Relevancia en la búsqueda de palabras clave (puntuación BM25)
En este artículo se explican los algoritmos de puntuación de relevancia BM25 que se usan para calcular las puntuaciones de búsqueda de texto completo. La relevancia BM25 es exclusiva de la búsqueda de texto completo. Las consultas de filtro, de autocompletar y sugeridas, de búsqueda con caracteres comodín y de búsqueda aproximada no se puntúan ni clasifican por relevancia.
Algoritmos de puntuación usados en la búsqueda de texto completo
Azure AI Search proporciona los siguientes algoritmos de puntuación para la búsqueda de texto completo:
| Algoritmo | Uso | Range |
|---|---|---|
BM25Similarity |
Algoritmo fijo en todos los servicios de búsqueda creados después de julio de 2020. Puede configurar este algoritmo, pero no puede cambiar a uno anterior (clásico). | Sin enlazar. |
ClassicSimilarity |
Valor predeterminado en los servicios de búsqueda anteriores a julio de 2020. En los servicios anteriores, puede participar en BM25 y elegir un algoritmo BM25 para cada índice. | 0 < 1.00 |
La función BM25 y la función clásica son funciones de recuperación similares a TF-IDF que usan la frecuencia de los términos (TF) y la frecuencia inversa del documento (IDF) como variables para realizar el cálculo de las puntuaciones de relevancia correspondientes a cada par documento-consulta, que luego se usa para obtener los resultados de clasificación. Aunque conceptualmente es similar al clásico, BM25 se basa en la recuperación de información probabilística, que genera coincidencias más intuitivas según las mediciones de la investigación del usuario.
BM25 ofrece opciones de personalización avanzadas, como permitir que el usuario decida cómo se escala la puntuación de relevancia en función de la frecuencia de los términos coincidentes.
Funcionamiento de la clasificación de BM25
La puntuación de relevancia hace referencia al cálculo de una puntuación de búsqueda (@search.score) que actúa como indicador de la relevancia de un elemento en el contexto de la consulta actual. El intervalo es ilimitado. Cuanto mayor sea la puntuación, mayor relevancia tendrá el elemento.
La puntuación de búsqueda se calcula en función de las propiedades estadísticas de la entrada de la cadena y la propia consulta. Azure AI Search busca documentos que coinciden con los términos de búsqueda (algunos o todos, dependiendo de searchMode), lo cual favorece a los documentos que contienen muchas instancias del término de búsqueda. La puntuación de búsqueda aumenta todavía más si el término es poco frecuente en el índice de datos, pero común dentro del documento. La base de este enfoque de relevancia informática se denomina TF-IDF o frecuencia de documento inverso de la frecuencia del término.
Las puntuaciones de búsqueda pueden repetirse en un conjunto de resultados. Cuando varios resultados tienen la misma puntuación de búsqueda, el orden de estos elementos puntuados no está definido y no es estable. Vuelva a ejecutar la consulta y podrá ver que los elementos cambian de posición, especialmente si usa el servicio gratuito o un servicio facturable con varias réplicas. Si dos elementos disponen de la misma puntuación, no hay ninguna garantía de cuál aparecerá en primer lugar.
Para romper el vínculo entre las puntuaciones repetidas, puede agregar una cláusula $orderby para ordenar primero por puntuación y, después, por otro campo que se pueda ordenar (por ejemplo, $orderby=search.score() desc,Rating desc).
Solo se usan campos marcados como searchable en el índice o searchFields en la consulta para la puntuación. Solo los campos marcados como retrievable, o los especificados en select en la consulta, se devuelven en los resultados de búsqueda, junto con su puntuación de búsqueda.
Nota:
@search.score = 1 indica un conjunto de resultados sin puntuar o sin clasificar. La puntuación es uniforme en todos los resultados. Los resultados sin puntuar se producen cuando el formulario de la consulta es una búsqueda aproximada, consultas con caracteres comodín o expresiones regulares, o una búsqueda vacía (search=*, a veces emparejada con filtros, donde el filtro es el medio principal para devolver una coincidencia).
