Creación y administración de recursos de datos
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
En este artículo se muestra cómo crear y administrar un recurso de datos en Azure Machine Learning.
Los recursos de datos pueden ayudarle cuando necesite:
- Control de versiones: los recursos de datos admiten el control de versiones de los datos.
- Reproducibilidad: una vez creada una versión de recurso de datos, es inmutable. No se puede modificar ni eliminar. Por lo tanto, se pueden reproducir trabajos de entrenamiento o canalizaciones que consumen el recurso de datos.
- Auditabilidad: dado que la versión del recurso de datos es inmutable, puede supervisar las versiones del recurso, quién actualizó una versión y cuándo se produjeron las actualizaciones de la versión.
- Linaje: puede ver qué trabajos o canalizaciones consumen los datos de cualquier recurso de datos determinado.
- Facilidad de uso: un activo de datos de Azure Machine Learning se parece a los marcadores del explorador web (favoritos). En lugar de recordar rutas de acceso de almacenamiento largas (URI) que hacen referencia a los datos usados con frecuencia en Azure Storage, puede crear una versión del recurso de datos y, luego, acceder a esa versión del recurso con un nombre descriptivo (por ejemplo:
azureml:<my_data_asset_name>:<version>).
Sugerencia
Para acceder a los datos en una sesión interactiva (por ejemplo, un cuaderno) o un trabajo, no es necesario crear primero un recurso de datos. Puede usar identificadores URI del almacén de datos para acceder a los datos. Los identificadores URI del almacén de datos ofrecen una manera sencilla de acceder a los datos para empezar a trabajar con Azure Machine Learning.
Requisitos previos
Para crear y trabajar con recursos de datos, necesita lo siguiente:
Suscripción a Azure. Si no tiene una, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
Un área de trabajo de Azure Machine Learning. Creación de recursos para el área de trabajo.
Creación de recursos de datos
Al crear el recurso de datos, debe establecer el tipo de recurso de datos. Azure Machine Learning admite tres tipos de recursos de datos:
| Tipo | API | Escenarios canónicos |
|---|---|---|
| Archivo Referencia a un único archivo. |
uri_file |
Lectura de un único archivo en Azure Storage (el archivo puede tener cualquier formato). |
| Carpeta Referencia a una carpeta |
uri_folder |
Lectura de una carpeta de archivos Parquet o CSV en Pandas o Spark. Lectura de datos no estructurados (imágenes, texto, audio, etc.) ubicados en una carpeta. |
| Tabla Referencia a una tabla de datos |
mltable |
Tiene un esquema complejo sujeto a cambios frecuentes o necesita un subconjunto de datos tabulares grandes. AutoML con tablas. Lectura de datos no estructurados (imágenes, texto, audio, etc.) que se distribuyen entre varias ubicaciones de almacenamiento. |
Nota:
Use solo las nuevas líneas insertadas en archivos .csv si registra los datos como una MLTable. Las nuevas líneas insertadas en archivos CSV pueden provocar valores de campo desalineados al leer los datos. MLTable tiene el parámetro support_multi_line disponible en la transformación de read_delimited para interpretar los saltos de línea entre comillas como un registro.
Al consumir el recurso de datos en un trabajo de Azure Machine Learning, puede montar o descargar el recurso en los nodos de proceso. Para más información, visite Modos.
También debe especificar un parámetro path que apunte a la ubicación del recurso de datos. Rutas de acceso admitidas:
| Ubicación | Ejemplos |
|---|---|
| Ruta de acceso en la máquina local | ./home/username/data/my_data |
| Ruta de acceso en un almacén de datos | azureml://datastores/<data_store_name>/paths/<path> |
| Ruta de acceso en un servidor http(s) público | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Ruta de acceso en Azure Storage | (Blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS Gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS Gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Nota
Al crear un recurso de datos desde una ruta de acceso local, se cargará automáticamente en el almacén de datos predeterminado en la nube de Azure Machine Learning.
