Tutorial: carga, acceso y exploración de datos en Azure Machine Learning
SE APLICA A:  SDK de Python azure-ai-ml v2 (actual)
SDK de Python azure-ai-ml v2 (actual)
En este tutorial, aprenderá a:
- Carga de datos en el almacenamiento en la nube
- Creación de un activo de datos de Azure Machine Learning
- Acceda a sus datos en un cuaderno para el desarrollo interactivo
- Creación de nuevas versiones de recursos de datos
Normalmente, un proyecto de aprendizaje automático comienza con el análisis exploratorio de datos (EDA), el preprocesamiento de datos (limpieza, ingeniería de características) y la creación de prototipos de modelo de Machine Learning para validar hipótesis. Esta fase de prototipado del proyecto es muy interactiva. Se presta al desarrollo en un IDE o en un cuaderno Jupyter, con una consola interactiva Python. Este tutorial describe estas ideas.
En este vídeo se muestra cómo empezar a trabajar en el Estudio de Azure Machine Learning para que pueda seguir los pasos del tutorial. En el vídeo se muestra cómo crear un cuaderno, clonar el cuaderno, crear una instancia de proceso y descargar los datos necesarios para el tutorial. Estos pasos también se describen en las secciones siguientes.
Requisitos previos
-
Para usar Azure Machine Learning, necesita un área de trabajo. Si no tiene una, complete Crear recursos necesarios para empezar para crear un área de trabajo y obtener más información sobre su uso.
Importante
Si el área de trabajo de Azure Machine Learning está configurada con una red virtual administrada, es posible que tenga que agregar reglas de salida para permitir el acceso a los repositorios de paquetes de Python públicos. Para más información, consulte Escenario: Acceso a paquetes de aprendizaje automático públicos.
-
Inicie sesión en Studio y seleccione el área de trabajo si aún no está abierta.
-
Abra o cree una libreta en el área de trabajo:
- Si desea copiar y pegar código en celdas, cree un cuaderno nuevo.
- O, abra tutorials/get-started-notebooks/explore-data.ipynb de la sección Ejemplos de Studio A continuación, seleccione Clonar para agregar el cuaderno a sus Archivos. Para encontrar cuadernos de ejemplo, consulte Aprender con cuadernos de ejemplo.
Establecer el kernel y abrirlo en Visual Studio Code (VS Code)
En la barra superior del cuaderno abierto, cree una instancia de proceso si aún no tiene una.

Si la instancia de proceso se detiene, seleccione Iniciar proceso y espere hasta que se ejecute.

Espere hasta que la instancia de cálculo esté en ejecución. A continuación, asegúrese de que el kernel, que se encuentra en la parte superior derecha, es
Python 3.10 - SDK v2. Si no es así, use la lista desplegable para seleccionar este kernel.
Si no ve este kernel, compruebe que la instancia de proceso se está ejecutando. Si es así, seleccione el botón Actualizar situado en la parte superior derecha del cuaderno.
Si ves un banner que dice que debes autenticarte, selecciona Autenticar.
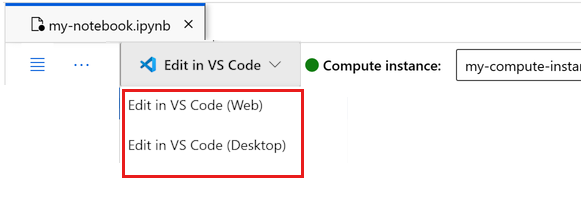
Puede ejecutar el cuaderno aquí o abrirlo en VS Code para un entorno de desarrollo integrado (IDE) completo con la eficacia de los recursos de Azure Machine Learning. Seleccione Abrir en VS Codey, a continuación, seleccione la opción web o de escritorio. Cuando se inicia de esta manera, VS Code se adjunta a la instancia de proceso, el kernel y el sistema de archivos del área de trabajo.




