun suorituksen on oltava valmis ennen Data Wranglerin käynnistämistä.
- Valitse muistikirjan valintanauhan Tiedot-välilehdessä Käynnistä tiedot Wrangler. Näet luettelon aktivoiduista pandas DataFrame -kehyksistä, joita voi muokata.
- Valitse DataFrame, jonka haluat avata Data Wranglerissa. Koska tämä muistikirja sisältää vain yhden DataFrame-kehyksen,
dfvalitsedf.
Data Wrangler käynnistyy ja luo tiedoistasi kuvaavan yleiskatsauksen. Keskellä olevassa taulukossa näkyvät kaikki tietosarakkeet. Taulukon vieressä olevassa Yhteenveto-paneelissa näkyy tietoja DataFramesta. Kun valitset sarakkeen taulukossa, yhteenvetoon päivitetään valitun sarakkeen tiedot. Joissakin tapauksissa näytettävät ja yhteenvedetyt tiedot ovat dataframe-kehyksen katkenneet näkymät. Kun näin käy, näet yhteenvetoruudussa varoituskuvan. Pidä hiiren osoitinta tämän varoituksen päällä, kun haluat tarkastella tilannetta kuvattavaa tekstiä.

Kutakin toimintoa voidaan käyttää vain napsautuksella, päivittää reaaliaikaisesti näytettäviä tietoja ja luoda koodi, joka voidaan tallentaa takaisin muistikirjaan uudelleenkäytettävänä funktiona.
Tämän osion muissa osissa käydään läpi tietojen puhdistaminen Data Wranglerilla.
Rivien kaksoiskappaleiden pudottaminen
Vasemmassa paneelissa on luettelo toiminnoista (kuten Etsi ja korvaa, Muotoile, Kaavat, Numeerinen), jotka voit suorittaa tietojoukolle.
Laajenna Etsi ja korvaa ja valitse Poista rivien kaksoiskappaleet.
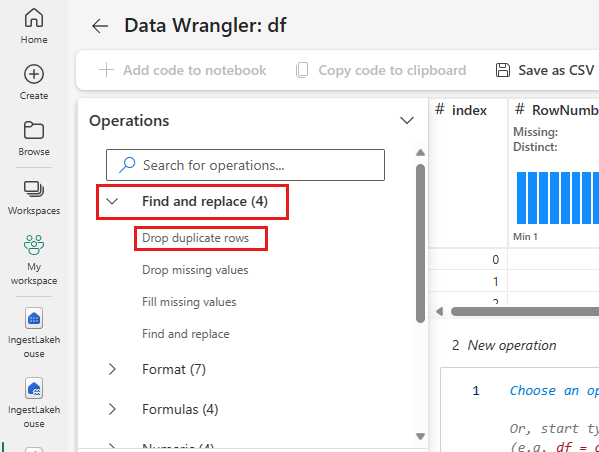
Näyttöön tulee paneeli, jossa voit valita vertailtavien sarakkeiden luettelon ja määrittää rivin kaksoiskappaleen. Valitse RowNumber ja CustomerId.
Keskimmäisessä paneelissa on esikatselu tämän toiminnon tuloksista. Esikatselu-kohdassa on koodin, joka suorittaa toiminnon. Tässä esiintymässä tiedot näyttävät muuttumattomina. Mutta koska tarkastelet katkennttua näkymää, toimintoa kannattaa silti käyttää.