El siguiente segmento de vídeo avanza rápidamente hasta una explicación de los algoritmos de clasificación de disponibilidad general que se usan en Azure AI Search. Puede ver el vídeo completo para obtener más información.
Puntuaciones en los resultados de un texto
Cada vez que se clasifican los resultados, la propiedad @search.score contiene el valor usado para ordenar los resultados.
En la tabla siguiente se identifican la propiedad de puntuación, el algoritmo y el intervalo.
| Método de búsqueda | Parámetro | Algoritmo de puntuación | Range |
|---|---|---|---|
| búsqueda de texto completo | @search.score |
Algoritmo BM25, mediante los parámetros especificados en el índice. | Sin enlazar. |
Variación de puntuación
Las puntuaciones de búsqueda transmiten el sentido general de pertinencia, lo que refleja la exactitud de la coincidencia en relación con otros documentos del mismo conjunto de resultados. Sin embargo, las puntuaciones no siempre son coherentes de una consulta a la siguiente, por lo que, al trabajar con consultas, es posible que observe pequeñas discrepancias en cómo se ordenan los documentos de búsqueda. Hay varias explicaciones de por qué puede ocurrir esto.
| Causa | Descripción |
|---|---|
| Puntuaciones idénticas | Si varios documentos tienen la misma puntuación, cualquiera de ellos podría aparecer en primer lugar. |
| Volatilidad de datos | El contenido del índice varía a medida que se agregan, modifican o eliminan documentos. Las frecuencias de los términos cambiarán a medida que se procesen las actualizaciones del índice a lo largo del tiempo, lo que afecta a las puntuaciones de búsqueda de los documentos coincidentes |
| Varias réplicas | En el caso de los servicios que usan varias réplicas, las consultas se emiten para cada réplica en paralelo. Las estadísticas del índice usadas para calcular una puntuación de búsqueda se calculan por réplica, donde los resultados se combinan y ordenan en la respuesta de la consulta. Las réplicas son principalmente reflejos unas de otras, pero las estadísticas pueden diferir debido a pequeñas diferencias en el estado. Por ejemplo, una réplica podría tener documentos eliminados que contribuyan a sus estadísticas, que se combinaron a partir de otras réplicas. Normalmente, las diferencias en las estadísticas por réplica son más evidentes en los índices más pequeños. En la sección siguiente se proporciona más información sobre esta condición. |
Efectos de particionamiento en los resultados de la consulta
Una partición es un fragmento de un índice. Azure AI Search divide cada índice en particiones de base de datos para que el proceso de agregar particiones sea más rápido (al mover las particiones de base de datos a nuevas unidades de búsqueda). En un servicio de búsqueda, la gestión de fragmentos es un detalle de implementación y no configurable, pero saber que un índice está fragmentado ayuda a comprender las anomalías ocasionales en los comportamientos de clasificación y autocompletado:
Anomalías de clasificación: las puntuaciones de búsqueda se calculan primero en el nivel de partición de base de datos y luego se suman en un único conjunto de resultados. En función de las características del contenido de la partición de base de datos, las coincidencias de una partición de base de datos pueden tener una clasificación mayor que las de otra. Si observa clasificaciones intuitivas del contador en los resultados de búsqueda, lo más probable es que se deba a los efectos del particionamiento, especialmente si los índices son pequeños. Puede evitar estas anomalías de clasificación si opta por calcular las puntuaciones de forma global en todo el índice, aunque esto conlleva una penalización de rendimiento.
Anomalías de autocompletar: las consultas de tipo Autocompletar, donde las coincidencias se realizan según los primeros caracteres de un término especificado parcialmente, aceptan un parámetro aproximado que perdona pequeñas desviaciones de ortografía. En Autocompletar, la coincidencia aproximada se restringe a los términos de la partición de base de datos actual. Por ejemplo, si una partición de base de datos contiene "Microsoft" y se escribe un término parcial "micro", el motor de búsqueda combinará con "Microsoft" en esa partición de base de datos, pero no en otras particiones de base de datos que contengan las partes restantes del índice.