Importante
El resto de este tutorial contiene celdas del cuaderno del tutorial. Cópielos y péguelos en su nuevo cuaderno, o cambie al cuaderno actual si lo ha clonado.
Descargar los datos que se usan en este tutorial
Para la ingesta de datos, Azure Data Explorer maneja datos sin procesar en estos formatos. En este tutorial se usa esta muestra de datos de clientes de tarjetas de crédito en formato CSV. Veremos los pasos a seguir en un recurso de Azure Machine Learning. En ese recurso, crearemos una carpeta local con el nombre sugerido de datos directamente debajo de la carpeta donde se encuentra este cuaderno.
Nota:
Este tutorial depende de los datos colocados en una ubicación de carpeta de recursos de Azure Machine Learning. Para este tutorial, 'local' significa una ubicación de carpeta en ese recurso de Azure Machine Learning.
Seleccione Abrir terminal debajo de los tres puntos, como se muestra en esta imagen:
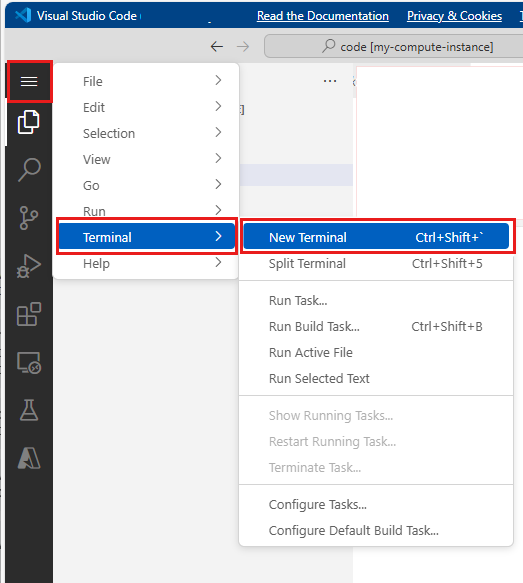
La ventana de terminal se abre en una nueva pestaña.
Asegúrese de
cd(Cambiar directorio) a la misma carpeta donde se encuentra este cuaderno. Por ejemplo, si el cuaderno está en una carpeta llamada get-started-notebooks:cd get-started-notebooks # modify this to the path where your notebook is locatedEscriba estos comandos en la ventana de terminal para copiar los datos a la instancia de proceso:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvAhora puede cerrar la ventana de terminal.
Para obtener más información sobre los datos en el repositorio de Machine Learning de UC Irvine, visite este recurso.
Creación de un identificador en el área de trabajo
Antes de explorar el código, necesita una manera de hacer referencia al área de trabajo. Creará ml_client para un manipulador para el área de trabajo. A continuación, use ml_client para administrar los recursos y puestos de trabajo.
En la celda siguiente, escriba el identificador de suscripción, el nombre del grupo de recursos y el nombre del área de trabajo. Para establecer estos valores:
- En la barra de herramientas de Estudio de Azure Machine Learning superior derecha, seleccione el nombre del área de trabajo.
- Copie el valor del área de trabajo, el grupo de recursos y el identificador de suscripción en el código.
- Debe copiar individualmente los valores de uno en uno, cerrar el área y pegar y, a continuación, continuar con el siguiente.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Nota:
La creación de MLClient no se conectará al área de trabajo. La inicialización del cliente es diferida. Espera para la primera vez que necesita realizar una llamada. Esto sucede en la siguiente celda de código.
Cargar los datos en el almacenamiento en la nube
Azure Machine Learning usa identificadores de uniforme de recursos (URI), que apuntan a ubicaciones de almacenamiento en la nube. Un URI facilita el acceso a los datos en cuadernos y trabajos. Los formatos de URI de datos tienen un formato similar a las URL web que se usan en el navegador web para acceder a páginas web. Por ejemplo:
- Accede a los datos desde un servidor público https:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Acceso a datos desde Azure Data Lake Gen 2:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Un recurso de datos de Azure Machine Learning es similar a los marcadores del explorador web (favoritos). En lugar de recordar largas rutas de acceso de almacenamiento (URI) que apuntan a los datos usados con más frecuencia, puede crear un recurso de datos y, luego, acceder a ese recurso con un nombre descriptivo.