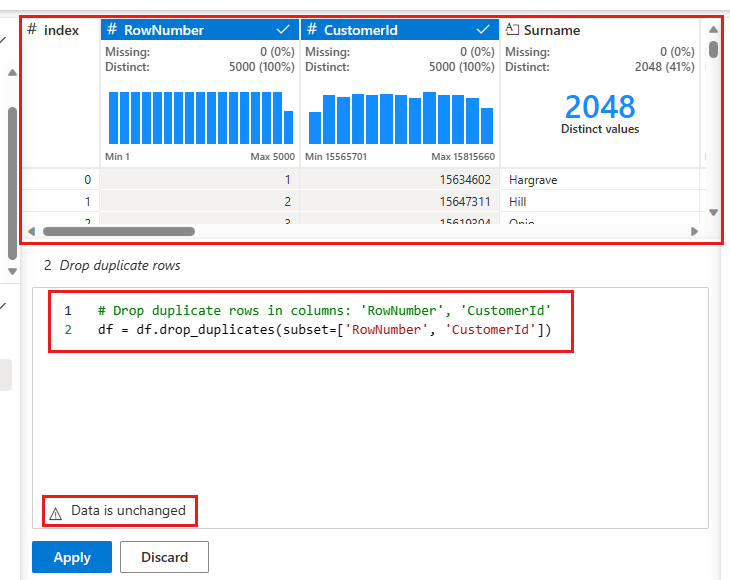
Valitse Käytä (joko sivulta tai alareunasta) siirtyäksesi seuraavaan vaiheeseen.

Jätä rivit, joista puuttuu tietoja
Data Wrangler -funktion avulla voit pudottaa rivejä, joista puuttuu tietoja kaikista sarakkeista.
Valitse Poista puuttuvat arvot etsi ja korvaa -kohdasta.
Valitse Target-sarakkeista Valitse kaikki.
Siirry seuraavaan vaiheeseen valitsemalla Käytä .

Sarakkeiden pudottaminen
Data Wrangler -painikkeilla voit pudottaa sarakkeita, joita et tarvitse.
Laajenna rakenne ja valitse Pudota sarakkeet.
Valitse RowNumber, CustomerId, Surname. Nämä sarakkeet näkyvät punaisina esikatselussa, jotta ne näkyvät koodin muuttamia (tässä tapauksessa ne on jätetty pois).
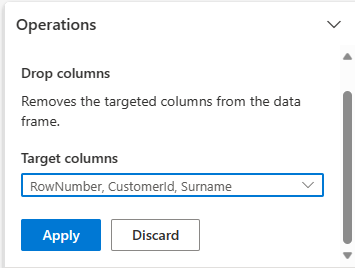
Siirry seuraavaan vaiheeseen valitsemalla Käytä .

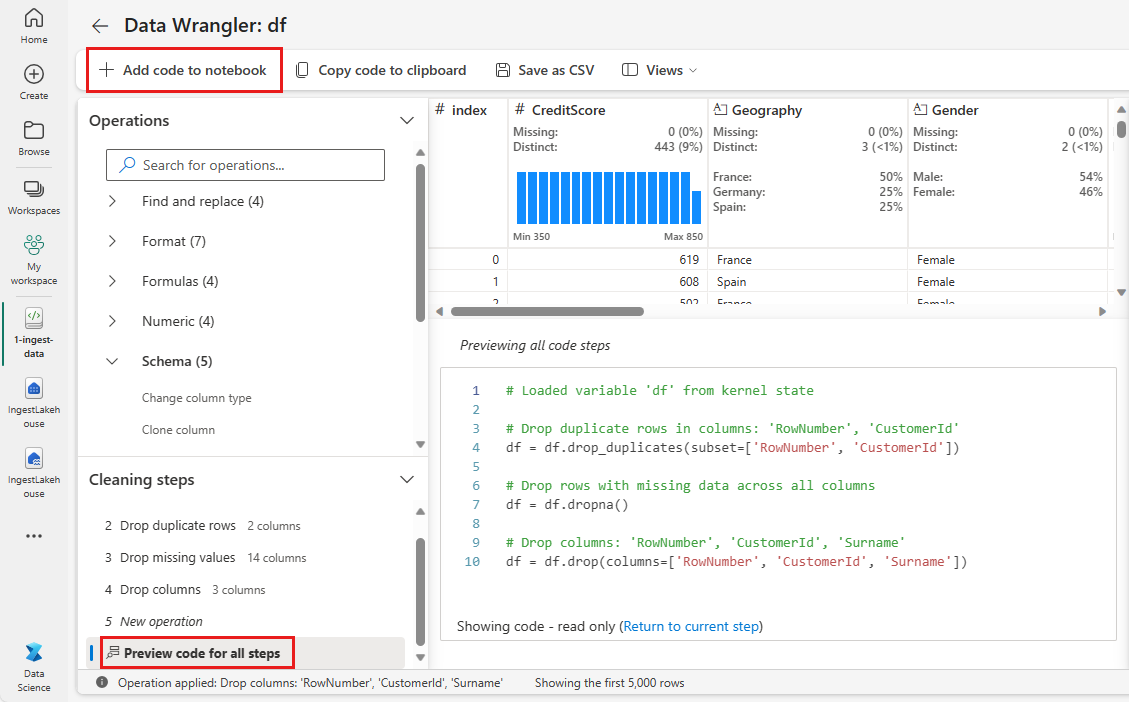
Koodin lisääminen muistikirjaan
Aina kun valitset Käytä, uusi vaihe luodaan vasemmassa alakulmassa olevassa Puhdista vaiheet -paneelissa. Valitse paneelin alareunassa Esikatsele koodia kaikille vaiheille , jotta näet kaikkien erillisten vaiheiden yhdistelmän.
Sulje Data Wrangler valitsemalla vasemmasta yläkulmasta Lisää koodi muistikirjaan ja lisää koodi automaattisesti. Lisää koodi muistikirjaan rivittää koodin funktioon ja kutsuu sitten funktiota.
Vihje
Data Wrangler -funktion luomaa koodia ei käytetä, ennen kuin suoritat uuden solun manuaalisesti.
Jos et käyttänyt Data Wrangler -toimintoa, voit käyttää seuraavaa koodisolua.
Tämä koodi on samanlainen kuin Data Wranglerin tuottama koodi, mutta lisää argumentin inplace=True kuhunkin luotuun vaiheisiin. inplace=TrueMäärittämällä pandas korvaa alkuperäisen DataFramen sen sijaan, että tuotokseksi tuotetaan uusi DataFrame.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Tietojen tutkiminen
Näyttää joitakin puhdistetun tiedon yhteenvetoja ja visualisointeja.
Luokittaisten, numeeristen ja kohdemääritteiden määrittäminen
Tämän koodin avulla voit määrittää luokittaisia, numeerisia ja kohdemääritteitä.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
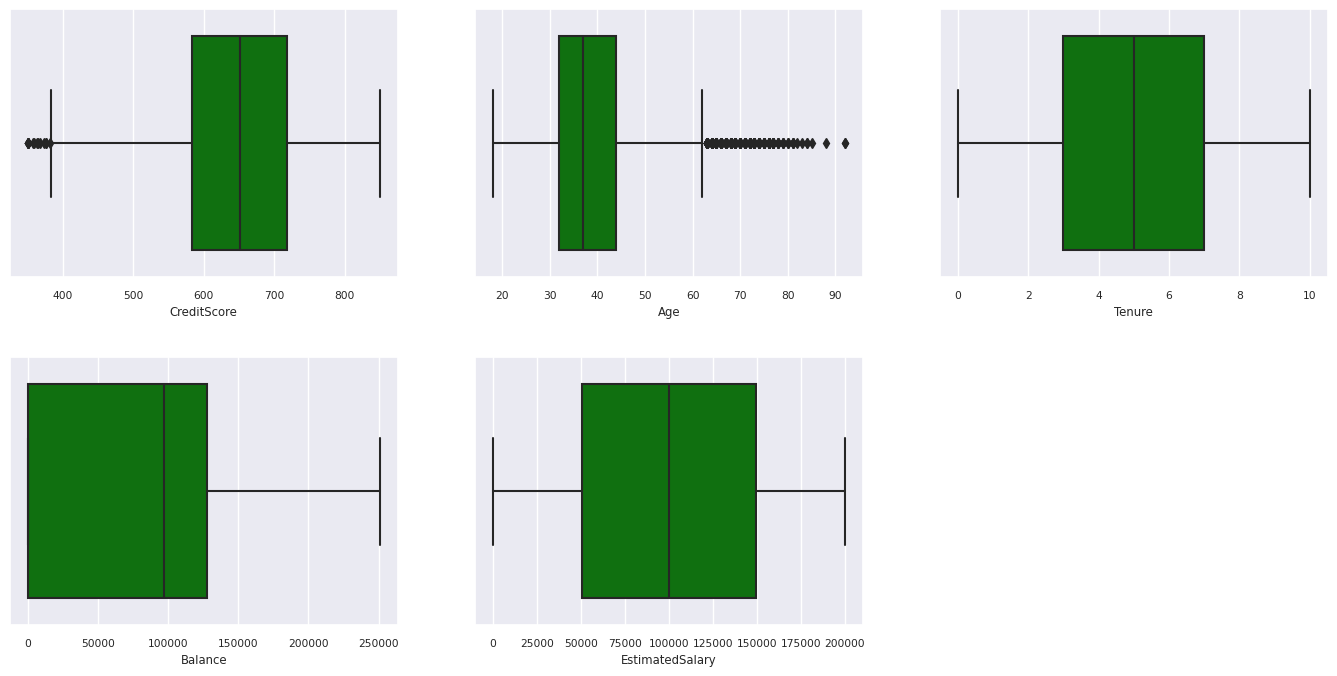
Viiden numeron yhteenveto
Näytä numeeristen määritteiden viiden numeron yhteenveto (vähimmäispistemäärä, ensimmäinen louhos, mediaani, kolmas kvartaali, enimmäispistemäärä) ruutukaavioiden avulla.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
Poistuneiden ja ei-yhdenkään asiakkaan jakelu
Näytä poistuneiden ja ei-yhteensopimattomiin asiakkaisiin verrattuna luokittaisten määritteiden jakauma.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Numeeristen määritteiden jakauma
Näytä numeeristen määritteiden tiheysjakauma histogrammin avulla.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Ominaisuuksien suunnittelun suorittaminen