Creación de un recurso de datos: tipo de archivo
Un recurso de datos de tipo de archivo (uri_file) apunta a un único archivo en el almacenamiento (por ejemplo, un archivo .csv). Puede crear un recurso de datos con tipo de archivo con:
Cree un archivo YAML y copie y pegue el siguiente fragmento de código. Asegúrese de actualizar los marcadores de posición <> con:
- el nombre del recurso de datos
- la versión
- descripción
- la ruta de acceso a un único archivo en una ubicación admitida
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
A continuación, ejecute el comando siguiente en la CLI. Asegúrese de actualizar el marcador de posición <filename> con el nombre del archivo YAML.
az ml data create -f <filename>.yml
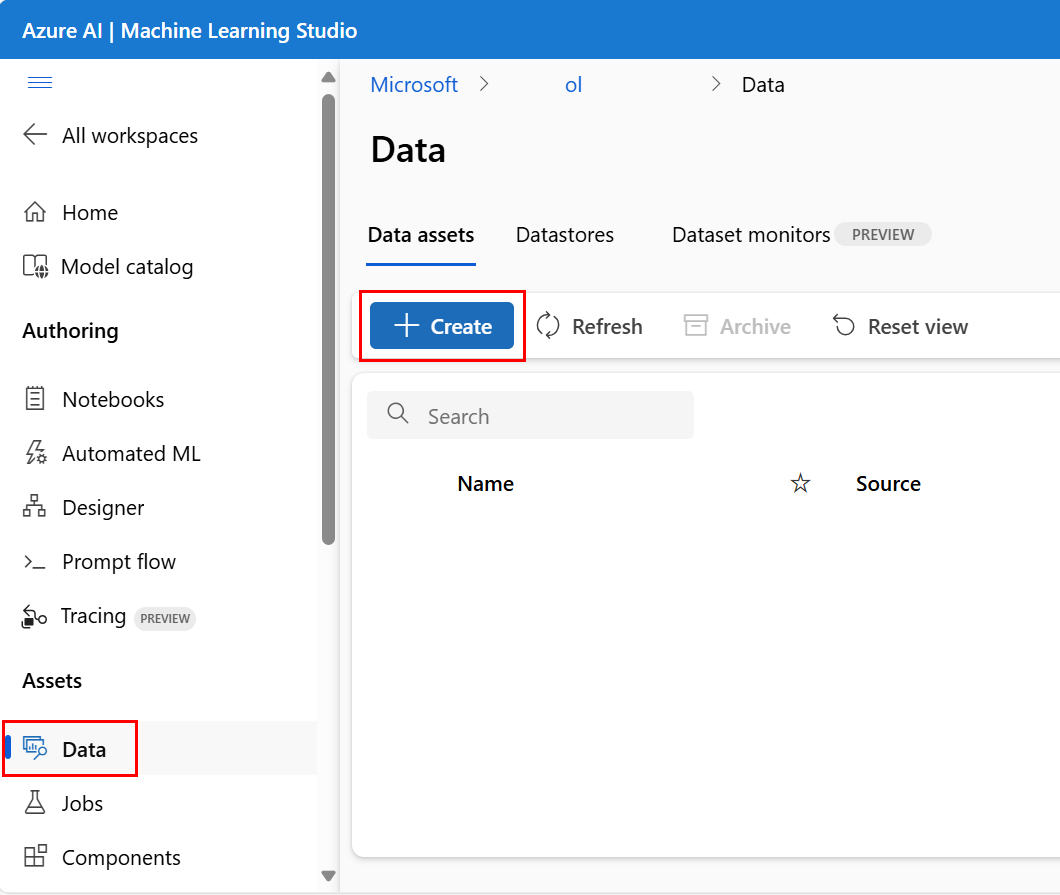

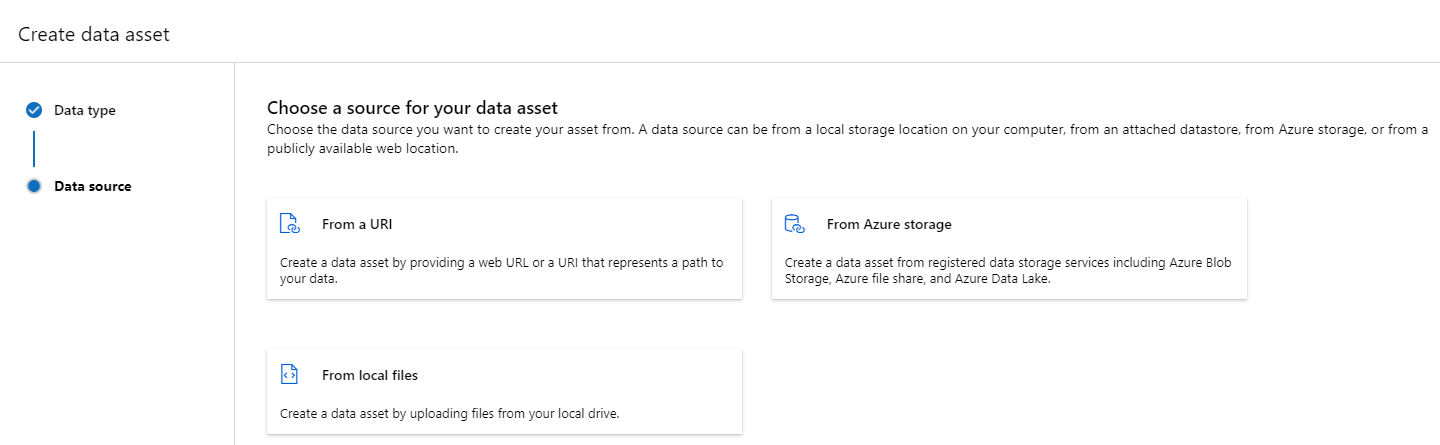
Creación de un recurso de datos: tipo de carpeta
Un recurso de datos de tipo de carpeta (uri_folder) apunta a una carpeta en un recurso de almacenamiento, por ejemplo, una carpeta que contiene varias subcarpetas de imágenes. Puede crear un recurso de datos con tipo de carpeta con:
Copie y pegue el código siguiente en un nuevo archivo YAML. Asegúrese de actualizar los marcadores de posición <> con:
- El nombre del recurso de datos
- La versión
- Descripción
- La ruta de acceso a una carpeta en una ubicación admitida
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
A continuación, ejecute el comando siguiente en la CLI. Asegúrese de actualizar el marcador de posición <filename> con el nombre del archivo YAML.
az ml data create -f <filename>.yml

Creación de un recurso de datos: tipo de tabla
Las tablas de Azure Machine Learning (MLTable) tienen una funcionalidad enriquecida, que se describe con más detalle en Uso de tablas en Azure Machine Learning. En lugar de repetir esa documentación aquí, lea este ejemplo que describe cómo crear un recurso de datos con tipo de tabla usando datos de Titanic que se encuentran en una cuenta de Azure Blob Storage disponible públicamente.
En primer lugar, cree un directorio denominado datos y cree un archivo denominado MLTable:
mkdir data
touch MLTable
Después, copie y pegue el YAML siguiente en el archivo MLTable que creó en el paso anterior:
Precaución
No cambie el nombre del archivo MLTable a MLTable.yaml o MLTable.yml. Azure Machine Learning espera un archivo MLTable.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Ejecute el siguiente comando en la CLI. Asegúrese de actualizar los marcadores de posición <> con los valores de nombre y versión del recurso de datos.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Importante
path debe ser una carpeta que contenga un archivo MLTable válido.
Creación de recursos de datos a partir de salidas de trabajo
Puede crear un recurso de datos a partir de un trabajo de Azure Machine Learning. Para ello, establezca el parámetro name en la salida. En este ejemplo, se envía un trabajo que copia datos de un almacén de blobs público en el almacén de datos de Azure Machine Learning predeterminado y crea un recurso de datos denominado job_output_titanic_asset.
Cree un archivo YAML de especificación de trabajo (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
A continuación, envíe el trabajo mediante la CLI:
az ml job create --file <file-name>.yml
Administración de recursos de datos
Eliminación de un recurso de datos
Importante
Por diseño, no se admite la eliminación de recursos de datos.
Si Azure Machine Learning permitía la eliminación de recursos de datos, tendría los siguientes efectos adversos y negativos:
- Los trabajos de producción que consumen recursos de datos que se eliminaron posteriormente producirán un error.
- Sería más difícil reproducir un experimento de ML.
- El linaje del trabajo se interrumpiría, ya que sería imposible ver la versión del recurso de datos eliminado.
- No podría hacer un seguimiento y auditar correctamente, ya que podrían faltar versiones.
Por lo tanto, la inmutabilidad de los recursos de datos proporciona un nivel de protección al trabajar en un equipo que crea cargas de trabajo de producción.
Para un recurso de datos creado por error (por ejemplo, con un nombre, un tipo o una ruta de acceso incorrectos), Azure Machine Learning ofrece soluciones para abordar la situación sin las consecuencias negativas de la eliminación:
| Quiero eliminar este recurso de datos porque… | Solución |
|---|---|
| El nombre es incorrecto | Archive el recurso de datos |
| El equipo ya no usa el recurso de datos. | Archive el recurso de datos |
| Desordena la lista de recursos de datos. | Archive el recurso de datos |
| La ruta de acceso es incorrecta | Cree una nueva versión del recurso de datos (mismo nombre) con la ruta de acceso correcta. Para más información, consulte Creación de recursos de datos. |
| Tiene un tipo incorrecto. | En este momento, Azure Machine Learning no permite la creación de una nueva versión que sea de tipo diferente en comparación con la versión inicial. (1) Archive el recurso de datos (2) Cree un nuevo recurso de datos con un nombre diferente con el tipo correcto. |
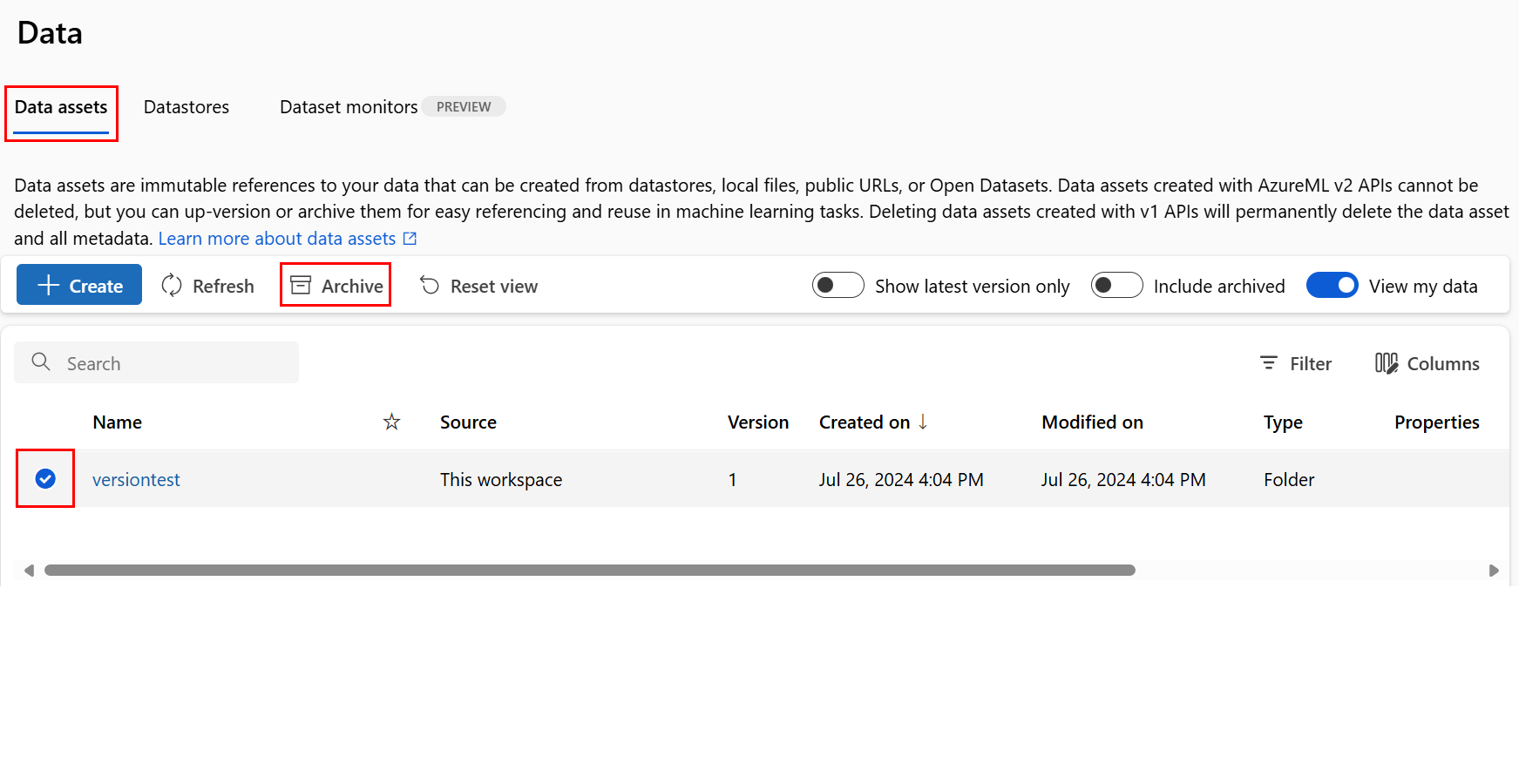
Archivado de un recurso de datos
Al archivar un recurso de datos, este se oculta de manera predeterminada de las consultas de lista (por ejemplo, en la az ml data list de la CLI) y de la lista de recursos de datos en la interfaz de usuario de Studio. Todavía puede seguir haciendo referencia a un recurso de datos archivado y usarlo en los flujos de trabajo. Puede archivar:
- Todas las versiones del recurso de datos con un nombre determinado
o
- Una versión específica del recurso de datos
Archivado de todas las versiones de un recurso de datos
Para archivar todas las versiones del recurso de datos con un nombre determinado, utilice:
Ejecute el comando siguiente. Asegúrese de actualizar los marcadores de posición <> con su información.
az ml data archive --name <NAME OF DATA ASSET>
Archivado de una versión específica del recurso de datos
Para archivar una versión específica del recurso de datos, use:
Ejecute el comando siguiente. Asegúrese de actualizar los marcadores de posición <> con el nombre y la versión del recurso de datos.
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
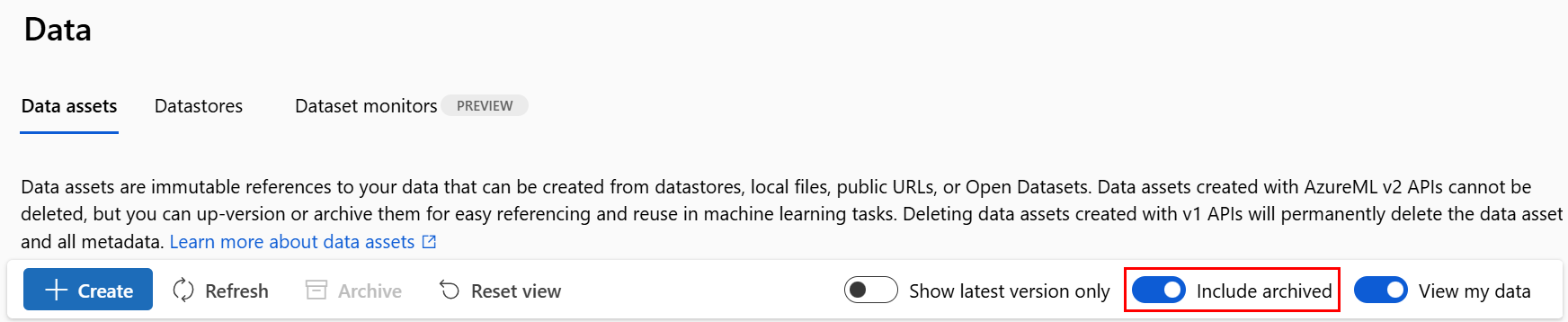
Restauración de un recurso de datos archivado
Puede restaurar un recurso de datos archivado. Si se archivan todas las versiones del recurso de datos, no se pueden restaurar sus versiones individuales. Debe restaurar todas las versiones.
Restauración de todas las versiones de un recurso de datos
Para restaurar todas las versiones del recurso de datos con un nombre determinado, utilice:
Ejecute el comando siguiente. Asegúrese de actualizar los marcadores de posición <> con el nombre del recurso de datos.
az ml data restore --name <NAME OF DATA ASSET>
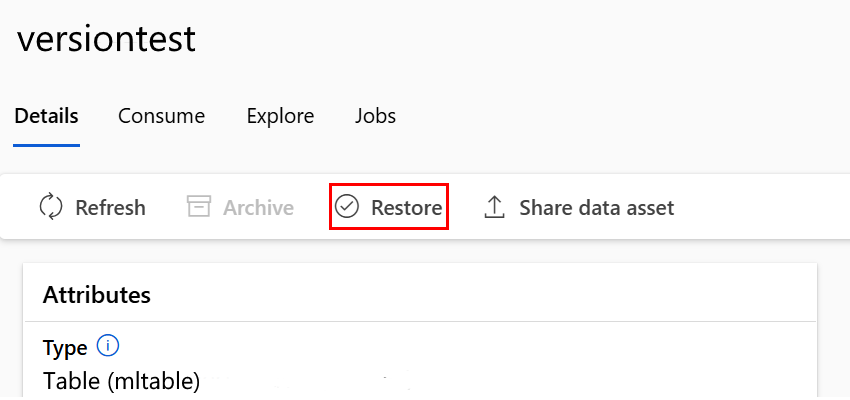
Restauración de una versión específica del recurso de datos
Importante
Si se archivaron todas las versiones del recurso de datos, no puede restaurar sus versiones individuales. Debe restaurar todas las versiones.
Para restaurar una versión específica del recurso de datos, use:
Ejecute el comando siguiente. Asegúrese de actualizar los marcadores de posición <> con el nombre y la versión del recurso de datos.
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Linaje de datos
El linaje de datos es, en términos generales, el ciclo de vida que abarca el origen de los datos y que se mueve con el tiempo en el almacenamiento. Lo usan diferentes tipos de escenarios de búsqueda retroactiva, por ejemplo:
- Solución de problemas
- Seguimiento de las causas raíz en canalizaciones de ML
- Depuración
El análisis de calidad de los datos, el cumplimiento y los escenarios de tipo "what if" también usan el linaje. El linaje se representa visualmente para mostrar los datos que se transfieren del origen al destino y también trata las transformaciones de datos. Dada la complejidad de la mayoría de los entornos de datos empresariales, estas vistas pueden ser difíciles de entender si no se consolidan ni enmascaran los puntos de datos periféricos.
En una canalización de Azure Machine Learning, los recursos de datos muestran el origen de los datos y cómo se procesaron los datos, por ejemplo:
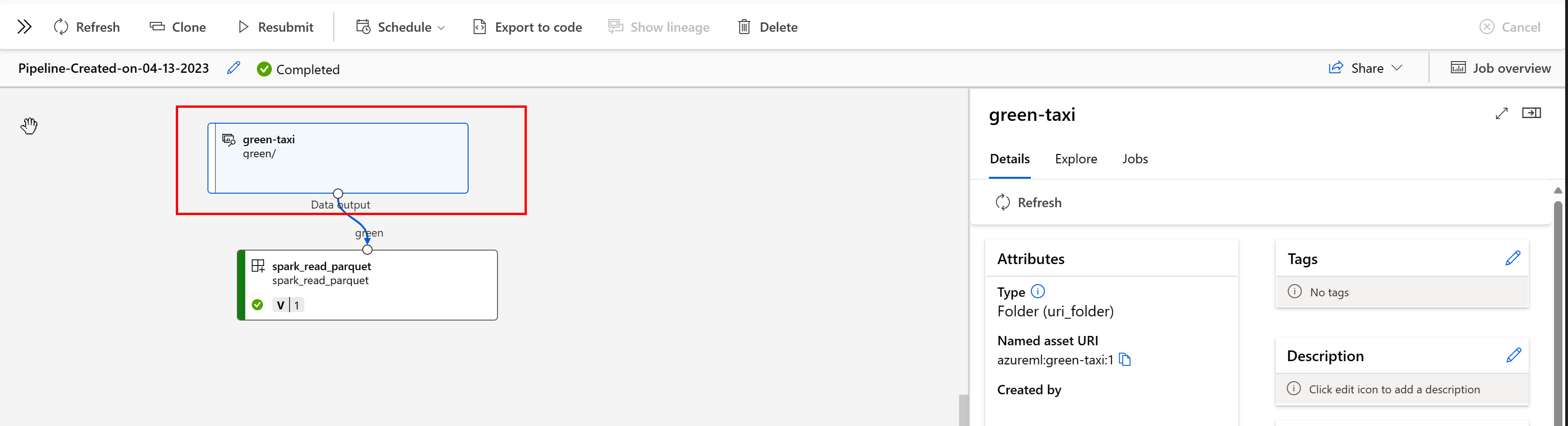
Puede ver los trabajos que consumen el recurso de datos en la interfaz de usuario de Estudio. En primer lugar, seleccione Datos en el menú izquierdo y, después, seleccione el nombre del recurso de datos. Observe los trabajos que consumen el recurso de datos:
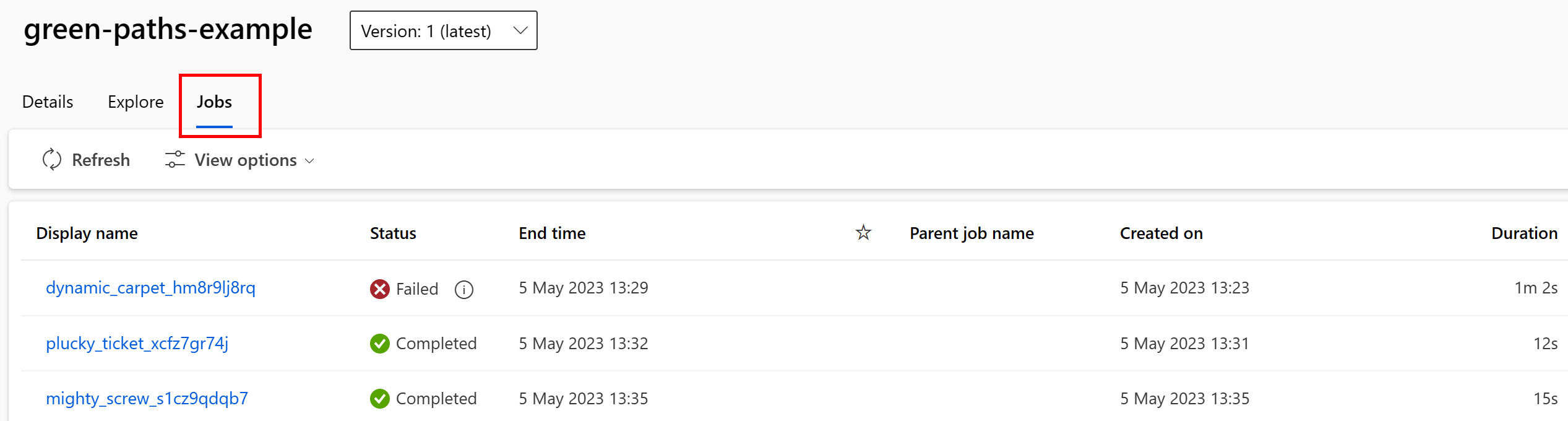
La vista de trabajos en Recursos de datos facilita la búsqueda de errores de trabajos y el análisis de la causa raíz en las canalizaciones y la depuración de ML.
Etiquetado de recursos de datos
Los recursos de datos admiten el etiquetado, que son otros metadatos aplicados al recurso de datos como par clave-valor. El etiquetado de datos proporciona muchas ventajas:
- Descripción de la calidad de los datos. Por ejemplo, si en la organización se usa una arquitectura de almacén de lago de medallón, puede etiquetar recursos con
medallion:bronze(sin procesar),medallion:silver(validado) ymedallion:gold(enriquecido). - Búsqueda y filtrado eficaces de los datos para ayudar a la detección de datos.
- Identificación de datos personales confidenciales para administrar y controlar correctamente el acceso a los datos. Por ejemplo,
sensitivity:PII/sensitivity:nonPII. - Determinación de si los datos están aprobados por una auditoría de IA responsable (IAR). Por ejemplo,
RAI_audit:approved/RAI_audit:todo.
Puede agregar etiquetas a los recursos de datos como parte de su flujo de creación, o bien puede agregar etiquetas a los recursos de datos existentes. En esta sección se muestran ambas opciones:
Adición de etiquetas como parte del flujo de creación de recursos de datos
Cree un archivo YAML y copie y pegue el siguiente fragmento de código en él. Asegúrese de actualizar los marcadores de posición <> con:
- el nombre del recurso de datos
- la versión
- descripción
- etiquetas (pares clave-valor)
- la ruta de acceso a un único archivo en una ubicación admitida
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Ejecute el siguiente comando en la CLI. Asegúrese de actualizar el marcador de posición <filename> con el nombre del archivo YAML.
az ml data create -f <filename>.yml
Adición de etiquetas a un recurso de datos existente
Ejecute el comando siguiente en la CLI de Azure. Asegúrese de actualizar los marcadores de posición <> con:
- El nombre del recurso de datos
- La versión
- Par clave-valor para la etiqueta
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Prácticas recomendadas en relación con las versiones
Normalmente, los procesos de ETL organizan la estructura de carpetas en Azure Storage por tiempo, por ejemplo:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
La combinación de carpetas estructuradas por hora y versión y tablas de Azure Machine Learning (MLTable) permite crear conjuntos de datos con versiones. Un ejemplo hipotético muestra cómo lograr datos con versiones con tablas de Azure Machine Learning. Supongamos que tiene un proceso que carga imágenes de una cámara en Azure Blob Storage cada semana con esta estructura:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Nota:
Aunque se muestra cómo crear versiones de datos de imagen (jpeg), el mismo enfoque funciona para cualquier tipo de archivo (por ejemplo, Parquet, CSV).
Con las tablas de Azure Machine Learning (mltable), cree una tabla de rutas de acceso que incluyen los datos hasta el final de la primera semana en 2023. Después, cree un recurso de datos:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Al final de la semana siguiente, el ETL ha actualizado los datos para incluir más datos:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
La primera versión (20230108) solo continúa montando o descargando los archivos desde year=2022/week=52 y year=2023/week=1, porque las rutas de acceso se declaran en el archivo MLTable. Esto garantiza la reproducibilidad de los experimentos. Para crear una nueva versión del recurso de datos que incluye year=2023/week2, use:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Ahora, tiene dos versiones de los datos, donde el nombre de la versión corresponde a la fecha en que se cargaron las imágenes en el almacenamiento:
- 20230108: las imágenes hasta el 8-ene-2023.
- 20230115: las imágenes hasta el 15-ene-2023.
En ambos casos, MLTable crea una tabla de rutas que solo incluyen las imágenes hasta esas fechas.
En un trabajo de Azure Machine Learning, puede montar o descargar esas rutas de acceso en MLTable con versiones en el destino de proceso mediante los eval_download modos o eval_mount:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Nota
Los modos eval_mount y eval_download son únicos para MLTable. En este caso, la funcionalidad de tiempo de ejecución de datos de AzureML evalúa el archivo MLTable y monta las rutas de acceso en el destino de proceso.