La creación de un recurso de datos también crea una referencia a la ubicación del origen de datos, junto con una copia de sus metadatos. Dado que los datos permanecen en su ubicación existente, no incurre en ningún costo de almacenamiento adicional ni arriesga la integridad de los orígenes de datos. Puede crear recursos de datos a partir de almacenes de datos de Azure Machine Learning, Azure Storage, URL públicas y archivos locales.
Sugerencia
Para cargas de datos de menor tamaño, la creación de activos de datos de Azure Machine Learning funciona bien para cargas de datos desde recursos de máquinas locales al almacenamiento en la nube. Este enfoque evita la necesidad de herramientas o utilidades adicionales. Sin embargo, una carga de datos de mayor tamaño puede requerir una herramienta o utilidad dedicada, por ejemplo, azcopy. La herramienta de línea de comandos azcopy mueve datos hacia y desde Azure Storage. Para más información sobre azcopy, visite este recurso.
La siguiente celda del cuaderno crea el activo de datos. El ejemplo de código carga el archivo de datos sin procesar en el recurso de almacenamiento en la nube asignado.
Cada vez que cree un activo de datos, necesitará una versión única para él. Si la versión ya existe, aparecerá un error. En este código, se usa la "initial" para la primera lectura de los datos. Si esa versión ya existe, no se vuelve a crear.
También puede omitir el parámetro version. En este caso, se genera un número de versión automáticamente, empezando por 1 y, a continuación, incrementando desde allí.
En este tutorial se usa el nombre "initial" como primera versión. El tutorial Creación de canalizaciones de aprendizaje automático de producción también usará esta versión de los datos, por lo que aquí se usa un valor que verá de nuevo en ese tutorial.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Para examinar los datos cargados, seleccione Datos a la izquierda. Los datos se cargaron y se creó un activo de datos:
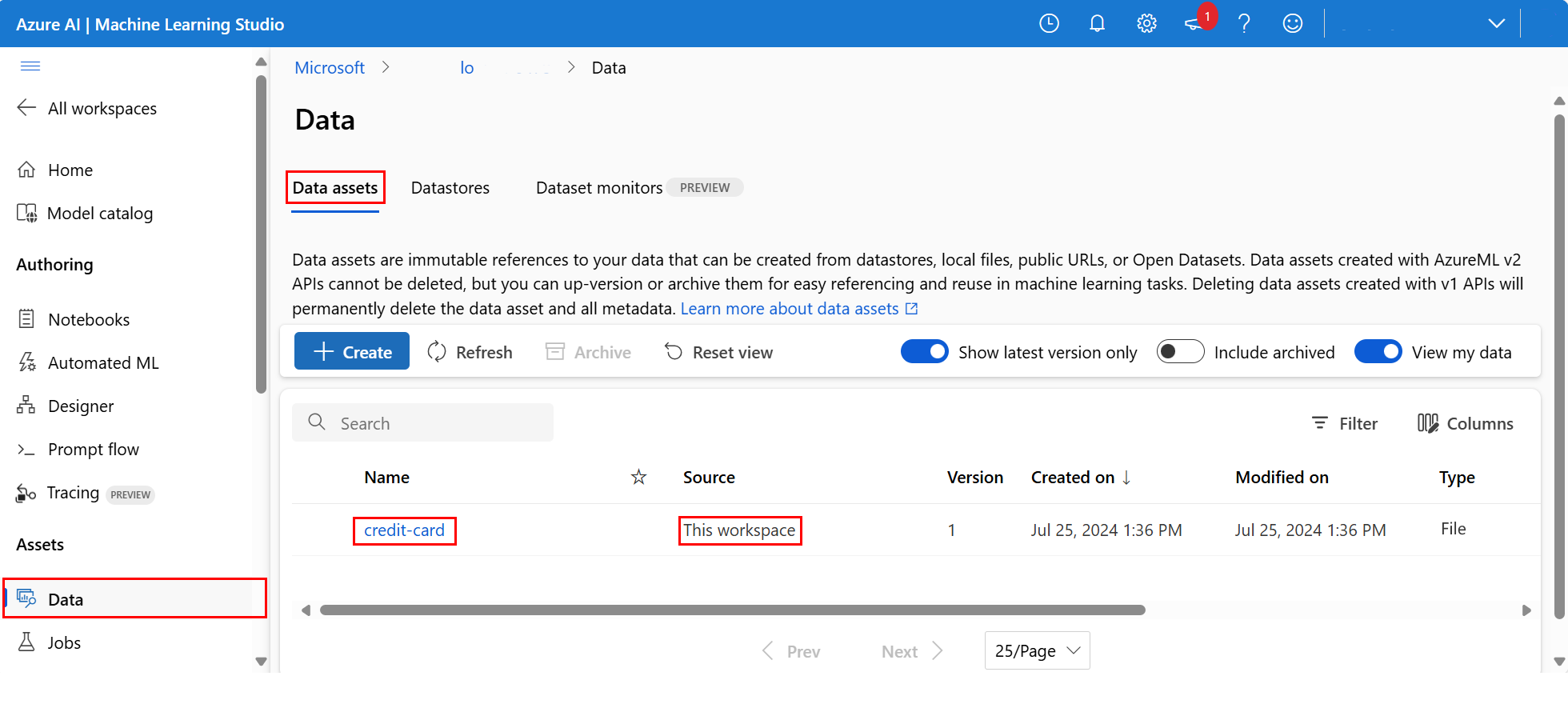
Estos datos se denominan tarjeta de crédito, y en la pestaña Activos de datos, podemos verlos en la columna Nombre.
Un almacén de datos de Azure Machine Learning es una referencia a una cuenta de almacenamiento existente en Azure. Un almacén de datos ofrece las siguientes ventajas
Tener una API común y fácil de usar para interactuar con diferentes tipos de almacenamiento
- Almacén de Azure Data Lake
- Blob
- Archivos
y métodos de autenticación.
Una forma más fácil de descubrir almacenes de datos útiles, cuando se trabaja en equipo.
En sus scripts, una forma de ocultar la información de conexión para el acceso a datos basado en credenciales (service principal/SAS/key).
Acceso a los datos en un cuaderno
Pandas admite directamente URI - este ejemplo muestra cómo leer un archivo CSV de un Azure Machine Learning Datastore:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Sin embargo, como se mencionó anteriormente, puede llegar a ser difícil recordar estas URI. Además, debe sustituir manualmente todos los valores <substring> del comando pd.read_csv por los valores reales de sus recursos.
Es recomendable crear activos de datos para los datos a los que se accede con frecuencia. Aquí hay una manera más fácil de acceder al archivo CSV en Pandas:
Importante
En una celda del cuaderno, ejecute este código para instalar la librería azureml-fsspec Python en el núcleo Jupyter:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Para más información sobre el acceso a datos en un cuaderno, visite Acceso a datos desde el almacenamiento en la nube de Azure durante el desarrollo interactivo.