Luo uusia määritteitä nykyisten määritteiden perusteella suorittamalla ominaisuustekniikka:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Käytä Data Wrangler -funktiota yhden kuuman koodauksen suorittamiseen
Data Wrangler -funktiota voidaan käyttää myös yhden kuuman koodauksen suorittamiseen. Avaa tätä varten Data Wrangler uudelleen. Valitse tällä kertaa df_clean tiedot.
- Laajenna Kaavat ja valitse Yksi kuuma koodi.
- Näyttöön tulee paneeli, jossa on luettelo sarakkeista, joille haluat suorittaa yhden kuuman koodauksen. Valitse Maantiede ja Sukupuoli.
Voit kopioida luodun koodin, sulkea Data Wranglerin palataksesi muistikirjaan ja liittää sitten uuteen soluun. Vaihtoehtoisesti voit valita Lisää koodi muistikirjaan vasemmasta yläkulmasta, jos haluat sulkea Data Wranglerin, ja lisätä koodin automaattisesti.
Jos et käyttänyt Data Wrangler -toimintoa, voit käyttää seuraavaa koodisolua:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Yhteenveto valmistelevan tietoanalyysin havainnoista
- Suurin osa asiakkaista on Ranskasta, vertailusta Espanjaan ja Saksaan, kun taas Espanjan vaihtuvuusaste on alhaisin, kun se vertailee Ranskaa ja Saksaa.
- Useimmilla asiakkailla on luottokortit.
- On asiakkaita, joiden ikä ja luottopisteet ovat yli 60 ja alle 400, mutta heitä ei voida pitää poikkeavina arvoina.
- Vain harvoilla asiakkailla on enemmän kuin kaksi pankin tuotetta.
- Asiakkaiden, jotka eivät ole aktiivisia, vaihtuvuusaste on suurempi.
- Sukupuoli- ja virkavuodet eivät näytä vaikuttavan asiakkaan päätökseen sulkea pankkitili.
Delta-taulukon luominen puhdistettuja tietoja varten
Käytät näitä tietoja tämän sarjan seuraavassa muistikirjassa.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Seuraava vaihe
Opeta ja rekisteröi koneoppimismalleja näiden tietojen avulla:
Osa 3: Koneoppimismallien harjoittaminen ja rekisteröiminen.