Clasificación semántica en Azure AI Search
En Búsqueda de Azure AI, el clasificador semántico es una característica que mejora considerablemente la relevancia de la búsqueda mediante los modelos de reconocimiento del lenguaje de Microsoft para cambiar los resultados de la búsqueda. Este artículo es una introducción de alto nivel para ayudarle a comprender los comportamientos y las ventajas del clasificador semántico.
El clasificador semántico es una característica premium que se factura por uso. Si necesita información general, le recomendamos este artículo, pero, si prefiere empezar a trabajar, siga estos pasos:
Nota:
El clasificador semántico no usa IA generativa ni vectores. Si busca vectores y búsqueda de similitud, consulte Vector de búsqueda en Búsqueda de Azure AI para más información.
¿Qué es la clasificación semántica?
El clasificador semántico es una colección de funcionalidades del lado de la consulta que mejoran la calidad de un resultado de la búsqueda clasificado BM25 o clasificado RRF para consultas basadas en texto, consultas de vectores y consultas híbridas. Cuando la habilitas en el servicio de búsqueda, la clasificación semántica extiende la canalización de ejecución de consultas de dos maneras.
En primer lugar, agrega una clasificación secundaria sobre un conjunto de resultados inicial con clasificación BM25 o Fusión de clasificación recíproca (RRF). Esta clasificación secundaria usa modelos de aprendizaje profundo y multilingües adaptados de Microsoft Bing para promover los resultados más semánticamente relevantes.
En segundo lugar, extrae y devuelve subtítulos y respuestas en la respuesta, que puede representar en una página de búsqueda para mejorar la experiencia de búsqueda del usuario.
Estas son las funcionalidades del clasificador semántico.
| Funcionalidad | Descripción |
|---|---|
| Clasificación L2 | Usa el contexto o el significado semántico de una consulta para calcular una nueva puntuación de relevancia en los resultados clasificados previamente. |
| Títulos y resaltados semánticos | Extrae las oraciones y frases textuales de los campos que mejor resumen el contenido; se resaltan los pasajes clave para facilitar el análisis. Los títulos que resumen un resultado son útiles cuando los campos de contenido individuales son demasiado densos para la página de resultados de búsqueda. El texto resaltado eleva los términos y frases más relevantes para que los usuarios puedan determinar rápidamente por qué se consideró relevante una coincidencia. |
| Respuestas semánticas | Es una subestructura opcional y adicional que se devuelve desde una consulta semántica. Proporciona una respuesta directa a una consulta que se parece a una pregunta. Requiere que un documento tenga texto con las características de una respuesta. |
Cómo funciona el clasificador semántico
El clasificador semántico alimenta una consulta y los resultados para los modelos de reconocimiento del lenguaje hospedados por Microsoft y busca mejores coincidencias.
En la ilustración siguiente se explica el concepto. Usemos como ejemplo el término "capital". Tiene significados diferentes en función de si el contexto es finanzas, ley, geografía o demás. Mediante el reconocimiento del lenguaje, el clasificador semántico puede detectar contexto y promover resultados que se ajusten a la intención de la consulta.
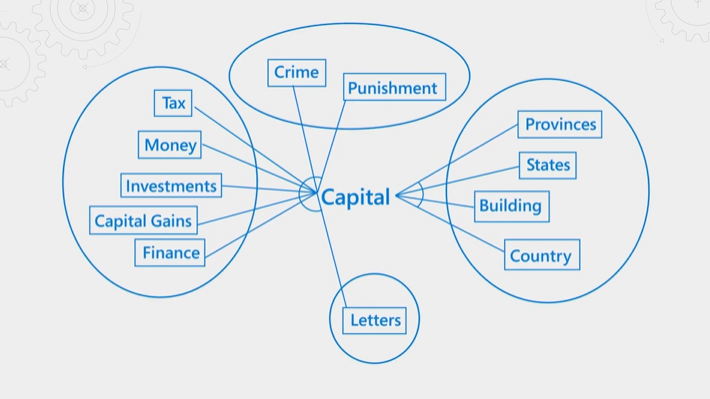
La clasificación semántica es una operación que consume tiempo y recursos. Para completar el procesamiento según la latencia esperada de una operación de consulta, las entradas en el clasificador semántico se consolidan y reducen para que el pasos de reclasificación subyacentes se pueda completar lo más rápido posible.
Hay tres pasos para la clasificador semántico:
- Recopilación y resumen de entradas
- Puntuación de los resultados mediante el clasificador semántico
- Devolución de resultados reclasificados, descripciones y respuestas
Cómo se recopilan y resumen las entradas
En la clasificación semántica, el subsistema de consultas pasa los resultados de búsqueda como entrada para modelos de resumen y clasificación. Dado que los modelos de clasificación tienen restricciones de tamaño de entrada y procesan de forma intensiva, los resultados de búsqueda deben tener un tamaño y una estructura (resumidos) para un control eficaz.
El clasificador semántico comienza con un resultado clasificado BM25 de una consulta de texto o un resultado clasificado RRF desde una consulta de vector o híbrida. Solo se usan campos de texto en el ejercicio de reclasificación y solo los 50 primeros resultados progresan a la clasificación semántica, aunque los resultados incluyan más de 50. Normalmente, los campos usados en la clasificación semántica son informativos y descriptivos.
Para cada documento del resultado de la búsqueda, el modelo de resumen acepta hasta 2000 tokens, donde un token tiene aproximadamente 10 caracteres. Las entradas se ensamblan a partir de los campos "title", "keyword" y "content" enumerados en la configuración semántica.
Cualquier cadena que sea excesivamente larga se recorta para garantizar que la longitud total cumple los requisitos de entrada del paso de resumen. Este ejercicio de recorte es el motivo por el que es importante agregar campos a la configuración semántica en orden de prioridad. Si tiene documentos muy grandes con campos con mucho texto, se omite todo lo que se encuentra después del límite máximo.
Campo semántico Límite de tokens "title" 128 tokens "Palabras clave" 128 tokens "contenido" tokens restantes El resultado del resumen es una cadena de resumen para cada documento, compuesta de la información más relevante de cada campo. Las cadenas de resumen se envían al clasificador para la puntuación y a los modelos de comprensión de lectura automática para títulos y respuestas.
A partir de noviembre de 2024, la longitud máxima de cada cadena de resumen generada que se pasa al clasificador semántico es de 2024 tokens. Anteriormente, era de 256 tokens.
Cómo se puntúa la clasificación
La puntuación se realiza sobre el título y cualquier otro contenido de la cadena de resumen que rellene la longitud de 2048 tokens.
Los subtítulos se evalúan para la relevancia conceptual y semántica, en relación con la consulta proporcionada.
Se asigna un @search.rerankerScore a cada documento en función de la importancia semántica del documento para la solicitud determinada. Las puntuaciones van de 4 a 0 (alta a baja), donde una puntuación más alta indica una mayor relevancia.
Puntuación Significado 4.0 El documento es muy relevante y responde a la pregunta por completo, aunque el pasaje podría contener texto adicional no relacionado con la pregunta. 3,0 El documento es relevante, pero carece de detalles que lo harían completo. 2.0 El documento es algo relevante; responde a la pregunta parcialmente o solo aborda algunos aspectos de la pregunta. 1.0 El documento está relacionado con la pregunta y responde a una pequeña parte de ella. 0,0 El documento es irrelevante. Los resultados se muestran en orden descendente en función de la puntuación y se incluyen en la carga de respuesta de la consulta. La carga útil incluye respuestas, texto sin formato y subtítulos resaltados, así como cualquier campo que se haya marcado como recuperable o especificado en una cláusula SELECT.
Nota:
Para cualquier consulta determinada, las distribuciones de @search.rerankerScore pueden presentar pequeñas variaciones debido a las condiciones en el nivel de infraestructura. También se sabe que las actualizaciones del modelo de clasificación afectan a la distribución. Por estos motivos, si escribe código personalizado para umbrales mínimos o establece la propiedad threshold para consultas híbridas y vectoriales, no establezca unos límites demasiado pormenorizados.
Resultados del clasificador semántico
A partir de cada cadena de resumen, los modelos de comprensión de lectura automática encuentran pasajes que son los más representativos.
Los resultados son:
Un título semántico para el documento. Cada subtítulo está disponible en una versión de texto sin formato y en una versión de resaltado, y con frecuencia es menor que 200 palabras por documento.
Una respuesta semántica opcional, suponiendo que hayas especificado el parámetro
answers, la consulta se planteó como una pregunta y se encuentra un paso en la cadena larga que proporciona una respuesta probable a la pregunta.
Los títulos y respuestas siempre son texto textual del índice. No hay ningún modelo de IA generativo en este flujo de trabajo que cree o componga contenido nuevo.
Funcionalidades y limitaciones semánticas
El clasificador semántico es una tecnología novedosa, por lo que es importante establecer expectativas sobre lo que puede y no puede hacer. Lo que puede hacer:
Promover las coincidencias que están semánticamente más cerca de la intención de la consulta original.
Buscar cadenas para usarlas como títulos y respuestas. Los títulos y las respuestas se devuelven en la respuesta y se pueden representar en una página de resultados de búsqueda.
Lo que el clasificador semántico no puede hacer es volver a ejecutar la consulta en todo el corpus para buscar resultados semánticamente relevantes. La clasificación semántica vuelve a clasificar el conjunto de resultados existente, que consta de los 50 primeros resultados puntuados por el algoritmo de clasificación predeterminado. Además, el clasificador semántico no puede crear nuevas cadenas o información. Los títulos y las respuestas se extraen textualmente del contenido, por lo que si los resultados no incluyen texto parecido a una respuesta, los modelos de lenguaje no producirán uno.
Aunque la clasificación semántica no es ventajosa en todos los escenarios, cierto contenido puede beneficiarse significativamente de sus funcionalidades. Los modelos de lenguaje del clasificador semántico funcionan mejor en contenido que permite búsquedas, que tiene gran cantidad de información y está estructurado como prosa. Una knowledge base, documentación en línea o los documentos con contenido descriptivo son los que más se benefician de las funcionalidades del clasificador semántico.
La tecnología subyacente es de Bing y Microsoft Research, y se integra con la infraestructura de Azure AI Search como una característica de complemento. Para más información sobre las inversiones en investigación e IA que respaldan el uso del clasificador semántico, consulte Formas en que la IA de Bing beneficia a Búsqueda de Azure AI (Microsoft Research Blog).
En el vídeo siguiente se proporciona información general de las funcionalidades.
Disponibilidad y precios
El clasificador semántico está disponible en los servicios de búsqueda en los niveles básico y superior, sujeta a disponibilidad regional.
Al habilitar el clasificador semántico, elige un plan de precios para la característica:
- En volúmenes de consulta más bajos (inferiores a 1000 mensuales), la búsqueda semántica es gratuita.
- En volúmenes de consulta más altos, elige el plan de precios estándar.
En la página de precios de Azure AI Search se muestra la tasa de facturación para diferentes monedas e intervalos.
Los cargos por el clasificador semántico se aplican cuando las solicitudes de consulta incluyen queryType=semantic y la cadena de búsqueda no está vacía (por ejemplo, search=pet friendly hotels in New York). Si la cadena de búsqueda está vacía (search=*), no pagas nada, aunque queryType esté establecido en semantic.
Introducción al clasificador semántico
Inicie sesión en Azure Portal para comprobar que el servicio de búsqueda es Básico o superior
Habilite el clasificador semántico y elegir un plan de precios.
Configure el clasificador semántico en un índice de búsqueda.
Configure consultas para devolver subtítulos y resaltados semánticos.