Creación de una nueva versión del recurso de datos
Los datos necesitan una limpieza ligera para ser aptos para un modelo de aprendizaje automático. Tiene:
- dos encabezados
- una columna de ID de cliente; no usaremos esta característica en Machine Learning
- espacios en el nombre de la variable de respuesta
Además, en comparación con el formato CSV, el formato de archivo Parquet se convierte en una mejor forma de almacenar estos datos. Parquet ofrece compresión y mantiene el esquema. Para limpiar los datos y almacenarlos en Parquet, use:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
Esta tabla muestra la estructura de los datos en el archivo original default_of_credit_card_clients.csv .CSV descargado en un paso anterior. Los datos cargados contienen 23 variables explicativas y 1 variable de respuesta, como se muestra aquí:
| Nombres de columna | Tipo de variable | Descripción |
|---|---|---|
| X1 | Explicación | Importe del crédito concedido (en dólares NT): incluye tanto el crédito al consumo individual como su crédito familiar (complementario). |
| X2 | Explicación | Sexo (1 = masculino; 2 = femenino). |
| X3 | Explicación | Estudios (1 = postgrado; 2 = universidad; 3 = bachillerato; 4 = otros). |
| X4 | Explicación | Estado civil (1 = casado; 2 = soltero; 3 = otros). |
| X5 | Explicación | Edad (años). |
| X6-X11 | Explicación | Historial de pagos anteriores. Realizamos un seguimiento de los registros de pagos mensuales anteriores (de abril a septiembre de 2005). -1 = pago puntual; 1 = retraso en el pago de un mes; 2 = retraso en el pago de dos meses; . . .; 8 = retraso en el pago durante ocho meses; 9 = retraso en el pago durante nueve meses o más. |
| X12-17 | Explicación | Importe del extracto de cuenta (dólares NT) de abril a septiembre de 2005. |
| X18-23 | Explicación | Importe del pago anterior (NT dólar) de abril a septiembre de 2005. |
| Y | Response | Pago predeterminado (Sí = 1, No = 0) |
A continuación, cree una nueva versión del activo de datos (los datos se cargan automáticamente en el almacenamiento en la nube). Para esta versión, agregaremos un valor de hora, por lo que cada vez que se ejecute este código, se creará un número de versión diferente.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
El archivo parquet limpiado es la fuente de datos de la última versión. Este código muestra primero el conjunto de resultados de la versión CSV y después la versión Parquet:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Limpieza de recursos
Si quiere continuar con otros tutoriales, ve a Pasos siguientes.
Detención de una instancia de proceso
Si no va a utilizar ahora la instancia de proceso, deténgala:
- En el estudio, en el área de navegación de la izquierda, seleccione Proceso.
- En las pestañas superiores, seleccione Instancia de proceso.
- Seleccione la instancia de proceso en la lista.
- En la barra de herramientas superior, seleccione Detener.
Eliminación de todos los recursos
Importante
Los recursos que creó pueden usarse como requisitos previos para otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Si no va a usar ninguno de los recursos que ha creado, elimínelos para no incurrir en cargos:
En Azure Portal, en el cuadro de búsqueda, escriba Grupos de recursos y selecciónelo en los resultados.
En la lista, seleccione el grupo de recursos que creó.
En la página Información general, seleccione Eliminar grupo de recursos.
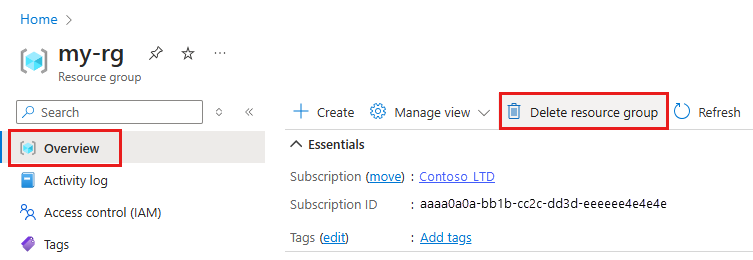
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.
Pasos siguientes
Para obtener más información sobre los recursos de datos, visite Crear recursos de datos.
Para obtener más información sobre los almacenes de datos, visite Crear almacenes de datos.
Continúe con el siguiente tutorial para aprender a desarrollar un script de entrenamiento: