Configuración de puntos de conexión de flujo de datos
Importante
En esta página se incluyen instrucciones para administrar componentes de Operaciones de IoT de Azure mediante manifiestos de implementación de Kubernetes, que se encuentra en versión preliminar. Esta característica se proporciona con varias limitacionesy no se debe usar para cargas de trabajo de producción.
Consulte Términos de uso complementarios para las versiones preliminares de Microsoft Azure para conocer los términos legales que se aplican a las características de Azure que se encuentran en la versión beta, en versión preliminar o que todavía no se han publicado para que estén disponibles con carácter general.
Para empezar a trabajar con flujos de datos, cree primero puntos de conexión de flujo de datos. Un punto de conexión de flujo de datos es el punto de conexión para el flujo de datos. Puede utilizar un punto de conexión como origen o destino del flujo de datos. Algunos tipos de puntos de conexión pueden utilizarse tanto como fuentes como destinos, mientras que otros son solo para destinos. Un flujo de datos necesita al menos un punto de conexión de origen y un punto de conexión de destino.
Use la tabla siguiente para elegir el tipo de punto de conexión que se va a configurar:
| Tipo de punto de conexión | Descripción | Se puede usar como origen | Se puede usar como destino |
|---|---|---|---|
| MQTT | Para la mensajería bidireccional con corredores MQTT, incluido el integrado en Operaciones de IoT de Azure y Event Grid. | Sí | Sí |
| Kafka | Para la mensajería bidireccional con agentes de Kafka, incluido Azure Event Hubs. | Sí | Sí |
| Data Lake | Para cargar datos en cuentas de almacenamiento de Azure Data Lake Gen2. | No | Sí |
| Microsoft Fabric OneLake | Para cargar datos en lakehouses de Microsoft Fabric OneLake. | No | Sí |
| Azure Data Explorer | Para cargar datos en bases de datos de Azure Data Explorer. | No | Sí |
| Almacenamiento local | Para enviar datos a un volumen persistente disponible localmente, a través del cual puede cargar datos a través de Azure Container Storage habilitado por volúmenes perimetrales de Azure Arc. | No | Sí |
Importante
Los puntos de conexión de almacenamiento requieren un esquema para la serialización. Para usar el flujo de datos con Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer o el almacenamiento local, debe especificar una referencia de esquema.
Para generar el esquema a partir de un archivo de datos de ejemplo, use el Asistente de generación de esquemas.
Los flujos de datos deben usar el punto de conexión del corredor MQTT local
Al crear un flujo de datos, especifique los puntos de conexión de origen y destino. El flujo de datos mueve los datos del punto de conexión de origen al punto de conexión de destino. Puede usar el mismo punto de conexión para varios flujos de datos y puede usar el mismo punto de conexión como origen y destino en un flujo de datos.
Sin embargo, no se admite el uso de puntos de conexión personalizados como origen y destino en un flujo de datos. Esta restricción significa que el corredor MQTT integrado en Operaciones de IoT de Azure debe ser al menos un punto de conexión. Puede ser el origen, el destino o ambos. Para evitar errores de implementación del flujo de datos, use el punto de conexión de flujo de datos MQTT predeterminado como origen o destino de cada flujo de datos.
El requisito específico es que cada flujo de datos debe tener configurado el origen o el destino con un punto de conexión MQTT que tenga el host aio-broker. Por lo tanto, no es estrictamente necesario usar el punto de conexión predeterminado y puede crear puntos de conexión de flujo de datos adicionales que apunten al corredor MQTT local siempre que el host sea aio-broker. Sin embargo, para evitar problemas de confusión y capacidad de administración, el punto de conexión predeterminado es el enfoque recomendado.
En la tabla siguiente se muestran los escenarios admitidos:
| Escenario | Compatible |
|---|---|
| Punto de conexión predeterminado como origen | Sí |
| Punto de conexión predeterminado como destino | Sí |
| Punto de conexión personalizado como origen | Sí, si el destino es el punto de conexión predeterminado o un punto de conexión MQTT con el host aio-broker |
| Punto de conexión personalizado como destino | Sí, si el origen es el punto de conexión predeterminado o un punto de conexión MQTT con el host aio-broker |
| Punto de conexión personalizado como origen y destino | No, a menos que uno de ellos sea un punto de conexión MQTT con el host aio-broker |
Reutilizar puntos de conexión
Piense en cada punto de conexión de flujo de datos como una agrupación de opciones de configuración que contiene de dónde deben venir o a dónde deben ir (el valor host), cómo autenticarse con el punto de conexión y otras opciones, como la configuración TLS o la preferencia de procesamiento por lotes. Por lo tanto, solo tiene que crearla una vez y, a continuación, puede reutilizarla en varios flujos de datos donde esta configuración sería la misma.