En el siguiente diagrama se muestra la relación entre réplicas, particiones, particiones de base de datos y unidades de búsqueda. Muestra un ejemplo de cómo se distribuye un solo índice entre cuatro unidades de búsqueda de un servicio con dos réplicas y dos particiones. Cada una de las cuatro unidades de búsqueda almacena solo la mitad de las particiones de base de datos del índice. Las unidades de búsqueda de la columna izquierda almacenan la primera mitad de las particiones de base de datos, que comprende la primera partición, mientras que las de la columna derecha almacenan la segunda mitad de las particiones de base de datos, que comprende la segunda partición. Dado que hay dos réplicas, hay dos copias de cada partición de base de datos del índice. Las unidades de búsqueda de la fila superior almacenan una copia, que comprende la primera réplica, mientras que las de la fila inferior almacenan otra copia, que comprende la segunda réplica.
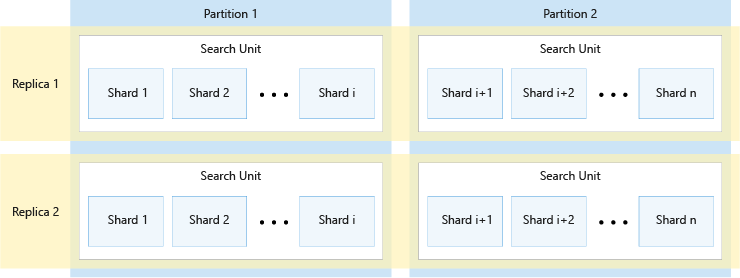
El diagrama anterior es solo un ejemplo. Hay muchas combinaciones de particiones y réplicas posibles, hasta un máximo de 36 unidades de búsqueda totales.
Nota:
El número de réplicas y particiones se dividirse equitativamente en 12 (en concreto, 1, 2, 3, 4, 6, 12). Azure AI Search divide previamente cada índice en 12 particiones para que se pueda repartir en porciones iguales entre todas las particiones. Por ejemplo, si su servicio tiene tres particiones y crea un nuevo índice, cada partición contendrá 4 particiones del índice. La manera en que Azure AI Search particiona un índice es un detalle de implementación, sujeto a cambios en la futura versión. Aunque el número es 12 hoy, no debe esperar que ese número se siempre 12 en el futuro.
Estadísticas de puntuación y sesiones permanentes
Para ofrecer escalabilidad, Azure AI Search distribuye cada índice horizontalmente a través de un proceso de particionamiento, lo que significa que las partes de un índice son físicamente independientes.
De forma predeterminada, la puntuación de un documento se calcula en función de las propiedades estadísticas de los datos de una partición. Este enfoque no suele ser un problema para una gran corpus de datos y proporciona un mejor rendimiento que el cálculo de la puntuación basado en la información de todas las particiones. Dicho esto, el uso de esta optimización del rendimiento puede provocar que dos documentos muy similares (o incluso idénticos) terminen con puntuaciones de relevancia diferentes si acaban en diferentes particiones.
Si prefiere calcular la puntuación en función de las propiedades estadísticas de todas las particiones, puede agregar scoringStatistics=global como un parámetro de consulta (o agregar "scoringStatistics": "global" como un parámetro del cuerpo de la solicitud de consulta).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
El uso de scoringStatistics garantizará que todas las particiones de la misma réplica proporcionen los mismos resultados. Dicho esto, cada réplica puede ser ligeramente distinta entre sí, ya que siempre se actualizan con los cambios más recientes en el índice. En algunos escenarios, es posible que quiera que los usuarios obtengan resultados más coherentes durante una "sesión de consulta". En esos casos, puede proporcionar un sessionId como parte de las consultas. El sessionId es una cadena única que se crea para hacer referencia a una sesión de usuario única.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
Siempre y cuando se use el mismo sessionId, se intentará en lo posible dirigirse a la misma réplica, lo que aumentará la coherencia de los resultados que verán los usuarios.
Nota:
Reutilizar los mismos valores de sessionId repetidamente puede interferir en el equilibrio de carga de las solicitudes entre réplicas y afectar negativamente al rendimiento del servicio de búsqueda. El valor usado como sessionId no puede empezar con un carácter '_'.
Ajuste de relevancia
En Búsqueda de Azure AI, para la búsqueda de palabras clave y la parte de texto de una consulta híbrida, puede configurar parámetros de algoritmo BM25, además de optimizar la relevancia de búsqueda y aumentar las puntuaciones de búsqueda por medio de los siguientes mecanismos.
| Enfoque | Implementación | Descripción |
|---|---|---|
| Configuración de algoritmos BM25 | Índice de búsqueda | Configure cómo la longitud del documento y la frecuencia del término afectan a la puntuación de relevancia. |
| Perfiles de puntuación | Índice de búsqueda | Proporcione criterios para aumentar la puntuación de búsqueda de una coincidencia en función de las características de contenido. Por ejemplo, puede aumentar las coincidencias según su potencial de ingresos, promover elementos más recientes o quizás aumentar los que han permanecido en el inventario demasiado tiempo. Un perfil de puntuación es parte de la definición del índice que se compone de campos, funciones y parámetros ponderados. Puede actualizar un índice existente con cambios en el perfil de puntuación, sin tener que recurrir a una recompilación del índice. |
| Clasificación semántica | Solicitud de consulta | Aplica la comprensión de lectura automática a los resultados de búsqueda, lo que hace que los resultados más pertinentes desde el punto de vista semántico se muevan a la parte superior. |
| Parámetro featuresMode | Solicitud de consulta | Este parámetro se usa principalmente para desempaquetar una puntuación clasificada en BM25, pero se puede usar para en el código que proporciona una solución de puntuación personalizada. |
Parámetro featuresMode (versión preliminar)
Buscar documentos solicitudes admiten un parámetro featuresMode que proporciona más detalles acerca de una puntuación de relevancia BM25 en el nivel de campo. Mientras que @searchScore se calcula para todo el documento (según corresponda, en el contexto de esta consulta), featuresMode muestra información sobre los campos individuales, tal y como se expresa en una estructura de @search.features. La estructura contiene todos los campos usados en la consulta (campos específicos mediante searchFields en una consulta o todos los campos asignados como que permite búsquedas en un índice).
Para cada campo, @search.features proporciona los siguientes valores:
- Número de tokens únicos encontrados en el campo
- Puntuación de similitud, o una medida de la similitud del contenido del campo con respecto al término de consulta
- Frecuencia del término, o el número de veces que el término de la consulta se encontró en el campo
Para una consulta que tiene como destino los campos "descripción" y "título", una respuesta que incluye @search.features podría ser similar a la siguiente:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
Puede utilizar estos puntos de datos en las soluciones de puntuación personalizadas o utilizar la información para depurar los problemas de relevancia de búsqueda.
El parámetro featuresMode no se documenta en las API de REST, pero puede usarlo en una llamada de API de REST en versión preliminar para buscar documentos para buscar texto (palabra clave) que está clasificado por BM25.
Número de resultados clasificados en una respuesta de consulta de texto completo
De manera predeterminada, si no utiliza la paginación, el motor de búsqueda devuelve las 50 coincidencias mejor clasificadas para la búsqueda de texto completo. Puede usar el parámetro top para devolver un número mayor o menor de elementos (hasta 1000 en una sola respuesta). Puede usar skip y next para paginar los resultados. La paginación determina el número de resultados en cada página lógica y admite la navegación de contenido. Para más información, vea Forma de los resultados de la búsqueda.
Si la consulta de texto completo forma parte de una consulta híbrida, puede establecer maxTextRecallSize para aumentar o reducir el número de resultados del lado de texto de la consulta.
La búsqueda de texto completo está sujeta a un límite máximo de 1000 coincidencias (consulte Límites de respuesta de API). Una vez encontradas 1000 coincidencias, el motor de búsqueda deja de buscar más.