Para facilitar la reutilización de puntos de conexión, el filtro de temas MQTT o Kafka no forma parte de la configuración del punto de conexión. En su lugar, especifique el filtro de tema en la configuración del flujo de datos. Esto significa que puede usar el mismo punto de conexión para varios flujos de datos que usan filtros de temas diferentes.
Por ejemplo, puede usar el punto de conexión de flujo de datos del corredor MQTT predeterminado. Puede usarlo para el origen y el destino con diferentes filtros de tema:
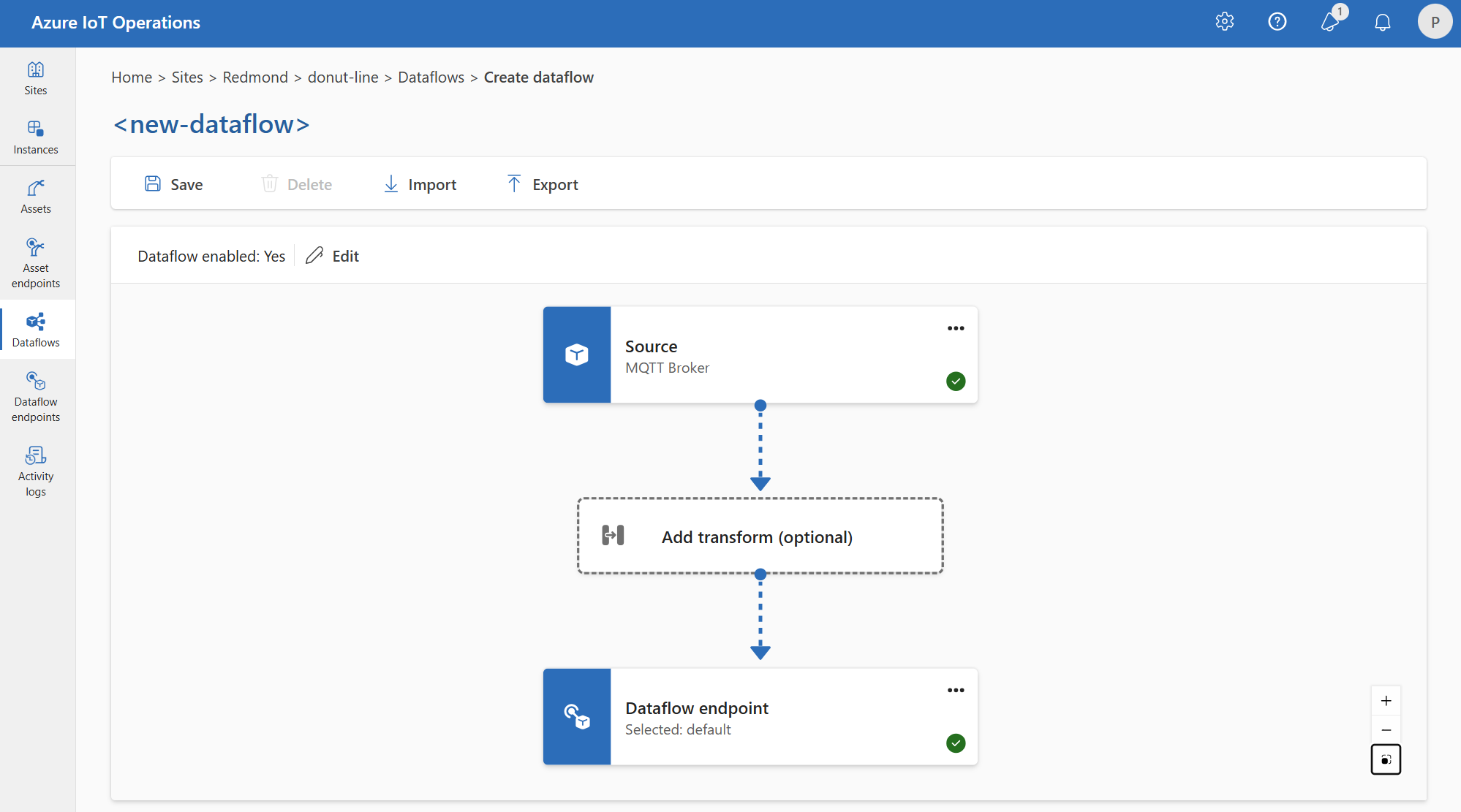
Del mismo modo, puede crear varios flujos de datos que usen el mismo punto de conexión MQTT para otros puntos de conexión y temas. Por ejemplo, puede usar el mismo punto de conexión MQTT para un flujo de datos que envíe datos a un punto de conexión de Event Hubs.
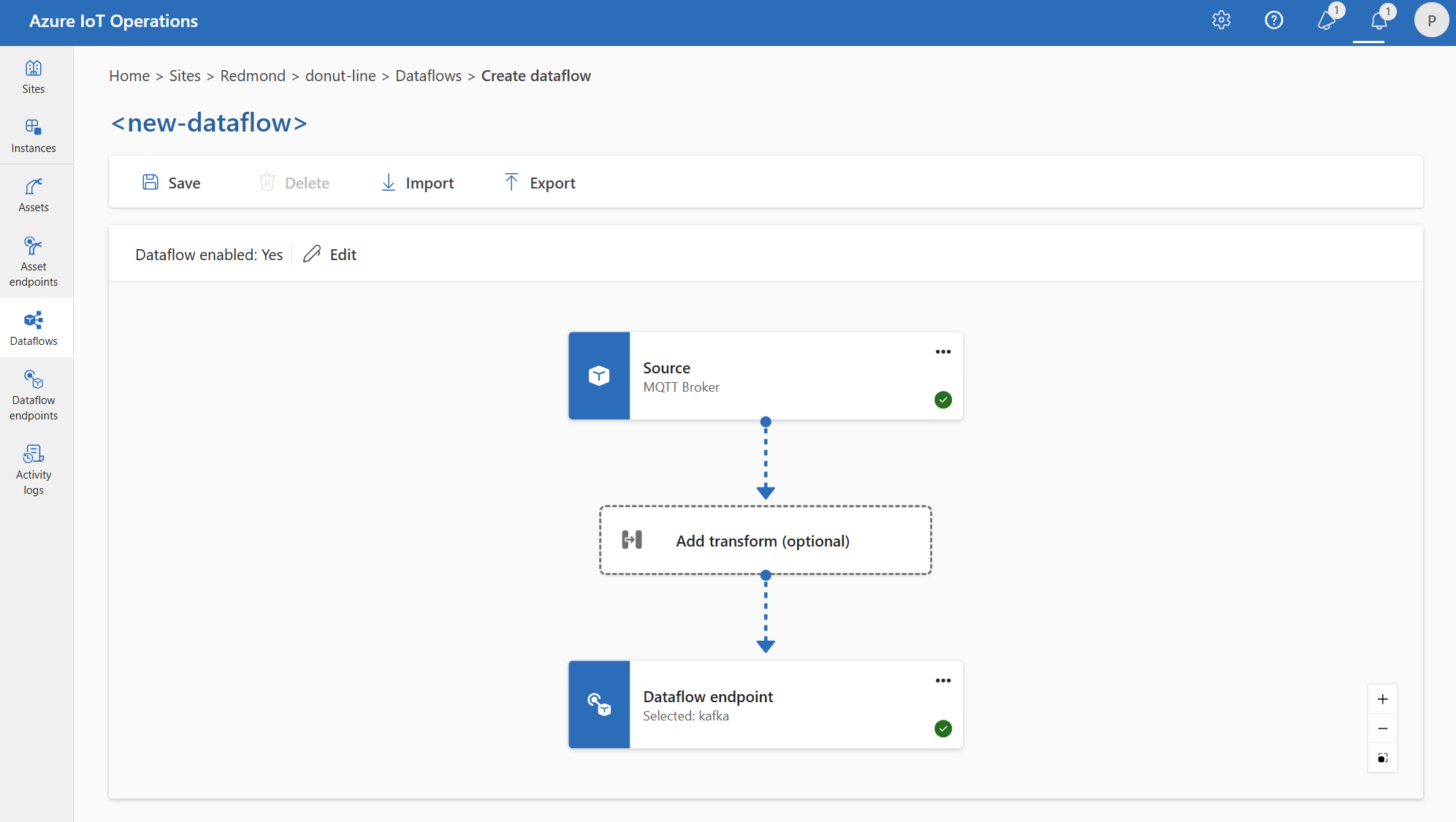
De forma similar al ejemplo de MQTT, puede crear varios flujos de datos que usen el mismo punto de conexión de Kafka para distintos temas, o el mismo punto de conexión de Data Lake para tablas diferentes.
Pasos siguientes
Crear un punto de conexión de flujo de datos: